MySQL Heatwave Lakehouse がリリース
昨年の年末よりいくつかのサイトではリリースされることが予告されていましたが、ようやく 2023-06-09 に 待望の MySQL Heatwave Lakehouse がリリースされたようです。
リリースノートはこちら:Release Notes
今回は、早速リリースされたばかりのMySQL Heatwave Lakehouseを試してみたいと思います。
MySQL Heatwave Lakehouseについて
MySQL Heatwave Lakehouse では、MySQL Heatwave (MySQL Database Service) に追加された Lakehouse ストレージエンジン を使用して以下の機能を提供します。
- オブジェクトストレージ上に配置された外部ファイルをMySQLテーブルとしてロード
- 対応ファイルフォーマットは CSV、 Parquet、Aurora/Redshiftエクスポートファイル
- 外部ファイルをロードすると、HeatWave ノードのストレージレイヤに保存され、その後メモリにロードされます。
環境の準備
MySQL Heatwave Lakehouseを試すには、以下の準備が必要です。
- Lakehouseが有効な MySQL Heatwave の起動
- MySQL Heatwave から Object Storageへのアクセス許可
Lakehouseが有効な MySQL Heatwave の起動
以下の手順に従い、MySQL Heatwaveノードの起動まで行います。
Creating a DB System
Adding a HeatWave Cluster
なお、現時点で MySQL Heatwave Lakehouse には以下の制限があります。
- MySQL.HeatWave.VM.StandardおよびHeatWave.512GB シェイプでのみサポート
- 高可用性構成では利用不可
- ポイントインタイムリカバリ不可
- リードレプリカの使用不可
コンソール、またはocicliでの作成時にこれらの要件を満たすように、設定を行う必要があります。
上記が満たされたインスタンスを起動すると、Heatwaveノードの追加時に 以下のように Lakehouseの有効化を選択できるようになります。
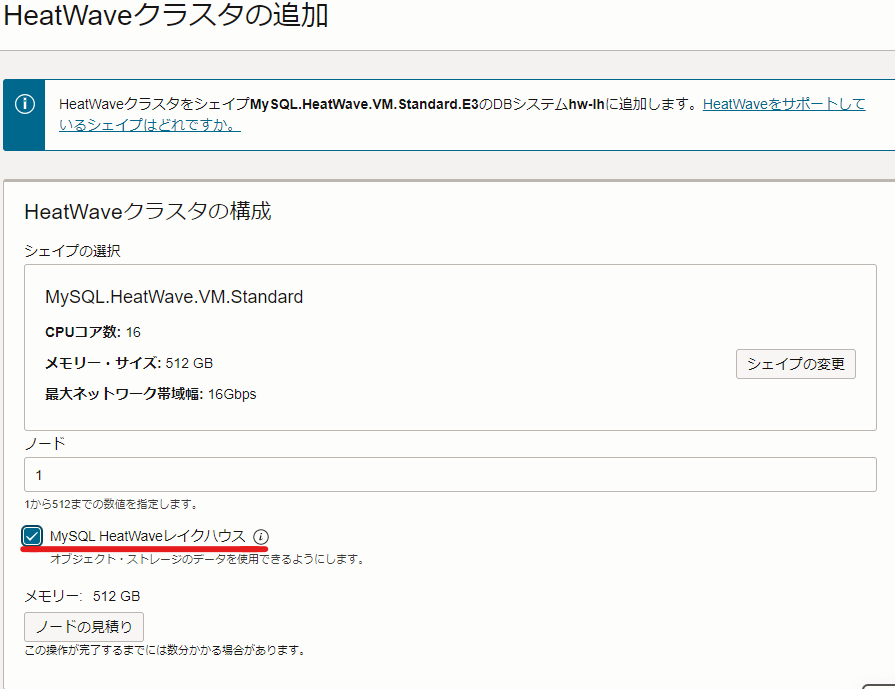
MySQL Heatwave から Object Storageへのアクセス許可
何らかの方法で MySQL Heatwave から Object Storage へのアクセスを許可する必要があります。
ドキュメントでは、Pre-Authenticated Request(PAR) によるオブジェクトストレージへのアクセス許可方法が案内されていますので、今回はこちらを使用します。
今回検証で利用する tpch_s1000 バケットには、TPC-H で作成した各種テーブルの.tblファイルが格納されており、それらに対してPARを作成しています。
なおドキュメントのPARの例ではオプションがありませんが、PARを使用してLakehouseストレージエンジンにデータをロードするために --bucket-listing-action ListObjects が必要なため追記しています。
https://dev.mysql.com/doc/heatwave/en/mys-hw-lakehouse-par-examples.html
|
1 2 3 4 5 6 7 |
for tab in customer lineitem nation orders part partsupp region supplier do oci os preauth-request create --namespace <namespace> --bucket-name tpch_s1000 \ --name par_read_tpch_s1000_${tab} --access-type AnyObjectRead \ --bucket-listing-action ListObjects \ --time-expires="2024-01-01T00:00:00+00:00" --object-name ${tab}.tbl done | jq -r '.data|[."access-uri", ."object-name"]' |
以下のようにPARの一覧が取得できました。これはテーブルの作成時に使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[ "/p/.../b/tpch_s1000/o/", "customer.tbl" ] [ "/p/.../b/tpch_s1000/o/", "lineitem.tbl" ] [ "/p/.../b/tpch_s1000/o/", "nation.tbl" ] (..略..) |
なお、PARは払い出されるURLを知っていれば誰でもアクセスできてしまうので、本番ではプリンシバルベースの許可方法の利用が推奨されています。
