CData Syncを使ってAmazon S3のCSVファイルをOracle Cloud Infrastracture(OCI)に構築済みのMySQL HeatWaveDatabase Serviceに連携する
はじめに
CData Syncは様々なSaaS/DBにあるデータを抽出して、データ分析基盤への同期に特化したデータパイプラインツールです。
詳しくはこちらをご覧ください。
CData Syncの現在のバージョンは「v23」となります。
以前のバージョンから UIのモダナイズ、dbt Cloud 対応、CDC 強化、新コネクタなどユーザビリティと機能面が強化されています。
今回は、CData Syncを使ってAmazon S3バケット内のCSVファイルをOracle Cloud Infrastracture(OCI)に構築済みのMySQL HeatWaveDatabase Serviceに連携します。
OCIドキュメントでは、MySQL HeatWaveDatabase Serviceが正式名称ですが、今回は、このうちのOLTPエンジン部分にあたる旧来MySQL Database Service(以下「MDS」と表記)に対する連携となるため、本Blogでは、こちらの表現を利用します。
実現したい構成

パブリックサブネット内に配置されたコンピュート・インスタンスにインストールされたCData SyncでAmazon S3バケット内のCSVファイルのデータをMDSへ連携する。
前提条件
- コンピュート・インスタンスにCData Syncがインストール済みであること
詳しくはこちらをご覧ください。
LinuxOS:CData Sync v23をインストールしてみる
WindowsServer:CData Sync v23をWindows Serverにインストールしてみる - OCI上にMDSが構築済みであること
詳しくはこちらをご覧ください。
MySQL HeatWave Database Serviceについて
その9 – クラウドでMySQL Databaseを使う - パブリック・サブネット内のコンピュート・インスタンスからMDSへ接続が可能であること
- Amazon S3バケットが利用可能であること
Amazon S3について
Amazon S3 とは
手順
1.MDSコネクション設定
まずは同期先となるMDSのコネクション設定を行います。
1.1.MDSに格納用のDBを作成する
同期したAmazon S3からのインポートデータを格納するデータベースを事前にMDSに作成しておきます。
既存のデータベースにデータを格納することも可能です。
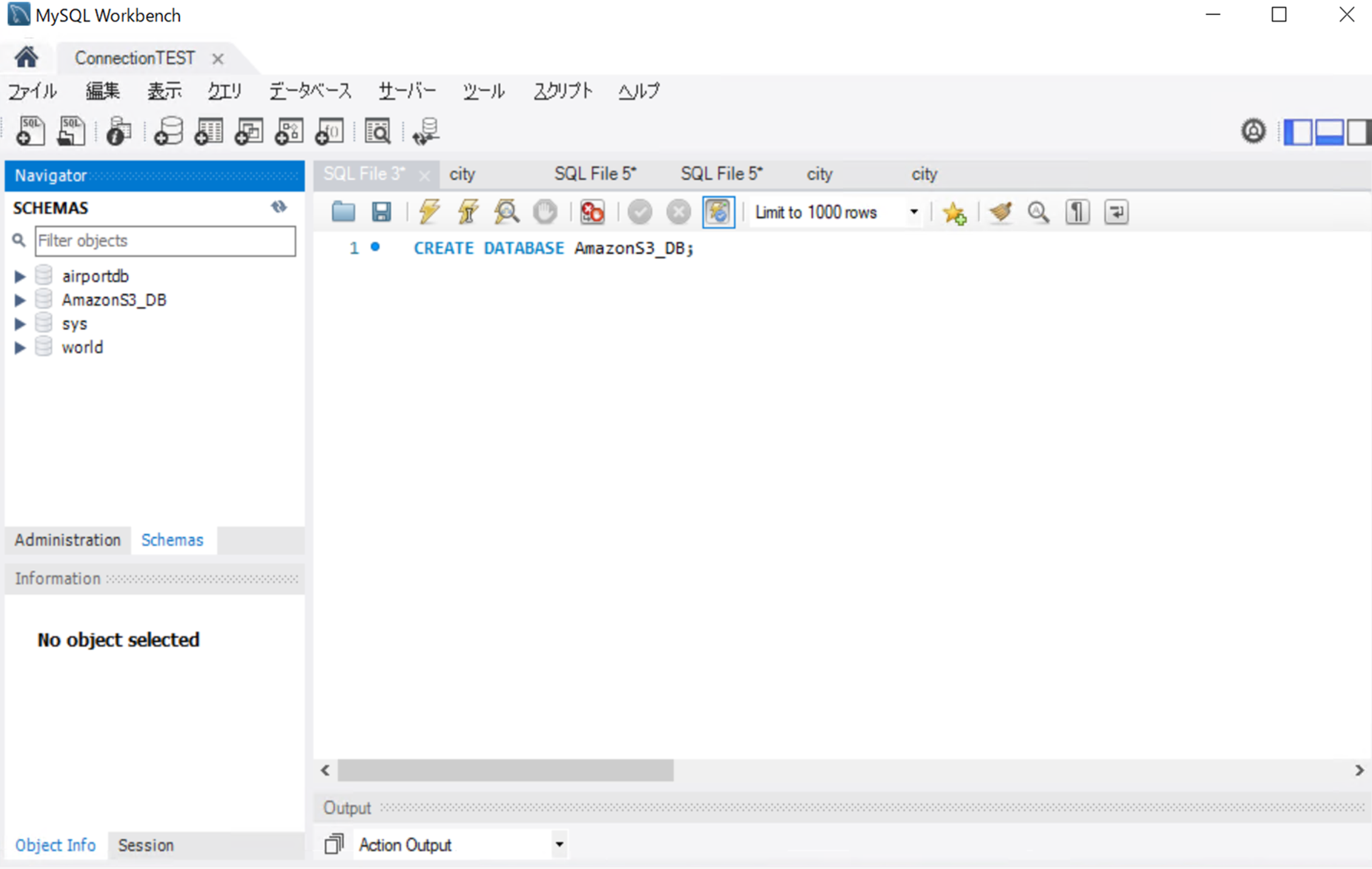
