CData Syncを使ってAmazon S3のCSVファイルをOracle Cloud Infrastracture(OCI)に構築済みのAutonomous Databaseにインポートする
はじめに
CData Syncは様々なSaaS/DBにあるデータを抽出して、データ分析基盤への同期に特化したデータパイプラインツールです。
詳しくはこちらをご覧ください。
CData Syncの現在のバージョンは「v23」となります。
以前のバージョンから UIのモダナイズ、dbt Cloud 対応、CDC 強化、新コネクタなどユーザビリティと機能面が強化されています。
今回は、CData Syncを使ってAmazon S3バケット内のCSVファイルをOracle Cloud Infrastracture(OCI)に構築済みのAutonomous Database(ADB)にインポートしてみます。
ADBの主なWorkloadのうち、今回は、Autonomous Data Warehouse(以下「ADW」と表記)で検証を行います。
実現したい構成

パブリックサブネット内に配置されたコンピュート・インスタンスにインストールされたCData SyncでAmazon S3バケット内のCSVファイルのデータをADWへ連携する。
前提条件
- コンピュート・インスタンスにCData Syncがインストール済みであること
詳しくはこちらをご覧ください。
LinuxOS:CData Sync v23をインストールしてみる
WindowsServer:CData Sync v23をWindows Serverにインストールしてみる - OCI上にADWが構築済みであること
詳しくはこちらをご覧ください。
Autonomous Databaseの作成 - パブリック・サブネット内のコンピュート・インスタンスからADWへ接続が可能であること
- Amazon S3バケットが利用可能であること
詳しくはこちらをご覧ください。
Amazon S3について手順
1.ADWコネクション設定
まずは同期先となるADWのコネクション設定を行います。
1.1.Oracle JDBC Driverセットアップ
こちらのサイトからZipped JDBC driver (ojdbc11.jar) and Companion Jarsをダウンロードします。
JDBCダウンロードサイト
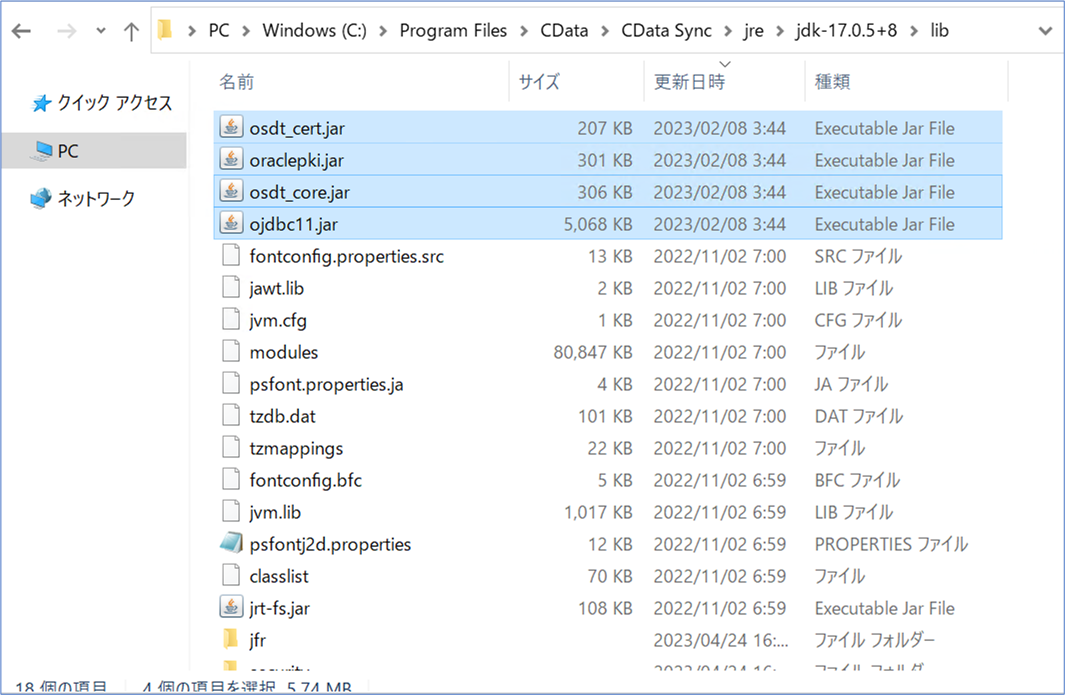
ダウンロードしたファイルを展開後、JDBCドライバ(ojdbc11.jar、oraclepki.jar、osdt_core.jar、osdt_cert.jar)をCData Syncのインストールフォルダにコピーします。
Windows Serverの場合:
例)C:\Program Files\CData\CData Sync\jre\jdk-17.0.5+8\lib
LinuxOSの場合:
/インストーラを展開したディレクトリ/libs
