今回は Orchestrator バージョン 3.2.6 で追加された 準同期レプリケーショントポロジーの管理機能 を紹介します。
Release GA release v3.2.6 · openark/orchestrator · GitHub
EnforceSemiSyncReplicas & RecoverLockedSemiSyncMaster – actively enable/disable semi-sync replicas to match master’s wait count #1373, thanks @binwiederhier
どのような機能かというと…
準同期レプリケーションを有効にしているトポロジーにおいて構成に変化が生じた場合、Orchesetrator が固有の障害分析として検知し、優先度に応じて準同期レプリケーションフラグパラメータを 自動的に ON/OFF するというものです。
デフォルトでは無効になっていますので、使用するには対象の準同期レプリケーショントポロジーの構成(待機レプリカ数や優先度、特定のレプリカは非同期とする、など)をあらかじめ設定しておき、関連パラメータを有効にしておく必要があります。
本機能を設定しておくことで、障害やメンテナンス時に、DBAが手動で準同期レプリケーションのフラグを管理・変更する手間がなくなります。
特に以下のようなケースに人的介入なく対処できるようになるため、準同期レプリケーションを用いる環境では非常に有益な機能と言えます。
複数台レプリカがある構成で、フェイルオーバー先レプリカを固定したい
-
複数台の準同期レプリカが存在し、
rpl_semi_sync_master_wait_for_slave_count = 1(デフォルト)が設定されている環境において、どのレプリカが ACK を返す(した)かどうかは分かりません。これは通常稼働中は問題ありませんが、ソースがダウンしてフェイルオーバー先を決定する場合、どのレプリカを新ソースとして昇格させるかというと、最新のトランザクションを受領済みのレプリカを割り出すことになりますが、リカバリシナリオ全体が非常に複雑になってしまいます。
どのサーバを昇格してどのサーバをメンテナンスするかといった判断含めた障害復旧をシンプルにするために、特定の準同期レプリカをフェイルオーバー候補としておく設定が可能となります。
-
トポロジー内に混在する、特定の非同期レプリカを可能な限り準同期ソースとして昇格させない(バックアップ専用など)
レプリカの増減が発生しても、rpl_semi_sync_master_wait_for_slave_count を保つようにしたい
- トポロジー内に最低1台準同期レプリカが存在すればいい、という環境では自動的に構成を保っていてくれると嬉しいですよね。
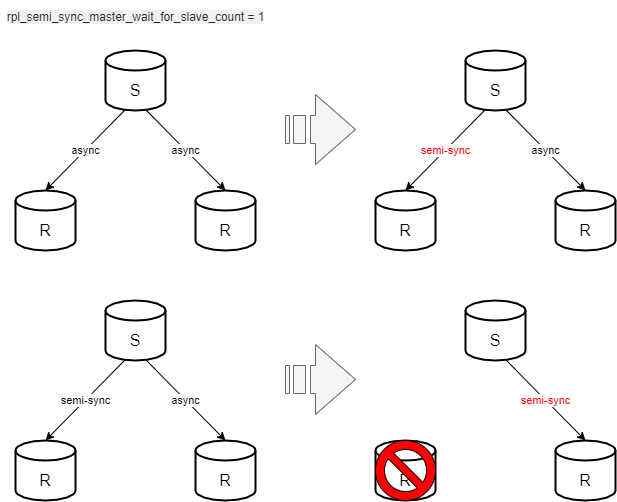
トポロジー全台のインスタンスに、静的に rpl_semi_sync_master_enabled = ON, rpl_semi_sync_slave_enabled = ON を設定した状態で起動しておく運用をしていることもあると思います。
フェイルオーバーさせる、ということ自体はそれで問題ない(手動でフラグ変更が不要)ですが、上記のようなシチューション(特にフェイルオーバー契機でないケース)に柔軟に対応するには、どうしても DBA のオペレーションが必要となります。
準同期レプリケーションを採用することでコンフィグレーションが複雑化するので、Orchestrator の機能で準同期レプリケーションフラグを事前定義に応じて自動管理させるメリットは大きいと考えます。
早速、この機能の詳細について触れていきたいと思います。
公式ドキュメント
今回紹介する機能は、以下のドキュメントページに詳細が記載されています。
-
orchestrator/configuration-discovery-classifying.md at master · openark/orchestrator · GitHub
-
orchestrator/failure-detection.md at master · openark/orchestrator · GitHub
非常に便利な機能なのですが、ドキュメントの説明が少し複雑な印象を受けました。
本記事では、内容をもう少し分かりやすく整理してみようと思います。
準同期レプリケーションフラグパラメータについての注意
と、その前に Orchestrator で準同期レプリケーションを扱う際の注意事項をひとつ挙げておきます。
MySQL 8.0.26 から、新用語への切替えでインストールプラグイン名が変更された rpl_semi_sync_source(semisync_source.so), rpl_semi_sync_replica(semisync_replica.so) が提供されています。
これらのプラグインを指定して MySQL Server に準同期レプリケーション機能をインストールした場合、システム変数名も master/slave から source/replica に置き換えられます。
つまり、従来の master/slave と付く変数を参照できなくなります。
Orchestrator はこの編素名の変更にまだ対応していないため、準同期レプリケーションの設定を参照するときは依然として master/slave を使ってしまい適切に情報を取得できない問題が生じます。
よって、現時点(v3.2.6)ではまだ従前のインストールプラグインを使う必要がある点、注意してください。
※Issue は挙がっていますので、将来的に対応されることを期待しています。
Support new semi-sync variables in MySQL 8.0.26 · Issue #1416 · openark/orchestrator · GitHub
4つの関連パラメータと2つの障害分析
