概要
DRBD9では多ノード接続の特性を生かして、リソースのQuorum制御が出来ます。
この機能を使うと、HAクラスタシステムでよくある障害であるスプリットブレインの発生を防ぐことができます。
そもそもスプリットブレインは、ノード同士を繋ぐ回線が一時的に切断された場合、複数のノードがアクティブ状態になってしまうために発生します。DRBDではアクティブノードの数は1つだけになるように制御されていますが、DRBD同士の通信回線が切断されると、孤立したDRBDノードは、相手のノードの状態にかかわらず、アクティブになってしまう可能性があります。
これまでのDRBDではフェンシング(Fencing)機能を使って、Pacemakerがスタンバイ側のDRBDがアクティブにならないように制御することができましたが、この機能を使うためには最低でも2つの通信チャンネルを持たないと正しく動作しません。例えば仮想環境等でゲストOS間を繋ぐネットワークが複数回線確保できない場合は、フェンシング(Fencing)を使ったHAクラスタの構築は不可能になります。
DRBD9のQuorum機能は、通信できるノードの数がノード総数の半分を超える場合、データの更新ができます。つまり2ノード以上ノードが繋がっていない場合、DRBDのデバイスに書き込みが出来なくなります。
1回線でリソース制御が出来る代わりに、Quorum設定には最低3つのDRBDノードが必要となります。ただし全てのノードにストレージを持つ必要は無く、1台はストレージ無し(Diskless)でも構築出来ます。また、ストレージを持つノードは実サーバ、ストレージ無しのノードは仮想ゲストの構成で構築することも可能です。
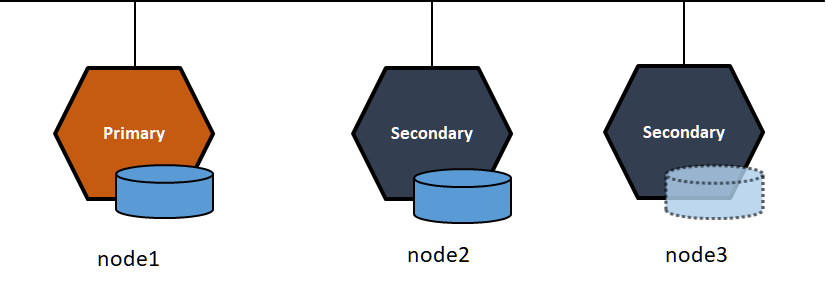
それでは実際に3ノード構成のDRBDの環境を構築して、DRBD9のQuorumの仕組みを確認しましょう。
試験環境のセットアップ
必要な環境
まずCentOS7の環境を3ノード準備します。DRBDはリソースをあまり必要としないため、VMwareやVirtualbox等の仮想ゲストを使ってテストをおこなうこともできます。
| 項目 | 値 | コメント |
|---|---|---|
| メモリー | 1GB以上 | 最低1GBあればDRBD、Pacemakerの動作テストができます。DBやWEBサーバなどを本格的に運用する場合には、それらが必要なメモリーサイズを足してください。 |
| HDD | 8GB以上 | 8GBで十分です。システムに4GB、SWAPに1GB、DRBDデータ同期用に3GBあればテスト環境が構築できます。 |
| NETWORK | 3経路 | 3系統を推奨します。サーバアクセス用に1系統、HA通信用に2系統、DRBDの同期にはHA通信用の回線のうち1つを使います。今回の実験では1系統で確認することも可能です。 |
| OS | 最小構成 | GUIは不要です。最小構成でインストールしてください。 |
DRBDは弊社へデモライセンスの申請をいただきLINBITのリポジトリからダウンロードいただくか、コミュティ版をELRepo Projectから入手してください。DRBDのバージョンは必ず9を選択ください。
ホスト名とネットワークの設定
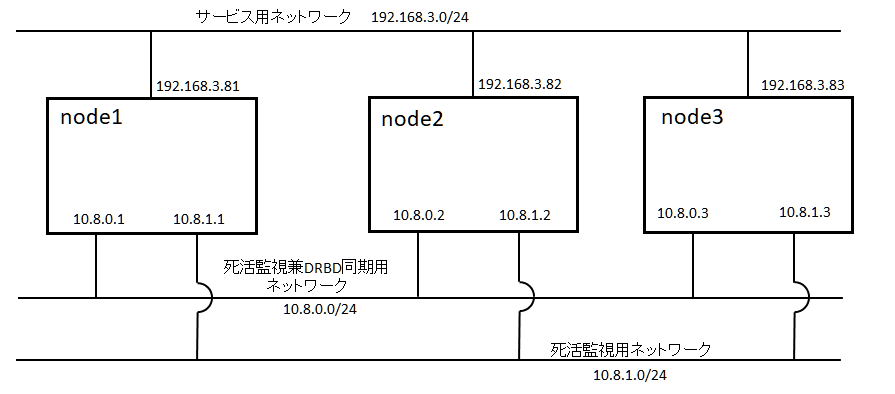
テスト環境のホスト名とネットワーク毎のIPアドレスは次になります。以後の説明でホスト名、IPアドレスが出てきますが、実際の環境に合わせて読み替えて下さい。
| ホスト名 | enp0s3(nic0) | enp0s8(nic1) | enp0s9(nic2) |
|---|---|---|---|
| node1 | 192.168.3.81 | 10.8.0.1 | 10.8.1.1 |
| node2 | 192.168.3.82 | 10.8.0.2 | 10.8.1.2 |
| node3 | 192.168.3.83 | 10.8.0.3 | 10.8.1.3 |
DRBDの設定
DRBDの設定は次です。node3のdisk設定がnoneになっているのはストレージ無し(Diskless)であることを意味します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
[root@node1 ~]# cat /etc/drbd.d/r0.res resource r0 { options { quorum majority; quorum-minimum-redundancy 1; on-no-quorum io-error; } net { protocol C; } on node1 { disk /dev/sdb1; meta-disk internal; device minor 0; address 10.8.0.1:7000; node-id 0; } on node2 { disk /dev/sdb1; meta-disk internal; device minor 0; address 10.8.0.2:7000; node-id 1; } on node3 { disk none; meta-disk internal; device minor 0; address 10.8.0.3:7000; node-id 2; } connection-mesh { hosts node1 node2 node3; } } |
DRBDのセットアップ