今回は詳しい手順は省かせて頂きますが、プリンシバルベースの許可方法については以下のドキュメントを参考に行います。
https://docs.oracle.com/en-us/iaas/Content/Identity/dynamicgroups/managingdynamicgroups.htm
Lakehouse ストレージエンジンで TPC-H してみる
早速Lakehouse ストレージエンジンを使って、TPC-Hしてみたいと思います。
外部ファイルのロード
Lakehouse ストレージエンジンを使用した外部表のCREATE TABLE構文は以下に記載されています。
https://dev.mysql.com/doc/heatwave/en/mys-hw-lakehouse-table-syntax.html
データをロードする方法として、Auto Parallel Loadと、手動でのデータローディング の2パターンがあります。
Auto Parallel Load は、ロード時のコマンドに、対象のファイル構造と、インポート先のDBを設定すれば、型推論によって半自動でテーブルを作成してくれる機能です。
早速やってみたいと思います。
クライアントに使用した Compute instance には mysql-shell 及び mysql-community-client をインストールしてあります。
各コマンドの構文は Lakehouse Auto Parallel Load で説明されています。
PARのURLは、 https://objectstorage.<region name>.oraclecloud.com/<PAR access-uri>/<filename> になります。
"tables" に TPC-Hのテーブルをすべて列挙してロードを実行しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
MySQL > CREATE DATABASE IF NOT EXISTS tpch; MySQL > SET @db_list = '["tpch"]'; MySQL > SET @ext_tables = '[{ "db_name": "tpch", "tables": [ { "table_name": "customer", "dialect": { "format": "csv", "field_delimiter": "|", "record_delimiter": "|\\n" }, "file": [ {"par": "https://objectstorage.ap-tokyo-1.oraclecloud.com/..../customer.tbl"} ] }, { "table_name": "region", "dialect": { "format": "csv", "field_delimiter": "|", "record_delimiter": "|\\n" }, "file": [ {"par": "https://objectstorage.ap-tokyo-1.oraclecloud.com/..../region.tbl"} ] }, ...略... ] }]'; MySQL > SET @options = JSON_OBJECT('external_tables', CAST(@ext_tables AS JSON)); MySQL > CALL sys.heatwave_load(@db_list, @options); |
ファイルサイズ的には合計1TB程度のデータでしたが、Heatwaveにロードする時点で最適化が行われ、見積もり上は 633.66 GiB となっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
+------------------------------------------+ | INITIALIZING HEATWAVE AUTO PARALLEL LOAD | +------------------------------------------+ | Version: 2.18 | | | | Load Mode: normal | | Load Policy: disable_unsupported_columns | | Output Mode: normal | | | +------------------------------------------+ 6 rows in set (0.0069 sec) +--------------------------------------------------------------------------------------------------------------------------------------+ | LAKEHOUSE AUTO SCHEMA INFERENCE | +--------------------------------------------------------------------------------------------------------------------------------------+ | Verifying external lakehouse tables: 7 | | | | SCHEMA TABLE TABLE IS RAW NUM. OF ESTIMATED SUMMARY OF | | NAME NAME CREATED FILE SIZE COLUMNS ROW COUNT ISSUES | | ------ ----- -------- --------- ------- --------- ---------- | | tpch customer NO 23.08 GiB 8 149.99 M | | tpch lineitem NO 757.86 GiB 16 6.01 B | | tpch nation NO 2.17 KiB 4 25 | | tpch orders NO 168.50 GiB 9 1.5 B | | tpch part NO 23.03 GiB 9 200.13 M | | tpch partsupp NO 115.20 GiB 5 800.31 M | | tpch supplier NO - - - Auto Schema Inference failed | | | | New schemas to be created: 0 | | External lakehouse tables to be created: 6 | | | +--------------------------------------------------------------------------------------------------------------------------------------+ 16 rows in set (0.0069 sec) +-----------------------------------------------------------------------------------------+ | OFFLOAD ANALYSIS | +-----------------------------------------------------------------------------------------+ | Verifying input schemas: 1 | | User excluded items: 0 | | | | SCHEMA OFFLOADABLE OFFLOADABLE SUMMARY OF | | NAME TABLES COLUMNS ISSUES | | ------ ----------- ----------- ---------- | | tpch 6 51 1 table(s) are not loadable | | | | Total offloadable schemas: 1 | | | +-----------------------------------------------------------------------------------------+ 10 rows in set (0.0069 sec) +-----------------------------------------------------------------------------------------------------------------------------+ | CAPACITY ESTIMATION | +-----------------------------------------------------------------------------------------------------------------------------+ | Default encoding for string columns: VARLEN (unless specified in the schema) | | Estimating memory footprint for 1 schema(s) | | | | TOTAL ESTIMATED ESTIMATED TOTAL DICTIONARY VARLEN ESTIMATED | | SCHEMA OFFLOADABLE HEATWAVE NODE MYSQL NODE STRING ENCODED ENCODED LOAD | | NAME TABLES FOOTPRINT FOOTPRINT COLUMNS COLUMNS COLUMNS TIME | | ------ ----------- --------- --------- ------- ---------- ------- --------- | | tpch 6 633.66 GiB 3.56 MiB 23 0 23 1.24 h | | | | Sufficient MySQL host memory available to load all tables. | | Sufficient HeatWave cluster memory available to load all tables. | | | +-----------------------------------------------------------------------------------------------------------------------------+ 12 rows in set (0.0069 sec) |
