はじめに
MySQL Database Service (MDS) 専用の分析クエリアクセラレーター HeatWave ですが、実際に数百倍~数千倍という分析処理の時間短縮が見られたというユーザー検証結果も国内外で多数公開されており、今、もっとも注目される大規模データ分析クラウドサービスと言えるのではないでしょうか。
その高性能をユーザーにも広く確かめてほしいという意図から、Amazon Redshift, Aurora とパフォーマンス比較の具体的な方法と結果が、Oracle 社の公式ドキュメントとして公開されています。
HeatWave Performance Benchmark | Oracle 日本
TPC-H ベンチマーク(集計・意思決定システムの性能測定として業界標準のベンチマークツール)を元にした派生クエリの実行時間を計測する内容になっています。
非常に特徴的と言えるのは、Oracle 製品以外の環境セットアップ手順も具に説明されている点で、Oracle社としても異例のことだそうです。
そして、肝心の Oracle社による比較結果では、以下のような圧倒的な性能差(と年間コスト)が報告されています。
- OCI コンピュートインスタンスにインストールした MySQL の 400倍
- Amazon Aurora の 1100倍
- Amazon Redshift の 2.7倍
今回の記事では、この Oracle社が公開する TPC-H 派生ベンチマークを実際に試してみて結果を確認していきたいと思います。
ベンチマーク計測対象
以前掲載しました RDS for MySQL と MDS のベンチマーク比較記事の流れから、今回も AWS のサービスとの対比を行います。
手軽に始められるクラウドサービスだからこそ、最小構成だとどれくらいの差があるのか気になる方も少なくはないだろうと考え、まずは HeatWave と Amazon Redshift の、それぞれ最小(最安)構成での比較を行ってみようと思います。
Scale Factor(データサイズ指標)
TPC-H におけるベンチマークを計測する際のデータの大きさを表す指標値です。
今回の検証では、300(GB) としました。
Scale Factor の詳細については、TPC-H 仕様 4.1.3.1 章をご確認ください。
シェイプ, インスタンスタイプの選択
HeatWave
- MySQL.HeatWave.VM.Standard.E3 (16 OCPUs/512GB RAM)
- 1 MDS(フロント) + 2 Heatwave Cluster nodes
- MySQL Version: 8.0.23
- ストレージ:1TB
Amazon Redshift
- dc2.large (2 vCPUs/15GB RAM) × 3 nodes
- ストレージ:480GB (160GB * 3)
環境構築
前提として、いずれのサービスも、デフォルトからパラメータ変更は行いません。
HeatWave
- ベンチマーククエリ実行用のクライアント(Compute)を先に作成しておきます。
- テストデータ生成時の一時格納領域としてブロックボリュームをマウントしておきます。
- クエリ実行クライアント上に、TPC-Hデータ生成ツール をダウンロード、配置しておきます。
- TPC-Hデータ生成ツールを使用してテストデータを生成します。
- ツールは、MySQL用にビルドしてから使用可能となります。
- インストールスクリプト(itiut/tpch-patches)が公開されていますので、有難くこちらを用いてビルドします。
TPC-H データ生成ツールの最新バージョンに合わせて修正が必要となりますが、詳細は以下の記事が参考になると思います。
データベースベンチマークTPC-HをMySQLで実行する(TPC-H v2.18.0) – Qiita dbgenコマンドは実行カレントディレクトリ配下に生成データを出力しますので、ブロックボリュームのマウントポイントディレクトリ配下で実行するよう、ご注意ください。
- 生成したテストデータは、Object Storage にアップロードしておきます。
e.g.)
1234$ cd /mnt/dbgen$ for datafile in $(ls); dotime oci os object put --bucket-name tpc-h-data-bucket --file $datafile --name sf30/$datafiledone - ベンチマーククエリ実行クライアント上に、HeatWave 用の公開ベンチマークスクリプトをダウンロードしておきます。
GitHub – oracle/heatwave-tpch: SQL scripts for HeatWave benchmarking1$ git clone https://github.com/oracle/heatwave-tpch.git - HeatWave の基本的な構築手順は、過去ブログ記事で紹介させていただきましたので是非そちらをご覧ください。
MySQLで分析処理を高速化させる HeatWave を使ってみた | スマートスタイル TECH BLOG- フロント MDS インスタンスを作成後、
heatwave-tpch/TPCHディレクトリ内にあるcreate_tables.sqlを実行し、TPC-Hテスト用のスキーマを作成します。(データベース名はtpch_1024になっていますが、お好みで変更しても問題ありません) - そして、先ほど生成したTPC-Hデータを フロント MDSにインポートします。(MySQL Shell Parallel Table ImportUtilityを使用)
e.g.)