準同期レプリケーショントポロジーの管理機能は、4つのパラメータによって制御します。
関連パラメータ
EnforceExactSemiSyncReplicas
フラグ値で、有効にすると LockedSemiSyncMaster と MasterWithTooManyReplicas という障害分析のリカバリにおいて、優先順位に基づいて希望するトポロジーに正確に一致するようにレプリカの準同期フラグ(rpl_semi_sync_slave_enabled)を ON/OFF するようになります。
※LockedSemiSyncMaster と MasterWithTooManyReplicasについては後述します。
RecoverLockedSemiSyncMaster
フラグ値で、有効にすると LockedSemiSyncMaster のリカバリ時に rpl_semi_sync_master_wait_for_slave_count に合わせた優先順位でレプリカの準同期フラグ(rpl_semi_sync_slave_enabled)を ON にするようになります。
上記の EnforceExactSemiSyncReplicas との違いは、レプリカの準同期フラグを OFF にはしない、ということです。
トポロジー内の準同期レプリカ数が不足した場合のみ、動作させたい場合に用います。(多い場合減らすことはしない分、EnforceExactSemiSyncReplicasと比べて緩いルールということになります)
そのため、EnforceExactSemiSyncReplicas が併せて設定されている場合、EnforceExactSemiSyncReplicas のほうが優先されます。
DetectSemiSyncEnforcedQuery
インスタンスごとの準同期設定の優先度を返すクエリを設定します。
0 は非同期レプリカを意味し、数値が大きいほど優先度が高くなります。
例えば、以下のようなレプリケーションクラスタごとにデータベース側に定義情報テーブルを設定する方法の場合、
|
1 2 3 4 5 6 7 8 9 10 |
mysql> select * from meta.semi_sync; +----------------+----------+ | cluster_member | priority | +----------------+----------+ | db-01 | 2 | | db-02 | 2 | | db-03 | 1 | | db-04 | 1 | | db-05 | 0 | +----------------+----------+ |
priority 値を取得するクエリをパラメータに設定します。
|
1 |
"DetectSemiSyncEnforcedQuery": "select priority from meta.semi_sync where cluster_member = @@hostname", |
優先度は従来のプロモーションルール(DetectPromotionRuleQuery)とも組み合わせて定義することが可能です。(後述)
また、ソースのフェイルオーバーが発生したとき、昇格する新ソースサーバの DetectSemiSyncEnforcedQuery で返される優先度が 1 以上であれば、rpl_semi_sync_master_enabled = ON が自動設定されるようになります。
ReasonableLockedSemiSyncMasterSeconds
LockedSemiSyncMaster 状態が発生するまでの秒数を指定します。
設定されていない場合、 ReasonableReplicationLagSeconds にフォールバックします。
障害分析
Orchestrator がレプリケーショントポロジーの異常を検知した際に、収集した各インスタンスの状態を Orchestrator が診断・分析します。
orchestrator/failure-detection.md at master · openark/orchestrator · GitHub
障害分析の種類に応じたリカバリが行われ、その種類は多数存在します。
今回の機能では LockedSemiSyncMaster と MasterWithTooManyReplicas の検知後行われるリカバリアクションによって作動します。
LockedSemiSyncMaster
以下の条件に全て合致すると、準同期ソースが書き込みロック状態に陥っていると判断されます。
- 準同期ソースが稼働中
rpl_semi_sync_master_enabled=1 - 準同期レプリカが
rpl_semi_sync_master_wait_for_slave_countの規定数より不足している rpl_semi_sync_master_timeoutが十分に高い時間に設定されていて、準同期レプリカからの ACK が返ってこないことにより非同期レプリケーションにフォールバックしない。
この状況に陥ると、何も対処しない限り rpl_semi_sync_master_timeout を経過するまでソースで全てのトランザクションがブロックされてしまうので、大きな障害となります。
準同期レプリケーションを使用するうえで、気を付けるべき重大な事態でしょう。
取り得る対処方法としては、準同期ソース設定を無効化するか、準同期レプリカを rpl_semi_sync_master_wait_for_slave_count の数分有効にすることになります。
Orchestrator はデフォルトでこの状況を障害分析として検知はしますが、警告メッセージを表示するのみで何のアクションも行いません。
本機能(EnforceExactSemiSyncReplicas または RecoverLockedSemiSyncMaster)を有効にすることで、Orchestrator はリカバリ処理を行うようになります。
