
はじめに
過去弊社ブログでも何度か取り上げている Orchestrator(MySQL用高可用性&レプリケーション管理ツール)ですが、GAリリースバージョン v3.2.3 のリリースノートをチェックしたところ Group Replication の初期サポート実装が追加されています。
- Feature Request: Add support for MySQL Group Replication · Issue #1179 · openark/orchestrator · GitHub
- Add basic support for group replication by ejortegau · Pull Request #1180 · openark/orchestrator · GitHub
- Release GA release v3.2.3 · openark/orchestrator · GitHub
Add basic support for group replication #1180 by @ejortegau
- FAQ : orchestrator/faq.md at master · openark/orchestrator · GitHub
今回の記事では、この内容について確認してみたいと思います。
変更点を確認してみる
上記の Pull Request #1180 および FAQ の Group Replication に関する記載内容から今回の「ベーシックサポート」の内容を拾ってみます。
- Group Replication(シングルプライマリーモードのみ)をサポート
- Orchestrator は
plain-old-MySQL-replicationのサポートを根幹に置いているので、シングルプライマリーモード構成であれば、各セカンダリーはプライマリーからのレプリカと見做せるためのようです。
- Orchestrator は
- UI上でクラスターを指定してトポロジーを確認すると、グループメンバーが1クラスター内に全て認識・表示されるようになりました。
- これまでのバージョンでは、Group Replicationをトポロジーグループとして識別できず、各メンバー毎に表示するしかできませんでした。