1234567891011$ for datafile in $(oci os object list --bucket-name tpc-h-data-bucket | jq -r '.data[].name'); dotime mysqlsh mysql://admin@<フロントエンドMDSエンドポイント>:<ポート番号> \--ssl-mode=DISABLED \-- util import-table ${datafile} \--schema=tpch_1024 \--table=$(basename $datafile .tbl | tr '[:lower:]' '[:upper:]') \--fieldsTerminatedBy='|' \--threads=16 \--osBucketName='tpc-h-data-bucket' \--osNamespace='XXXXXXX'done - MDSインスタンスにHeatWaveクラスターを追加したあと、
heatwave-tpch/TPCHディレクトリ内にあるsecondary_load.sqlを実行して、テストデータを HeatWave用に構成し、HeatWaveクラスターにロードします。1$ mysql --show-warnings -vvv tpch_1024 < secondary_load.sql
- フロント MDS インスタンスを作成後、
Redshift
- 基本的な準備の流れは HeatWave と同じになります。
- Redshift クラスターの構築方法は、本記事では割愛します。
- Oracle社のドキュメントで提案されている通り、拡張VPCルーティングを有効化しておきます。
- ベンチマーククエリ実行クライアント上に、Redshift 用の公開ベンチマークスクリプトをダウンロードしておきます。
1$ git clone https://github.com/awslabs/amazon-redshift-utils.git
- TPC-H テストデータは、S3 バケットにアップロードしておきます。
e.g.)
12$ aws s3 mb s3://tpch-data$ aws s3 sync dbgen s3://tpch-data/dbgen - 接続、クエリ実行は、お好みの方法で問題ありません。(Redshift コンソールなど)
- 今回は、
psql(PostgreSQL クライアントツール) を使いました。e.g.) Ubuntu20.04 への簡易インストール手順
12345678sudo apt install -y postgresqlwhich psqlpsql --versionpsql -h [Redshift EIP] -p 5439 -U awsuser -d devvi ~/.pgpass[Redshift EIP]:5439:dev:awsuser:[管理ユーザーのパスワード]chmod 600 ~/.pgpasspsql -h [Redshift EIP] -p 5439 -U awsuser -d dev
※初期作成DBをデフォルトの
devのままにした場合の例ですので、適宜変更してください。 - 今回は、
-
事前準備として、Redshift 上に TPC-H テスト用テーブルを作成し、S3 から Redshift へデータロードするという処理が記載された、以下のスクリプトファイルを実行することになります。
1amazon-redshift-utils/src/CloudDataWarehouseBenchmark/Cloud-DWB-Derived-from-TPCH/3TB/ddl.sqlテーブル作成先のデータベースは指定されていないので、任意のデータベースで構いません。
ここでの注意点としては、スクリプトの後半に記載された S3 から Redshift へデータロードする下記のコマンドは修正が必要で、当然ながら環境に即して S3バケットのパス・自身の接続認証情報に書き換える必要があります。12copy region from 's3://redshift-downloads/TPC-H/3TB/region/' credentials 'aws_access_key_id=<USER_ACCESS_KEY_ID> ;aws_secret_access_key=<USER_SECRET_ACCESS_KEY>' gzip delimiter '|';(...)今回は、事前にIAMロールを作成し、ロールの ARN を取得したうえで、以下のように書き換えました。
1copy region from 's3://tpch-data/dbgen/region.tbl' credentials 'aws_iam_role=arn:aws:iam::XXXXXXXX:role/hoo-redshift-role' delimiter '|' region 'ap-northeast-1';
ベンチマーク実行手順
- 各サービスごとに用意されているクエリのスクリプトを実行し、所要時間を計測します。
- 複数回実行し、初回実行は計測対象から除外します。
- 出力結果を
/dev/nullに捨てるようにしておくと、確認が捗ります。
Redshift
先に Redshift からクエリ実行時間を計測していきます。
Redshift 用として用意されているスクリプトは、query_0.sql の1ファイルのみでした。
こちらは、全22種のクエリが列挙されています。
スクリプトファイルの先頭に \timing と \o /dev/null を追加してから実行します。
e.g.)
|
1 2 3 |
$ cd Cloud-DWB-Derived-from-TPCH/queries $ sed -i.bk '1i\\\timing\n\\o /dev/null' query_0.sql $ psql -h [Redshift EIP] -p 5439 -U awsuser -d dev -f query_0.sql |
HeatWave
HeatWave 用に用意されているスクリプトは、hq1.sql~hq22.sql ですが、hp2,17,20 は無く、全 19ファイルとなっていました。
TPC-H 公式のクエリは全22種あるので、3クエリが対象外となっています。(その理由は不明です)
e.g.)
