はじめに
前回、HeatWave と Redshift との TPC-H 派生ベンチマーク比較記事を掲載しましたが、
MySQL Database Service HeatWave と Amazon Redshift の TPC-H 派生ベンチマーク比較 | スマートスタイル TECH BLOG
ちょうどこの記事のベンチマークを追えたタイミングで Redshift の新機能 AQUA (Advanced Query Accelerator) がGAリリースされているのに気付きました。
Amazon Redshift > 最新機能 | AWS は、Amazon Redshift 向けの AQUA の一般提供開始を発表
AQUA (Advanced Query Accelerator) for Amazon Redshift の一般提供が開始されました。
AQUA は、Amazon Redshift のストレージレイヤーにコンピューティングを導入し、他のエンタープライズクラウドデータウェアハウスよりも最大 10 倍高速なクエリパフォーマンスを提供する新しい分散型ハードウェアアクセラレーションキャッシュを提供します。AQUA は Redshift マネージドストレージに記憶される高速キャッシュであり、多くの AQUAノード間でスケールアウトやデータの並行処理が可能になります。
AQUA は、AWS が設計したアナリティクスプロセッサを使用して、大規模なデータセットをスキャン、フィルタリング、および集約するクエリでデータ圧縮、暗号化、データ処理を劇的に高速化します。
この新しいアーキテクチャにより、お客様はより迅速にクエリを実行できるので、たとえデータが大規模でも素早くクエリできるようになり、ダッシュボードで最新情報を確認し、開発時間を短縮でき、システムのメンテナンスがしやすくなります。
当時、こちらの概要説明を読んだ限りでは、ストレージレイヤーを追加し、高速キャッシュでハードウェアアクセラレーションを実現する、というアプローチなので、HeatWave との比較対象としては従来の Redshift よりも適切なのでは?という素朴な疑問が湧きました。
そこで今回は AQUA の機能確認と、HeatWave との比較を行ってみました。
AQUA の確認
まずは公式のマニュアルから使用条件などを確認してみます。
Amazon Redshift クラスター管理ガイド | AQUA (高度なクエリアクセラレータ) の操作 – Amazon Redshift
まず、AQUA を使用するための環境条件は以下の通りとのことです。
- インスタンスタイプは
ra3.4xlargeかra3.16xlarge - Redshift リリースバージョン
1.0.24421以降 - 以下のリージョンで提供
- us-east-1
- us-east-2
- us-west-2
- ap-northeast-1
- eu-west-1
- 追加料金は発生しない
これらの条件を満たす Redshiftクラスターで AQUA の設定を行います。
-
既存のクラスターの場合は、当該機能が既に利用可能な状態ですが、デフォルト値の
Automatic(自動)になっています。
アクション > Configure AQUAに移動し、有効・無効を設定します。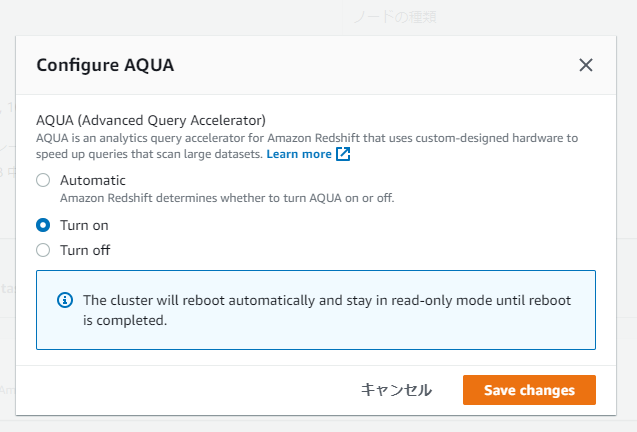
-
新規クラスターを作成する際には、以下の項目で同様に有効・無効を設定します。
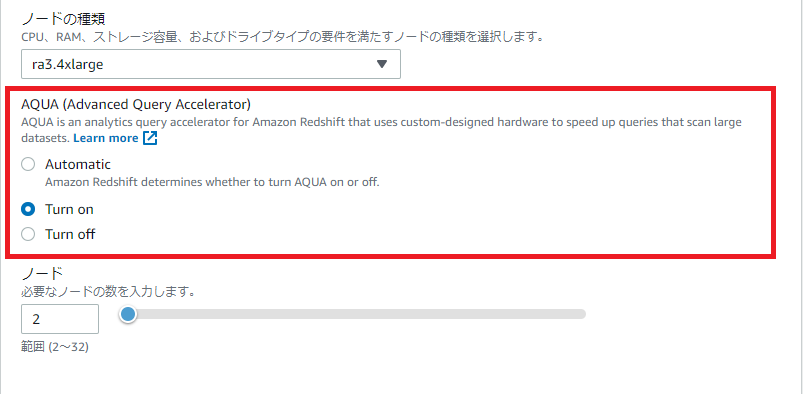
Automatic については、マニュアル上は現在以下のように記載されている通りですが、
Automatic – Amazon Redshiftは、AQUAを使用するかどうかを決定します。これがデフォルトです。現在、このオプションではAQUAは起動しませんが、この動作は変更される可能性があります。