今回の場合は「AmazonS3_DB」という名前のデータベースを作成します。
コマンド例
mysql> CREATE DATABASE AmazonS3_DB;
1.2.CDataSyncのコネクタの設定
CDataSync管理コンソールにログイン後、左メニューの「接続」をクリックします。
「Connections」画面で「接続を追加」をクリックします。
「コネクタを選択」画面で「同期先」タブに切り替え、コネクタの一覧から「MySQL」を選択します。(今回は検索ワードでコネクタを検出しています)
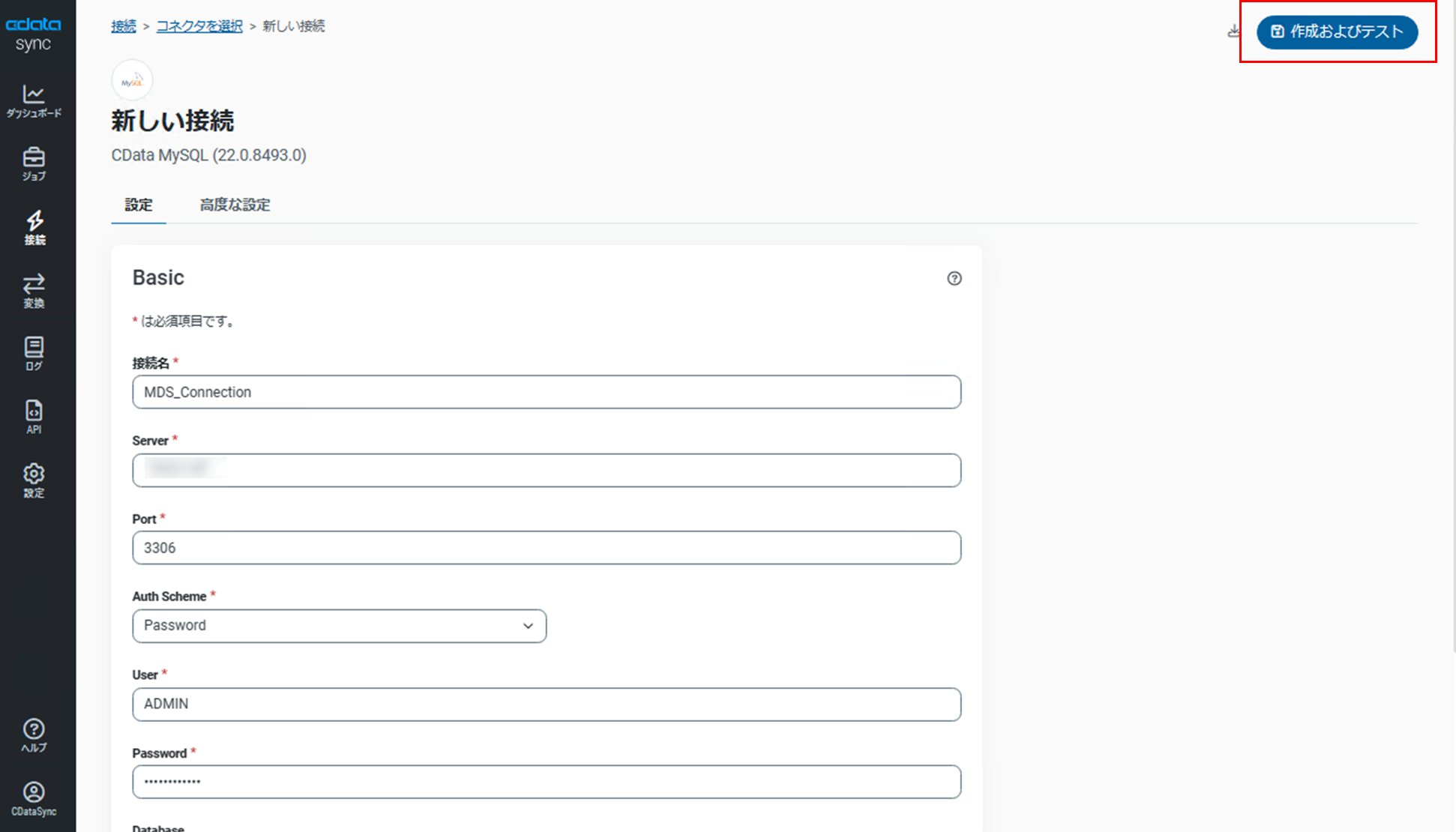
設定画面で以下の各項目を設定します。
・接続名:任意の接続名
・Connection Type:Data Source
・Server:MDSのIPアドレス
・Port:MDSのPort(デフォルトでは3306)
・Auth Scheme:「Password」を選択
・User:MDSの管理者ユーザまたはDB操作権限を持つユーザ※
・Password:MDSのPassword
・Database:同期データを格納するDBを指定
※本設定ではADMINユーザを使用して接続を行います。
設定画面の右上にある「保存およびテスト」をクリックします。
「接続は正常に作成されました」と表示されれば設定が完了となります。