- 専用のアイコンが表示されるようになりました。(アイコンにマウスオーバーするとGroup Replication上のロールとステータスがポップアップ表示されます)
- 以前のバージョンまでは Group Replication のメンバーからレプリケーションされた非同期レプリカ の GTID を errant として見做していたが、そうではなく正常と識別するようになりました。
- ユーザーが、Orchestrator 経由で Group Replication に対して誤ったトポロジー変更を実行することを防ぐようになりました。
具体的には、以下のような操作を行うとエラーとなります。- プライマリーをセカンダリーからレプリケートするように設定しようとする
- セカンダリーを別の場所からレプリケートするように移動させようとする
動作確認してみる
簡易的ではありますが、MySQL 8.0.21 - 3ノード Group Replication環境(MySQL Shell の InnoDB Cluster デプロイ用APIを使って構築)を Orchestrator v3.2.3 にてディスカバリーさせ、Group Replication のトポロジー変化にどのように対応しているのか、確認してみました。
事前に必要な設定
Group Replication のメンバーステータスを取得・監視するため、Orchestrator クライアントユーザー(MySQL側ユーザー)に、performance_schema.replication_group_members の参照権限を追加する必要があります。
orchestrator/configuration-discovery-basic.md at master · openark/orchestrator · GitHub
|
1 |
mysql> GRANT SELECT ON performance_schema.replication_group_members TO 'orchestrator'@'orc_host'; -- Only for Group Replication / InnoDB cluster |
※ユーザー名・ホスト名は環境に合わせて適宜変更してください