Orchestrator が LockedSemiSyncMaster と判定するまでの時間は ReasonableLockedSemiSyncMasterSeconds で設定します。
設定されていない場合、 ReasonableReplicationLagSeconds が用いられることになりますが、このパラメータはレプリケーション遅延発生時異常とみなす時間を設定するものですので、準同期ソースのロック状態検知は別の検知時間として ReasonableLockedSemiSyncMasterSeconds を明示的に設定しておいたほうが柔軟かと考えます。
MasterWithTooManySemiSyncReplicas
以下の条件に全て合致すると、こちらは文字通り準同期レプリカ数が過多になっていると判断されます。
- 準同期ソースが稼働中
rpl_semi_sync_master_enabled=1 - 準同期レプリカが
rpl_semi_sync_master_wait_for_slave_countの規定数より多くなっている EnforceExactSemiSyncReplicasが有効になっている
EnforceExactSemiSyncReplicas と RecoverLockedSemiSyncMaster 2つのフラグパラメータの設定パターンによって MasterWithTooManySemiSyncReplicas がトリガされるかが異なってきますので、多少分かり辛い印象です。
設定パターンごとに表にまとめてみました。

いずれかのフラグを ON にする設定方法が分かり易いのではと思います。
優先順位の決定方法について
準同期の優先順位は以下の順によって定義されます。
DetectSemiSyncEnforcedQueryで取得した数値(数字が大きいほど優先度が高い)- プロモーションルール(
DetectPromotionRuleQuery) - ホスト名
- 枝番が振られている場合、若いほうが優先度が高い
プロモーションルールのみで準同期の管理優先度も制御したい場合は、DetectSemiSyncEnforcedQuery には固定値(select 100など)を設定すると、プロモーションルールで決定させることができるようになります。
|
1 2 |
"DetectSemiSyncEnforcedQuery": "select 100", "DetectPromotionRuleQuery": "select promotion_rule from meta.promotion_rules where cluster_member = @@hostname", |
動作検証
では実際に以下のレプリケーショントポロジーで機能確認してみたいと思います。
分かりづらいですが、赤枠で囲った部分が準同期フラグを表しています。
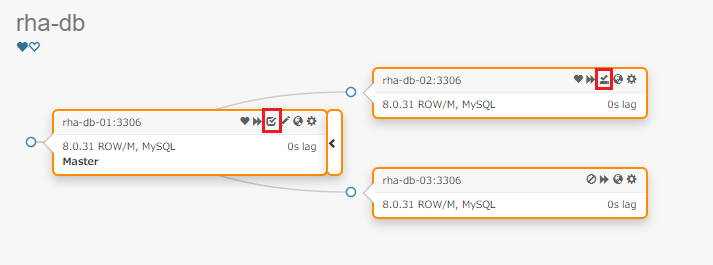
準同期レプリケーションの設定(フラグと優先度)、およびプロモーションルールの設定は以下のようになっています。
|
1 2 3 4 |
[root@rha-orc-03 ~]# orchestrator-client -c topology --alias rha-db rha-db-01:3306 [0s,ok,8.0.31,rw,ROW,>>,GTID,semi:master] + rha-db-02:3306 [0s,ok,8.0.31,ro,ROW,>>,GTID,semi:replica] + rha-db-03:3306 [0s,ok,8.0.31,ro,ROW,>>,GTID] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
mysql> select @@GLOBAL.rpl_semi_sync_master_wait_for_slave_count,@@GLOBAL.rpl_semi_sync_master_timeout; +----------------------------------------------------+---------------------------------------+ | @@GLOBAL.rpl_semi_sync_master_wait_for_slave_count | @@GLOBAL.rpl_semi_sync_master_timeout | +----------------------------------------------------+---------------------------------------+ | 1 | 3600000 | +----------------------------------------------------+---------------------------------------+ 1 row in set (0.00 sec) mysql> select * from semi_sync; +----------------+----------+ | cluster_member | priority | +----------------+----------+ | rha-db-01 | 2 | | rha-db-02 | 2 | | rha-db-03 | 1 | +----------------+----------+ 3 rows in set (0.00 sec) mysql> select * from promotion_rules; +----------------+----------------+ | cluster_member | promotion_rule | +----------------+----------------+ | rha-db-01 | prefer | | rha-db-02 | prefer | | rha-db-03 | must_not | +----------------+----------------+ 3 rows in set (0.00 sec) |