「Connections」画面を開き、MDSの接続が作成されていることを確認します。
2.CSVコネクション設定
つぎにデータソースとなるAmazon S3(CSV)のコネクション設定を行います。
2.1.アクセスキーの取得
今回はAmazon S3のバケット内のCSVをデータソースとします。
そのためAmazon S3のバケットにアクセスするアクセスキーとシークレットキーが必要となります。
アクセスキーとシークレットキーの取得方法については下記のリンクをご覧ください。
2.2.CSVのコネクタ設定
CDataSync管理コンソールにログイン後、左メニューの「接続」をクリックします。
「Connections」画面で「接続を追加」をクリックします。
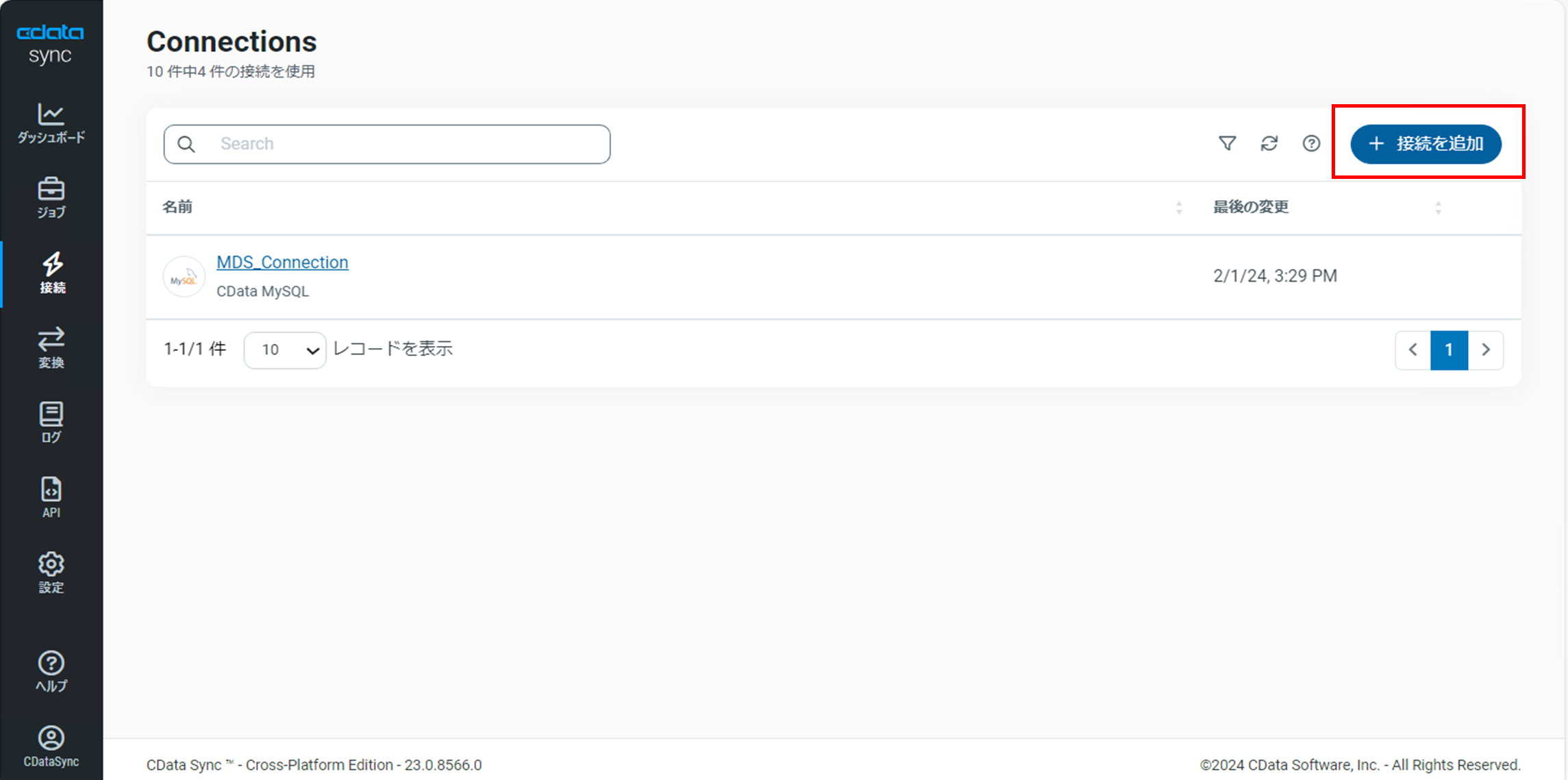
「コネクタを選択」画面で「データソース」タブになっていることを確認し、コネクタの一覧から「CSV」を選択します。(今回は検索ワードでコネクタを検出しています)
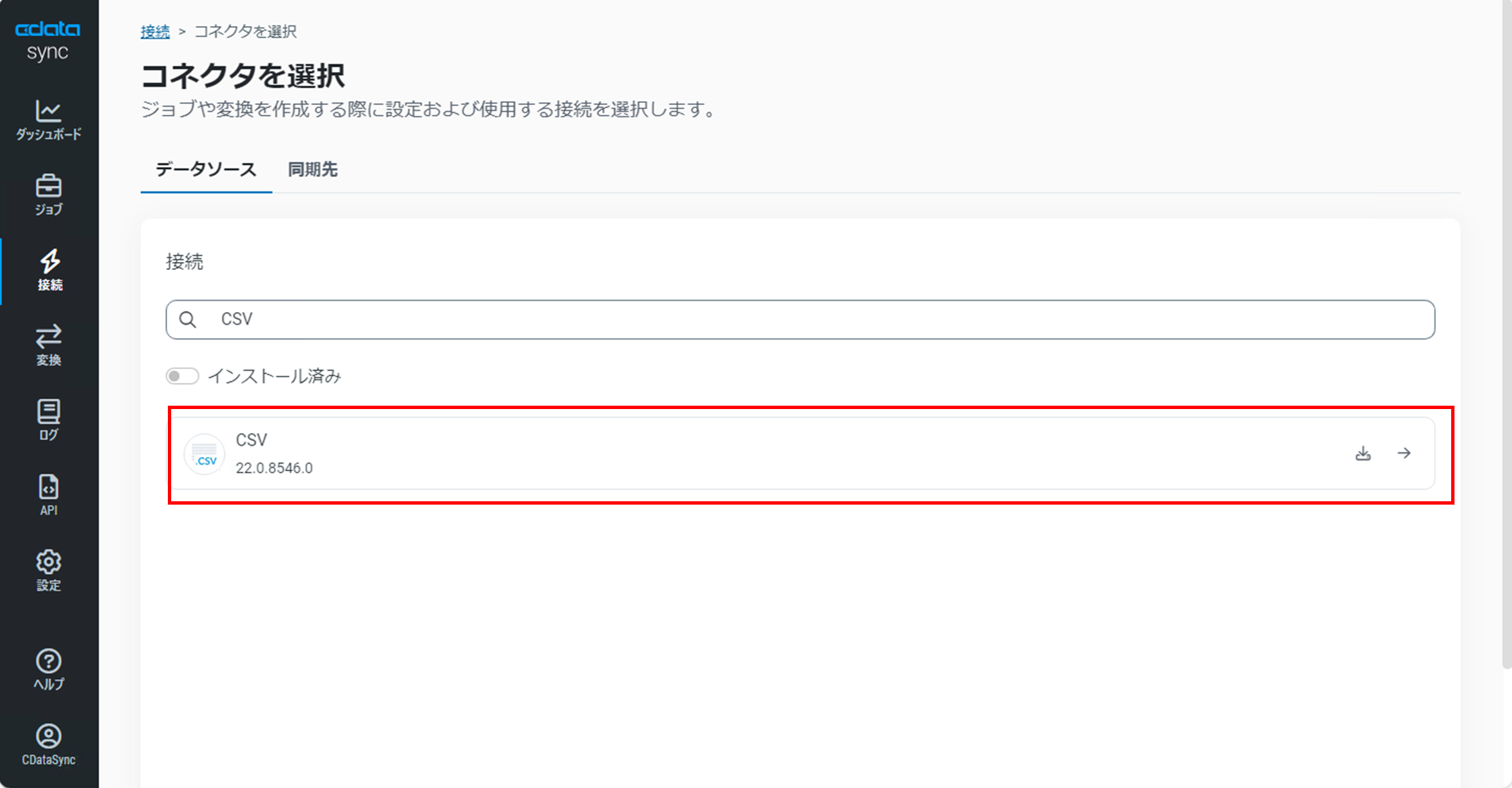
設定画面で以下の各項目を設定します。
・接続名:任意の接続名
・Connection Type:Amazon S3を選択
・AWS Region:AWS リージョンを指定
・Auth Scheme:AwsRpptKeysを選択