例)/opt/sync/libs
|
1 2 3 4 5 6 7 8 |
[opc@CSVM ~]$ ll /opt/cdata/libs/ total 251416 -rw-r--r-- 1 root root 312983 Mar 10 15:41 osdt_core.jar -rw-r--r-- 1 root root 211063 Mar 10 15:40 osdt_cert.jar -rw-r--r-- 1 root root 307822 Mar 10 15:40 oraclepki.jar -rw-r--r-- 1 root root 5189606 Mar 10 15:40 ojdbc11.jar ・・・(中略)~ |
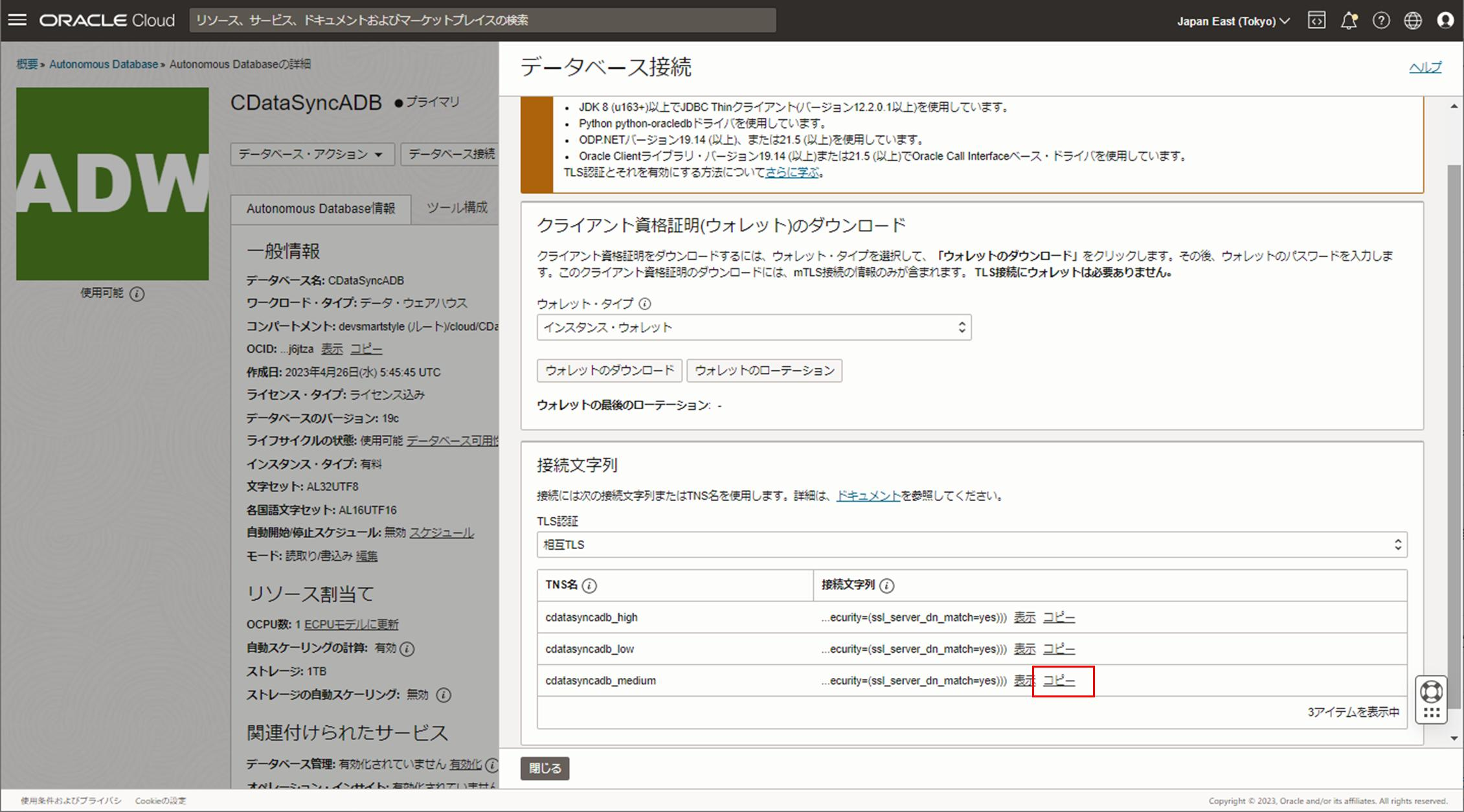
1.2.ADW接続文字列のコピー
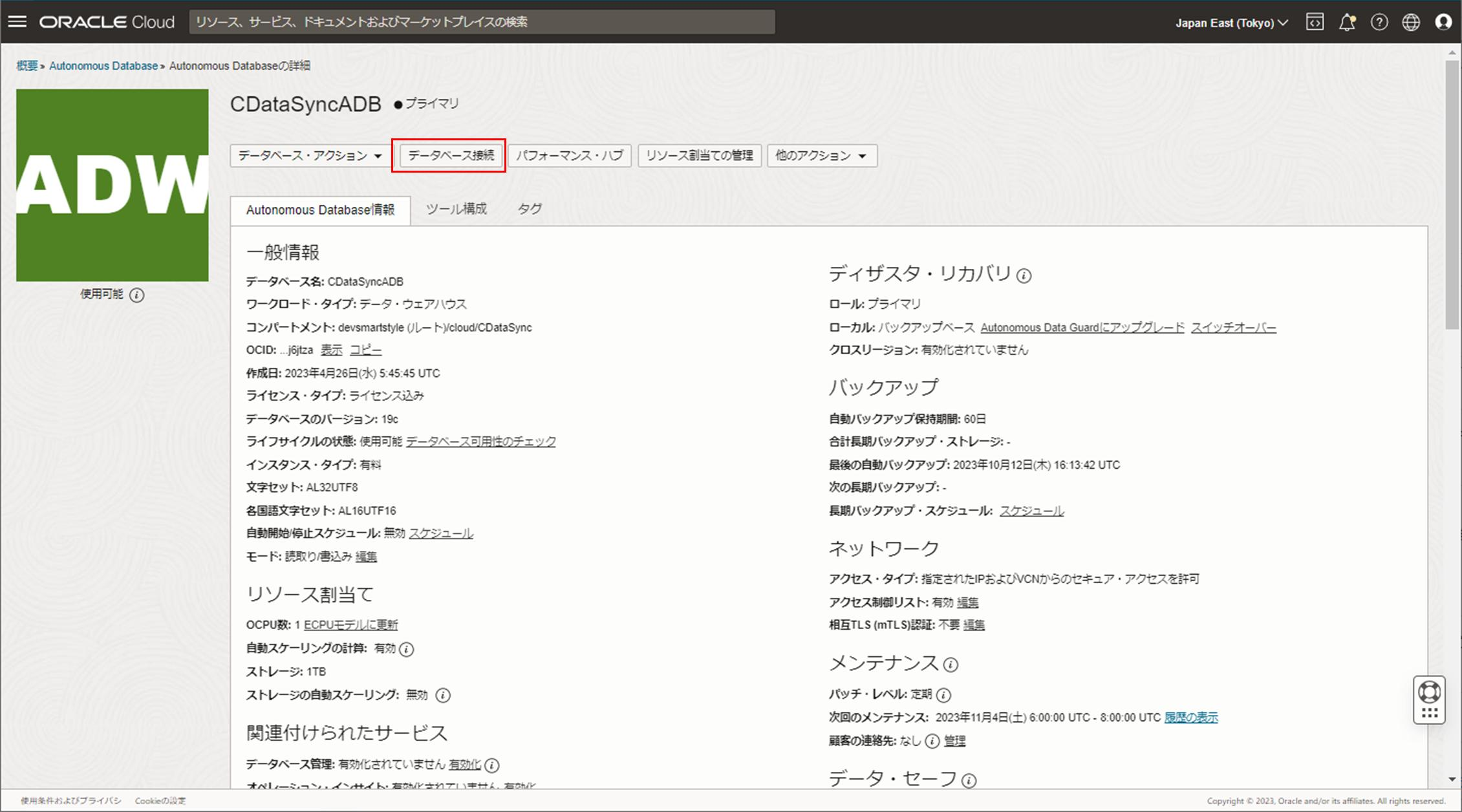
対象のADWを選択後、詳細画面で「データベース接続」をクリックし、「MEDIUM」の接続文字列をコピーします。
接続文字列はCData SyncからADWに接続する際に必要な情報となるためテキスト等に控えておきます。
1.3.CData Syncのコネクタの設定
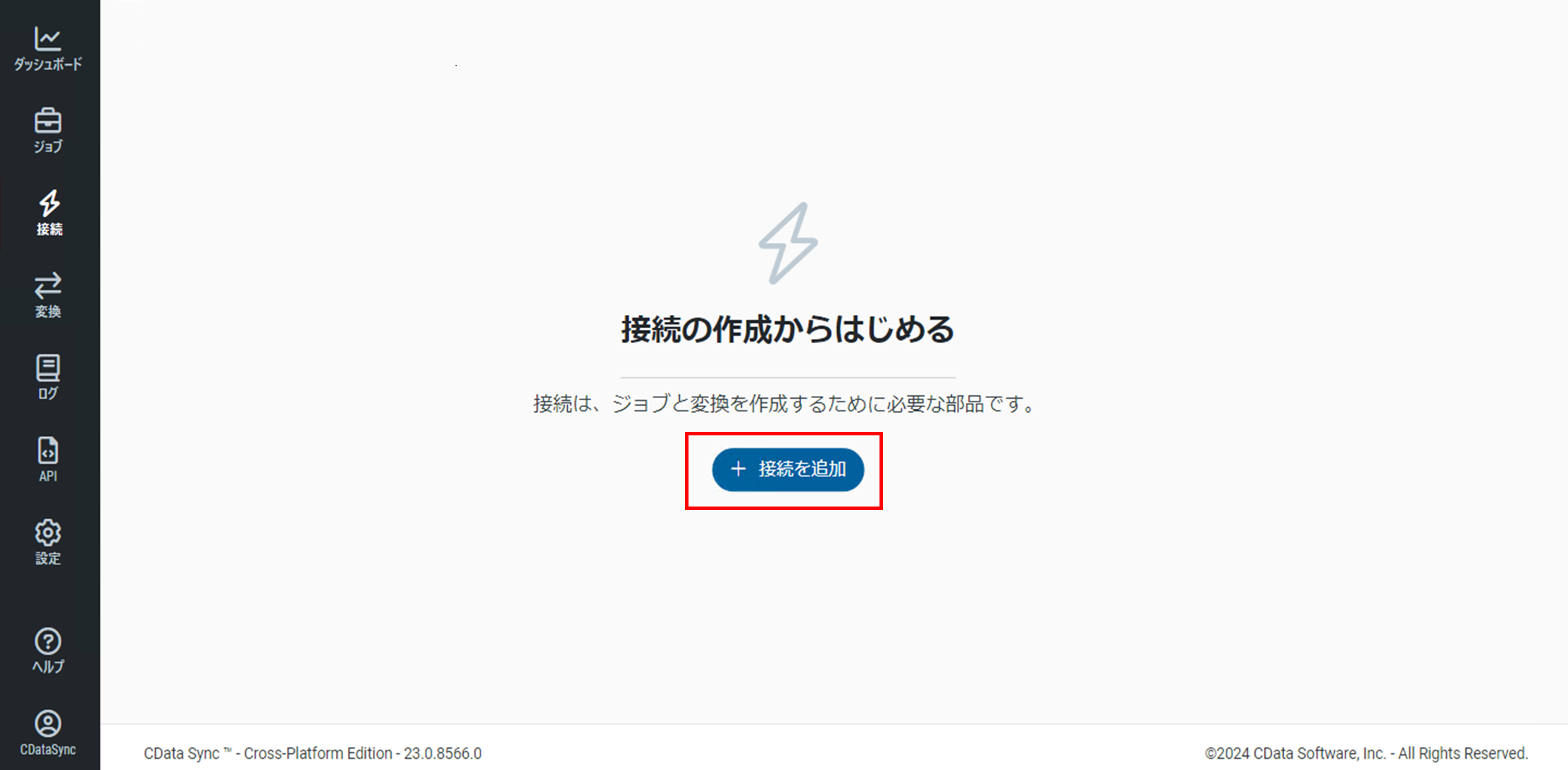
CDataSync管理コンソールにログイン後、左メニューの「接続」をクリックします。
「Connections」画面で「接続を追加」をクリックします。
