今回の記事は MySQL Shell 8.1 (Innovation release) で追加された新機能 Copy Instance ユーティリティ の紹介です。
リリースノートはこちら。
MySQL :: MySQL Shell Release Notes :: Changes in MySQL Shell 8.1.0 (2023-07-18, Innovation Release)
※注:2024/5月時点でリンク切れ
It is now possible to copy an instance, schemas, and tables from one instance to another with the new MySQL Shell copy utilities. The copy utilities enable you to copy DDL and data between MySQL instances, without the need for intermediate storage. The data is stored in memory.
The following methods were added:
util.copyInstance(): Enables copying of an entire instance to another server.
util.copySchemas(): Enables copying of one or more schemas to another server.
util.copyTables(): Enables copying of one or more tables from a schema to another server.
See Copy Instance, Schemas, and Tables. (WL #15298)
ユーティリティの名前からして想像に難くないとは思いますが、コピー元(ソース)からダンプし、コピー先(ターゲット)へインポートするという、一連のデータコピー処理を一貫して実行することができる優れものです。
つい先日(2024年4月30日)、待望の LTS となるバージョン 8.4 が GA リリースされましたが、本記事では MySQL Shell 8.3 (Innovation release) を用いて解説していきます。
バージョン 8.3 のリファレンスマニュアルはこちらです。
MySQL :: MySQL Shell 8.3 :: 11.7 Copy Instance, Schemas, and Tables
特徴
MySQL Shell Copy Instance ユーティリティ(以降 Copy Instance ユーティリティ) は、
既存の Dump ユーティリティ( util.dumpInstance(), util.dumpSchemas(), util.dumpTables()) と、
Dump Load ユーティリティ(util.loadDump()) を一回の実行で同時に行えます。
かつ、既存のユーティリティと大きく異なる点として、中間データ(ダンプファイル)を生成しません。
データをダンプしつつ、並行でネットワークを介してストリーミングで直接コピー対象のインスタンスにインポートしてくれるのです。
つまり、データ移行の際に考慮しなければならないダンプデータの格納領域が不要となります。
以前、過去記事で Dump Load ユーティリティの waitDumpTimeout オプションを用いてデータエクスポートと同時並行でインポートを実行する方法を紹介しましたが、Copy Instance ユーティリティはその進化版と言えます。
MySQL Shell でデータエクスポートと同時並行でインポートを実行する – スマートスタイル技術ブログ
ユースケース
Copy Instance ユーティリティの使いどころとしては以下のようなケースが考えられると思います。
- データ移行の操作手順ステップをシンプルにしたい
- レプリカDBを作成する際のデータコピー方法として
- 異なる OS (バージョン) のソースDBからデータをコピーしたい
- データ移行したいが、ダンプデータの出力先ディスク容量を確保できない
- MySQL HeatWave Service (OCI) の DB システムに手軽にデータ移行したい
Copy Instance ユーティリティで指定できるオプションは、既存のユーティリティ(util.dumpInstance(), util.dumpSchemas(), util.dumpTables(), util.loadDump()) とほぼ同じです。
なので、これまで Dump ユーティリティ・Dump Load ユーティリティを使用したことのあるユーザであれば、オプションの指定の仕方はほぼ踏襲して使うことができます。
データの一貫性を保つ機能はもちろん、データ抽出条件を SQL の WHERE 句記法で指定できるオプションであったり、コピー先との互換性を保つようにデータを調整する compatibility オプションといった、非常に多彩で強力、柔軟性に富んだ機能を利用できるのが魅力的です。
MySQL Shell ダンプユーティリティーのwhereオプション紹介 – スマートスタイル技術ブログ
また Innovation release ということもあり、 8.3 以降を使用すればデータコピー元先の整合性を検査する checksum オプションが使用できるのも特筆すべき点かと思います。
【MySQL Shell 8.3.0】ダンプ・ロードユーティリティのchecksumオプションについて – スマートスタイル技術ブログ
既存のダンプ・ロードユーティリティとの違い、注意事項など
前述の通り、既存のユーティリティが統合されたかたちではありますが、Copy Instance ユーティリティ独自の仕様があるのでその点をピックアップしておきます。
一時中断・再開(リジューム)ができない
Dump Load ユーティリティではデータロード中の中断・再開が可能でしたが、Copy Instance では(ストリーミング方式なので致し方ないのかとは思いますが)その機能がありません。
データコピー中に処理が中断された場合、再実行したときはその時点までターゲットにロードされたデータが既に存在するためエラーとなりますので、以下のいずれかの対応を適宜とる必要があります。
- ターゲットDB側でコピー対象のスキーマやテーブル、ユーザを削除する
ignoreExistingObjectsオプションをtrueにして、重複エラーを無視する- フィルタリングオプション (
excludeTablesなど) で除外して再実行する
スレッド数はパラメータ指定値の倍になる
マニュアルに記載の通り、データのコピーに1スレッド+インポートに1スレッド必要となります。
threads で指定する値はそれぞれの処理のスレッド数ということになり、結果的に threads で指定する値の倍数のスレッド(※)が使用されます。
threads: int
The number of parallel threads to use to copy chunks of data from the MySQL instance. Each thread has its own connection to the MySQL instance. The default is 4.