現在は未実装のようで、選択しても無効と同値となります(実際その挙動となりました)。そのため、AQUA を使用したい場合は、明示的に有効にする必要がありました。
クラスター自体の機能の有効化は分かりました。では、具体的にどのような方法で AQUA を利用できるのかを確認してみます。
Aqua を使用するために、データベースやアプリケーションを変更する必要はありません。
Amazon Redshift は、高速化の恩恵を受けるクエリのスキャン部分を特定し、処理のために AQUA にプッシュします。
AQUA は、広範なスキャン、フィルタ、集約を必要とするデータのサブセットに対するクエリのパフォーマンスを自動的に最適化します。
この方法では、AQUA を使用して、大規模なデータセットをスキャン、フィルタ、集計するクエリを実行できます。
AQUA は、LIKE 述語や SIMILAR TO 述語を含むクエリなど、処理負荷の高いスキャン、フィルタ、集約を必要とするクエリに優れています。
この説明からは、どうも特定のクエリで機能することが読み取れましたが、マニュアルにはしっかりとこの疑問に応えるページが用意されていました。
Amazon Redshift は AQUA を使用してクエリを実行するのはいつですか? – Amazon Redshift
Amazon Redshift は、テーブルをスキャンするクエリごとに、スキャンオペレーションを AQUA に送信するか、Amazon Redshift クラスター上でローカルで実行するかを決定します。
スキャンおよび集計操作は、AQUA がサポートする LIKE または SIMILAR TO 式を含む述語が少なくとも 1 つ含まれている場合、AQUA に送信されます。
スキャン操作が AQUA に送信されると、(LIKE または SIMILAR TO 処理だけでなく)操作全体が AQUA で実行されます。
つまり、(現時点の実装では) SELECT の述語に LIKE または SIMILAR TO を含むクエリのみ、AQUA ノードにプッシュされ、アクセラレーションの恩恵を受ける、ということのようです。
現時点の実装では、と書きましたが、こちらの公式ブログに記載されていまして、今後、サポートされるクエリ対象が追加されていく予定とのことですので、まだ限定的な機能であるようです。
AQUA (Advanced Query Accelerator) – A Speed Boost for Your Amazon Redshift Queries | AWS News Blog
AQUA の効果を試してみる
前回の記事でベンチマークの際に使用した TPC-H データが S3 にアップロード済みなのでそのまま利用します。
AQUA 用の Redshift クラスターは以下の構成で新規作成しました。
環境情報
Redshift
- ra3.4xlarge
- 12vCPU, 96GiBメモリ, ストレージ容量 128TB
- AQUAを有効化
- 2ノード
- クラスターのアクセス許可 (オプション)
- IAMロールをアタッチ (前回記事を参照)
- 追加設定
- 拡張された VPC のルーティングを有効化
TPC-H用テーブル作成、S3からRedshiftへデータロード、まで、前回記事の手順と同一の内容で実施しました。
HeatWave
前回記事とほぼ同一スペックの環境です。
- MySQL.HeatWave.VM.Standard.E3 2ノード(最小構成)
- MySQL 8.0.25
実測クエリ
前述の通り、LIKE または SIMILAR TO を含むクエリが AQUA の対象となるということでした。