・AWS Access Key :IAMユーザーのアクセスキー
・AWS Secret Key:IAMユーザーのシークレットキー
・URI:対象のS3バケットのS3 URIを指定
・Aggregate Files:Falseを選択
・Include Column Headers:Trueを選択
設定画面の右上にある「保存およびテスト」をクリックします。
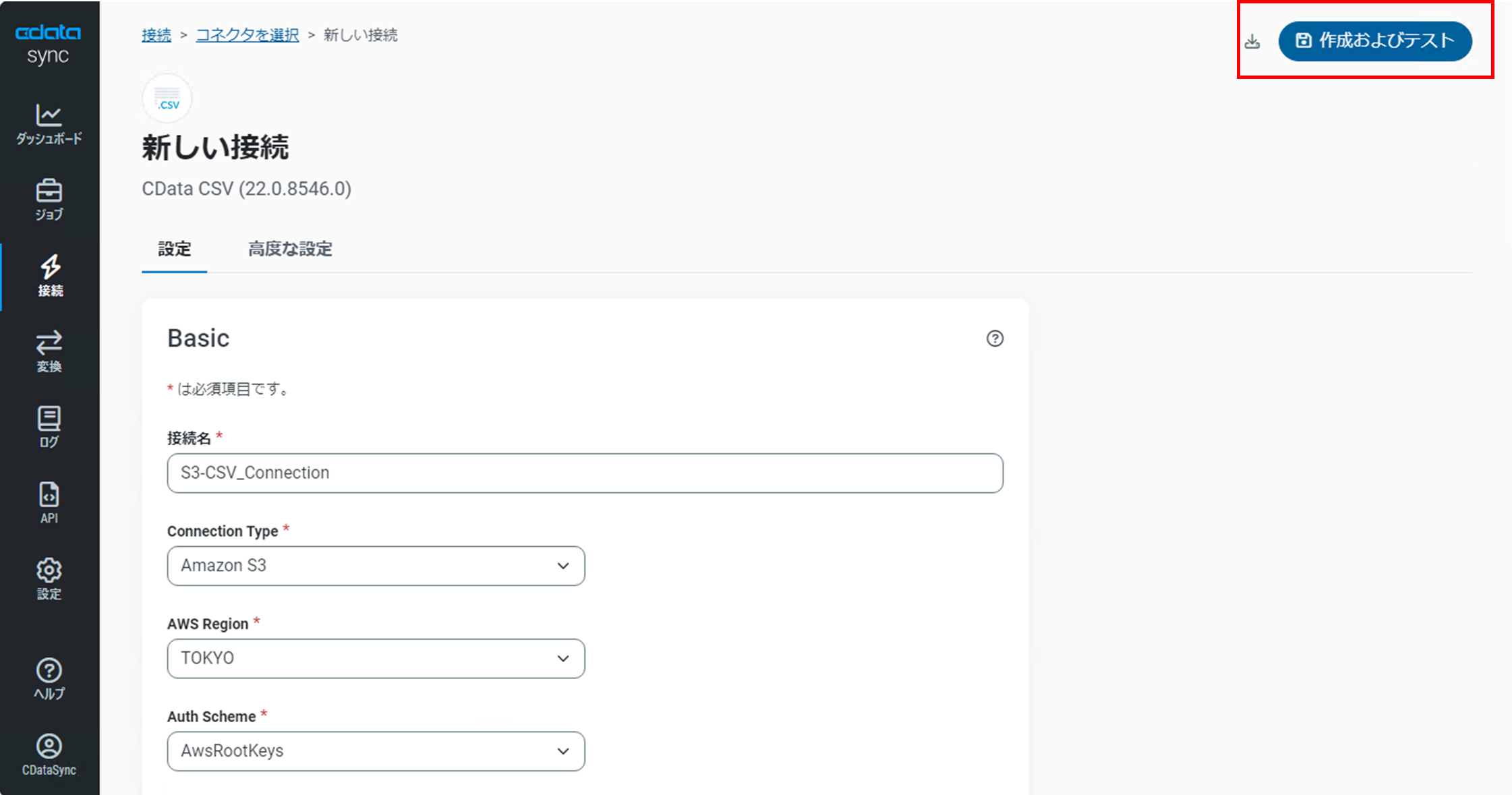
「接続は正常に作成されました」と表示されれば設定が完了となります。
「Connections」画面を開き、CSVの接続が作成されていることを確認します。
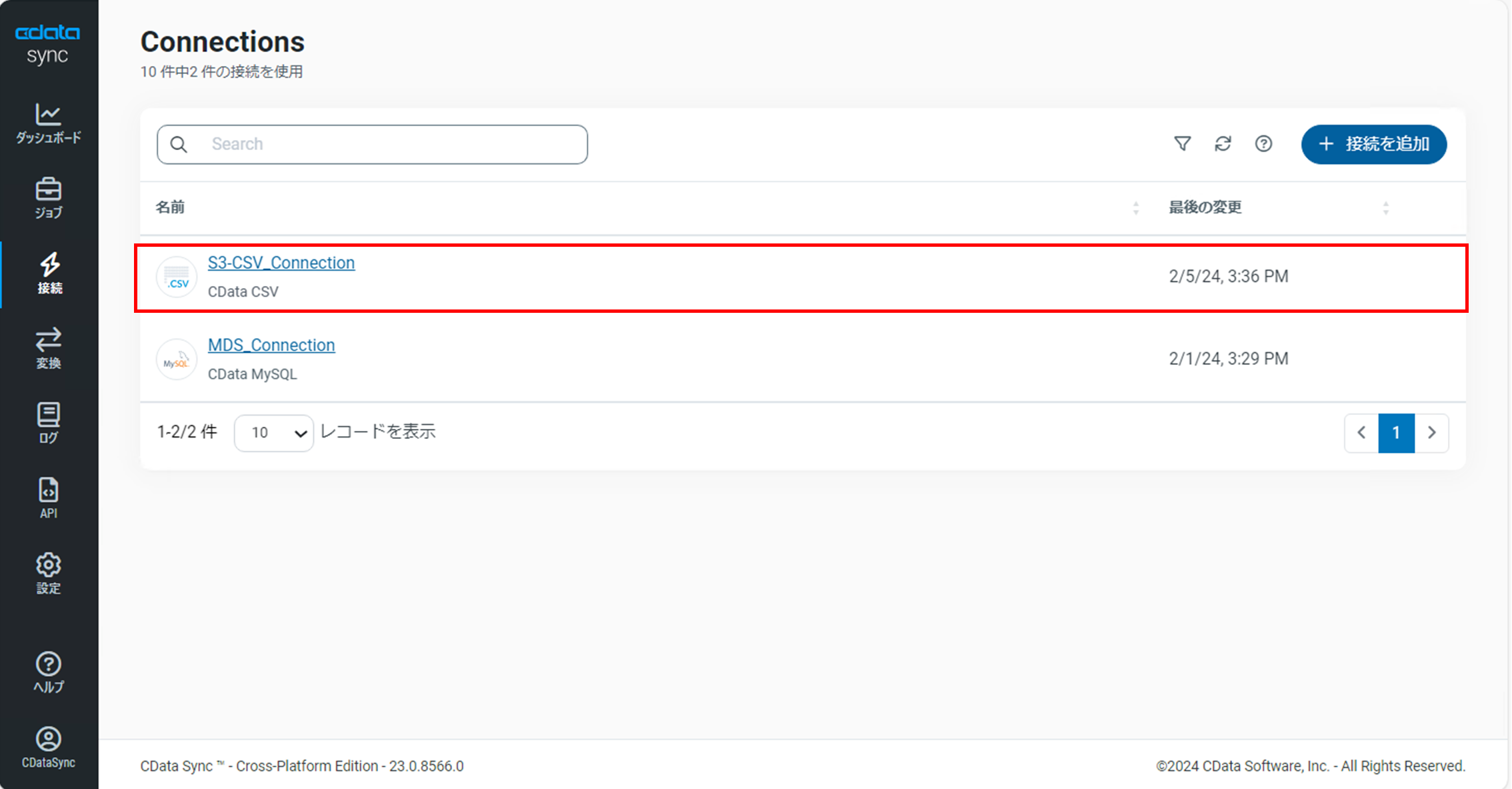
3.ジョブ設定
データソースと同期先のコネクション設定が完了したら、CSVからMDSへのデータ連携ジョブを作成します。
3.1.CData Syncのジョブの設定
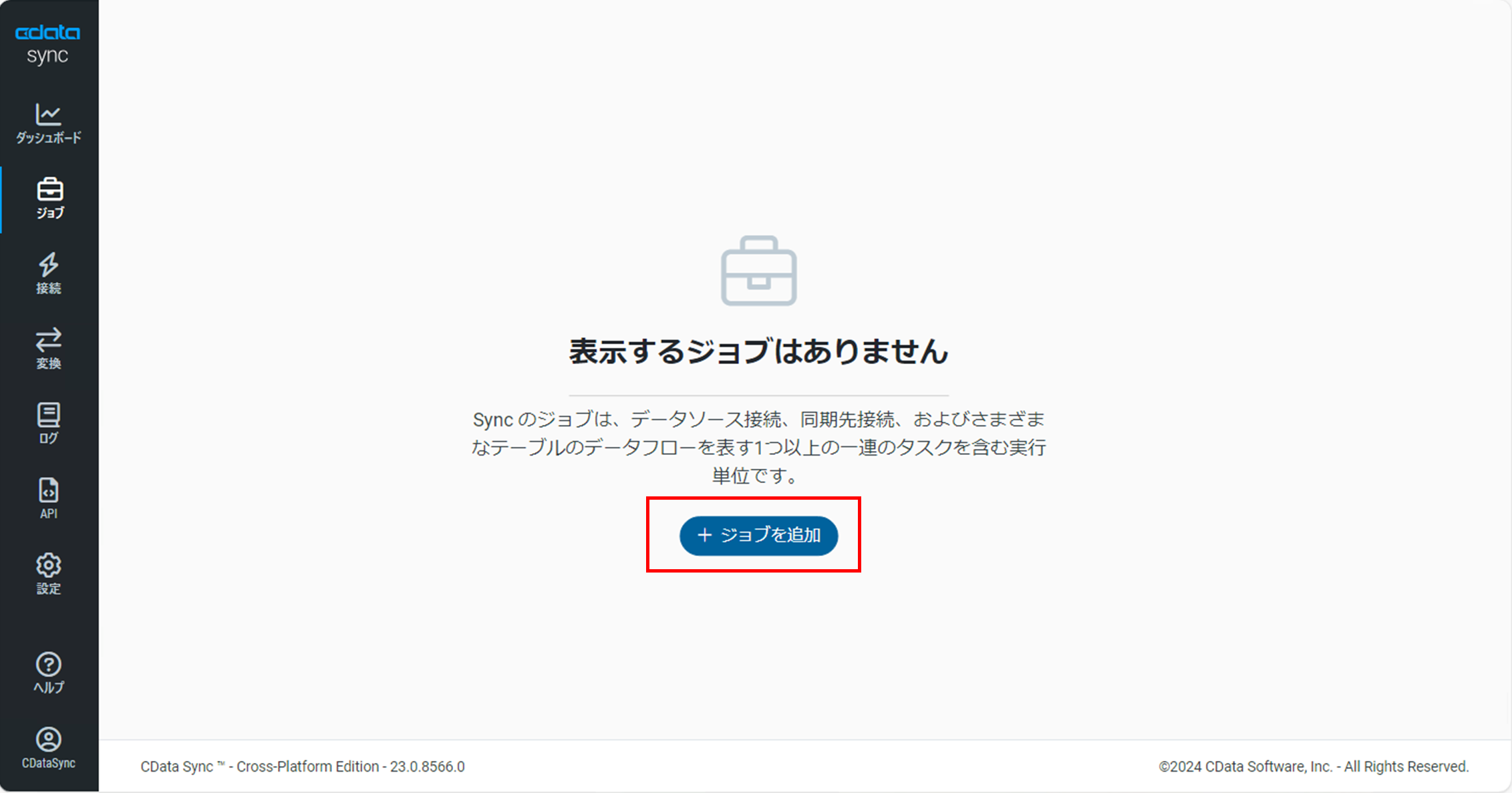
管理コンソールの左メニューの「ジョブ」をクリックします。
「ジョブ」画面で「ジョブを追加」をクリックします。
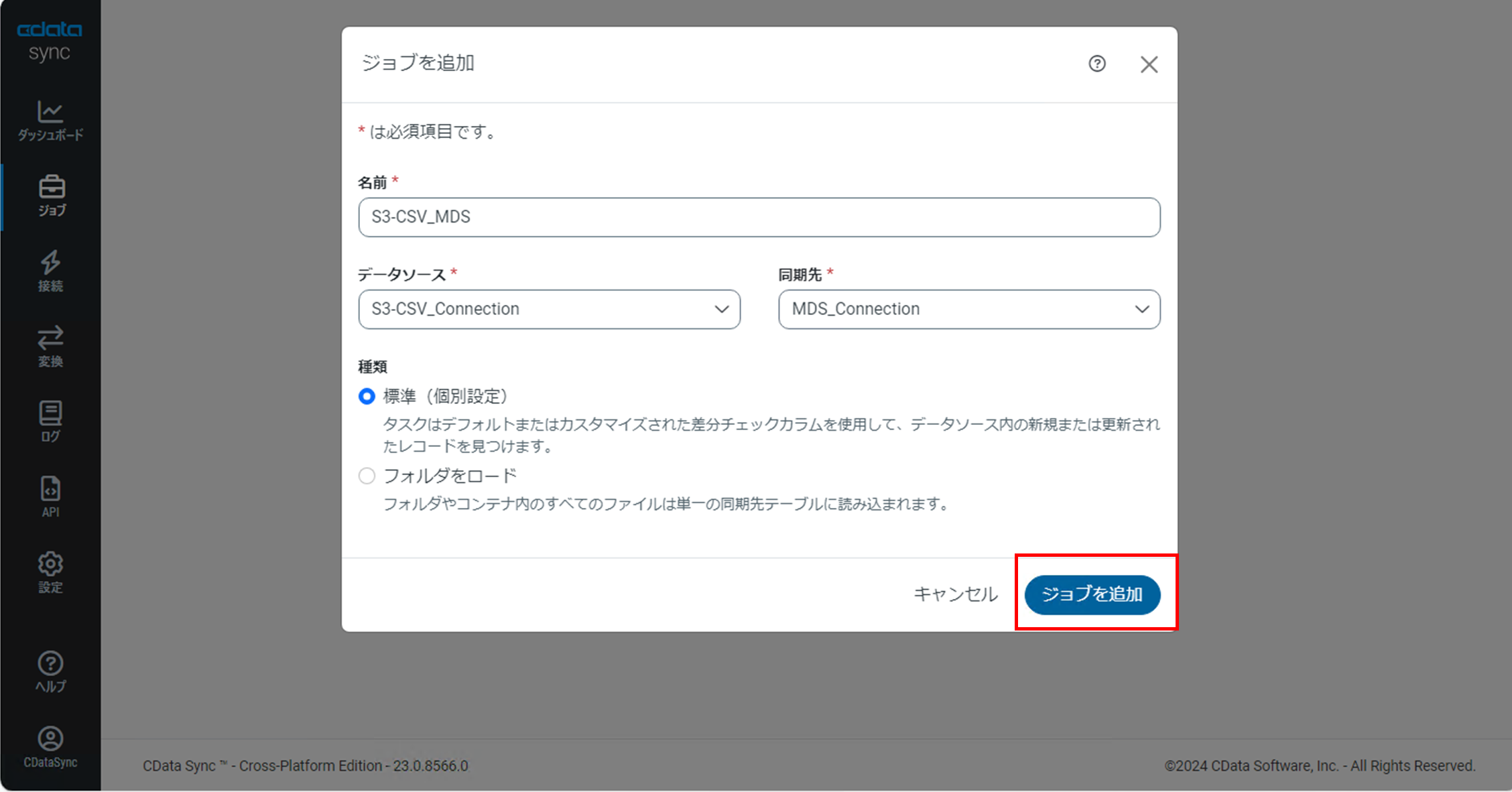
「ジョブを追加」ダイアログ画面で以下の項目を設定します。
・名前:任意のジョブ名
・データソース:CSVのコネクション名