The copy utilities require twice the number of threads, one thread to copy and one thread to write. If threads is set to N, 2N threads are used.
※既存ユーティリティもそうですが、かならずこのスレッド数で動作するのではなく、あくまで最大数です。(処理内容によってはスレッド数が減少する場合もあります)
Copy Instance ユーティリティの実行方法
次に実行方法について触れたいと思います。
所感ですが、具体的に実行しようとしたとき、公式リファレンスマニュアルを一読しただけでは、以下の点が分かり辛かったです。
- ソース・ターゲット、どちらのサーバで MySQL Shell をインストールして実行すればいいか
- どのようなユーザを用意すればいいか
これらを踏まえ、実行パターンは以下の2通りが可能であることが実際に試してみて分かりました。
- ソースDB 上で ユーティリティを実行
- ターゲットDB 上でユーティリティを実行
それぞれのパターンを解説します。
なお、以降の手順では以下の環境/バージョンを使用しています。
- VM:OCI コンピュートインスタンス
- Oracle Linux Server release 8.9
- シェイプ:VM.Standard.E4.Flex
- OCPU数:2 (= 4VCPU)
- ネットワーク帯域幅:2Gbps
- メモリー:16GB
- MySQL Community Server Ver 8.0.36 for Linux on x86_64
- MySQL Shell Ver 8.3.0 for Linux on x86_64
また、ターゲットDB の my.cnf に以下の設定を入れておきました。
|
1 |
local_infile = ON |
1. ソースDB 上で ユーティリティを実行
MySQL Shell のインストール先、および処理の主体がソースDB側、というシンプルで分かり易いパターンです。
ソースDB に MySQL Shell をインストールします。
|
1 2 3 |
# dnf install -y https://dev.mysql.com/get/mysql84-community-release-el8-1.noarch.rpm # dnf config-manager --enable mysql-tools-innovation-community # dnf install -y mysql-shell-8.3.0 |
次に、ターゲットDB側にデータインポートを実行する DB ユーザ(本例では target_user)を作成しておきます。
|
1 2 |
mysql> CREATE USER target_user identified by 'MySQLSell8.3'; mysql> GRANT ALL ON *.* TO target_user WITH GRANT OPTION; |
このパターンの処理概要を図にすると以下の流れになります。
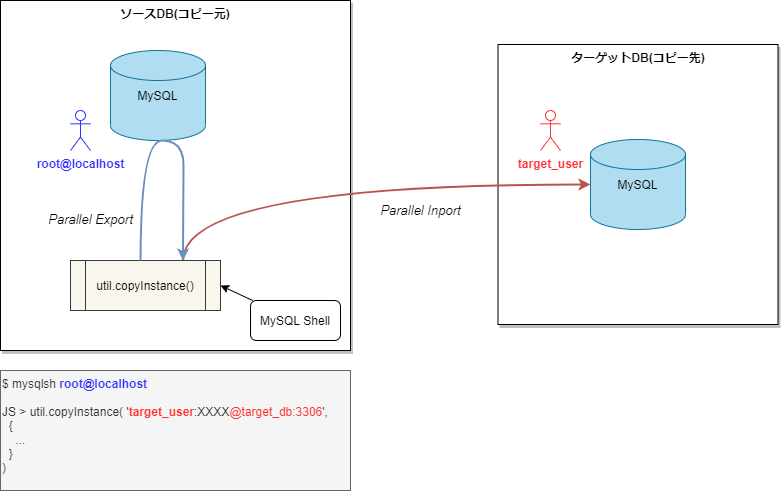
MySQL Shell でソースDBにローカルアクセス(本例では root@localhost で接続)します。
このユーザでデータのダンプを行うことになります。(よって、後述しますが使用するユーザによっては必要な権限に注意が必要です)
|
1 |
$ mysqlsh root@localhost |
ソースDB 接続後に util.copyInstance() を実行します。
第一引数はターゲットDBの接続情報を指定しますが、ここで先ほどターゲットDB側に作成しておいた DB ユーザで接続するようにします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
JS > util.copyInstance( 'target_user:MySQLSell8.3@target_db:3306', { defaultCharacterSet: 'utf8mb4' , consistent: true , tzUtc: true , chunking: true , analyzeTables: 'on' , skipBinlog: true , threads: 8 , showProgress: true , checksum: true , excludeUsers: [ "root@localhost" ] , dryRun: false } ) |
※上記オプション設定は一例です。各オプションの詳細はリファレンスマニュアルの以下セクションをご確認ください。
※ デフォルトのままだと root@localhost のロードで既にターゲット側に存在するためのエラーとなるので、ロード対象から除外しています。
少し長いですが、上のコマンドで実行した結果を貼付けておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