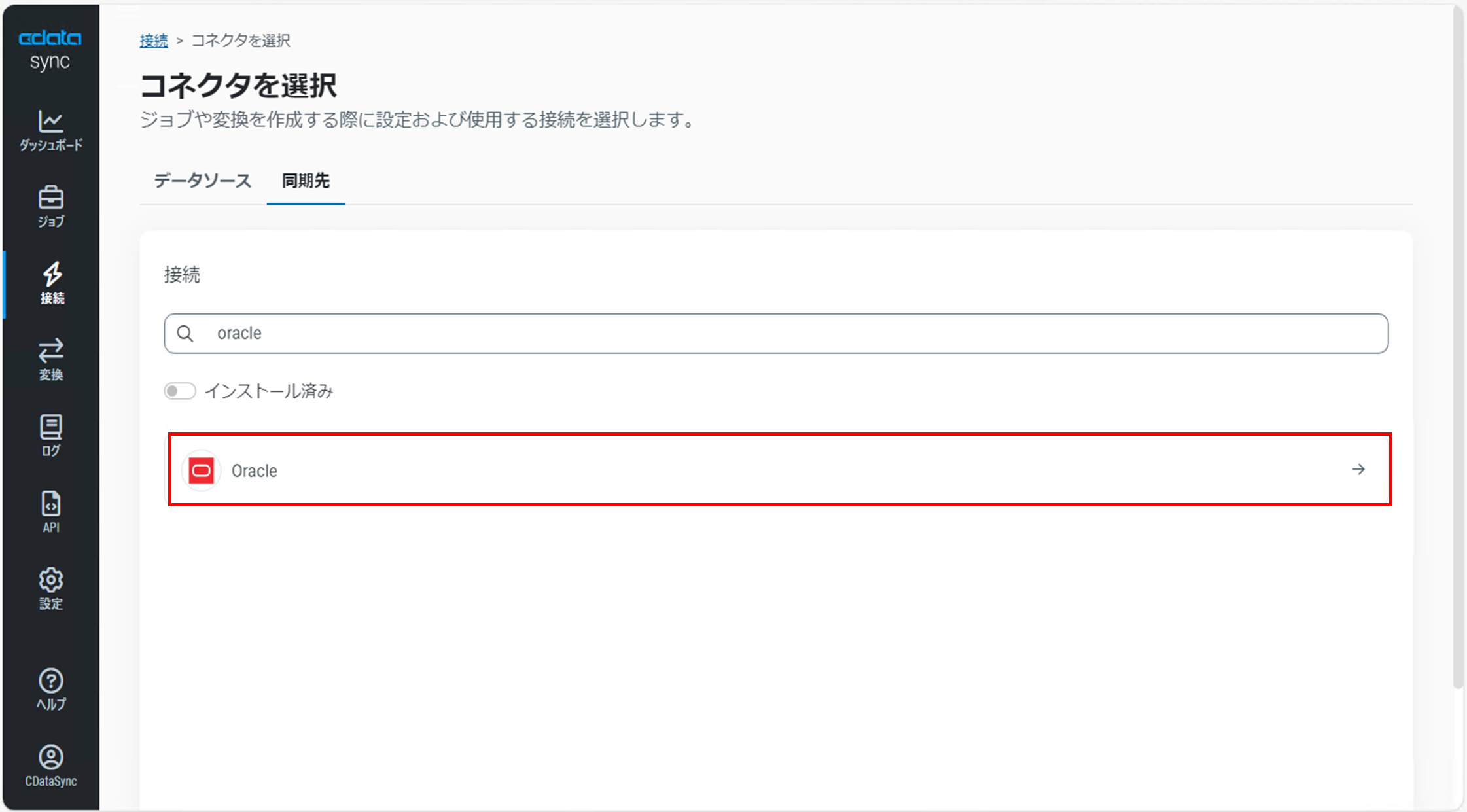
「コネクタを選択」画面で「同期先」タブに切り替え、コネクタの一覧から「oracle」を選択します。(今回は検索ワードでコネクタを検出しています)
設定画面で以下の各項目を設定します。
・接続名:任意の接続名
・Connection Type:Data Source
・User:ADWに設定した管理者ユーザ
・Password:ADWに設定した管理者ユーザのパスワード
・Data Source:取得した「ADW接続文字列」
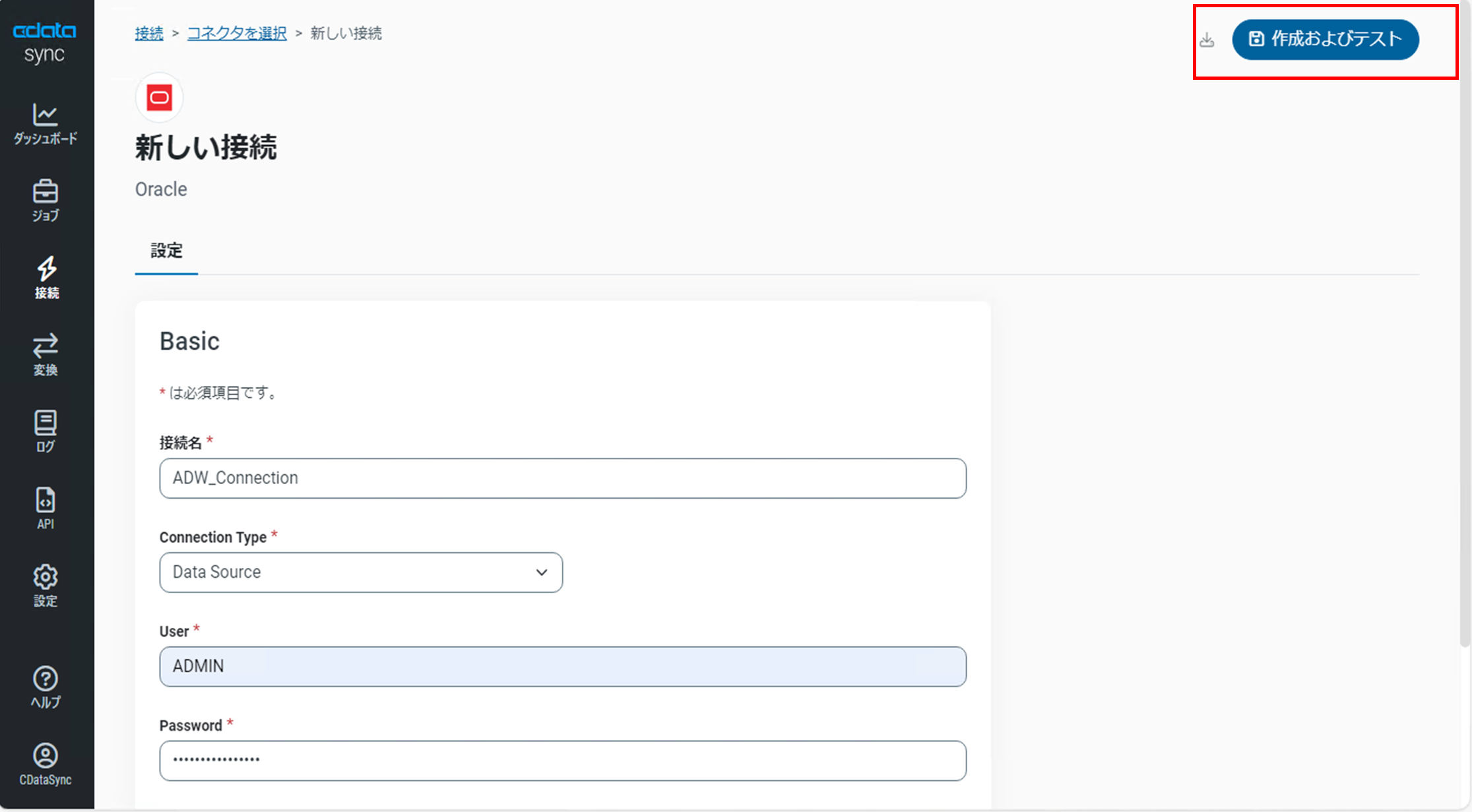
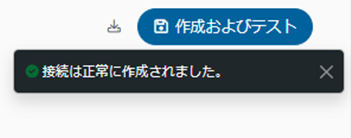
設定画面の右上にある「保存およびテスト」をクリックします。
「接続は正常に作成されました」と表示されれば設定が完了となります。
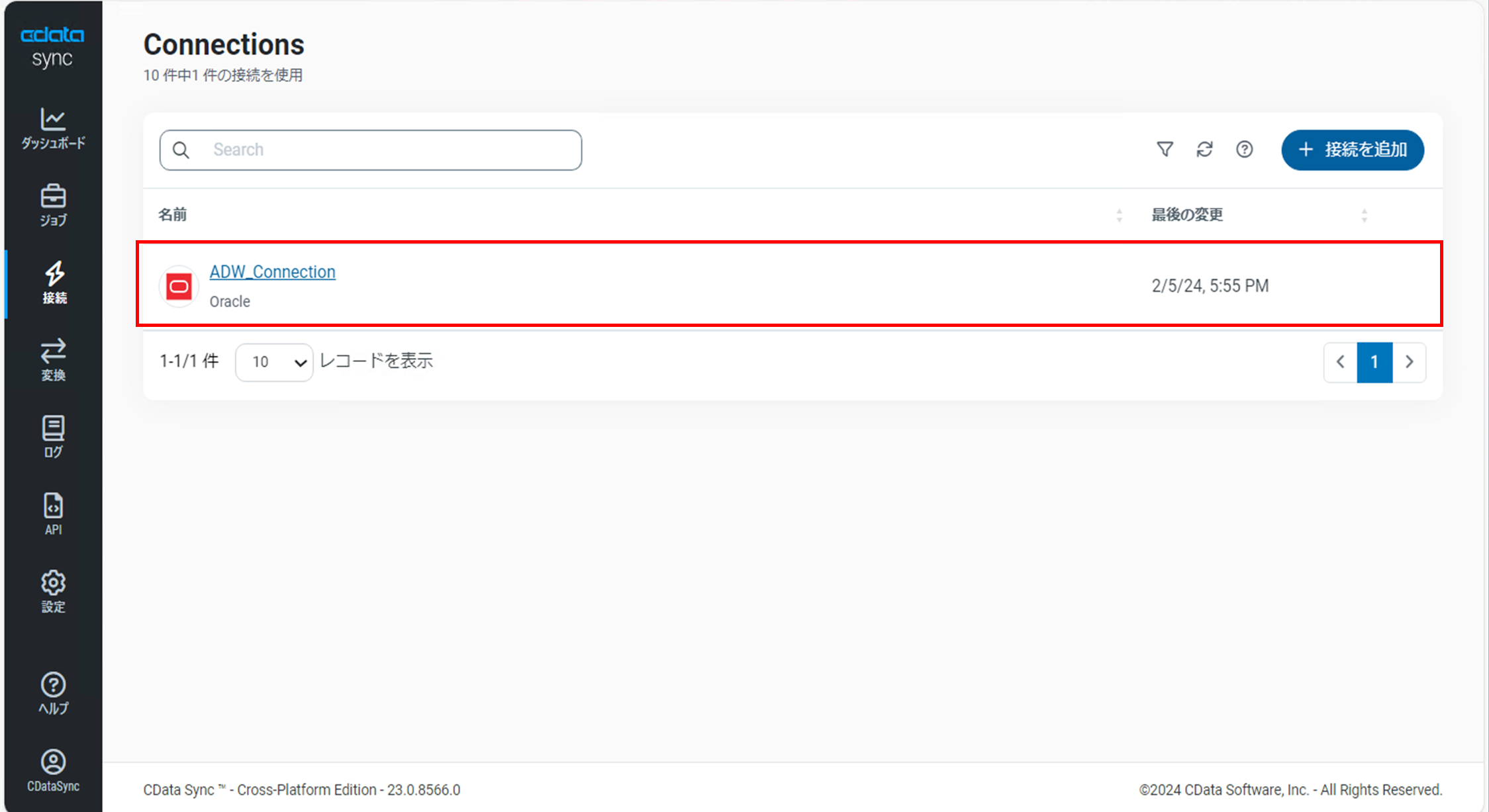
「Connections」画面を開き、ADWの接続が作成されていることを確認します。
2.CSVコネクション設定
つぎにデータソースとなるAmazon S3(CSV)のコネクション設定を行います。
2.1.アクセスキーの取得
今回はAmazon S3のバケット内のCSVをデータソースとします。
そのためAmazon S3のバケットにアクセスするアクセスキーとシークレットキーが必要となります。