データの耐久性を担保するため rpl_semi_sync_master_timeout を非常に長いタイムアウト値に設定し、非同期レプリケーションへフォールバックさせない設計です。
今回は EnforceExactSemiSyncReplicas を有効にする設定で、LockedSemiSyncMaster と MasterWithTooManyReplicas それぞれを検知・リカバリする流れを確認していきます。
|
1 2 3 |
"DetectSemiSyncEnforcedQuery": "select priority from meta.semi_sync where cluster_member = @@hostname", "EnforceExactSemiSyncReplicas": true, "ReasonableLockedSemiSyncMasterSeconds": 60, |
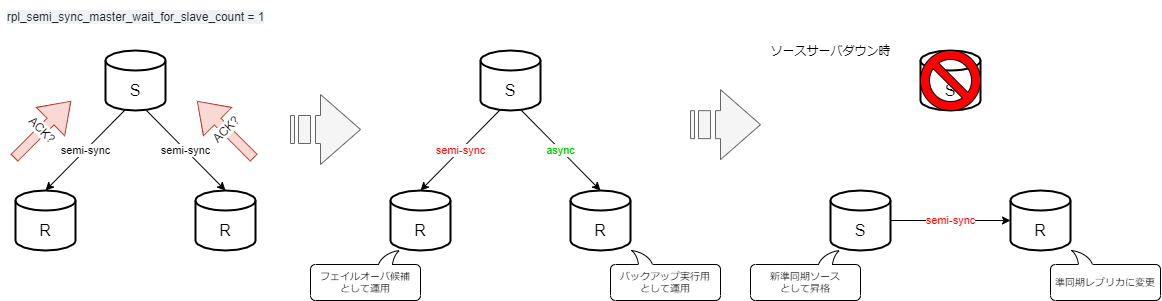
ソースサーバダウン時
この場合、rha-db-01(ソース)のフェイルオーバー後、結果的に以下のように自動的に再構成されることを期待します。
- rha-db-02 :準同期レプリカ → 準同期ソース
- rha-db-03 :非同期レプリカ → 準同期レプリカ
RecoveryPeriodBlockSeconds と ReasonableLockedSemiSyncMasterSeconds の調整
ここで、この検証を行う前に、設定上の注意点を挙げておきます。
Orchestrator はアンチフラッピング機構という仕組みを持ちます。
リカバリが発生したあと、さらに障害が連鎖的に発生し、継続的な停止やリソースの枯渇を招くのを回避するため、同一クラスタにおいて、一定期間再びリカバリが実行されないようにするブロック期間(RecoveryPeriodBlockSeconds)が設けられています。
RecoveryPeriodBlockSeconds で指定した時間が経過するか、ブロックされたリカバリを手動で承認する(管理画面上から実施、または orchestrator-client コマンドから発行)することで解除されます。
ソースフェイルオーバーは、DeadMaster のリカバリによって動作します。
そして、前述の通り準同期レプリカのフラグを変更する本機能は、LockedSemiSyncMaster のリカバリとして作動します。
つまり、DeadMaster のリカバリ完了後、そのフラッピングブロックが解除されないと、LockedSemiSyncMaster を検知していてもリカバリが作動しないのです。
RecoveryPeriodBlockSeconds はデフォルト 3600(秒) = 1時間です。
このパラメータはシステムの SLA や予測される障害発生頻度によって、設定値を検討すべき内容ではありますが、
ソースフェイルオーバー後に準同期レプリカフラグ変更機能が動作するには、DeadMaster のブロック解除後に LockedSemiSyncMaster の検出およびリカバリが働くように、
RecoveryPeriodBlockSeconds < ReasonableLockedSemiSyncMasterSeconds
という関係性でパラメータを調整する必要があります。
例えば、ソースフェイルオーバー完了から即時準同期レプリカを自動構成させたいのであれば、以下の設定の組み合わせになります。
|
1 2 |
"RecoveryPeriodBlockSeconds": 1, "ReasonableLockedSemiSyncMasterSeconds": 2 |
この場合、アンチフラッピング機能を無効にするのと同等ですので、システムの障害発生時要件を踏まえてどのような選択を採るかを検討してください。
実際の挙動を確認する
それでは、上記の注意点を踏まえ、改めてパラメータを以下のように変更してソースフェイルオーバーを発生させてみましょう。
|
1 2 |
"RecoveryPeriodBlockSeconds": 59, "ReasonableLockedSemiSyncMasterSeconds": 60 |
まずは rha-db-01 をシャットダウンします。
|
1 2 3 4 |
[root@rha-db-01 ~]# date;shutdown -h now Tue Nov 29 18:09:11 JST 2022 Connection to 192.168.30.152 closed by remote host. Connection to 192.168.30.152 closed. |
UnreachableMaster が検知されました。
|
1 |
2022-11-29 18:09:17 INFO executeCheckAndRecoverFunction: proceeding with UnreachableMaster detection on rha-db-01:3306; isActionable?: false; skipProcesses: false |
その後 DeadMaster 判定となり、リカバリ(フェイルオーバー)が作動します。
rha-db-02 は以下のタイミングで準同期ソースフラグが ON になります。
|
1 |
2022-11-29 18:09:21 INFO topology_recovery: - RecoverDeadMaster: will apply MySQL changes to promoted master |
フェイルオーバーリカバリ中、準同期フラグ管理機能のバックグラウンドチェック処理が動いていることが確認できます。