トポロジー・グループメンバーの状態表示
基本的には、上述のperformance_schema.replication_group_membersテーブルから読み取った状態を表示していることが確認できます。
- 正常時
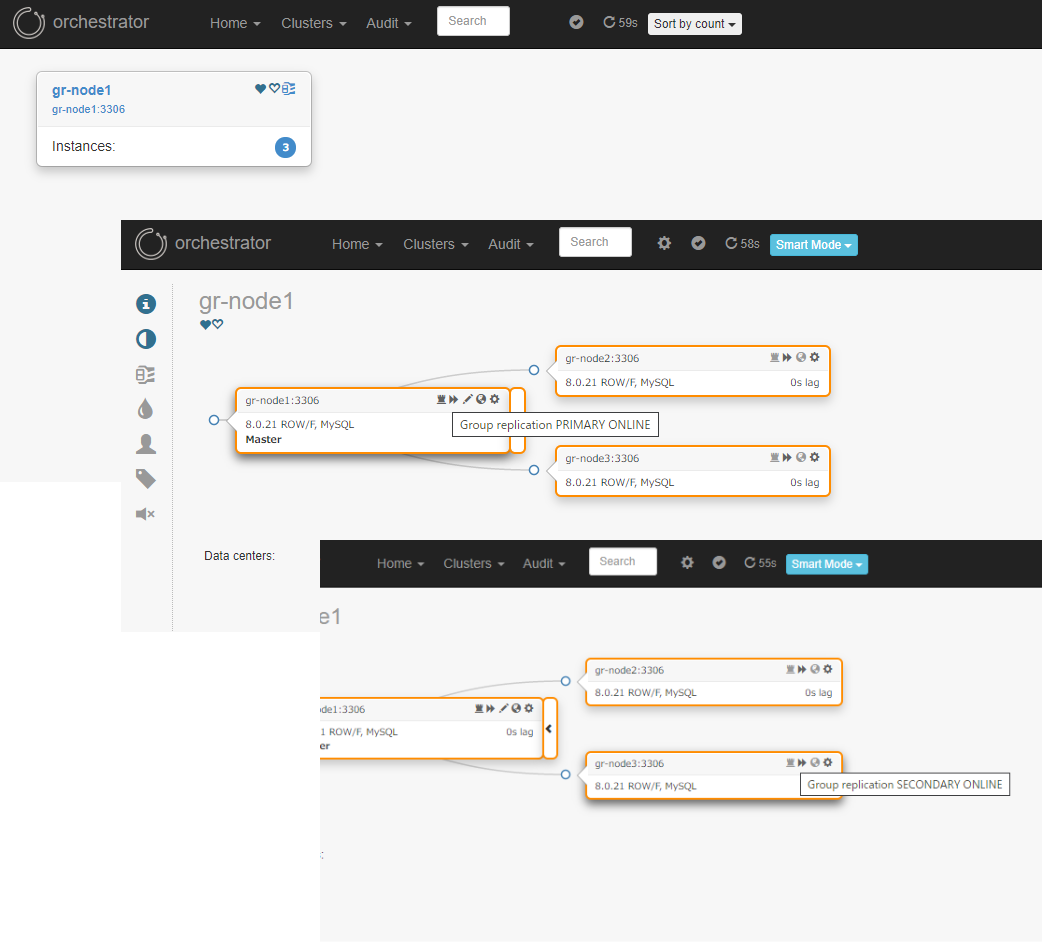
ただ、
orchestrator-clientでトポロジーを確認したところ、グループメンバーの最後のノードしか表示されません…
恐らくAPIのBugかもしれませんので、後ほど Issue をあげてみようと思います。123456$ orchestrator-client -c topology -i gr-node1gr-node3:3306 [0s,ok,8.0.21,ro,ROW,>>,GTID]$ orchestrator-client -c all-instancesgr-node1:3306gr-node2:3306gr-node3:3306 - セカンダリーノード停止時
通常のレプリケーション構成の場合と同じ仕様で、停止ノードが黒枠で表示されています。
ただ、アイコンのポップアップでは ONLINE のままになっていますね…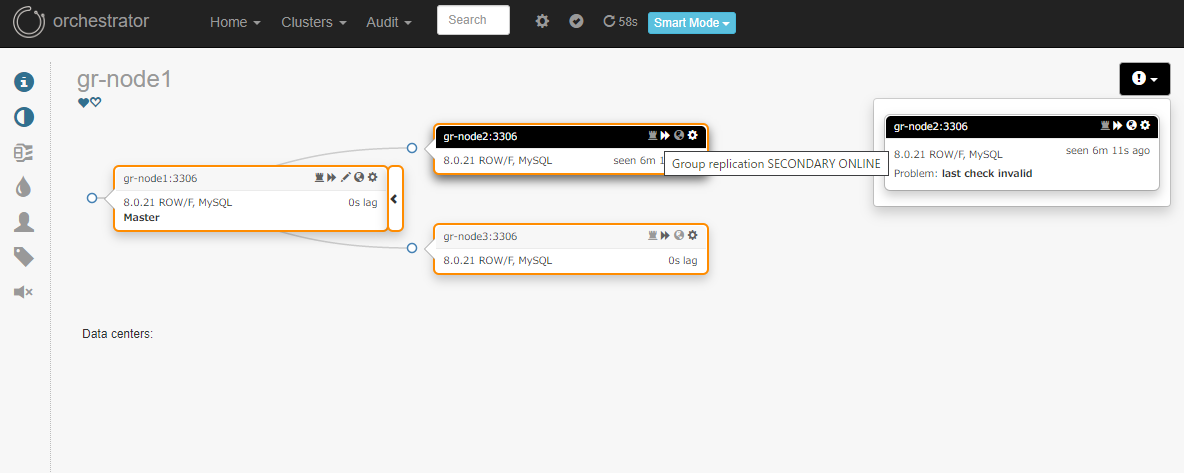
これは監視対象テーブル上に停止したノードのレコードが無いからなのかと推察します。
12345678mysql> select * from performance_schema.replication_group_members;+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+| group_replication_applier | dc8d56e7-0dfc-11eb-b100-52540082f717 | gr-node1 | 3306 | ONLINE | PRIMARY | 8.0.21 || group_replication_applier | dc9ca94b-0dfc-11eb-b087-525400a1134a | gr-node3 | 3306 | ONLINE | SECONDARY | 8.0.21 |+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+2 rows in set (0.00 sec)MySQL Shell からステータスを確認してみますと確かに MISSING になっているので、この場合はこのようなステータスが反映された方がより良いかもしれません…
12345678910111213141516171819202122232425MySQL gr-node1:33060+ ssl JS > cluster.status(){"clusterName": "myCluster","defaultReplicaSet": {"name": "default","primary": "gr-node1:3306","ssl": "REQUIRED","status": "OK_NO_TOLERANCE","statusText": "Cluster is NOT tolerant to any failures. 1 member is not active","topology": {(...)"gr-node2:3306": {"address": "gr-node2:3306","mode": "n/a","readReplicas": {},"role": "HA","shellConnectError": "MySQL Error 2003 (HY000): Can't connect to MySQL server on 'gr-node2' (111)","status": "(MISSING)"},(...)},"topologyMode": "Single-Primary"},"groupInformationSourceMember": "gr-node1:3306"}その後、起動してグループに再参加させている途中の RECOVERING ステータスは垣間見ることが出来ました。
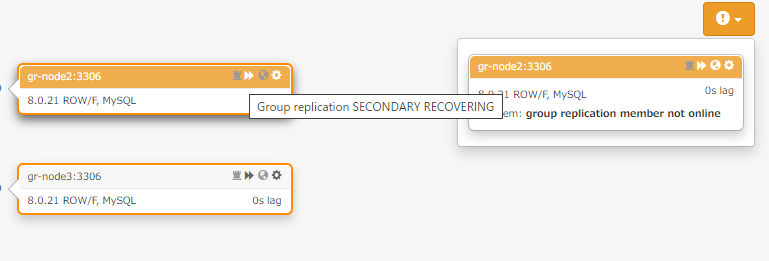
-
プライマリーノード停止時
プライマリーのgr-node1を停止すると、トポロジーが再グループ(分断)されました。
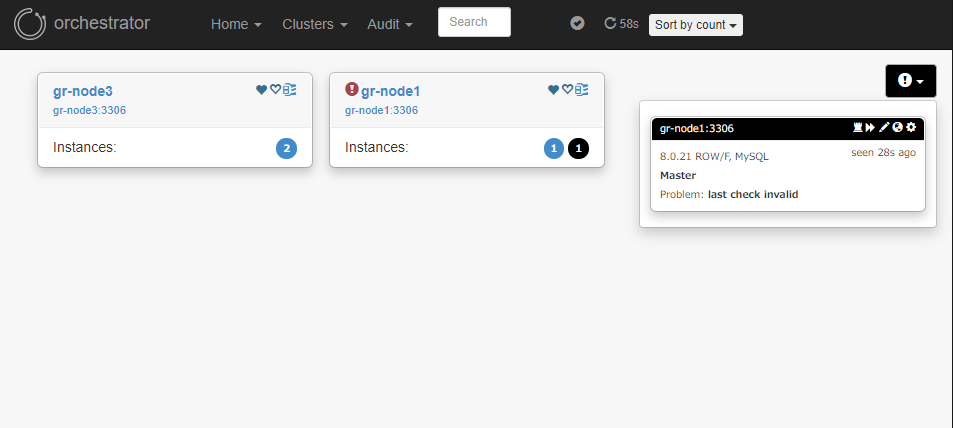