ロード時間の見積もりは 1.24h と出ています。
あれこれ考えずとも、事前にこういった情報が確認できるのは非常に嬉しいポイントです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
+---------------------------------------------------------------------------------------------------------------------------------------+ | EXECUTING LOAD | +---------------------------------------------------------------------------------------------------------------------------------------+ | HeatWave Load script generated | | Retrieve load script containing 12 generated DDL command(s) using the query below: | | Deprecation Notice: "heatwave_load_report" will be deprecated, please switch to "heatwave_autopilot_report" | | SELECT log->>"$.sql" AS "Load Script" FROM sys.heatwave_autopilot_report WHERE type = "sql" ORDER BY id; | | | | Adjusting load parallelism dynamically per internal/external table. | | Using current parallelism of 32 thread(s) as maximum for internal tables. | | | | Using SQL_MODE: ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION | | | | Proceeding to load 6 table(s) into HeatWave. | | | | Applying changes will take approximately 1.24 h | | | +---------------------------------------------------------------------------------------------------------------------------------------+ 14 rows in set (0.0069 sec) ...略... +----------------------------------------+ | LOADING TABLE | +----------------------------------------+ | TABLE (6 of 6): tpch.partsupp | | Commands executed successfully: 2 of 2 | | Warnings encountered: 0 | | Table loaded successfully! | | Total columns loaded: 5 | | Elapsed time: 5.22 min | | | +----------------------------------------+ 7 rows in set (0.0069 sec) +-------------------------------------------------------------------------------+ | LOAD SUMMARY | +-------------------------------------------------------------------------------+ | | | SCHEMA TABLES TABLES COLUMNS LOAD | | NAME LOADED FAILED LOADED DURATION | | ------ ------ ------ ------- -------- | | tpch 6 0 51 45.27 min | | | +-------------------------------------------------------------------------------+ 6 rows in set (0.0069 sec) |