・同期先:MDSのコネクション名
項目を設定後、「ジョブを追加」をクリックします。
「ジョブ」画面でジョブが作成されていることを確認します。
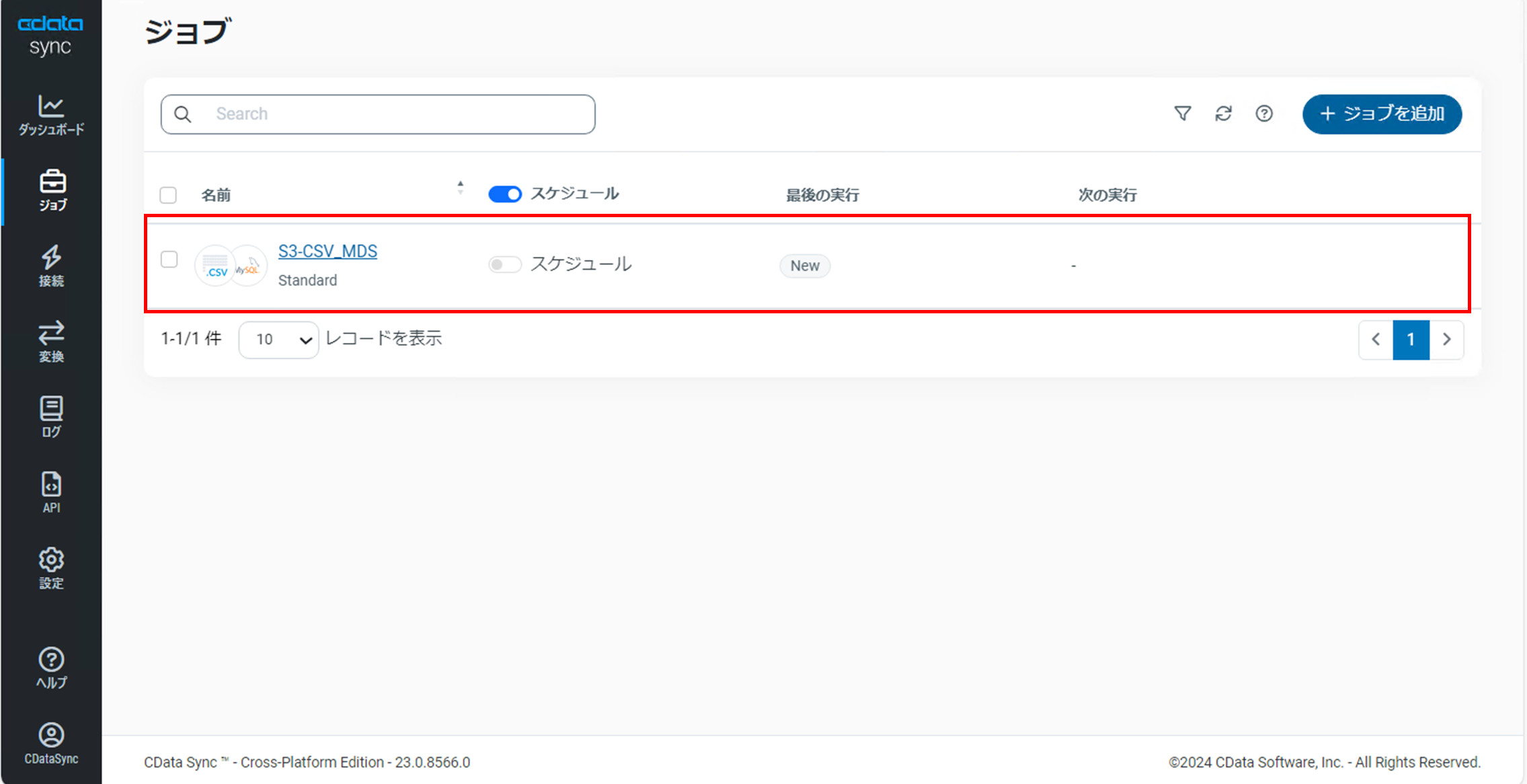
作成したジョブをクリックし、ジョブの詳細画面で「タスク」タブに切り替えます。
「タスクを追加」をクリックします。
「タスクを追加」ダイアログが表示されます
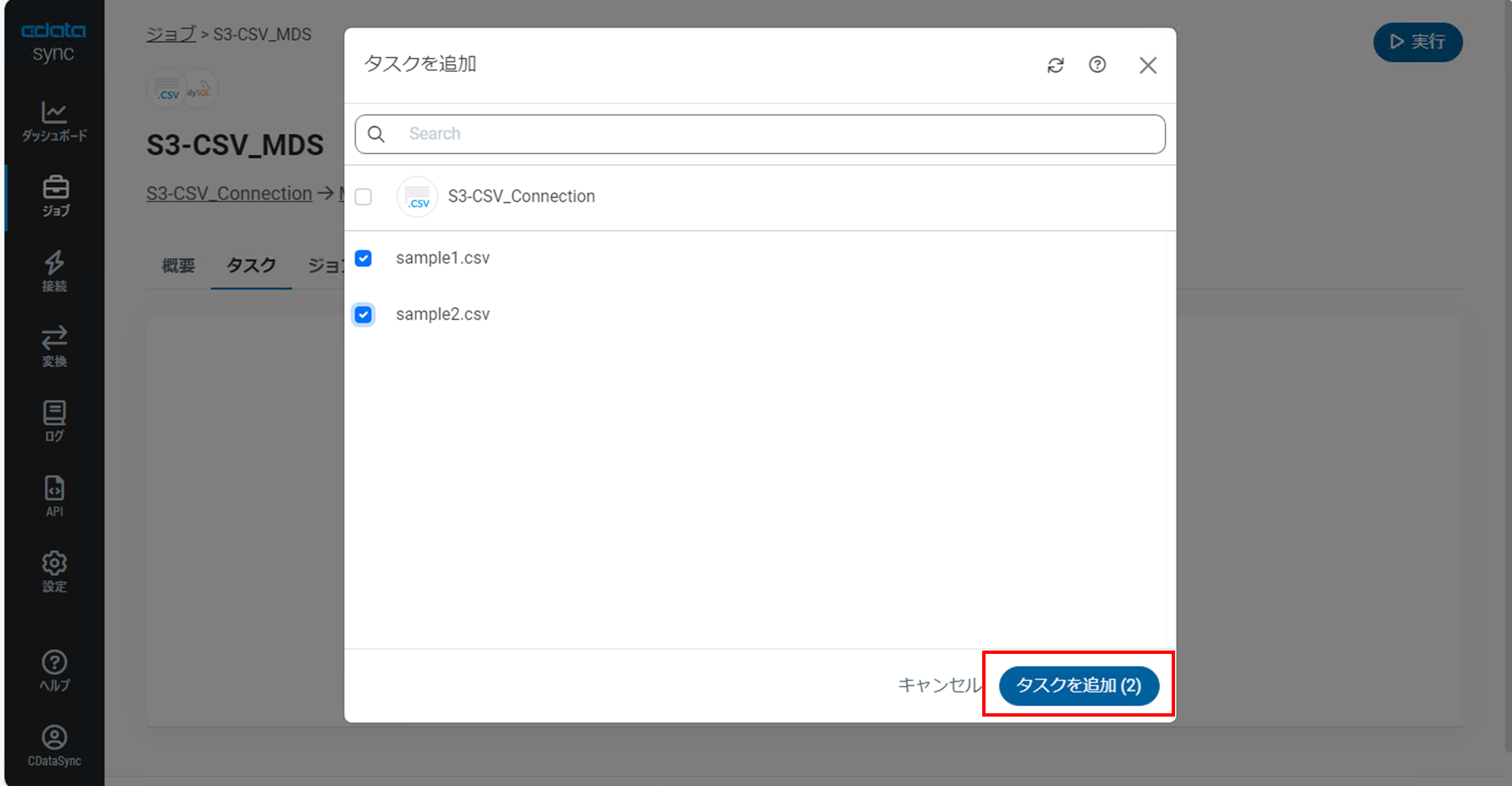
データソースとなるAmazon S3バケット内のCSVファイルが表示され、ここで選択したオブジェクトがテーブルとして連携されます。
任意のオブジェクトにチェックを入れ「タスクを追加」をクリックします。
ジョブの詳細画面で「タスク」タブに切り替え、追加したオブジェクトが設定されていることを確認します。
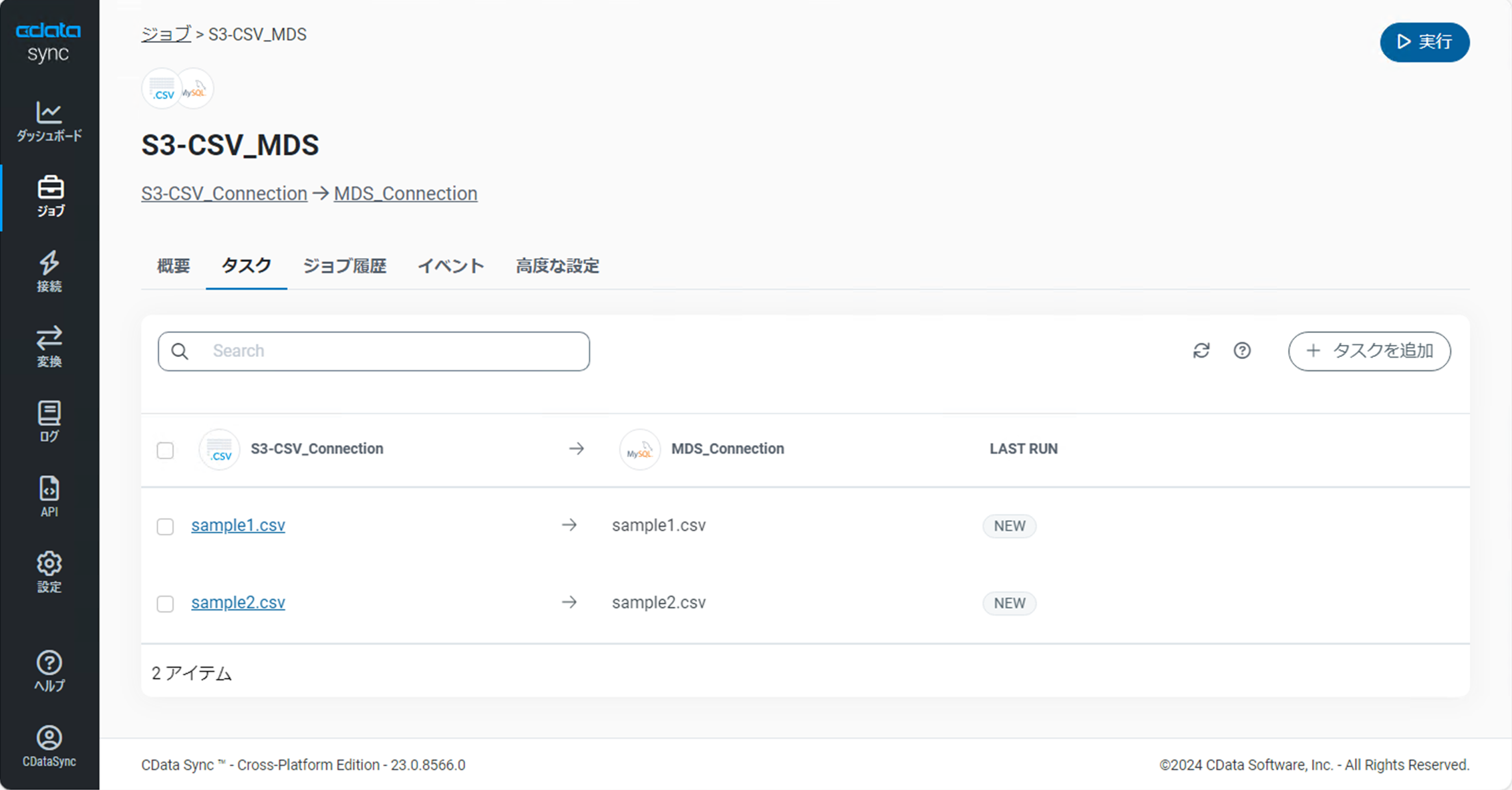
今回はわかりやすいように、同期先でのテーブル名を意図的に変更します。
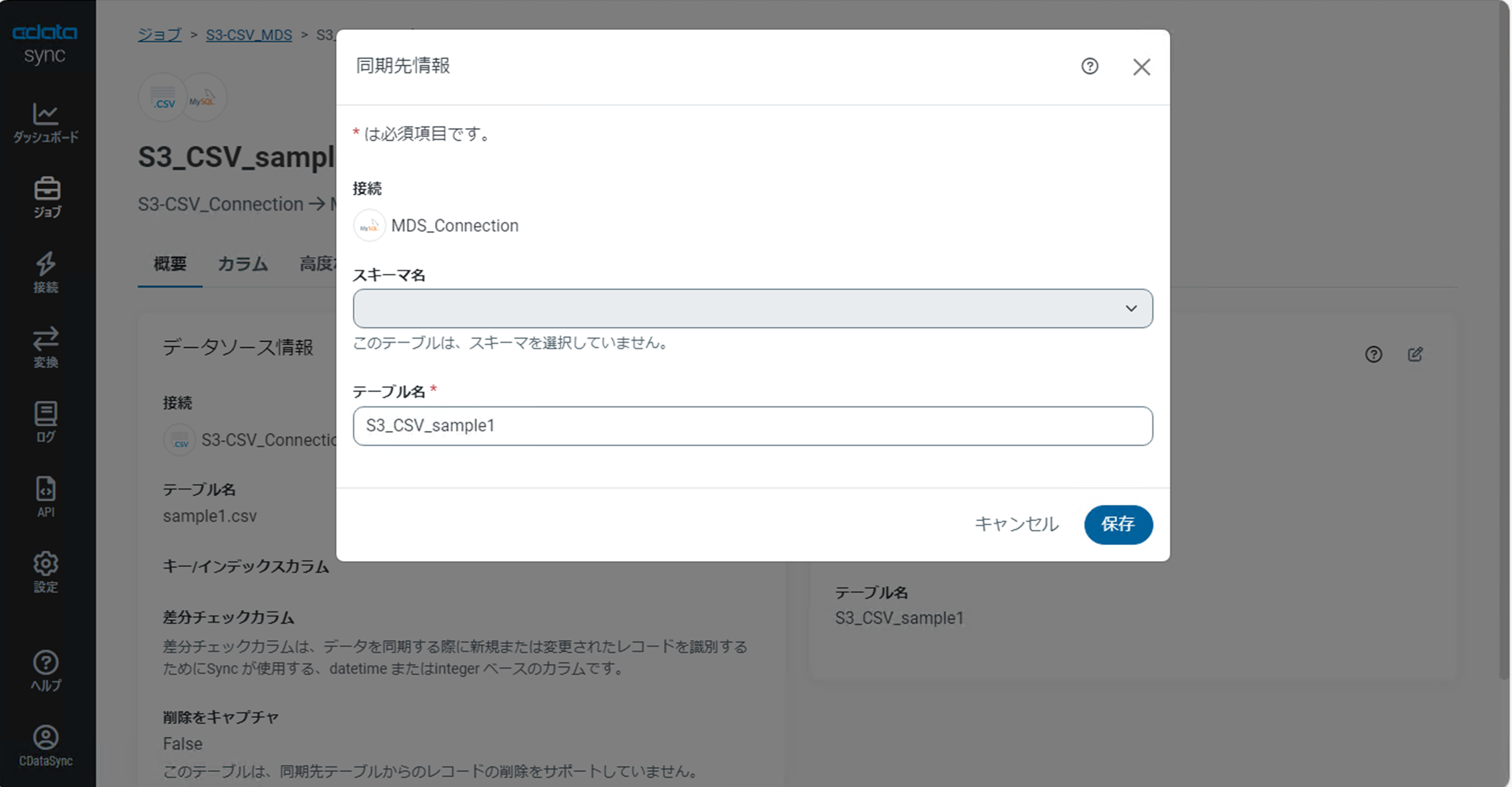
追加したタスクをクリックし「タスクの詳細画面」で右側の「同期先情報」右上の「Edit Setting」アイコンをクリックします。
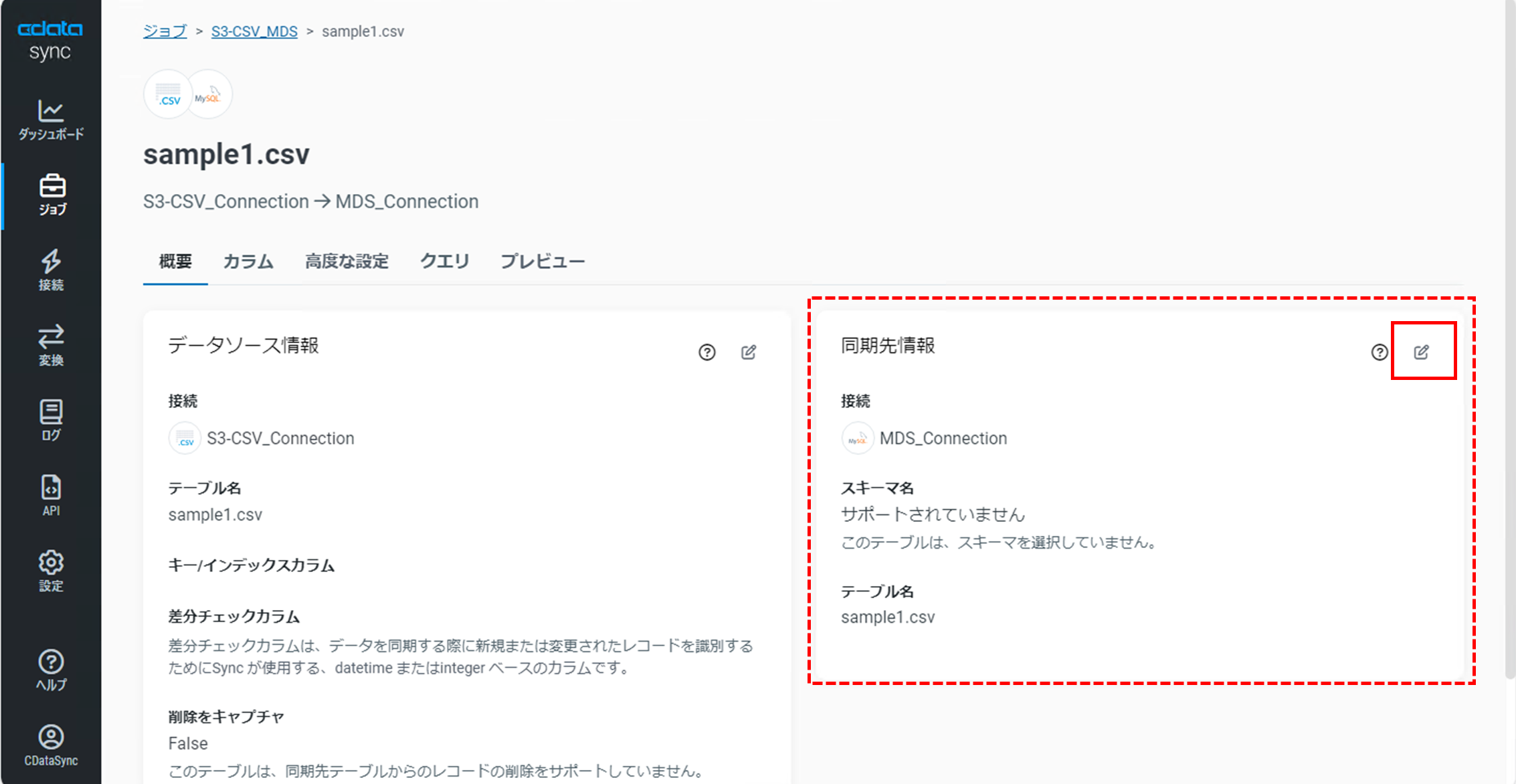