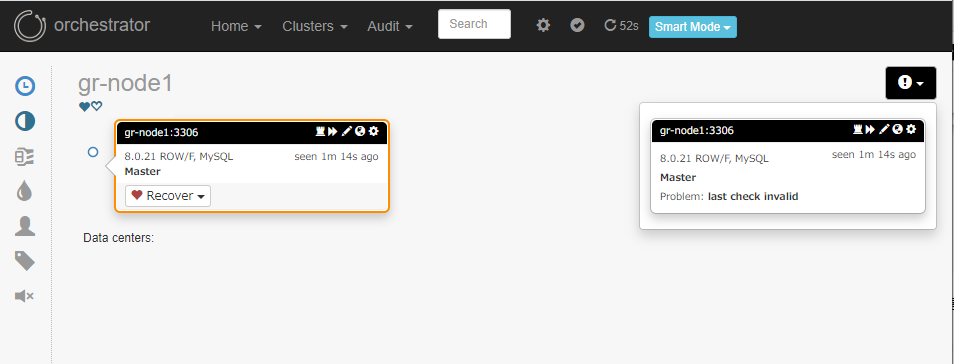
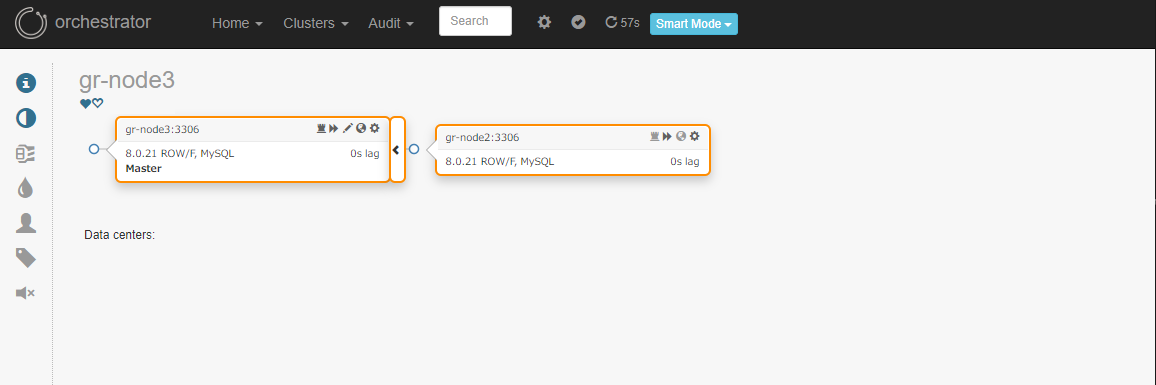
残アクティブノードのグループは以下のように表示されています。
元プライマリーをグループレプリケーションに復帰させると、gr-node3クラスターのトポロジーに再グルーピングされました。
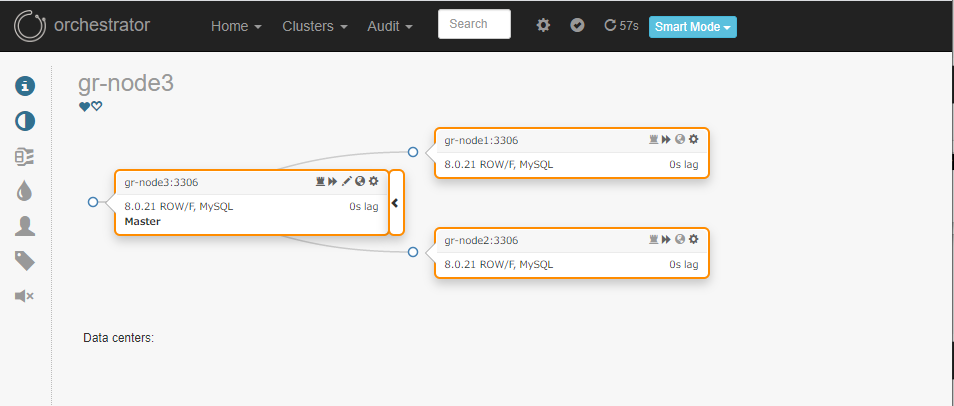
グループレプリケーションメンバーの障害復旧は正常に行われ、Orchestratorは復旧後の状態を正常に把握できています。
あくまで、障害時の高可用性はグループレプリケーション本来の挙動に則っていて、Orchestrator が自動リカバリーを行ってはいないようです。(当然と言えばその通りですが) -
プライマリー変更時
12345678910MySQL gr-node1:33060+ ssl JS > cluster.setPrimaryInstance('gr-node1')Setting instance 'gr-node1' as the primary instance of cluster 'myCluster'...Instance 'gr-node1:3306' was switched from SECONDARY to PRIMARY.Instance 'gr-node3:3306' was switched from PRIMARY to SECONDARY.Instance 'gr-node2:3306' remains SECONDARY.WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using dba.getCluster().The instance 'gr-node1' was successfully elected as primary.プライマリーがgr-node1に戻ったことを反映させています。

-
メンバー追加時
ノード4と5(gr-node4,gr-node5)をグループレプリケーションメンバーに追加してみます。
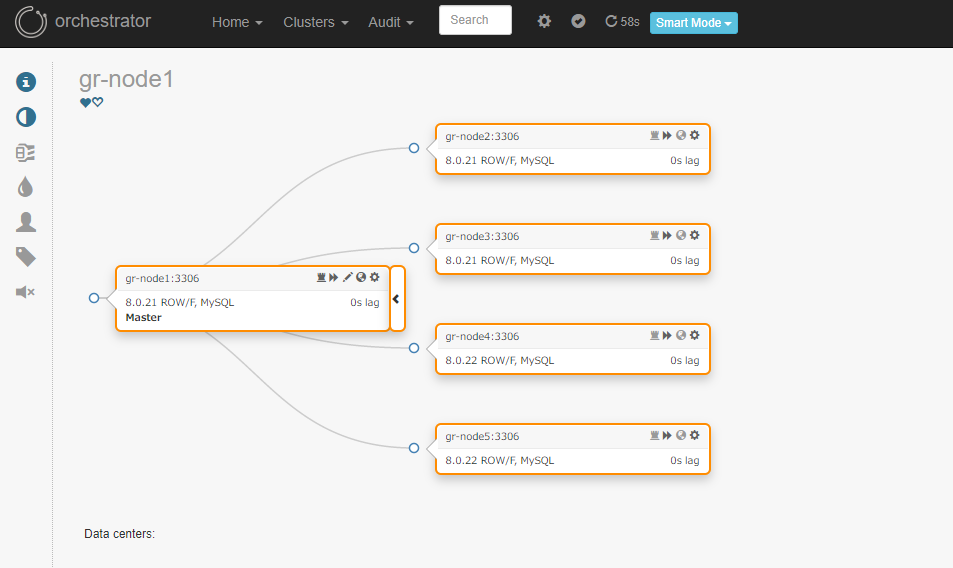