ロードに使用されたコマンドは以下で確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
MySQL > SELECT log->>"$.sql" AS "Load Script" FROM sys.heatwave_autopilot_report WHERE type = "sql" ORDER BY id\G -- 実際の結果に含まれるCREATE TABLEは1行で表示されます *************************** 1. row *************************** Load Script: CREATE TABLE tpch.customer ( col_1 int unsigned NOT NULL, col_2 varchar(18) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', col_3 varchar(40) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', col_4 tinyint unsigned NOT NULL, col_5 varchar(15) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', col_6 decimal(6,2) NOT NULL, col_7 varchar(10) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', col_8 varchar(116) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN') ENGINE=lakehouse SECONDARY_ENGINE=RAPID ENGINE_ATTRIBUTE='{"file": [{"par": "https://objectstorage.ap-tokyo-1.oraclecloud.com/p/.../customer.tbl"}], "dialect": {"format": "csv", "field_delimiter": "|", "record_delimiter": "|\\n"}}'; *************************** 2. row *************************** Load Script: ALTER TABLE tpch . customer SECONDARY_LOAD; .. 略 .. |
列名には、 自動的に col1 からの連番の名称が設定されています。型推論によって、列データの内容に沿った型が自動的に設定されているのは素晴らしいと思いました。
なお、ロードに使用されるコマンドは sys.heatwave_load() を dryrun モードで実行する事でも確認できます。
|
1 |
MySQL > SET @options = JSON_OBJECT('mode', 'dryrun', 'external_tables', CAST(@ext_tables AS JSON)); |
実運用では、dryrunモードで取得したロードスクリプトをもとに、適切な列名を設定して手動でテーブルを作成する、という流れが一般的になるのではと思います。
ということで、列名が colN だとTPC-Hが実行できないため、一旦 DROP DATABASE しました。
|
1 2 |
MySQL > DROP DATABASE tpch; MySQL > CREATE DATABASE tpch; |
TPC-Hの実行
実行するSQLについては、 HeatWave TPC-H をありがたく利用させていただきました。
|
1 |
$ git clone https://github.com/oracle/heatwave-tpch.git |
この公開ベンチマークスクリプトには create_tables_lakehouse.sql という専用のテーブル作成スクリプトが同梱されています。
ENGINE_ATTRIBUTE の箇所を修正するだけで使用する事ができます。
なお、ENGINE=datalake となっている箇所は現時点ではENGINE=lakehouseに書き換えが必要です
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE LINEITEM ( L_ORDERKEY BIGINT NOT NULL, ..略.. L_COMMENT VARCHAR(44) NOT NULL, PRIMARY KEY (L_ORDERKEY, L_LINENUMBER)) ENGINE=datalake secondary_engine=rapid ENGINE_ATTRIBUTE='{"file": [{"region":"<region>", "namespace":"<namespace>", "bucket":"<bucket_name>", "name":"<lineitem_file_location>"}]}'; |