「同期先情報」ダイアログが表示され「テーブル名」を変更することができます。
デフォルトではファイル名がそのままテーブル名として同期されます。
今回は、Amazon S3からのCSVファイルをインポートしたことを明記するため「S3_CSV_ファイル名)」というテーブル名に変更します。
変更後、「保存」をクリックします。
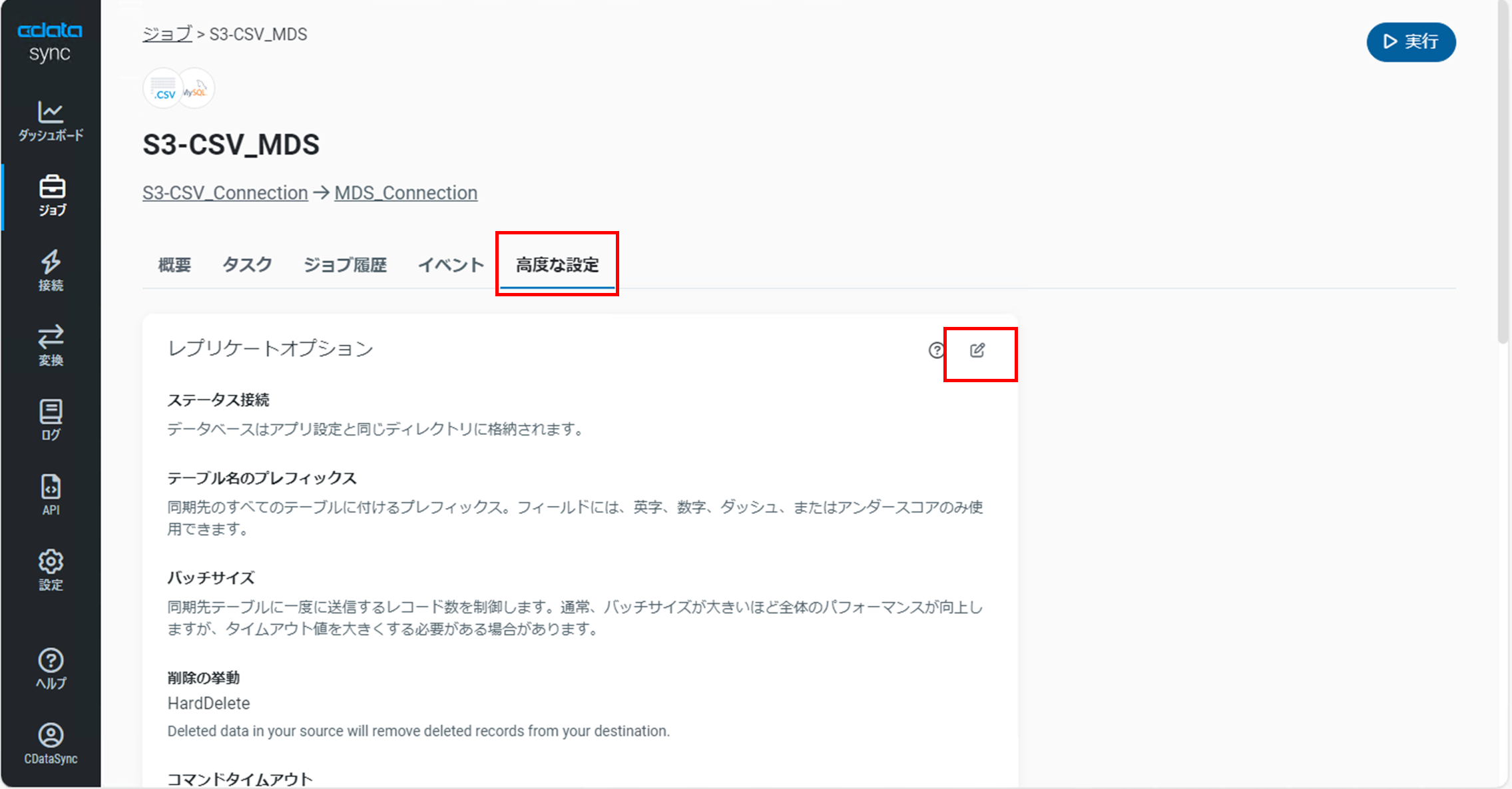
同期先のテーブル名、カラム名を大文字に統一します。
今回の同期先となるMDSの場合、テーブル名、カラム名に大文字、小文字が混在していても問題ありませんが、同期先のDBによってはSQL文で名前を指定する際、ダブルクォーテーション(“”)で囲う必要があります。テーブルを参照しやすくするために今回は下記の手順で事前に統一をしておきます。
「ジョブの詳細」画面の「高度な設定」タブでレプリケーションオプションの右上の「Edit Setting」アイコンをクリックします。
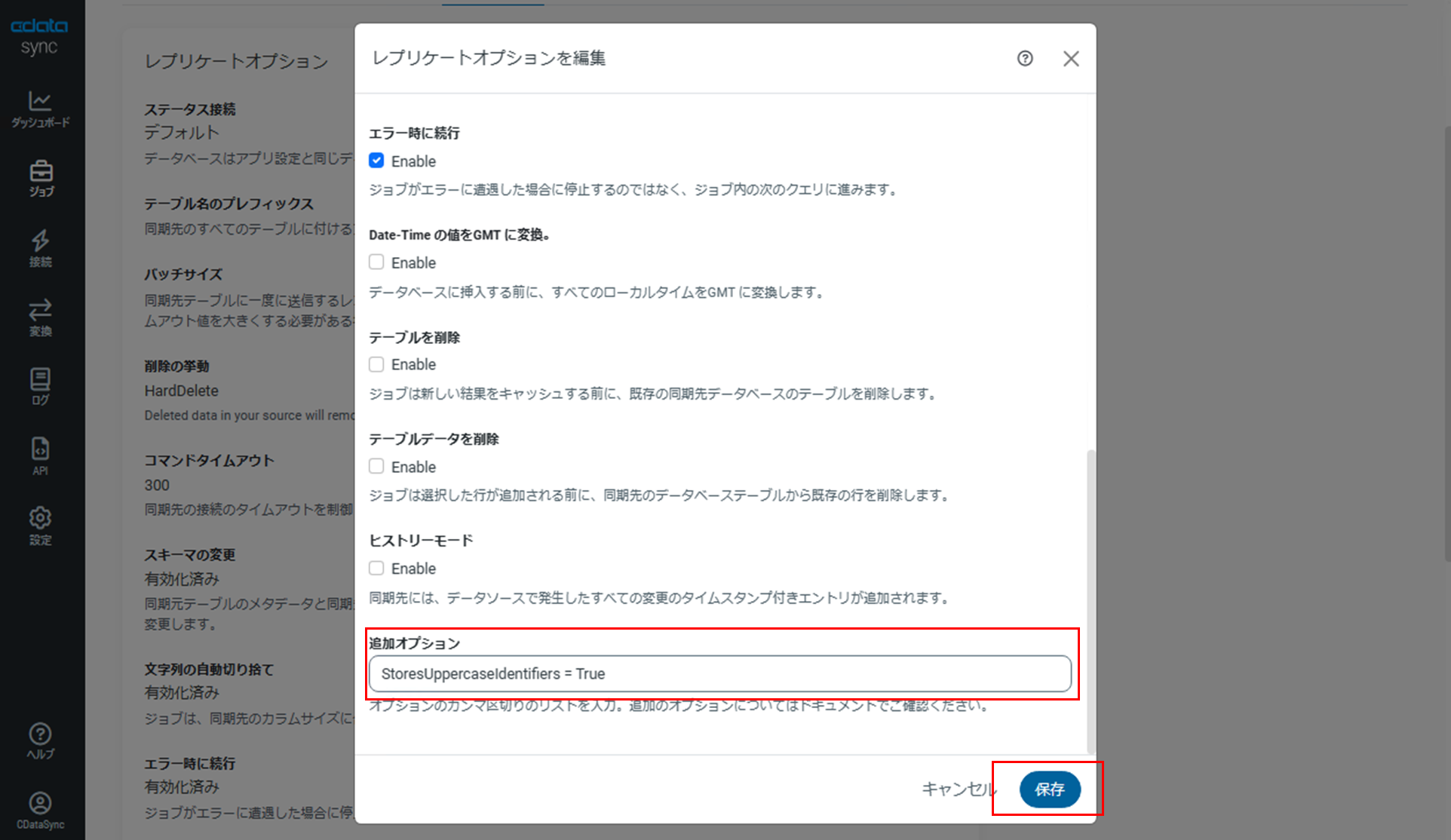
「追加オプション」に「StoresUppercaseIdentifiers = True」と入力して「保存」をクリックします。
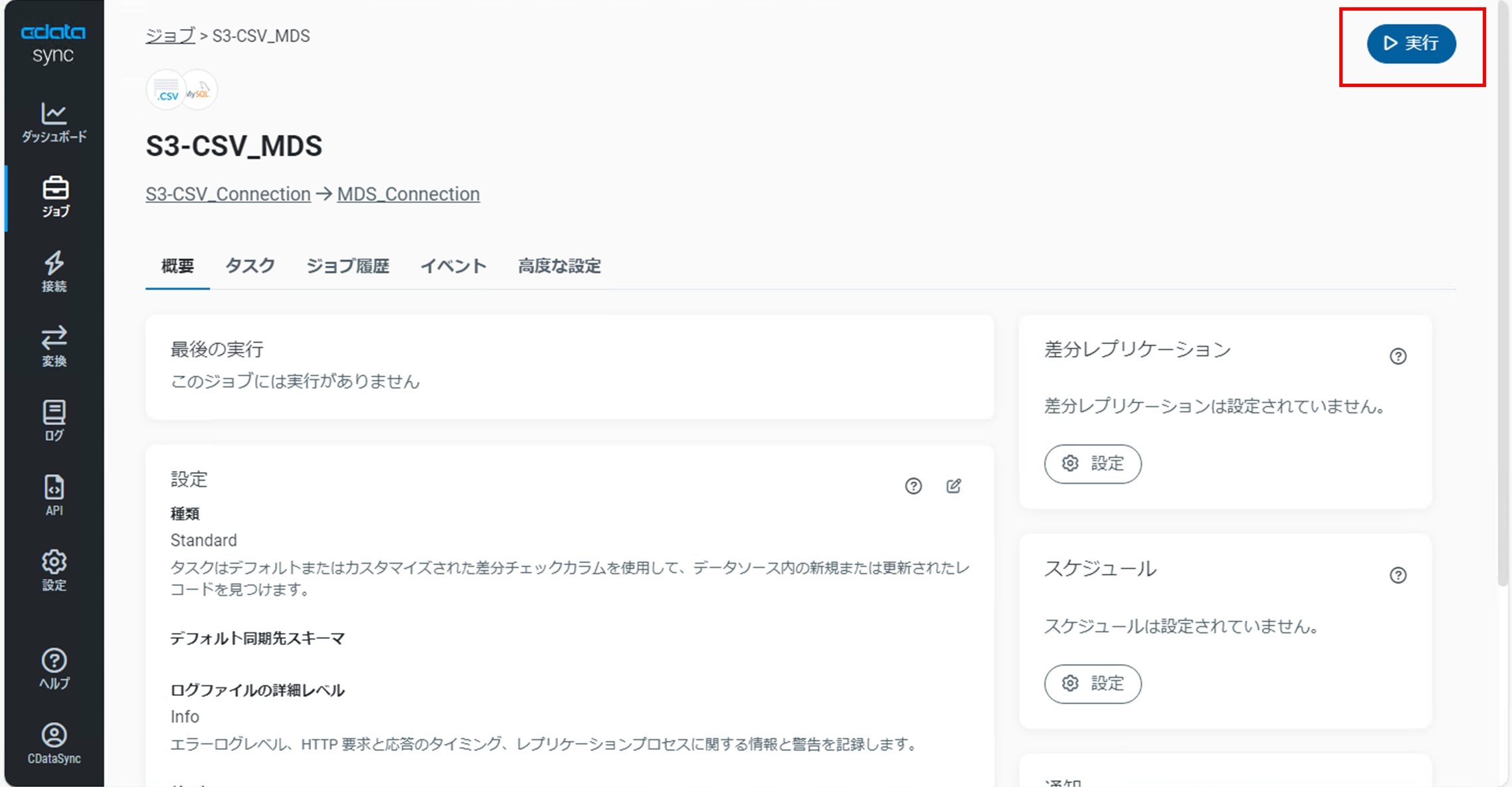