※追加ノードはちょうど8.0.22がリリースされた直後に作成したインスタンスです。 -
メンバー削除時
Group Replication 上からメンバーを削除した場合、Orchestrator 上ではProblem: group replication member not onlineとして扱われていますので、完全に削除するには Orchestrator 側で削除したメンバーをforgetしてあげる必要がありました。

予期せぬトポロジーリファクタリング操作の防止
Orchestrator上からグループレプリケーションのトポロジーを変更しようとしても防がれることが確認できます。(エラーメッセージがでてオペレーションが許可されません)
- プライマリーをセカンダリーからレプリケートするように設定しようとすると…
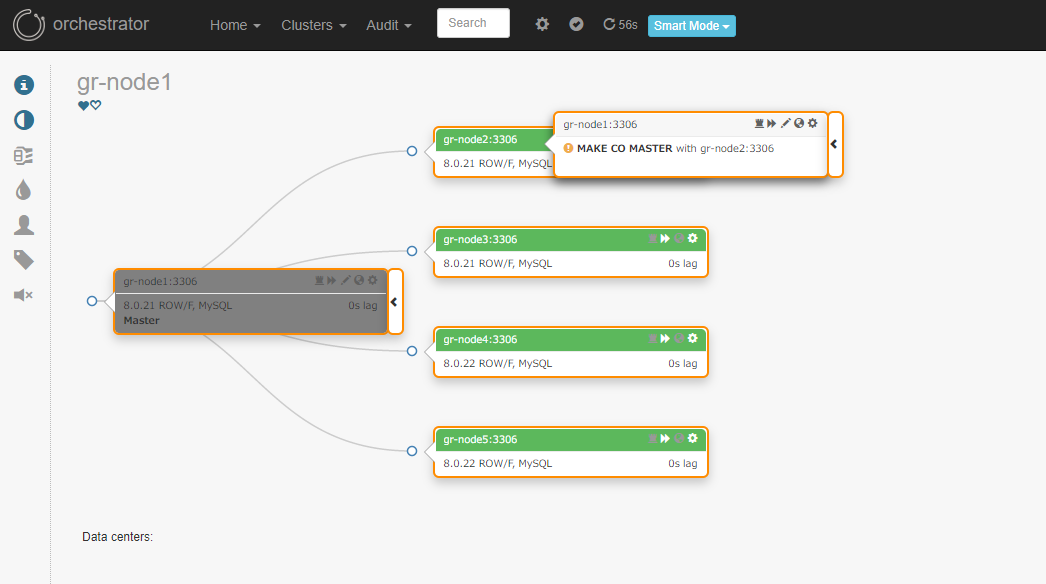
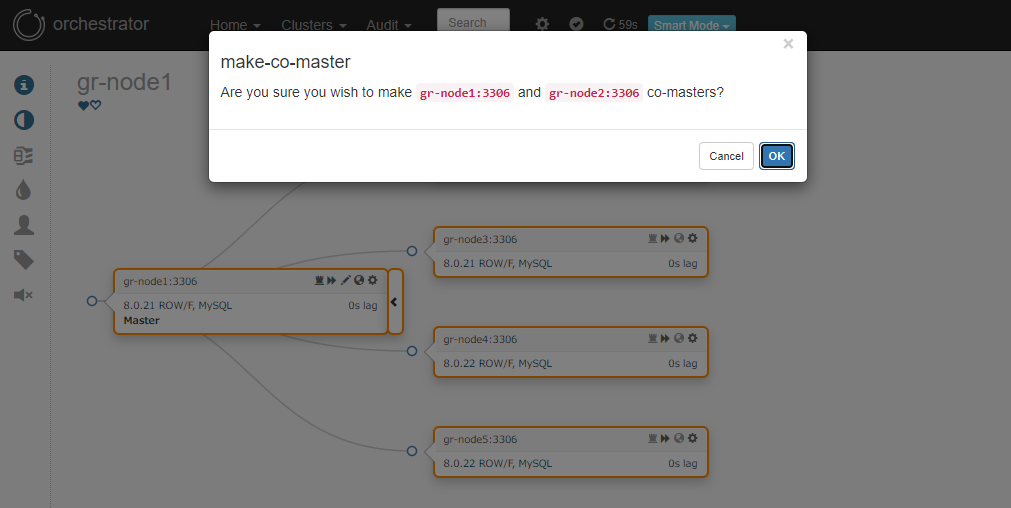

-
セカンダリーを別の場所からレプリケートするように移動させようとすると…
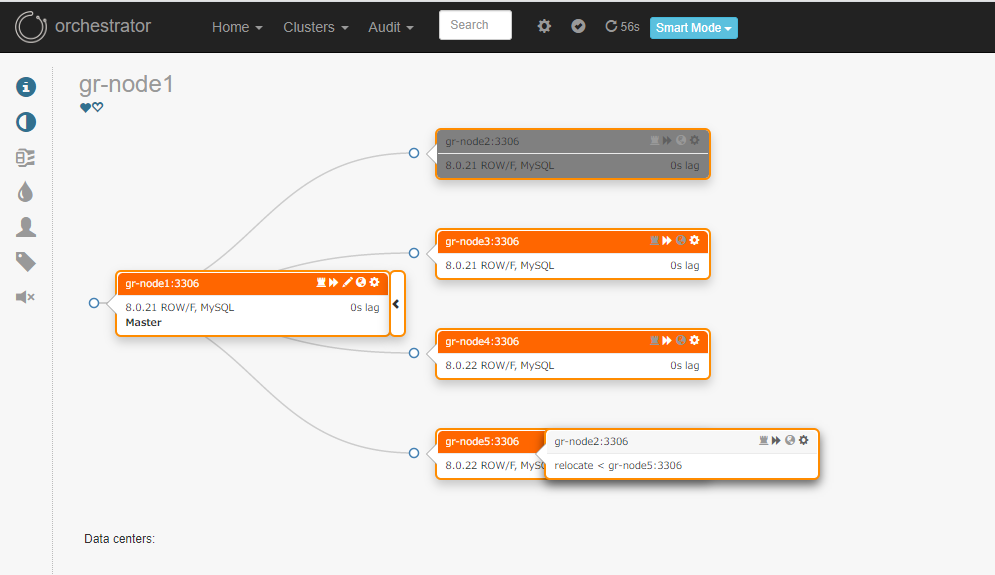
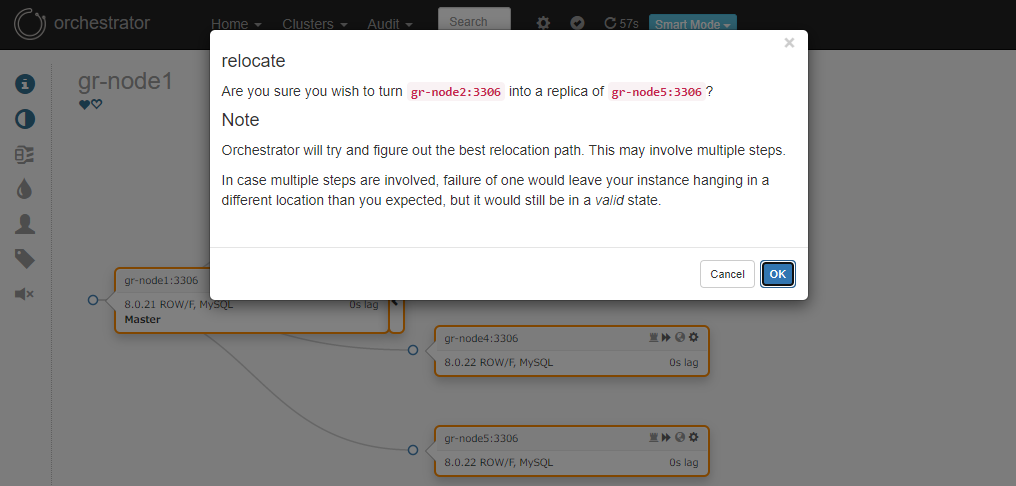
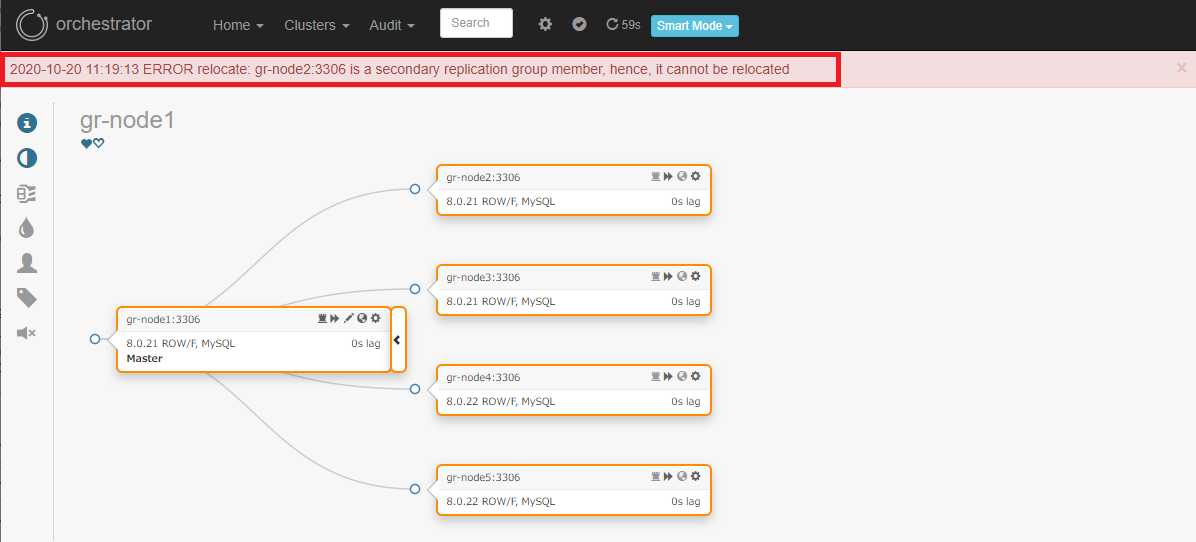
Group Replicationのメンバーをソースとしたレプリケーション構成が組まれている場合
pull reqest に書いてあった通り、セカンダリーメンバーにぶら下げた非同期レプリケーションも正常に認識されます。
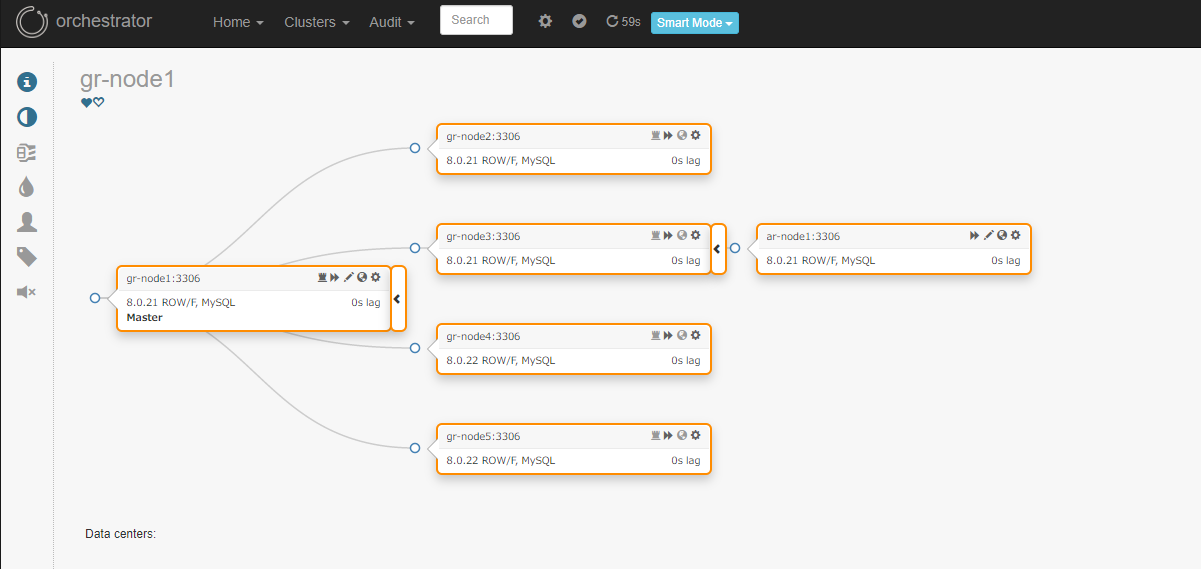
ただし、残念ながらレプリカのソースとなるセカンダリーメンバーがダウンしたら自動フェイルオーバーはされません。(トポロジー上で障害は検知されている模様)
元レプリカは元のクラスターからは再グループされ、孤立状態となっています。
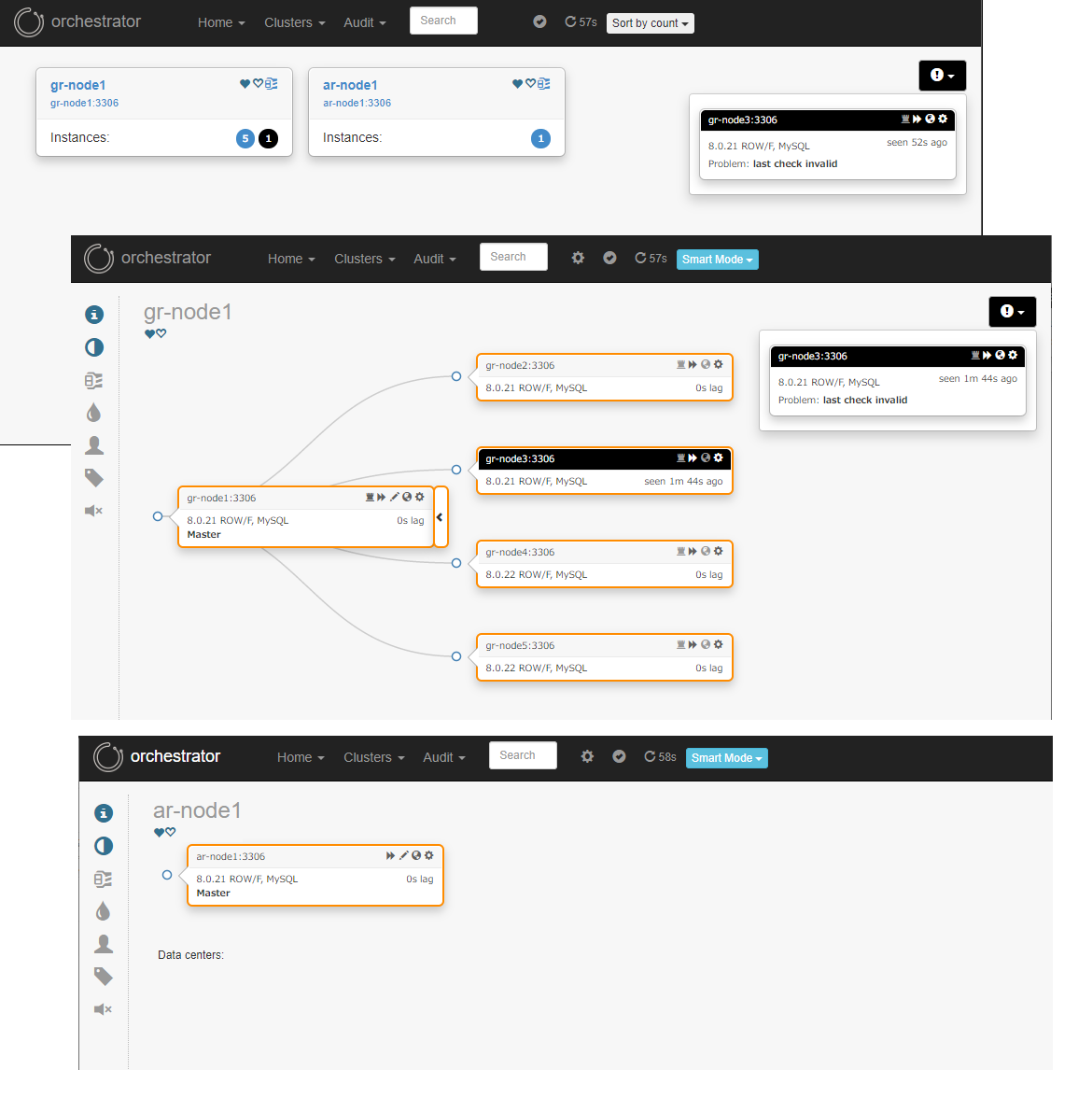