アクセスキーとシークレットキーの取得方法については下記のリンクをご覧ください。
IAM ユーザーのアクセスキーの管理
2.2.CSVのコネクタ設定
CDataSync管理コンソールにログイン後、左メニューの「接続」をクリックします。
「Connections」画面で「接続を追加」をクリックします。
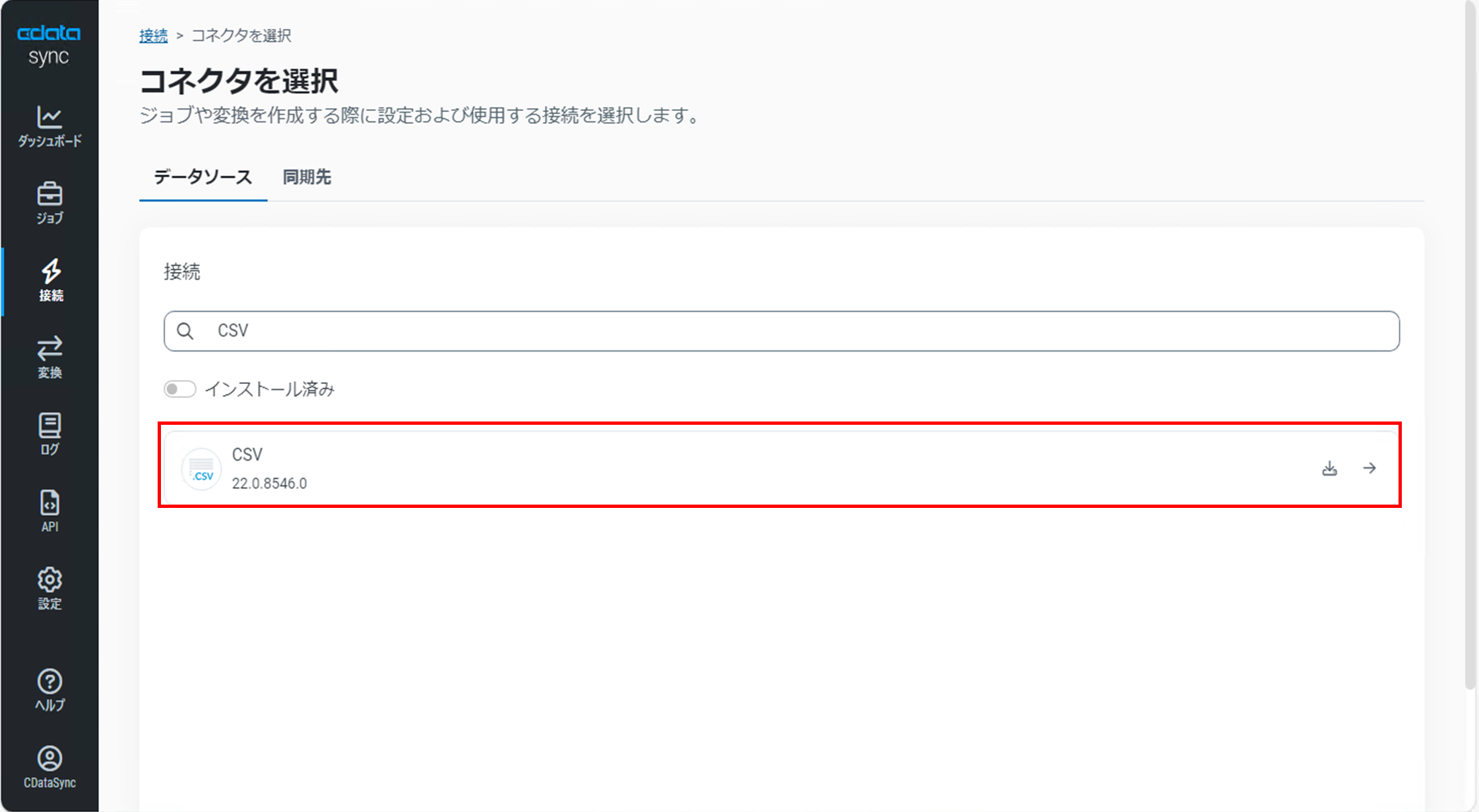
「コネクタを選択」画面で「データソース」タブになっていることを確認し、コネクタの一覧から「CSV」を選択します。(今回は検索ワードでコネクタを検出しています)
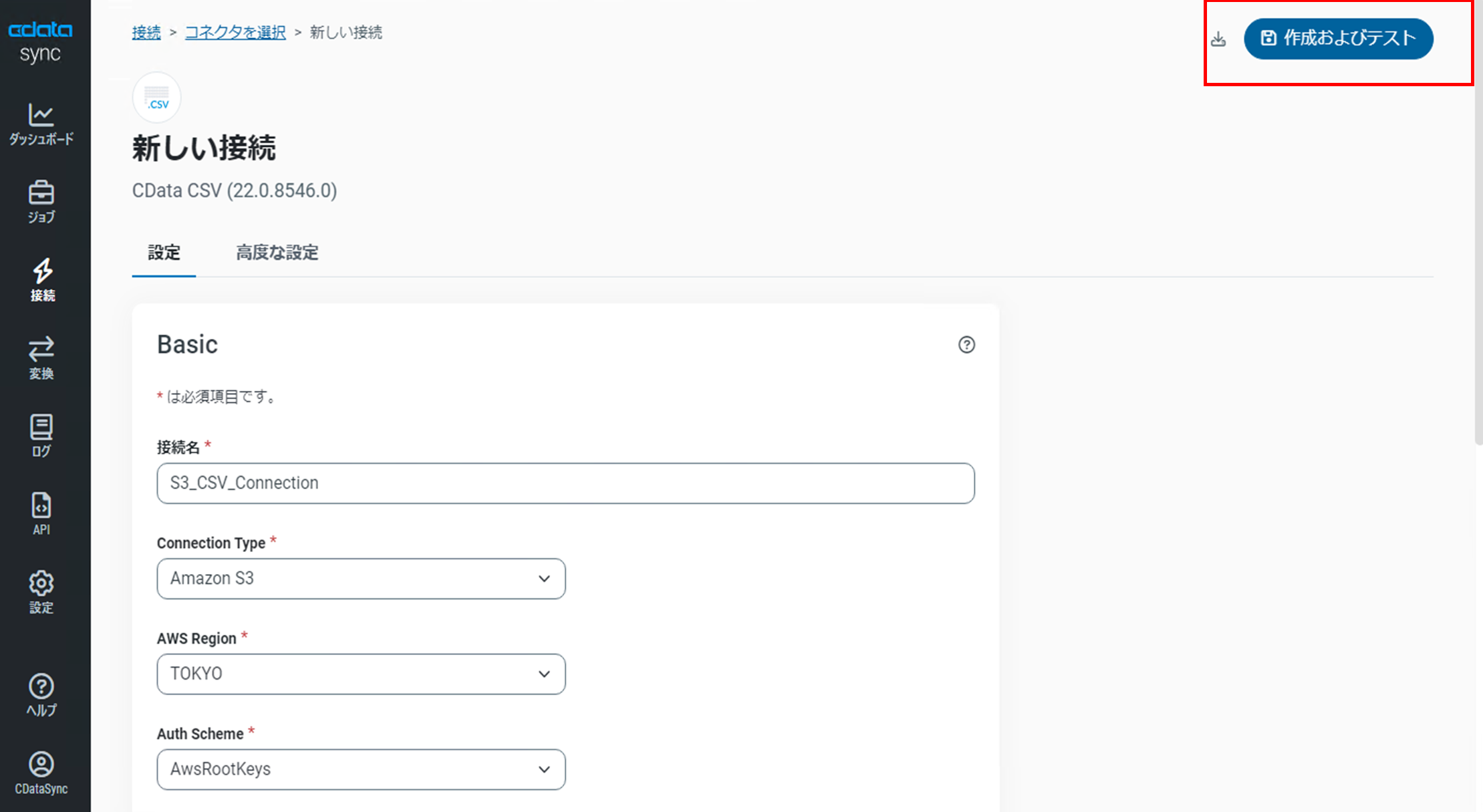
設定画面で以下の各項目を設定します。
・接続名:任意の接続名
・Connection Type:Amazon S3を選択
・AWS Region:AWS リージョンを指定
・Auth Scheme:AwsRpptKeysを選択
・AWS Access Key :IAMユーザーのアクセスキー
・AWS Secret Key:IAMユーザーのシークレットキー
・URI:対象のS3バケットのS3 URIを指定
・Aggregate Files:Falseを選択
・Include Column Headers:Trueを選択
設定画面の右上にある「保存およびテスト」をクリックします。
「接続は正常に作成されました」と表示されれば設定が完了となります。
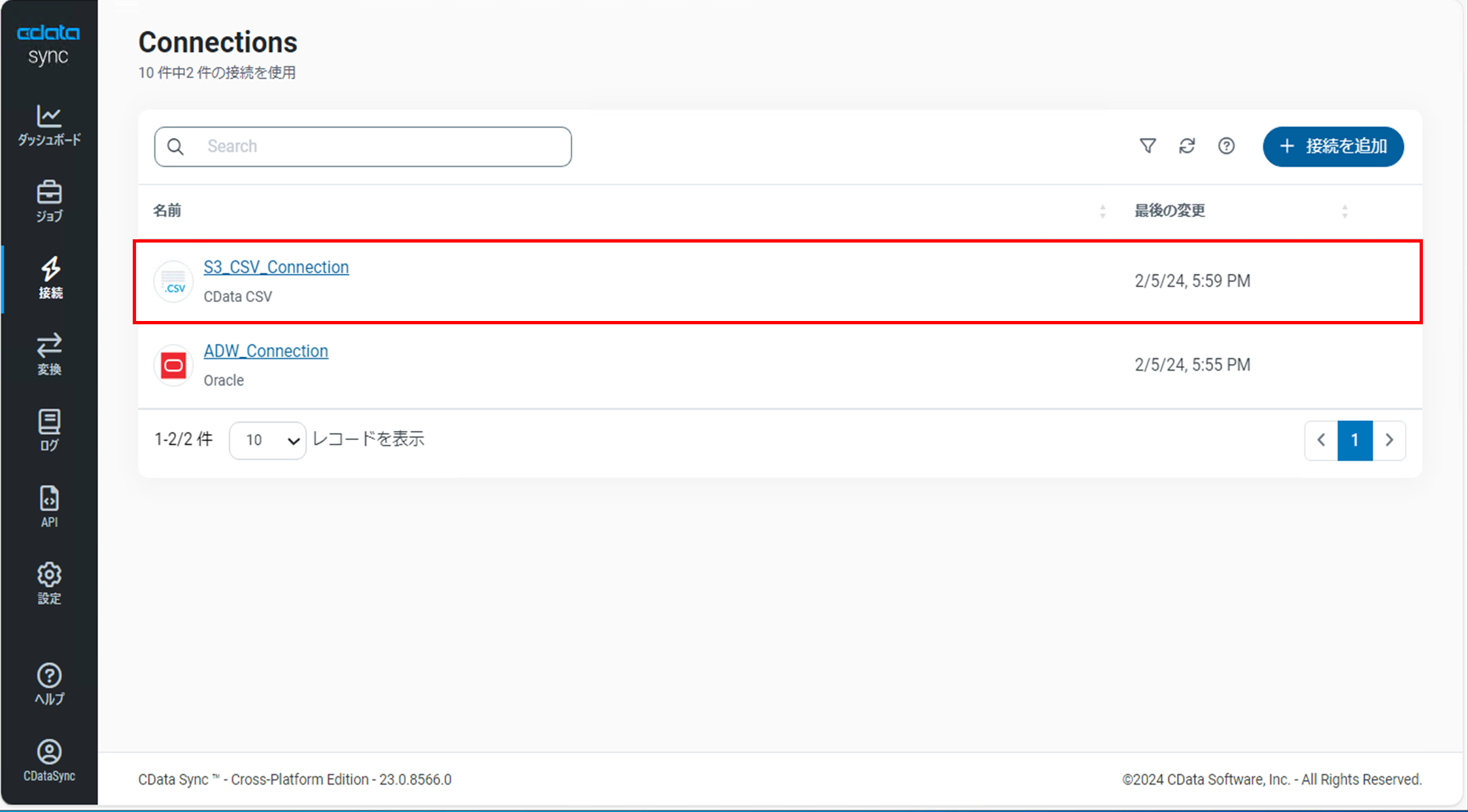