: : Copying DDL, Data and Users from in-memory FS, source: srcdb801:3306, target: dstdb802:3306. SRC: Acquiring global read lock SRC: Global read lock acquired Initializing - done SRC: 1 out of 5 schemas will be dumped and within them 5 tables, 0 views. SRC: 1 out of 5 users will be dumped. Gathering information - done SRC: All transactions have been started SRC: Locking instance for backup SRC: Global read lock has been released SRC: Writing global DDL files SRC: Writing users DDL SRC: Running data dump using 8 threads. Checksumming enabled. NOTE: SRC: Progress information uses estimated values and may not be accurate. TGT: Opening dump... NOTE: TGT: Dump is still ongoing, data will be loaded as it becomes available. TGT: Target is MySQL 8.0.36. Dump was produced from MySQL 8.0.36 TGT: Scanning metadata... TGT: Scanning metadata - done TGT: Checking for pre-existing objects... TGT: Executing common preamble SQL TGT: Executing DDL... TGT: Executing DDL - done TGT: Executing user accounts SQL... TGT: Executing view DDL... TGT: Executing view DDL - done TGT: Loading data... TGT: Starting data load Writing schema metadata - done Writing DDL - done Writing table metadata - done SRC: Starting data dump TGT: Recreating indexes... TGT: Analyzing tables... TGT: Verifying checksum information... 8 thds chksum | 102% (200.00M rows / ~195.73M rows), 79.50K rows/s, 15.69 MB/s TGT: Waiting for more data to become available... Computing checksum - done SRC: Dump duration: 00:26:24s SRC: Checksum duration: 00:11:14s SRC: Total duration: 00:37:26s SRC: Schemas dumped: 1 SRC: Tables dumped: 5 SRC: Data size: 39.54 GB SRC: Rows written: 200000000 SRC: Bytes written: 39.54 GB SRC: Average throughput: 24.96 MB/s 8 thds chksum - 100% (39.54 GB / 39.54 GB), 0.00 B/s, 5 / 5 tables done Recreating indexes - done Analyzing tables - done TGT: Executing common postamble SQL1 / 662 Verifying checksum information - done NOTE: TGT: The redo log is currently disabled, which causes MySQL to not be crash safe! Do not forget to enable it again before putting this instance in production. TGT: 662 chunks (200.00M rows, 39.54 GB) for 5 tables in 1 schemas were loaded in 57 min 56 sec (avg throughput 17.56 MB/s) TGT: 1 accounts were loaded TGT: 0 warnings were reported during the load. TGT: 662 checksums were verified in 31 min 44 sec. --- Dump_metadata: Binlog_file: binlog.000003 Binlog_position: 197 Executed_GTID_set: 0f5d543a-06f3-11ef-8db3-02001701174d:1-2 |
上記は処理が完了した状態の出力ですが、処理中は showProgress オプションを有効にしている場合は実行状況の進捗が逐次表示されます。
ソースDB側でバイナリログ出力を有効にしている場合はバイナリログ情報が、また GTID を有効にしている場合は Executed_GTID_set (=gtid_executed) も取得できます。レプリカ作成時に捗りますね。