Orchestrator のログメッセージ上からは、RecoverDeadIntermediateMasterのトポロジリカバリーを試みようとしていますが、ソース候補が見つかっていないようです。
|
1 2 3 4 5 6 7 8 9 |
(...) Oct 19 16:31:54 orch2 orchestrator[10401]: topology_recovery: - RecoverDeadIntermediateMaster: regrouped under ar-node1:3306, with 0 lost replicas Oct 19 16:31:54 orch2 orchestrator: 2020-10-19 16:31:54 INFO topology_recovery: - RecoverDeadIntermediateMaster: regrouped under ar-node1:3306, with 0 lost replicas Oct 19 16:31:54 orch2 orchestrator: 2020-10-19 16:31:54 DEBUG orchestrator/raft: applying command 131418: write-recovery-step Oct 19 16:31:54 orch2 orchestrator: 2020-10-19 16:31:54 INFO topology_recovery: - RecoverDeadIntermediateMaster: will next attempt to relocate up from gr-node3:3306 Oct 19 16:31:54 orch2 orchestrator[10401]: topology_recovery: - RecoverDeadIntermediateMaster: will next attempt to relocate up from gr-node3:3306 Oct 19 16:31:54 orch2 orchestrator: 2020-10-19 16:31:54 DEBUG orchestrator/raft: applying command 131419: write-recovery-step Oct 19 16:31:54 orch2 