適当なクエリを作成するよりは、折角 TPC-H のデータなので、条件に合致しそうな TPC-H クエリを探してみました。
実際のところ、Redshift 用クエリで SIMILAR TO を使用しているクエリは一つもありませんでしたが、
クエリ No.9 のサブクエリで PART.P_NAME カラムに LIKE 検索を行っている箇所がありました。
awslabs 公開スクリプト
amazon-redshift-utils/query_0.sql · awslabs/amazon-redshift-utils · GitHub
Oracle 公開スクリプト
heatwave-tpch/hq9.sql · oracle/heatwave-tpch · GitHub
このクエリをベースに、演算子を変更した各パターンで処理時間を実測してみます。
-
LIKE (オリジナルのまま)
1P_NAME LIKE '%green%' -
SIMILAR TO (※Redshiftのみ)
1P_NAME SIMILAR TO '%green%'
そして、AQUAのドキュメントには明記されていませんが、Redshift (PostgresSQL) では、LIKE または SIMILAR TO 以外のもう一つのパターンマッチング検索方法として POSIX 演算子 があり、この場合はどうなるのか(AQUAは機能するのか)気になったので、テストパターンに入れてみました。
-
POSIX 演算 (※Redshiftのみ)
1P_NAME ~ '.*green.*'
なお、HeatWaveでは、REGEXP 演算子が代替となりますので、以下のように変更しました。
-
REGEXP (※HeatWaveのみ)
1AND p_name REGEXP '.*green.*') AS profit
処理時間のまとめ
AQUA 有効/無効で、各クエリを3回実行した結果を下表にまとめてみました。
なお、Redshift はリザルトキャッシュを無効(set enable_result_cache_for_session=off;)とし、
Redshift・HeatWave いずれも初回実行時は測定から除外、2~4回の計3回の平均実行時間を算出しています。
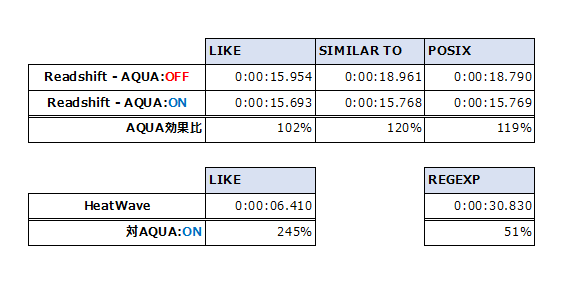
AQUA の効果については、
LIKE検索での AQUA の効果は僅か2%の向上でした。- 一方、
SIMILAR TO検索では、20% の速度向上が見られました。 - そして、マニュアル上には明記されていなかった `POSIX 演算子での検索も、AQUA へプッシュされ、ほぼ SIMILAR TO 検索と同じ効果が出る結果となりました。
HeatWave の性能と AQUA との対比では、
-
MySQL には
SIMILAR TO演算子およびその代替となる機能は存在しないので、LIKE検索との比較がメインとなりますが、
AQUA 有効時の Redshift との比較では、2.5倍近く HeatWave のほうが処理時間が短い という結果となりました。 -
HeatWave での
REGEXP演算子検索は、Redshift の POSIX 演算子検索に相当します。
この比較では HeatWave は AQUA の約2倍の時間が掛かっており、Redshift に軍配が上がりました。(AQUA 無効でも Redshiftのほうが速いことが分かります)
AQUA が使用されたかどうかを確認する方法
AQUAが使用されたかどうかを確認する方法 | Amazon Redshift は AQUA を使用してクエリを実行するのはいつですか? – Amazon Redshift
上記マニュアルに記載されている通り、クエリ実行後に、SVL_QUERY_SUMMARY ビューのクエリ実行ステップから、ラベルを検索することで AQUA へプッシュされたかを確認することができます。