ただし、まだリカバリは完了していないので、この時点でのアクションはありません。
|
1 2 3 4 5 6 7 |
2022-11-29 18:09:21 DEBUG semi-sync: analysis results for recovery of cluster rha-db-01:3306: 2022-11-29 18:09:21 DEBUG semi-sync: master = rha-db-02:3306, master semi-sync wait count = 1, master semi-sync replica count = 0 2022-11-29 18:09:21 DEBUG semi-sync: possible semi-sync replicas (in priority order): (none) 2022-11-29 18:09:21 DEBUG semi-sync: always-async replicas: (none) 2022-11-29 18:09:21 DEBUG semi-sync: excluded replicas (defunct): (none) 2022-11-29 18:09:21 DEBUG semi-sync: suggested actions: (none) 2022-11-29 18:09:21 INFO semi-sync: rha-db-03:3306: no action taken; this may lead to future recoveries |
フェイルオーバーが完了したあと、LockedSemiSyncMasterHypothesis という分析が確認されました。
文字通り、LockedSemiSyncMaster 状態発生の疑いがある、ということを Orchestrator が検出しています。
|
1 2 3 |
2022-11-29 18:09:21 INFO topology_recovery: Completed PostFailoverProcesses hook 1 of 1 in 3.48312ms : 2022-11-29 18:09:22 INFO auditType:emergently-read-topology-instance instance:rha-db-02:3306 cluster:rha-db-01:3306 message:LockedSemiSyncMasterHypothesis |
具体的には、ソースサーバのバイナリログ座標(ファイルとポジション)が動かずに ReasonableLockedSemiSyncMasterSeconds 時間経過すると、LockedSemiSyncMaster が確定します。
フェイルオーバーから約1分(ReasonableLockedSemiSyncMasterSeconds)後に LockedSemiSyncMaster のリカバリが動き出しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
2022-11-29 18:10:23 INFO executeCheckAndRecoverFunction: proceeding with LockedSemiSyncMaster recovery on rha-db-02:3306; isRecoverable?: true; skipProcesses: false 2022-11-29 18:10:23 DEBUG semi-sync: analysis results for recovery of cluster rha-db-02:3306: 2022-11-29 18:10:23 DEBUG semi-sync: master = rha-db-02:3306, master semi-sync wait count = 1, master semi-sync replica count = 0 2022-11-29 18:10:23 DEBUG semi-sync: possible semi-sync replicas (in priority order): 2022-11-29 18:10:23 DEBUG semi-sync: - rha-db-03:3306: semi-sync enabled = false, priority = 1, promotion rule = must_not, last check = true, replicating = true 2022-11-29 18:10:23 DEBUG semi-sync: always-async replicas: (none) 2022-11-29 18:10:23 DEBUG semi-sync: excluded replicas (defunct): (none) 2022-11-29 18:10:23 DEBUG semi-sync: suggested actions: 2022-11-29 18:10:23 DEBUG semi-sync: - rha-db-03:3306: should set semi-sync enabled = true 2022-11-29 18:10:23 INFO topology_recovery: semi-sync: taking actions: 2022-11-29 18:10:23 INFO topology_recovery: semi-sync: - rha-db-03:3306: setting rpl_semi_sync_slave_enabled=true, restarting slave_io thread 2022-11-29 18:10:23 INFO topology_recovery: semi-sync: recovery complete; success = true |