以下のように修正します。
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE LINEITEM ( L_ORDERKEY BIGINT NOT NULL, ..略.. L_COMMENT VARCHAR(44) NOT NULL, PRIMARY KEY (L_ORDERKEY, L_LINENUMBER)) ENGINE=lakehouse secondary_engine=rapid ENGINE_ATTRIBUTE='{"file": [{ "par": "https://objectstorage.ap-tokyo-1.oraclecloud.com/..../lineitem.tbl"}] }'; |
全テーブルを作成し、データをロードします。
|
1 2 |
MySQL > SOURCE heatwave-tpch/TPCH/create_tables_lakehouse.sql MySQL > SOURCE heatwave-tpch/HeatWave/secondary_load_lakehouse.sql |
以下のようにTPC-Hを実行し、実行速度を測定してみました。
|
1 2 3 |
$ for q in $(ls hq*.tbl); do mysql --show-warnings -vvv -uadmin -p[password] -h[HeatWave endpoint] -P[port] tpch < $q done |
Heatwave(RAPID) ストレージエンジンの場合と比較してみた結果、以下のようになりました。
結果は、各SQLごとに5回実行した平均値(秒)になります。
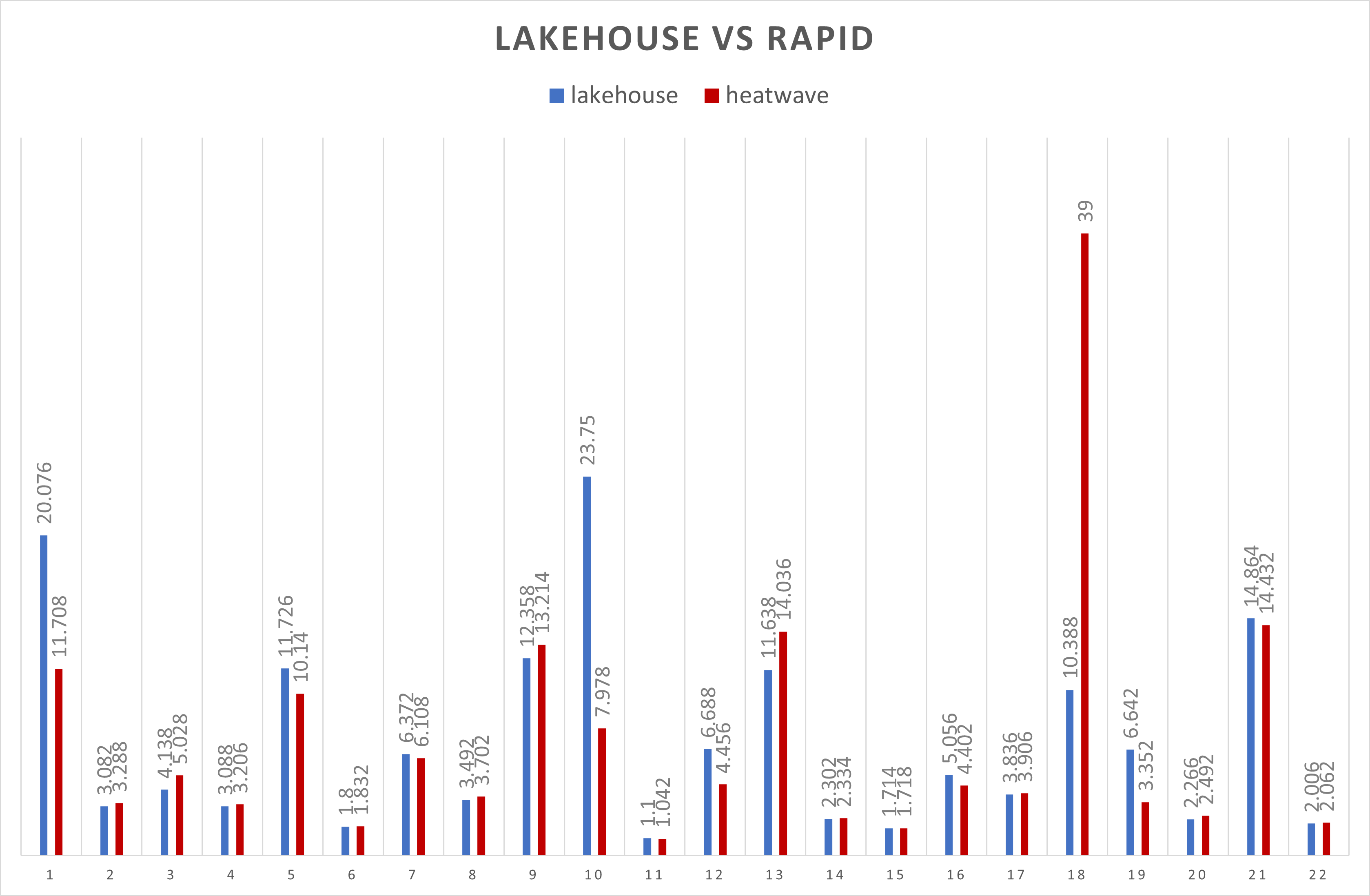
想定ではLakehouseストレージエンジンのほうがかなり遅いと考えていましたが、RAPIDストレージエンジンと比較してもレスポンスタイムは遜色なく、場合によっては高速であるケースもある事がわかりました。
Lakehouseストレージエンジンの制限
最後にドキュメントをもとに、2023-06-21現在での MySQL Heatwave Lakehouse の制限について確認しておきましょう。
https://dev.mysql.com/doc/heatwave/en/mys-hw-lakehouse-limitations.html
- クエリによってはHeatWave Lakehouseによって高速化できない場合がある
- ファイルに含まれるすべてのNAN値をNULLに置き換える必要がある
dumpInstance()などのMySQL Shellエクスポートユーティリティを使用して外部テーブルをダンプすることはできない- このため、上記の処理時にはexcludeTablesオプションにlakehouseテーブルを列挙する必要がある
- 1行あたり4 MBを超えるCSVファイルはサポートされていない
- Lakehouse対応DBシステムからスタンドアロンDBシステムにバックアップを復元することはできない
- Lakehouseテーブルにについて以下は実行できない
- DMLステートメント
- 一時テーブルの作成
- AUTO_INCREMENTカラムの作成
- トリガーの作成
- ANALYZE TABLEの実行
- インデックスの作成
- ALTER TABLE ADD/DROP COLUMN
- CHECK制約
- 一意制約の強制
- GROUP BY句の結果に影響
- STORAGE句を含む任意のステートメントの実行
- 次のシェイプのみをサポートする →
MySQL.HeatWave.VM.Standard、MySQL.HeatWave.512 - ポイントインタイムリカバリ機能の使用はできない
- 高可用性構成の使用はできない
- リードレプリカの使用はできない
- アウトバウンドレプリケーション機能の使用はできない
現状の制限からは、MySQL Heatwave Lakehouseを使用する場合は、ある程度データレイク専用の用途として運用するのが良いように見えます。
まとめ
今回、MySQL Heatwave Lakehouseを使ってみて、簡単かつ高速であることを確認できました。
データレイク領域まで、MySQLクライアントでアクセスできるようになり、MySQLの便利さはとどまることを知らないようです。
現在 MySQL Heatwave はマルチクラウド対応や高可用性構成でのRAPIDストレージエンジンの対応、MySQL Enterprise Editionの機能の統合、機械学習 など非常に活発に開発が進んでいます。
ぜひMySQL Heatwave Lakehouseをお試しください!