「Connections」画面を開き、CSVの接続が作成されていることを確認します。
3.ジョブ設定
データソースと同期先のコネクション設定が完了したら、CSVからADWへのデータ連携ジョブを作成します。
3.1.CData Syncのジョブの設定
管理コンソールの左メニューの「ジョブ」をクリックします。
「ジョブ」画面で「ジョブを追加」をクリックします。
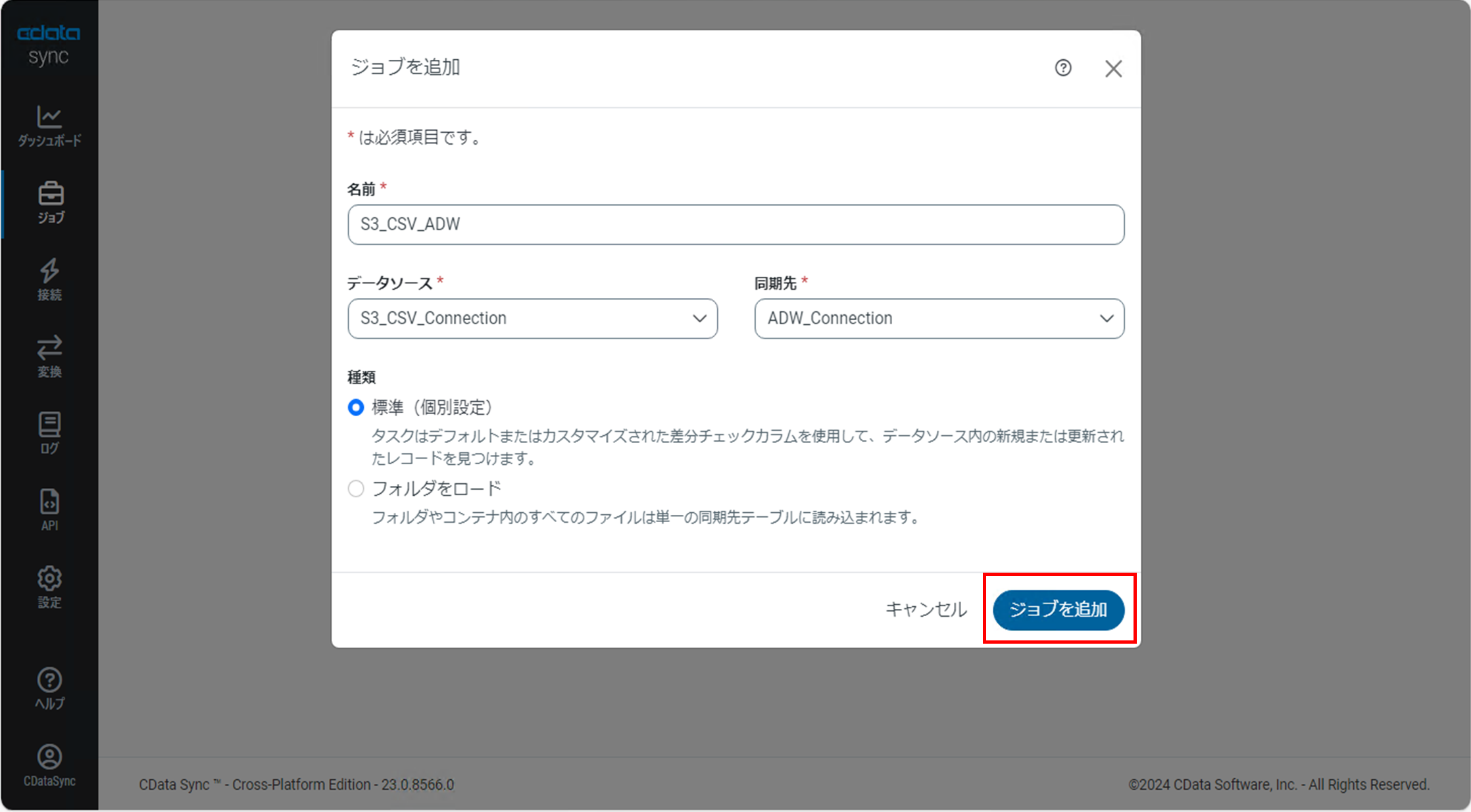
「ジョブを追加」ダイアログ画面で以下の項目を設定します。
・名前:任意のジョブ名
・データソース:CSVのコネクション名
・同期先:ADWのコネクション名
項目を設定後、「ジョブを追加」をクリックします。
「ジョブ」画面でジョブが作成されていることを確認します。
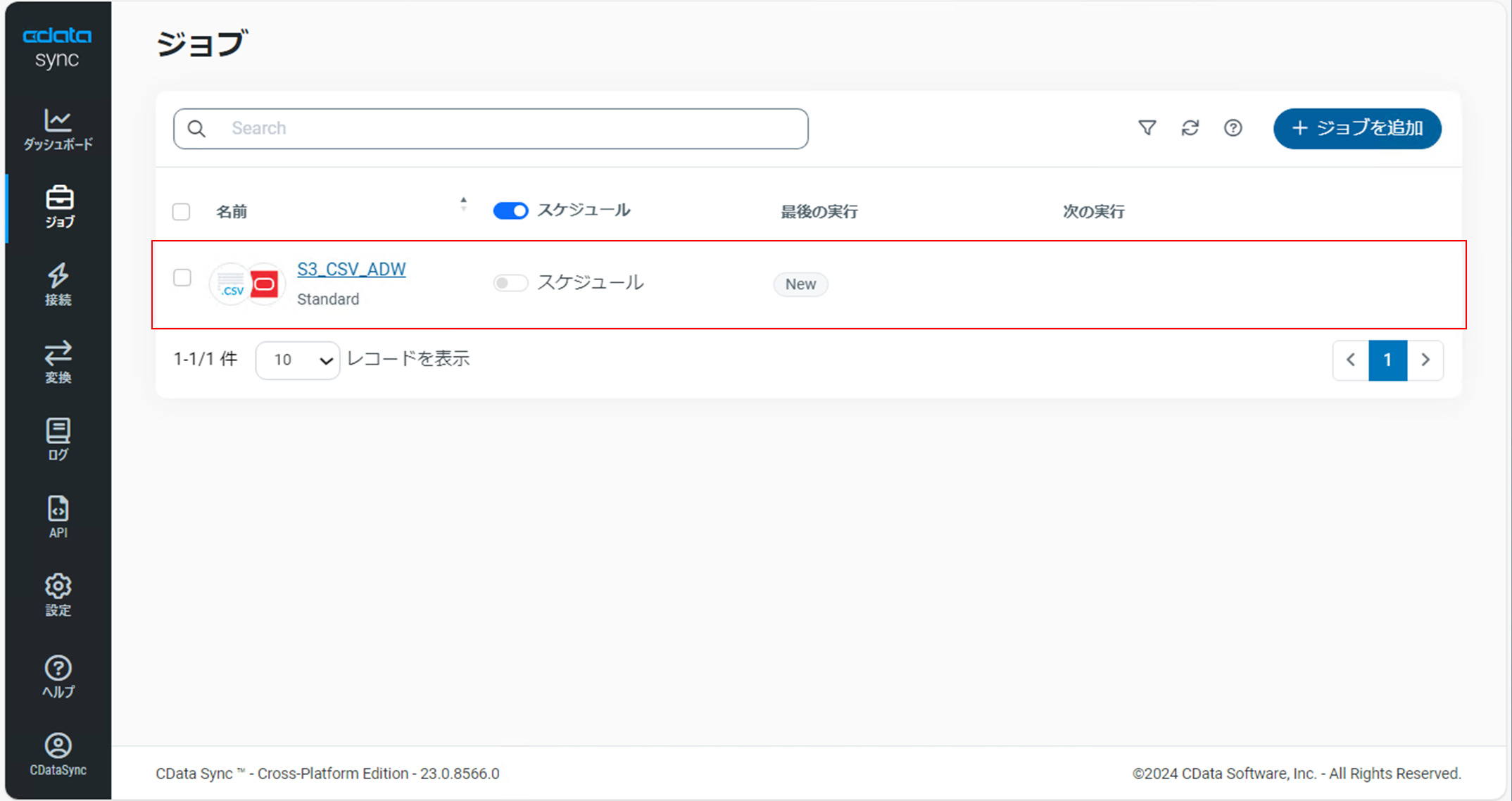
作成したジョブをクリックし、ジョブの詳細画面で「タスク」タブに切り替えます。
「タスクを追加」をクリックします。
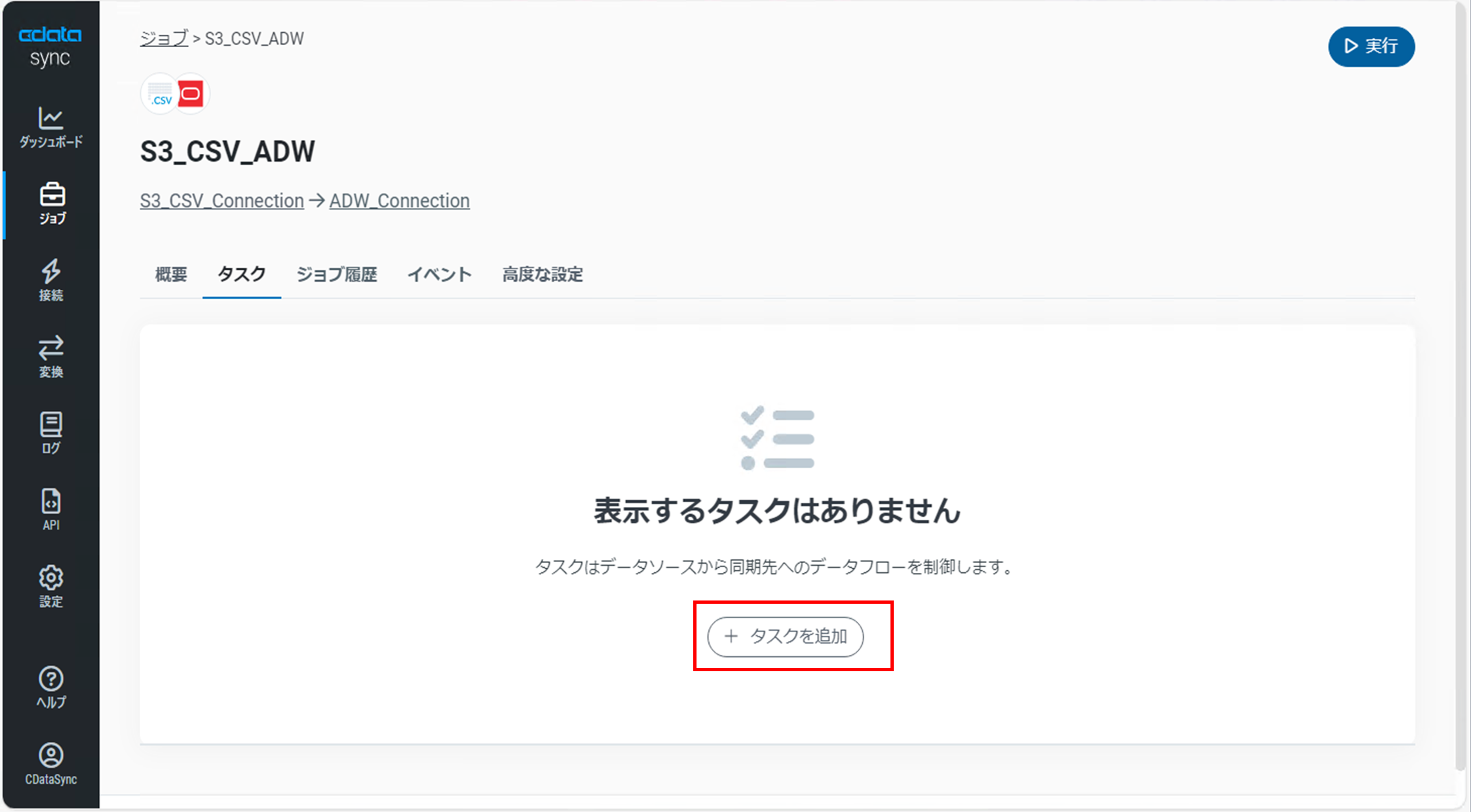
「タスクを追加」ダイアログが表示されます
データソースとなるAmazon S3バケット内のCSVファイルが表示され、ここで選択したCSVファイルがテーブルとして連携されます。
任意のCSVファイルにチェックを入れ「タスクを追加」をクリックします。