メッセージから rha-db-03 に対して rpl_semi_sync_slave_enabled=true が設定(反映のため I/O スレッドも再起動)されたことが確認できます。
トポロジーを確認してみましょう。GUI管理画面では準同期ソース・レプリカのフラグがアイコンで示されますが、若干視認性に欠けるので、CLI で確認してみます。
以下の通り、準同期ソース・レプリカのフラグが意図した構成で有効になっているのが確認できました。
|
1 2 3 |
[root@rha-orc-01 ~]# orchestrator-client -c topology -alias rha-db rha-db-02:3306 [0s,ok,8.0.31,rw,ROW,>>,GTID,semi:master] + rha-db-03:3306 [0s,ok,8.0.31,ro,ROW,>>,GTID,semi:replica] |
そして RecoverLockedSemiSyncMaster リカバリが完了したので、フラッピングブロック期間に入ります。
|
1 2 3 |
2022-11-29 18:10:24 ERROR AttemptRecoveryRegistration: instance rha-db-02:3306 has recently been promoted (by failover of rha-db-02:3306) and is in active period. It will not be failed over. You may acknowledge the failure on rha-db-02:3306 (-c ack-instance-recoveries) to remove this blockage 2022-11-29 18:10:24 INFO topology_recovery: found an active or recent recovery on rha-db-02:3306. Will not issue another RecoverLockedSemiSyncMaster. 2022-11-29 18:10:24 ERROR 2022-11-29 18:10:24 ERROR AttemptRecoveryRegistration: instance rha-db-02:3306 has recently been promoted (by failover of rha-db-02:3306) and is in active period. It will not be failed over. You may acknowledge the failure on rha-db-02:3306 (-c ack-instance-recoveries) to remove this blockage |
準同期レプリカダウン時
唯一の準同期レプリカがダウンし、準同期レプリカがロック状態になるケースです。
|
1 2 3 4 |
[root@rha-db-02 ~]# date;shutdown -h now Thu Dec 1 19:23:19 JST 2022 Connection to 192.168.30.45 closed by remote host. Connection to 192.168.30.45 closed. |
rha-db-02 ダウン直後、rha-db-03 はまだ非同期レプリカです。
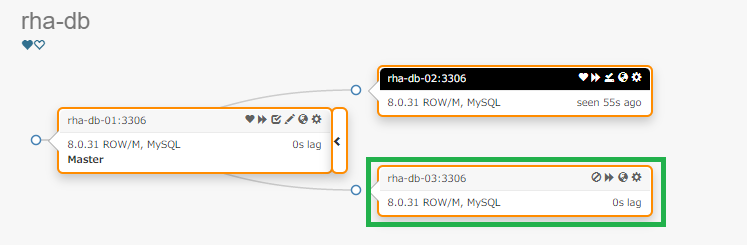
shutdown 実行から 2秒後に Orchestrator は rha-db-03 の異常を検知しました。
|
1 |
2022-12-01 19:23:21 WARNING DiscoverInstance(rha-db-02:3306) instance is nil in 0.008s (Backend: 0.005s, Instance: 0.003s), error=Error 1053: Server shutdown in progress |
その 7秒後、LockedSemiSyncMasterHypothesis として LockedSemiSyncMaster 嫌疑がかけられます。
|
1 |
2022-12-01 19:23:28 WARNING executeCheckAndRecoverFunction: ignoring analysisEntry that has no action plan: LockedSemiSyncMasterHypothesis; key: rha-db-01:3306 |
そこから約1分後に LockedSemiSyncMaster として判断され、リカバリの進行が開始されます。
本機能が作動し、rha-db-03 に rpl_semi_sync_slave_enabled=true を設定したことが確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