※バイナリログ情報を取得するには、データダンプするユーザに REPLICATION CLIENT 権限が必要です。
2. ターゲットDB 上でユーティリティを実行
このパターンでは、ターゲットDB側に MySQL Shell をインストールします。
何らかの理由でソースDB側に MySQL Shell をインストールできない場合に用いるパターンになると思います。
使用する DB ユーザを以下の通りに作成しておきます。
-
ソースDB側にデータダンプを実行する DB ユーザ(本例では
src_user)12mysql> CREATE USER src_user identified by 'MySQLSell8.3';mysql> GRANT EVENT, RELOAD, SELECT, SHOW VIEW, TRIGGER, BACKUP_ADMIN, REPLICATION CLIENT ON *.* TO src_user;- データダンプに最小限必要な権限はグローバルスコープの
EVENT, RELOAD, SELECT, SHOW VIEW, TRIGGERです。 - データ一貫性を保ってダンプを取得する場合(
consistent: true)、BACKUP_ADMINが必要です。
- データダンプに最小限必要な権限はグローバルスコープの
-
ターゲットDB側にデータインポートを実行する DB ユーザ(本例では
target_user)12mysql> CREATE USER target_user identified by 'MySQLSell8.3';mysql> GRANT ALL ON *.* TO target_user WITH GRANT OPTION;- ユーザ情報をインポートする場合、
WITH GRANT OPTIONが必要です。 - 強力な権限のユーザではありますが、このように作成しておくことでインポート時のエラーを避けられます。(役目が終わったら適宜削除するなどしてください)
- ユーザ情報をインポートする場合、
このパターンでは以下の流れになります。
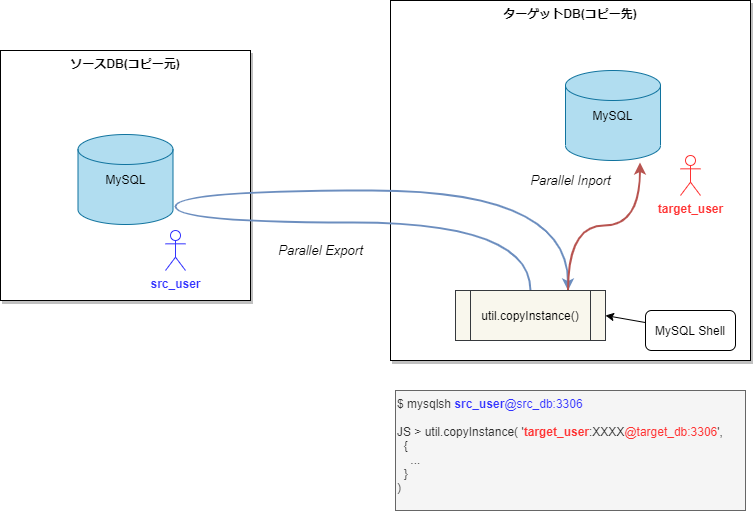
ターゲットDB上から MySQL Shell で ソースDB に接続します。(src_user を使用)
|
1 |
$ mysqlsh src_user@src_db:3306 |
util.copyInstance の第一引数はターゲットDBの接続情報を指定し、DB ユーザは target_user で接続するようにします。
|
1 2 3 4 5 |
JS > util.copyInstance( 'target_user:MySQLSell8.3@target_db:3306', { ... } ) |
※以降は、前述の実行と同じ処理となります。
CLONE プラグインのクローニングとの違い
類似の機能として、 MySQL 8.0 から使用できる CLONE プラグインによる CLONE INSTANCE コマンドでデータコピーする方法もあります。
MySQL :: MySQL 8.4 Reference Manual :: 7.6.7 The Clone Plugin
まず大きく異なるのが、CLONE は 物理データのコピーであるのに対し、Copy Instance ユーティリティは論理データコピーであるということです。
そのため、 CLONE 方式は主に以下の制約があります。
- コピー元・先で OS バージョンが同一であること
- コピー元・先で MySQL シリーズが同じであること
- 例:8.0.34 から 8.0.36 へはコピー可能。8.0 から 8.3 へはコピー不可。
- 暗号化データまたはページ圧縮されたデータをクローニングする場合は、コピー元・先でファイルシステムのブロックサイズが同一であること
※これ以外の前提条件や制約事項については以下のリファレンスマニュアルページを確認してください。
- MySQL :: MySQL 8.4 Reference Manual :: 7.6.7.3 Cloning Remote Data
- MySQL :: MySQL 8.4 Reference Manual :: 7.6.7.14 Clone Plugin Limitations
操作の手軽さに関しては、 CLONE プラグインはセットアップもクローニング実行も非常に簡単なので、上記制約があっても問題ない環境では便利です。(現に InnoDB Cluster でノード追加・削除を行う際の実装として採用されています)
それ以外の、記事冒頭で記載したようなユースケースの、例えば異なる OS バージョンのサーバで稼働するインスタンスからデータをコピーしたい場合(OSバージョンアップ対応など)は、 Copy Instance ユーティリティを利用するという使い分けになると思います。
また、CLONE プラグインによるクローニングはインスタンス全体をまるごと複製します。特定のテーブルやユーザを対象または除外、などといった調整を行いたい場合も Copy Instance ユーティリティを使用すると良いでしょう。
まとめ
データベースのデータコピーは非常に多くのケースで必要になってきますが、新しい Copy Instance ユーティリティという強力な選択肢が増えたことは MySQL ユーザにとっては朗報だと思います。
コピー時間の短縮だけでなく、移植性を高めるための柔軟なオプションを取り揃えており多様なシチュエーションにも対応できますので、ぜひ一度使ってみていただくことをお勧めします!