|
1 2 3 4 5 |
dev=# select * from svl_query_summary where query = 20499 and label ~ 'Aqua'; userid | query | stm | seg | step | maxtime | avgtime | rows | bytes | rate_row | rate_byte | label | is_diskbased | workmem | is_rrscan | is_delayed_scan | rows_pre_filter --------+-------+-----+-----+------+---------+---------+---------+----------+----------+-----------+------------------------------------+--------------+---------+-----------+-----------------+----------------- 100 | 20499 | 2 | 4 | 7 | 1745768 | 1566963 | 3263067 | 26104536 | 3263067 | 26104536 | scan tbl=866 name=Aqua Scan part | f | 0 | f | f | 3263067 (1 row) |
ただ、これだけでは断片的なので、クエリ実行ステップ全体を俯瞰したい場合は、以下のようにクエリします。
|
1 2 3 |
dev=# select * from svl_query_summary where query = 20499 order by stm, seg, step; ※出力結果が多い為割愛 |
なお、マニュアルに記載されていますが、EXPLAIN で取得できる実行計画には、AQUA が使用できるかどうかの情報は表示されません。
ちなみに、HeatWave はというと、(同じく EXPLAIN による) 実行計画で、Extra: Using secondary engine RAPID と表示されれば、HeatWave へオフロードされることを確認できます。
その他判明したこと
AQUA にプッシュされなかった事例
以下マニュアルには、AQUA にプッシュされず、従来の Redshift と同じ処理となってしまうクエリの条件が明記されています。
Aqua の考慮 | Amazon Redshift は AQUA を使用してクエリを実行するのはいつですか? – Amazon Redshift
次の SQL クエリのタイプは、現在 AQUA でサポートされていません。それらを含むクエリは、Amazon Redshift クラスターでローカルで実行されます。
今回 TPC-H クエリの No.9 以外で、No.13 のクエリでは NOT LIKE が使用されていたので高速化するか試してみたところ、AQUA へはプッシュされませんでした。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
set query_group='RSPERF TPC-H 1.13'; set enable_result_cache_for_session=off; SELECT C_COUNT, COUNT(*) AS CUSTDIST FROM ( SELECT C_CUSTKEY, COUNT(O_ORDERKEY) FROM CUSTOMER left outer join ORDERS on C_CUSTKEY = O_CUSTKEY AND O_COMMENT NOT LIKE '%special%requests%' GROUP BY C_CUSTKEY ) AS C_ORDERS (C_CUSTKEY, C_COUNT) GROUP BY C_COUNT ORDER BY CUSTDIST DESC, C_COUNT DESC ; |