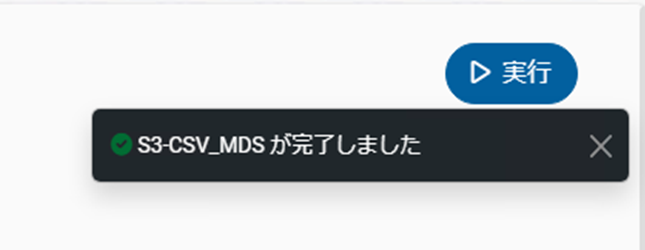
「ジョブの詳細」画面で右上の「実行」をクリックします。
「ジョブ名(今回は[S3-CSV_MDS])が完了しました」と表示されればデータ連携が成功です。
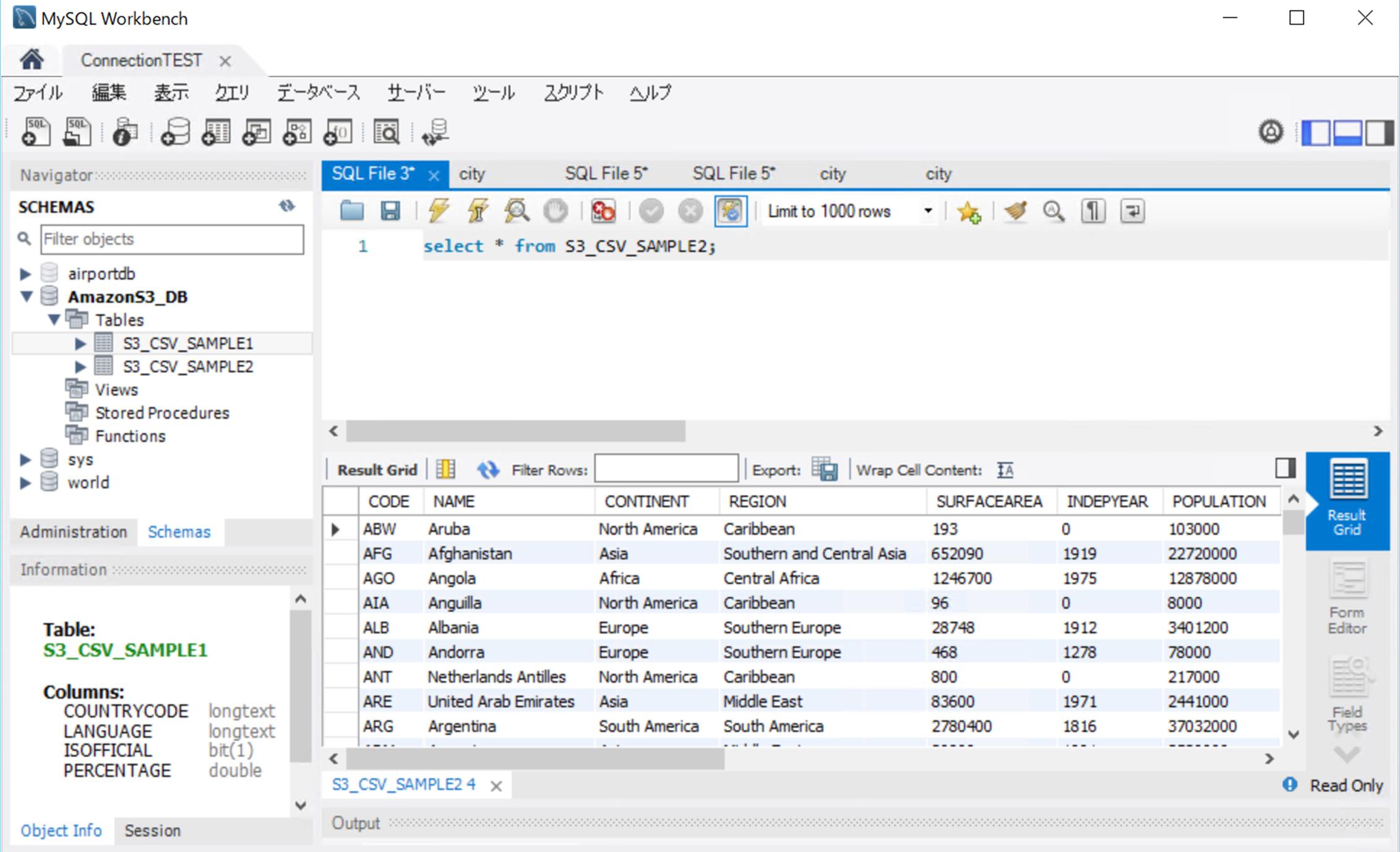
同期先のMDSにデータが同期されていることを確認します。
以上がCData Syncを使用してAmazon S3のCSVファイルをMDSへインポートする流れとなります。
まとめ
今回、CData Syncでデータ連携を検証してみてみました。
今回は一部の機能のみを使用してデータ連携の検証を行いましたが、CData Syncには他にも多くの機能が備わっており既存の環境に合わせた柔軟なデータ連携が可能です。
CData Syncは400種類以上のデータソースと20種類以上のデータベースを同期先としてサポートしています。
複数のSaaS/DBを使用している環境において、データの集約と分析のための可視化を課題と感じられているお客様も多く、CData Syncであればシンプルな構成および手順(3ステップ)でデータ連携が実現できます。
また複数のデータソースから同一のデータベース同期先へ、複数連携の実現も容易です。
データ集約などご検討いただいてる際は、弊社へご依頼をご一考いただけますと幸いです。