orchestrator: 2020-10-19 16:31:54 ERROR Error reading :0 Oct 19 16:31:54 orch2 orchestrator: 2020-10-19 16:31:54 ERROR topology_recovery: RecoverDeadIntermediateMaster failed to match up any replica from gr-node3:3306 |
- これに関しては、今回の実装ではあくまで基本サポートとして Group Replication を認識できるようになるところまでスコープとしたとのことで、自動リカバリについては次の拡張対応としてIssue が挙がっており、今後機能追加が行われる見込みのようです。
Orchestrator cannot recover async/semi-sync replicas of failed replication group members · Issue #1253 · openark/orchestrator · GitHub
Group Replication のプライマリーノードを別ノードのレプリカにした場合
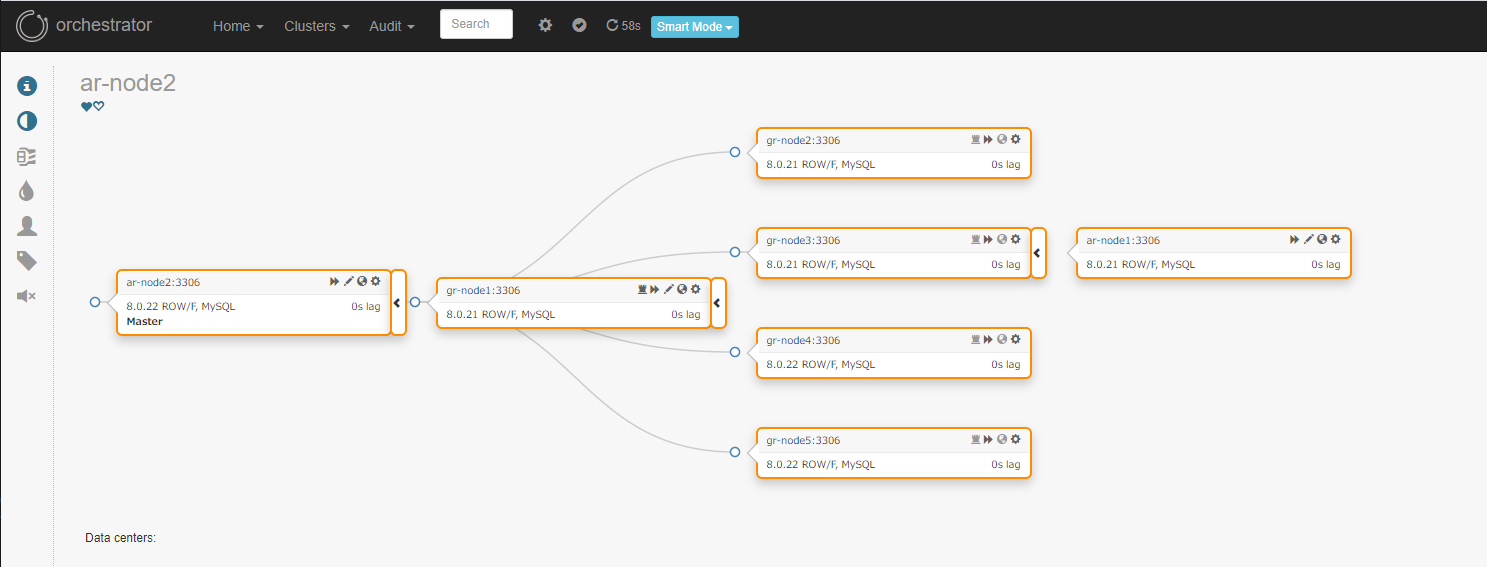
プライマリーメンバー gr-node1 を ar-node2 のレプリカに設定してみました。
構成当初はソースも Group Replication のトポロジー内に認識されますが、時間経過後、Group Replication のトポロジーマップが吸収されてしまいました。
まとめ
最近の MySQL における動向として、InnoDB Cluster および Group Replication は高可用性構成の中核として位置付けられているようですので、Orchestorator もサポートするようになったことは非常に重要なアップデートではないかと考えています。
まだ現時点では、基本的なトポロジー監視レベルの段階なのでOrchestoratorの強力な特徴であるトポロジーの自動リカバリが活かせないものの、機能拡張や Bug Fix 含め、今後の活発な開発に期待したいと思います。