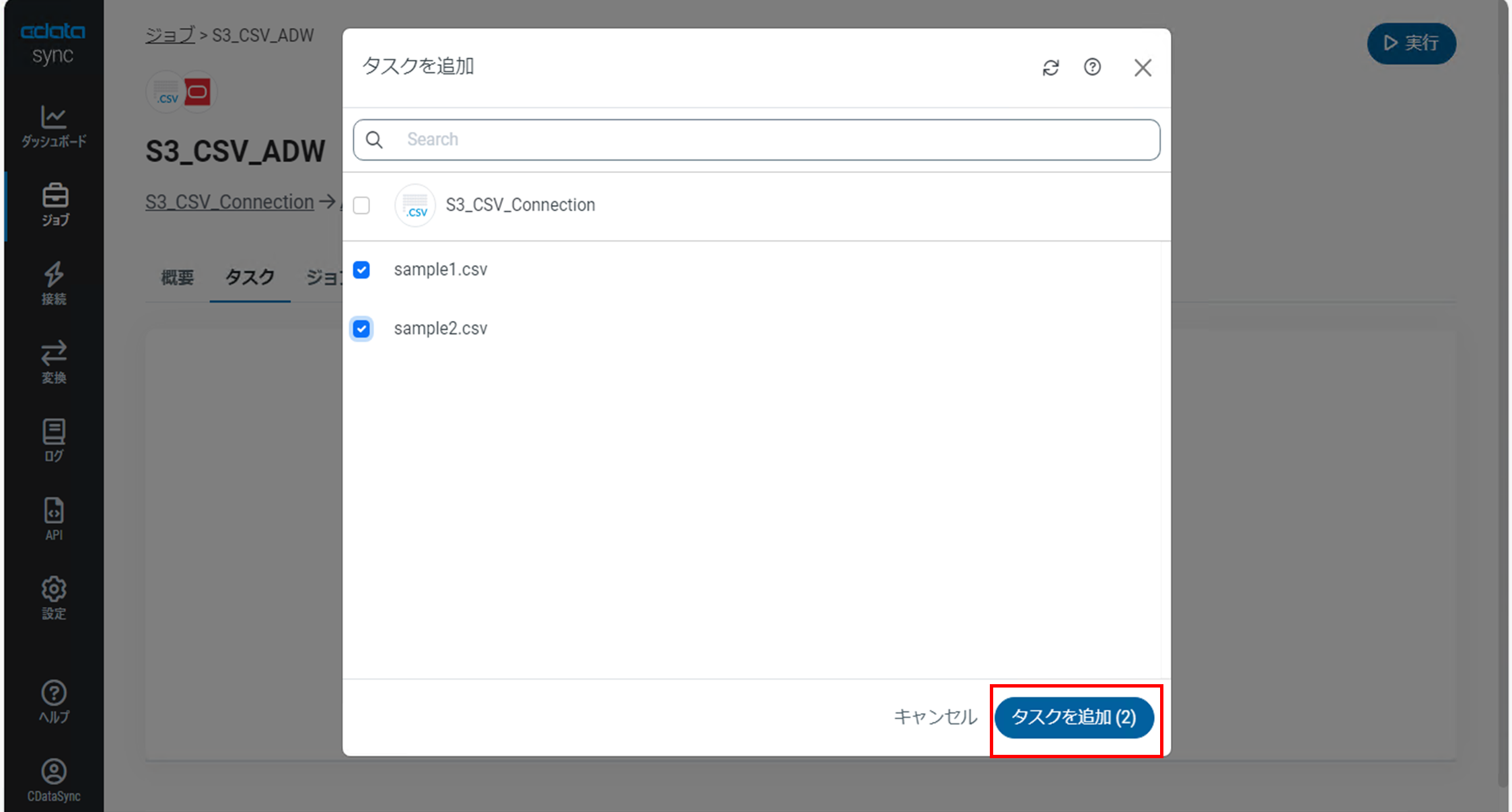
ジョブの詳細画面で「タスク」タブに切り替え、追加したオブジェクトが設定されていることを確認します。
今回はわかりやすいように、同期先でのテーブル名を意図的に変更します。
追加したタスクをクリックし「タスクの詳細画面」で右側の「同期先情報」右上の「Edit Setting」アイコンをクリックします。
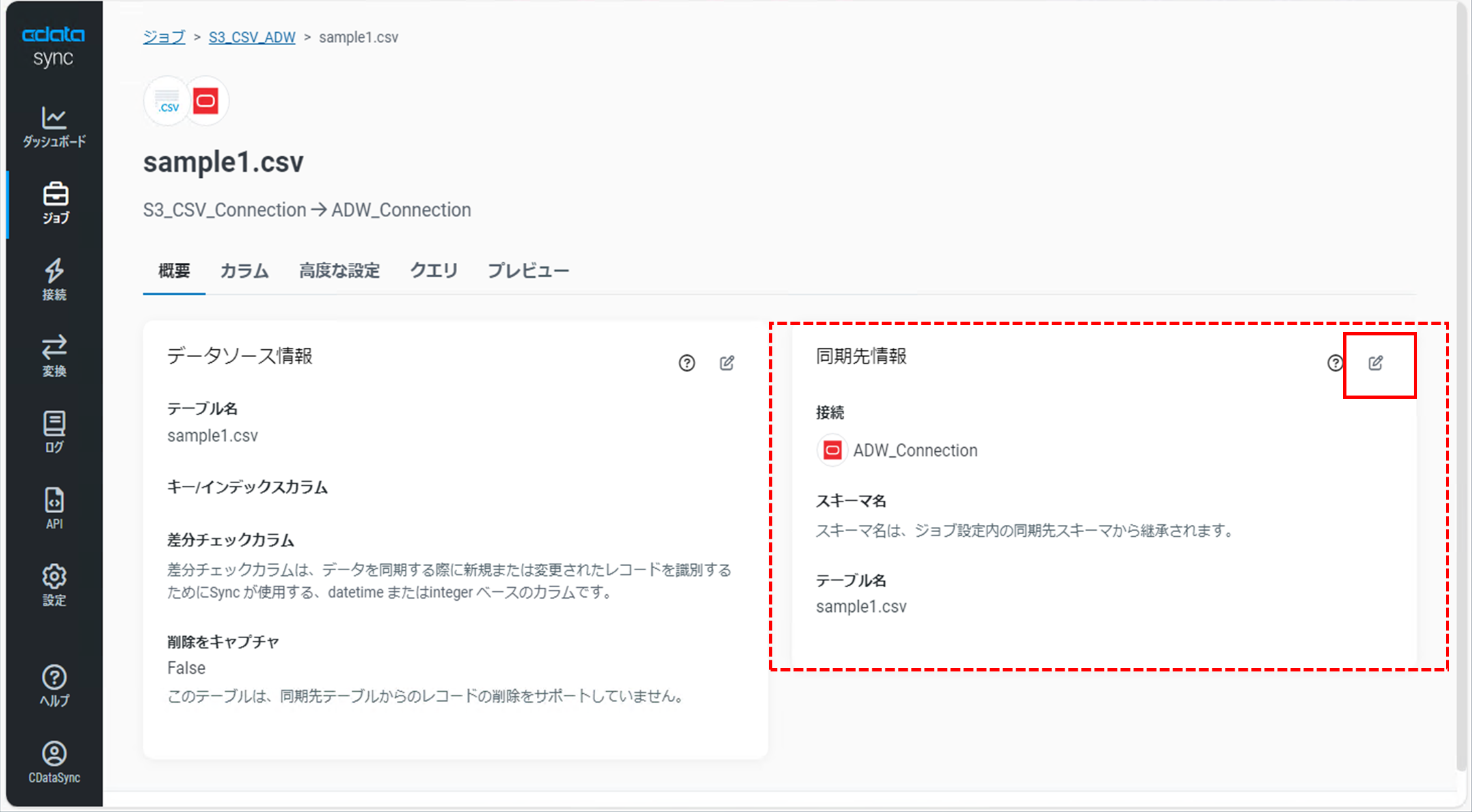
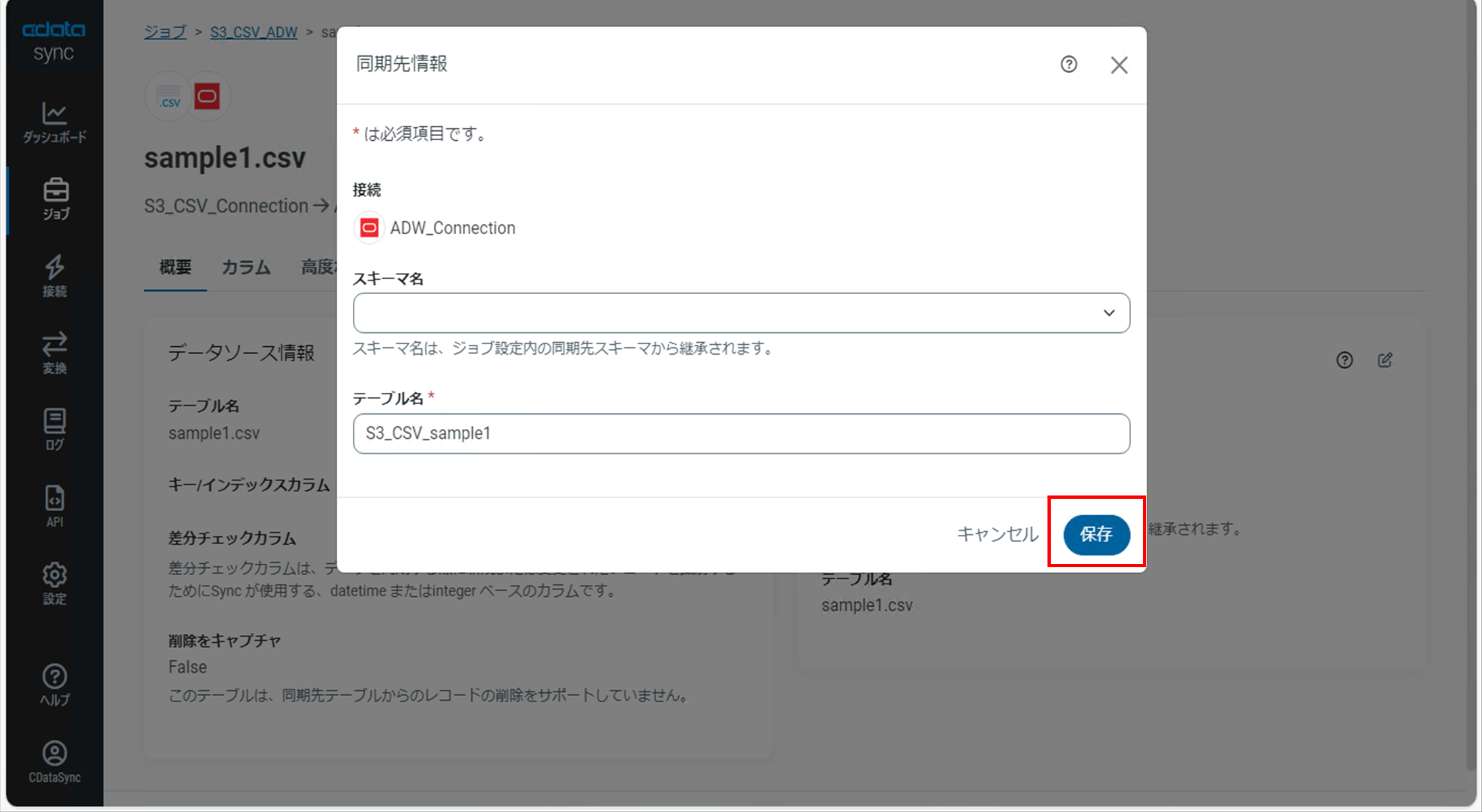
「同期先情報」ダイアログが表示され「テーブル名」を変更することができます。
デフォルトではファイル名がそのままテーブル名として同期されます。
今回は、Amazon S3からのCSVファイルをインポートしたことを明記するため「S3_CSV_ファイル名」というテーブル名に変更します。
変更後、「保存」をクリックします。
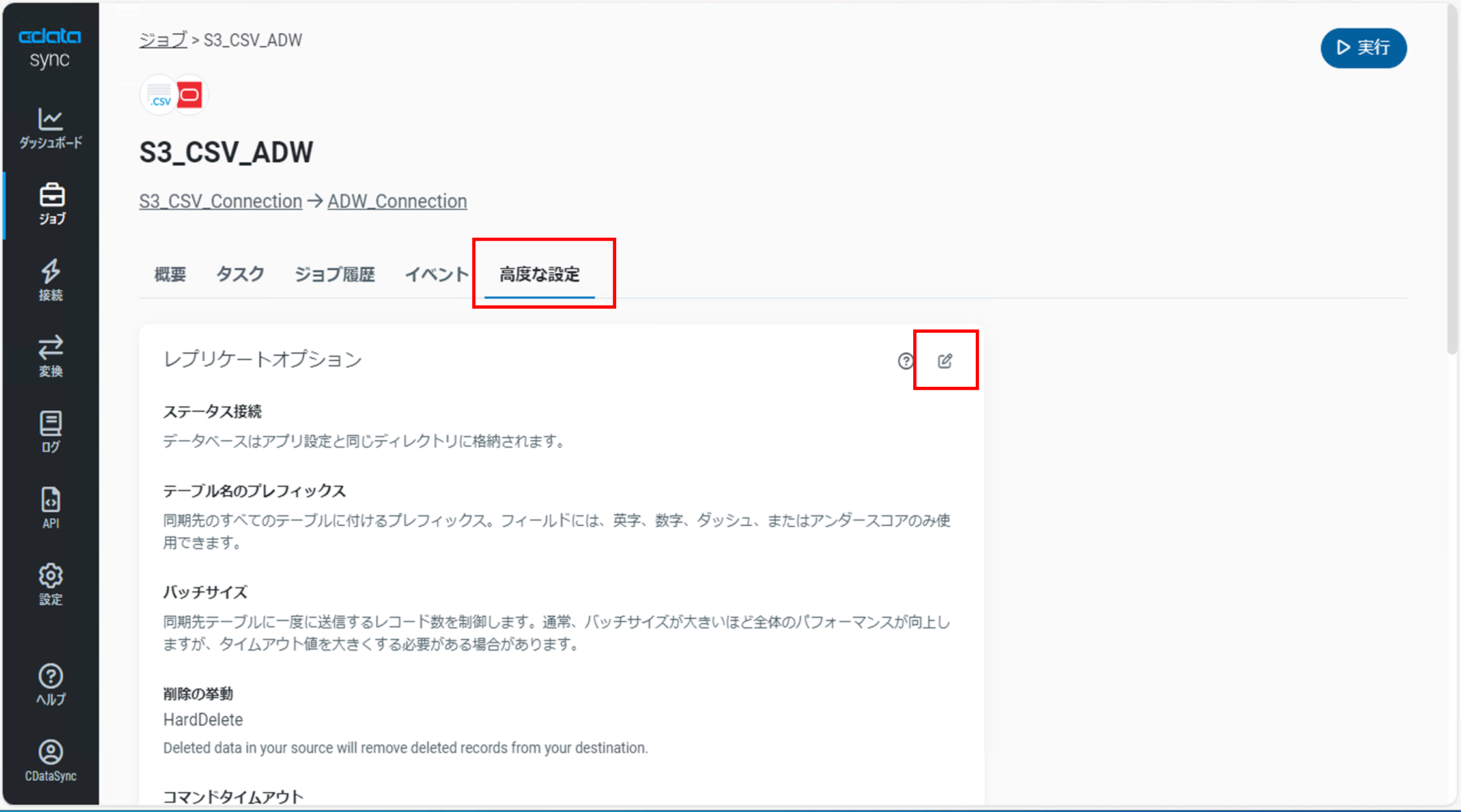
同期先のテーブル名、カラム名を大文字に統一します。
同期先のDBによっては、テーブル名、カラム名に大文字、小文字が混在することでSQL文で名前を指定する際、ダブルクォーテーション(“”)で囲う必要があるため事前に統一しておきます。
「ジョブの詳細」画面の「高度な設定」タブでレプリケーションオプションの右上の「Edit Setting」アイコンをクリックします。