2022-12-01 19:24:29 INFO executeCheckAndRecoverFunction: proceeding with LockedSemiSyncMaster recovery on rha-db-01:3306; isRecoverable?: true; skipProcesses: false 2022-12-01 19:24:29 DEBUG semi-sync: analysis results for recovery of cluster rha-db-01:3306: 2022-12-01 19:24:29 DEBUG semi-sync: master = rha-db-01:3306, master semi-sync wait count = 1, master semi-sync replica count = 0 2022-12-01 19:24:29 DEBUG semi-sync: possible semi-sync replicas (in priority order): 2022-12-01 19:24:29 DEBUG semi-sync: - rha-db-03:3306: semi-sync enabled = false, priority = 1, promotion rule = must_not, last check = true, replicating = true 2022-12-01 19:24:29 DEBUG semi-sync: always-async replicas: (none) 2022-12-01 19:24:29 DEBUG semi-sync: excluded replicas (defunct): (none) 2022-12-01 19:24:29 DEBUG semi-sync: suggested actions: 2022-12-01 19:24:29 DEBUG semi-sync: - rha-db-03:3306: should set semi-sync enabled = true 2022-12-01 19:24:29 INFO topology_recovery: semi-sync: taking actions: 2022-12-01 19:24:29 INFO topology_recovery: semi-sync: - rha-db-03:3306: setting rpl_semi_sync_slave_enabled=true, restarting slave_io thread [mysql] 2022/12/01 19:24:29 packets.go:123: closing bad idle connection: unexpected read from socket 2022-12-01 19:24:29 INFO topology_recovery: semi-sync: recovery complete; success = true |
リカバリ後のトポロジーを確認します。
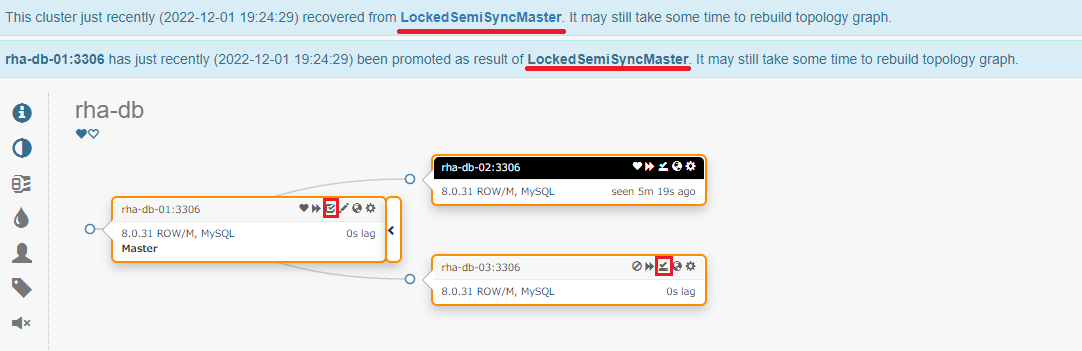
|
1 2 3 4 5 |
[root@rha-orc-01 rha-orc-01]# date '+%F %T';orchestrator-client -c topology -alias rha-db 2022-12-01 19:40:14 rha-db-01:3306 [0s,ok,8.0.31,rw,ROW,>>,GTID,semi:master] - rha-db-02:3306 [unknown,invalid,8.0.31,ro,ROW,>>,GTID,semi:replica] + rha-db-03:3306 [0s,ok,8.0.31,ro,ROW,>>,GTID,semi:replica] |
準同期レプリケーション構成を保ちつつ、ソースサーバのロック状態を復旧させるという、期待通りの挙動となりました。
準同期レプリカが増えた場合
今度は MasterWithTooManySemiSyncReplicas をリカバリさせてみます。
さきほどダウンさせた rha-db-02 を復旧させて…
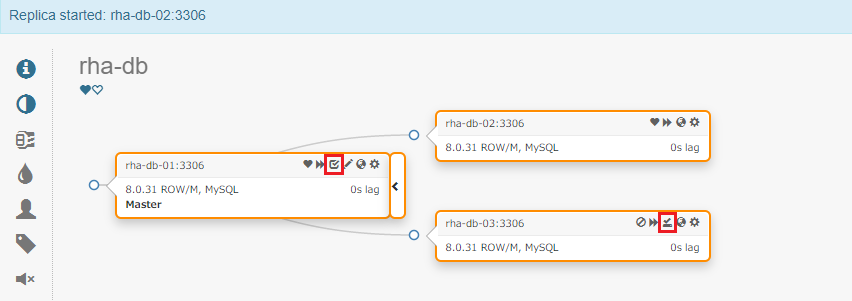
準同期レプリカを手動で有効にします。
|
1 2 3 4 5 6 |
[root@rha-orc-02 ~]# orchestrator-client -c enable-semi-sync-replica -i rha-db-02:3306 rha-db-02:3306 [root@rha-orc-02 ~]# orchestrator-client -c topology -alias rha-db rha-db-01:3306 [0s,ok,8.0.31,rw,ROW,>>,GTID,semi:master] - rha-db-02:3306 [null,nonreplicating,8.0.31,ro,ROW,>>,GTID,semi:replica] + rha-db-03:3306 [0s,ok,8.0.31,ro,ROW,>>,GTID,semi:replica] |
上記だと変更したタイミングが不明ですが、rha-db-02 の MySQL エラーログから I/O スレッドの再開時刻が確認できました。
|
1 |
2022-12-01T20:06:39.236217+09:00 853 [System] [MY-010562] [Repl] Slave I/O thread for channel '': connected to master 'repl@rha-db-01:3306',replication started in log 'mysql-bin.000018' at position 237 |
準同期レプリカを有効にした3秒後に MasterWithTooManySemiSyncReplicas を検知し、リカバリが開始されました。
ここでは、どの準同期レプリカのフラグを OFF にするかの判断が行われているのが分かります。
準同期プライオリティが低い rha-db-03 が rpl_semi_sync_slave_enabled=false となる想定(事前定義通りの)結果となりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