|
1 2 3 4 |
$ cd heatwave-tpch/TPCH $ mysql mysql> pager cat > /dev/null mysql> source hqXX.sql |
Redshift のクエリと実行結果(取得件数)が異なっていたクエリの条件修正
No.11(hq11.sql) ですが、そのまま実行すると結果が0件となってしまいました。
(Redshift側のクエリを確認してみると、実行結果は 6634534件)
クエリの差分を確認すると、検索条件が異なっていたため、HeatWave用の hq11.sql も同条件となるように修正しました。
|
1 2 3 4 5 6 7 8 9 10 |
WHERE (...) AND N_NAME = 'SAUDI ARABIA' (...) HAVING ... SUM(PS_SUPPLYCOST * PS_AVAILQTY) * 0.0000000333 (...) WHERE (...) AND N_NAME = 'SAUDI ARABIA') |
計測結果
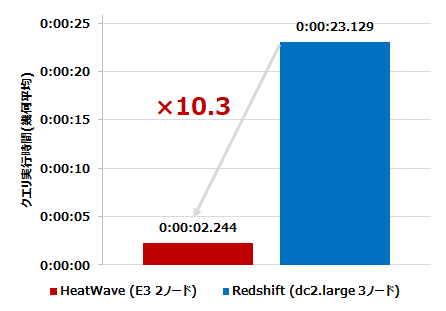
ケース1: 各サービス最小構成同士
全22クエリ中19クエリの処理時間の幾何平均を算出した結果、最小構成同士の比較では、HeatWave は Redshift の 10.3倍 の性能が出る ということが分かりました。
ケース2: HeatWave 2ノードのCPU数と同等の構成となる Redshift インスタンスタイプで比較
HeatWave のシェイプは、現在1タイプのみ選択が可能で、非常に高いスペックです。(1ノード当たり 16 OCPUs/512GB RAM)
そのため、ケース1 の比較では、Redshift dc2.large とであれば、このような差が出てしまうのは明白と考えるのが自然です。
そこで、HeatWave 2ノードのCPU数(64vCPUs 相当)の Redshift とでは、どのような結果となるか、追加検証してみました。
Amazon Redshift
- dc2.8xlarge (32 vCPUs/244GB RAM) × 2 nodes
- ストレージ:5.12TB (2.56TB × 2)
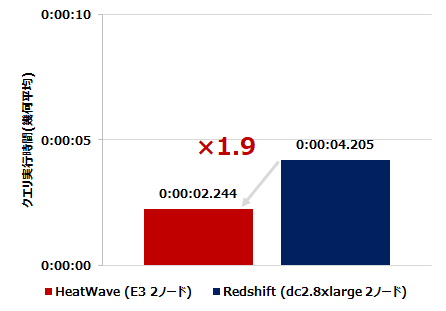
結果、このケースでは HeatWave が約2倍速いということが確認できました。
参考:コスト比較(クラウドサービス年間費用)
年間のクラウドサービス料(概算)でも比較してみます。
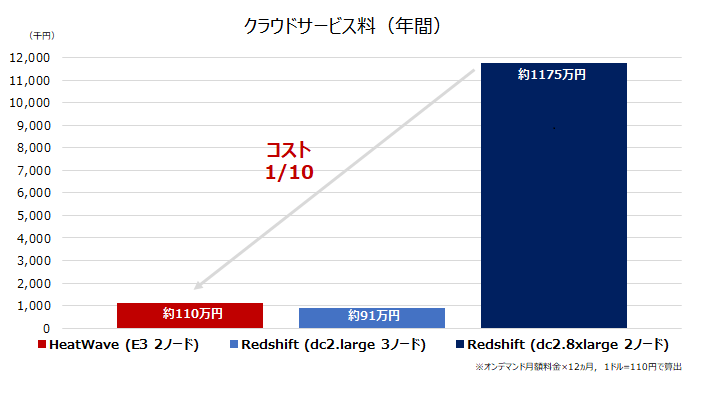
Redshift dc2.large はミニマムスペックが故、HeatWave のほうが若干費用は上となります。
しかし、前述のケース2(同CPU数スペック比較)という観点では、HeatWave が Redshift の約 1/10 のコストで利用できることが分かります。
Redshift はユースケースに応じたインスタンスタイプ(従量課金制のマネージドストレージタイプなど)が選べるのがメリットですが、HeatWave と同スペック(同CPU数)となると、性能面・コスト面で HeatWave に軍配が上がるのではないかと言えます。
注:本記事執筆時(ベンチマーク計測後)、実にタイムリーと言うべきか… AQUA (Advanced Query Accelerator) for Amazon Redshift がリリースされました。
AQUA (Advanced Query Accelerator) – Amazon Redshift クエリをブースト | Amazon Web Services ブログ
パフォーマンス検証の観点では、HeatWave と真に比較すべき対象は AQUA for Amazon Redshift と考えますが、今回は入れ違いでした…
後日、本記事の続きとして検証できればと考えています。
まとめ
TPC-H派生クエリを用いて実際にベンチマーク計測してみた結果では、以下の通りとなりました。
- 各サービスの最小(最安)構成で約10倍の性能差
- 同CPU数スペックのインスタンスタイプとの比較では、約2倍の性能差かつ約1/10のコスト差
ご利用のシステムの分析処理の改善に繋がるか、是非、実際の環境で実行されるクエリで HeatWave の性能検証を行っていただきたいですが、その前段の PoC 実施を判断する要素の一つとして、本記事で紹介したベンチマーク比較を行ってみてはいかがでしょうか。