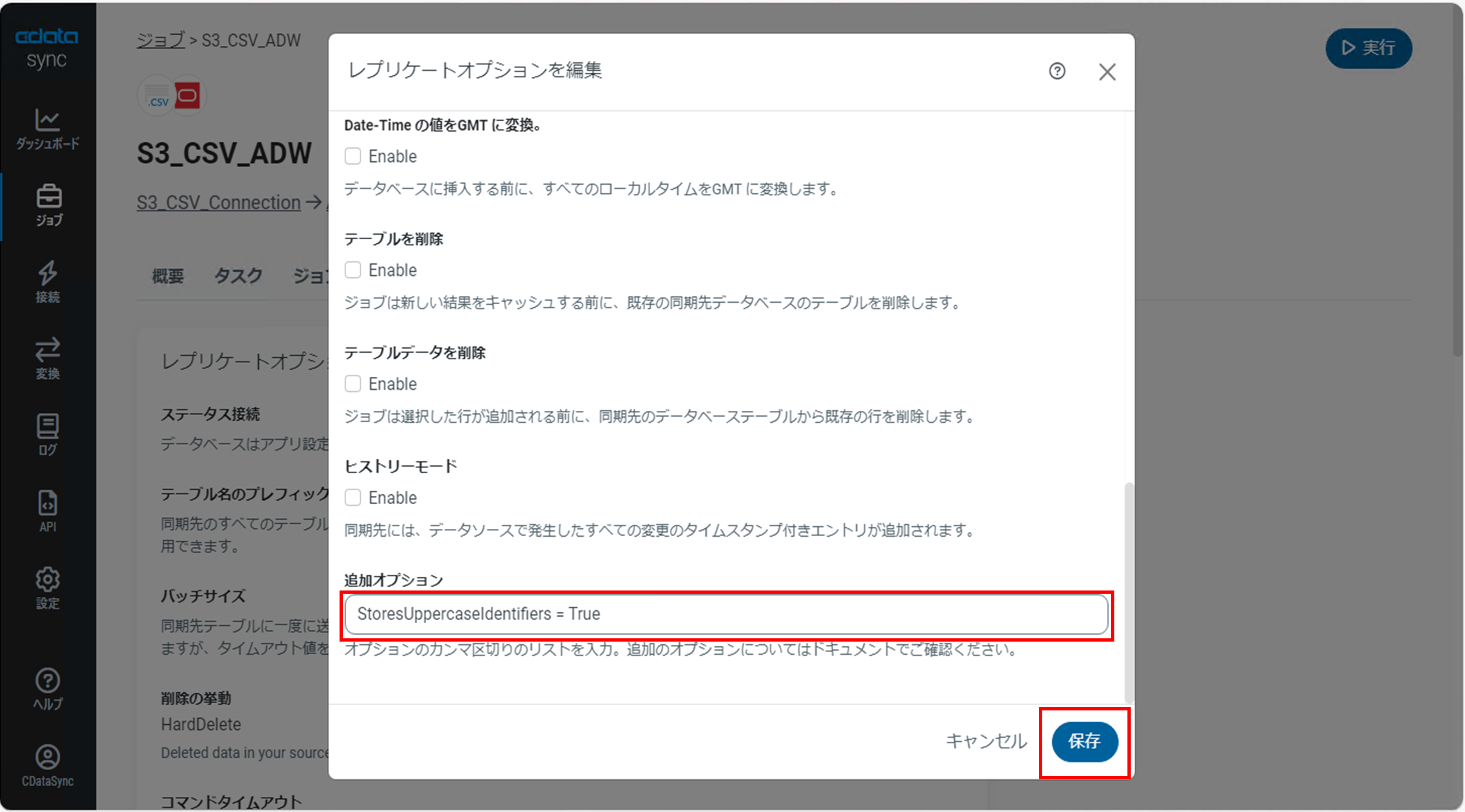
「追加オプション」に「StoresUppercaseIdentifiers = True」と入力して「保存」をクリックします。
「ジョブの詳細」画面で右上の「実行」をクリックします。
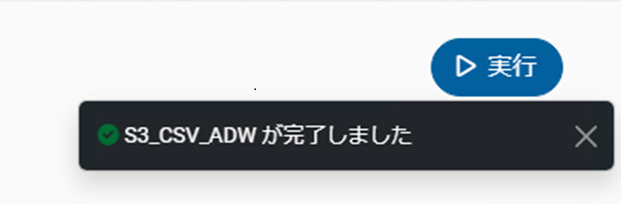
「ジョブ名(今回は[S3_CSV_ADW])が完了しました」と表示されればデータ連携が成功です。
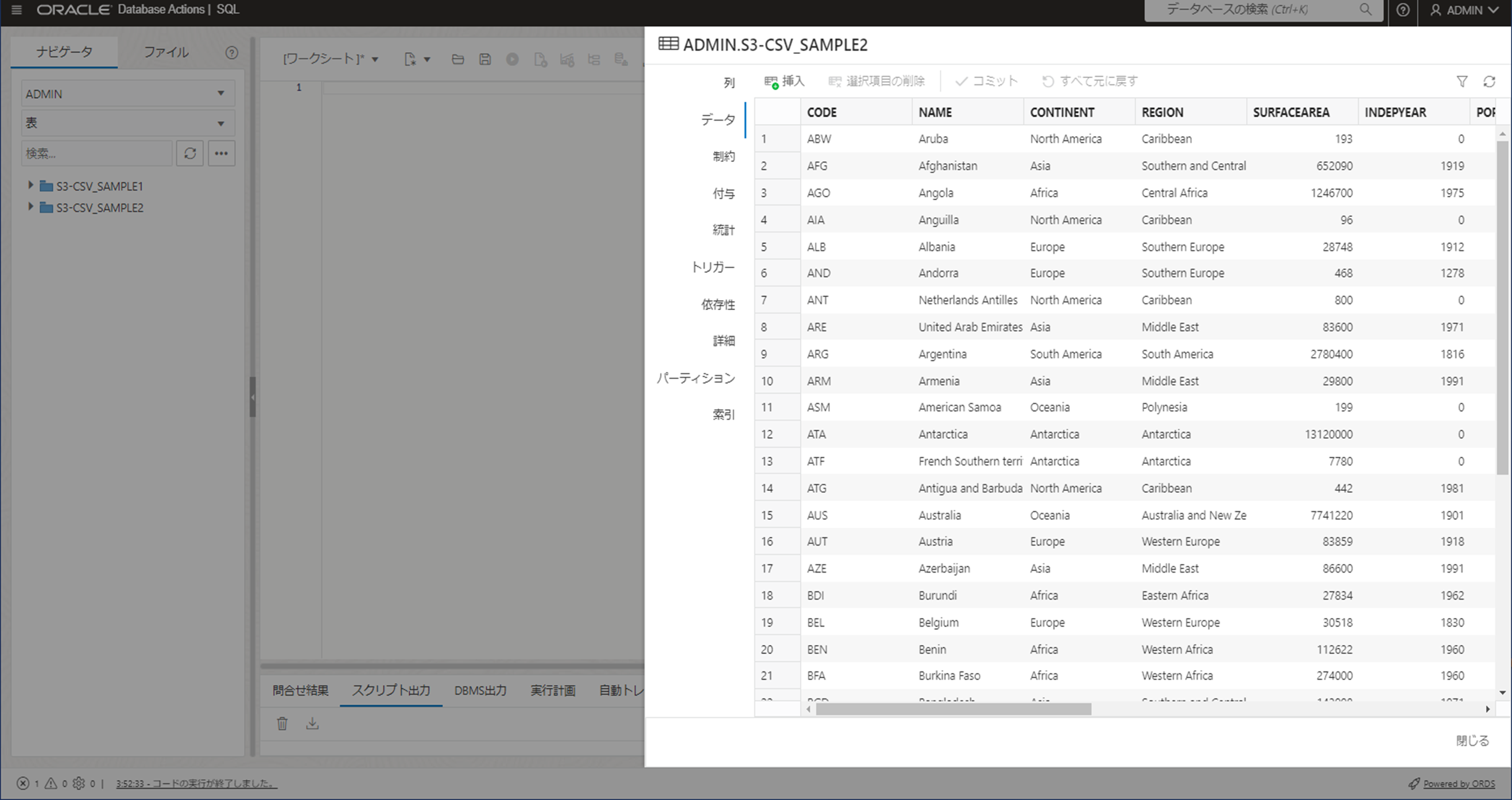
同期先のADWにデータが同期されていることを確認します。
以上がCData Syncを使用してAmazon S3のCSVファイルをADWへインポートする流れとなります。
まとめ
今回、CData Syncでデータ連携を検証してみてみました。
今回は一部の機能のみを使用してデータ連携の検証を行いましたが、CData Syncには他にも多くの機能が備わっており既存の環境に合わせた柔軟なデータ連携が可能です。
CData Syncは400種類以上のデータソースと20種類以上のデータベースを同期先としてサポートしています。
複数のSaaS/DBを使用している環境において、データの集約と分析のための可視化を課題と感じられているお客様も多く、CData Syncであればシンプルな構成および手順(3ステップ)でデータ連携が実現できます。
また複数のデータソースから同一のデータベース同期先へ、複数連携の実現も容易です。