2022-12-01 20:06:44 INFO executeCheckAndRecoverFunction: proceeding with MasterWithTooManySemiSyncReplicas detection on rha-db-01:3306; isActionable?: true; skipProcesses: false 2022-12-01 20:06:44 INFO checkAndExecuteFailureDetectionProcesses: could not register MasterWithTooManySemiSyncReplicas detection on rha-db-01:3306 2022-12-01 20:06:44 INFO executeCheckAndRecoverFunction: proceeding with MasterWithTooManySemiSyncReplicas recovery on rha-db-01:3306; isRecoverable?: true; skipProcesses: false 2022-12-01 20:06:44 DEBUG semi-sync: analysis results for recovery of cluster rha-db-01:3306: 2022-12-01 20:06:44 DEBUG semi-sync: master = rha-db-01:3306, master semi-sync wait count = 1, master semi-sync replica count = 2 2022-12-01 20:06:44 DEBUG semi-sync: possible semi-sync replicas (in priority order): 2022-12-01 20:06:44 DEBUG semi-sync: - rha-db-02:3306: semi-sync enabled = true, priority = 2, promotion rule = prefer, last check = true, replicating = true 2022-12-01 20:06:44 DEBUG semi-sync: - rha-db-03:3306: semi-sync enabled = true, priority = 1, promotion rule = must_not, last check = true, replicating = true 2022-12-01 20:06:44 DEBUG semi-sync: always-async replicas: (none) 2022-12-01 20:06:44 DEBUG semi-sync: excluded replicas (defunct): (none) 2022-12-01 20:06:44 DEBUG semi-sync: suggested actions: 2022-12-01 20:06:44 DEBUG semi-sync: - rha-db-03:3306: should set semi-sync enabled = false 2022-12-01 20:06:44 INFO topology_recovery: semi-sync: taking actions: 2022-12-01 20:06:44 INFO topology_recovery: semi-sync: - rha-db-03:3306: setting rpl_semi_sync_slave_enabled=false, restarting slave_io thread 2022-12-01 20:06:44 INFO topology_recovery: semi-sync: recovery complete; success = true |
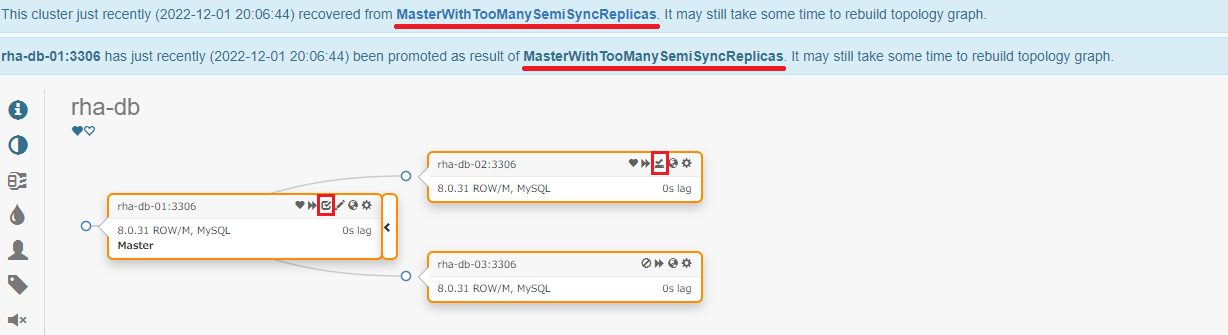
おまけ:SemiSyncEnforced
実は以前から SemiSyncEnforced というパラメータは(DetectSemiSyncEnforcedQuery も併せて)存在していました。
一見今回の機能と同じ意味かと思いきや…
これはフェイルオーバー終了時にレプリケーション再接続される際に準同期レプリカの設定を行うという機能で、今回のようにフェイルオーバーが発生しないケースの状態の変化に対応する機能ではありませんでした。
そこで、今回ニーズに応じて改めて再設計されたという経緯があるようです。(以下の Isuue を参照)
ちなみに GUI 画面のインスタンス詳細画面をポップアップさせると、Semi-sync enforced という項目が表示されていますが、これは古い実装の名残りで、もう使われなくなった SemiSyncEnforced の値を UI はまだ参照しているため実際の設定値と異なる値が表示されてしまうのです。
将来修正されるまでは無視して構いません。
まとめ
Orchestrator の新機能(といってもリリースから1年以上経過していますが…)、準同期レプリケーションのフラグ制御機能について、詳細に確認してみました。
実装上、フェイルオーバー後のアンチフラッピング時間を調整する必要がある点は考慮が必要ですが、準同期レプリケーショントポロジー維持・運用管理の利便性向上に大いに期待できます。
この機能を含む v3.2.6 のリリース(2021年7月)直前に、Orchestrator の開発者 Shlomi Noach氏はご自身の状況によりこのバージョン以降の開発・リリースの手を休めるという声明を発表されました。
Reducing my OSS involvement, and how it affects orchestrator & gh-ost – code.openark.org
それでもなお、MySQL レプリケーションのフェイルオーバーソリューションとして高いクオリティを持つ Orchestrator は MySQL ユーザの間で依然として人気を保っていると言えます。
また活発な開発が再開されることを期待しつつ、弊社としても今後も積極的に取り扱っていきたいと思います。