NOT が原因かと思い、外して実行してみましたが変化なく…
LIKE自体は外部結合条件に位置しているので、ドキュメントにある 述語なしの SELECT クエリ として対象外と判定されているのかもしれません。
なお、HeatWave では、オプティマイザ・トレースを用いて、クエリがHeatWaveにオフロードされない具体的な原因を探ることが可能です。
MySQL :: HeatWave User Guide :: 6 Running Queries
(前回記事のような)全体性能の比較は?
ここまでの確認で明白な通り、AQUA によるクエリアクセラレーションは、特定条件のクエリ(LIKE,SIMILAR TO)が実行された場合のみ、有効に機能します。
TPC-H 20クエリでは、AQUA の条件に合致するクエリが少なく(3/20)、前回記事のような、TPC-H の 20クエリ幾何平均実行時間での比較はあまり参考にならないような気もしました。
と言いつつ、一応、計測してはみたので、結果を貼っておきます。
左から3つのデータは前回記事の結果で、右側2つのデータが今回の ra3.4xlarge の AQUA: OFF, ON の場合となります。
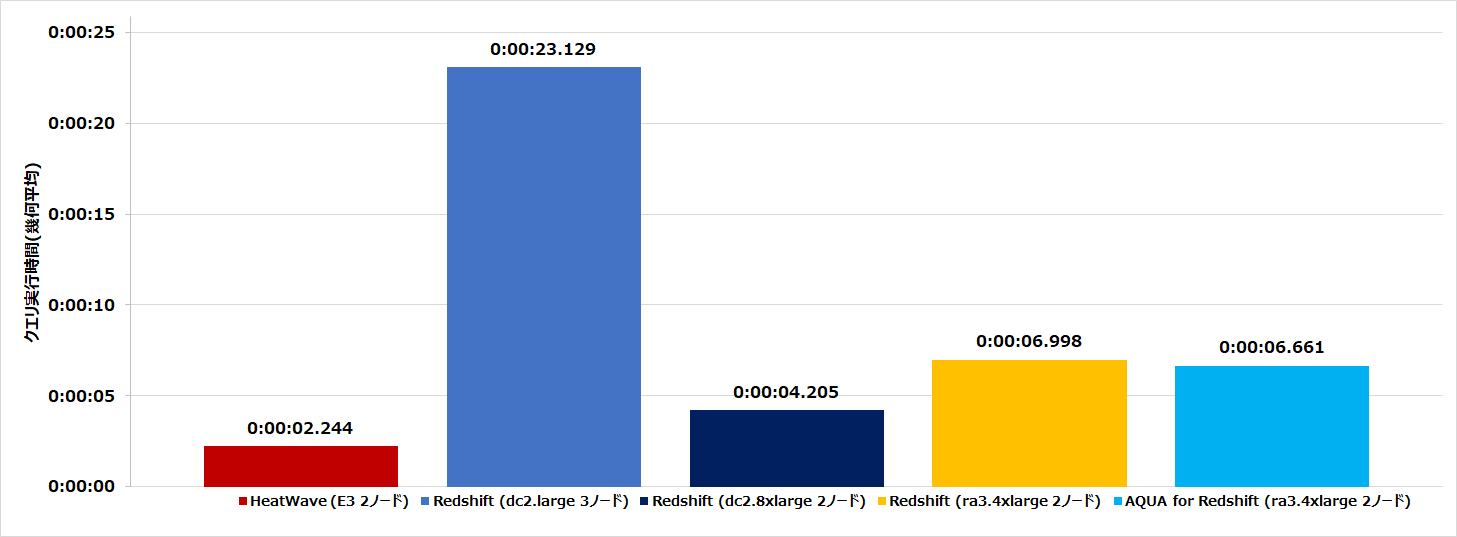
(※クリックして拡大)
案の定、AQUA:ON はほぼ素の ra3.4xlarge 2ノードとの結果と変わらない結果となってしまいましたので、そういった観点での参考データと捉えていただいた方が賢明です。
前回記事同様、年間クラウドサービス料のコスト比較も掲載しておきます。
AQUA を使用したい場合、AQUA を有効化すること自体に追加料金は発生しませんが、ra3.4xlarge か ra3.16xlarge を選択する必要があり、インスタンス使用量以外にRedshift マネージドストレージ(GB 単位の固定月額料金) が追加で発生する点が、コスト算出時の考慮として前回記事と異なる点です。
Redshift マネージドストレージの料金 | 料金 – Amazon Redshift | AWS
下記の表では、Redshift マネージドストレージ 300GB, 1ドル110円換算とした場合の算出例です。
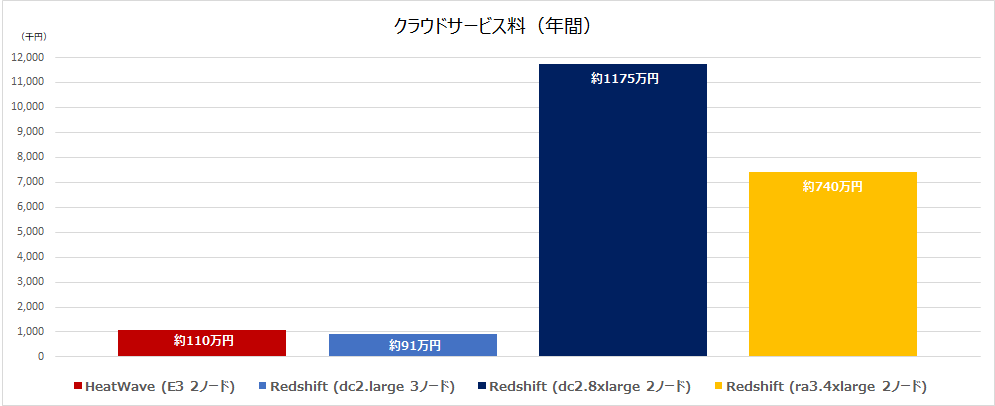
(※クリックして拡大)
まとめ
今回の検証で、AQUA について知ることが出来ました。
(当初、仕様に対する誤解があり、払拭できて良かったと思います)
まだ、実装されたばかりで、サポートされているクエリのタイプもパターンマッチング検索のみという状況ですが、今後、サポート対象が拡充され、またユーザーが意識せずとも Automatic に Redshift が AQUA へプッシュするようになっていく展望が期待できますね。
SIMILAR TO自体、ほぼ PostgreSQL でのみ使用できる演算子だと認識していますが、現 Redshift ユーザーや、PostgreSQL ベース の DWH を移行を検討していて、かつ SIMILAR TO の高速化を狙いたい場合、現時点で AQUA の効果は高いと言えます。
ただやはり、一般的には、LIKE 検索が多く使用されると思います。LIKE 検索の単性能比較で HeatWave が AQUA(ON) よりも 2.5倍速い という事実が確認できました。
前回記事からの続きとなりましたが、HeatWave のご利用を検討の際には、上記の点をご留意頂ければと思います。