DRBDの設定方法の記事を参考に3ノード構成のDRBDをセットアップします。
DRBDの設定方法 https://tech-lab.sios.jp/archives/19863
参照記事は2ノードですが、これを3ノード分作業します。
3ノード全てでメタデータを作成します。
|
1 2 3 4 5 6 |
[root@node1 ~]# drbdadm create-md r0 initializing activity log initializing bitmap (60 KB) to all zero Writing meta data... New drbd meta data block successfully created. success |
メタデータの作成が出来たら、DRBDを起動します。これも3ノードすべてで実行します。
|
1 |
[root@node1 ~]# drbdadm up r0 |
初期化のためにnode1をPrimaryにしてファイルシステムを作成します。
Primaryにするためには --force オプションを付ける必要があります。
|
1 |
[root@node1 ~]# drbdadm --force primary r0 |
--force オプションを付けると、DRBDのストレージの初期同期が開始され、node1からnode2にストレージの内容がコピーされます。
初期同期中にstatusを確認すると、次のように同期の進捗を確認出来ます。
3ノードですので参照記事の内容と少し異なり、node3の情報も表示されます。
|
1 2 3 4 5 6 7 |
[root@node1 ~]# drbdadm status r0 role:Primary disk:UpToDate quorum:no node2 role:Secondary congested:yes ap-in-flight:0 rs-in-flight:6144 replication:SyncSource peer-disk:Inconsistent done:7.13 node3 role:Secondary peer-disk:Diskless |
同期が終了すると、statusは次のようになります。
|
1 2 3 4 5 6 7 |
[root@node1 ~]# drbdadm status r0 role:Primary disk:UpToDate node2 role:Secondary peer-disk:UpToDate node3 role:Secondary peer-disk:Diskless |
冗長化されたデバイスが/dev/drbd0としてアクセスが出来るようになりましたので、xfsのファイルシステムを作成してマウントしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[root@node1 ~]# drbdadm secondary r0 [root@node1 ~]# mkfs.xfs /dev/drbd0 meta-data=/dev/drbd0 isize=512 agcount=4, agsize=117498 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=0, sparse=0 data = bsize=4096 blocks=469992, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 [root@node1 ~]# mount /dev/drbd0 /drbd [root@node1 ~]# df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 495592 0 495592 0% /dev tmpfs 507380 8208 499172 2% /dev/shm tmpfs 507380 13340 494040 3% /run tmpfs 507380 0 507380 0% /sys/fs/cgroup /dev/mapper/centos-root 14034944 6014348 8020596 43% / /dev/sda1 1038336 228452 809884 23% /boot tmpfs 101480 0 101480 0% /run/user/0 /dev/drbd0 8376796 199096 8177700 3% /drbd |
テストケース
node2、node3が正常に停止した場合
node1がアクティブな状態で、node2、node3を停止した場合は、node1のDRBDはそのまま正常に使えます。node2、node3が復帰すればスタンバイとして接続され、スプリットブレインは発生しません。
node2、node3でDRBDを停止します。
|
1 2 |
[root@node2 ~]# drbdadm down r0 [root@node3 ~]# drbdadm down r0 |
node1でDRBDの状態を見ると、node2、node3との通信待ちになります。
|
1 2 3 4 5 |
[root@node1 ~]# drbdadm status r0 role:Primary disk:UpToDate node2 connection:Connecting node3 connection:Connecting |
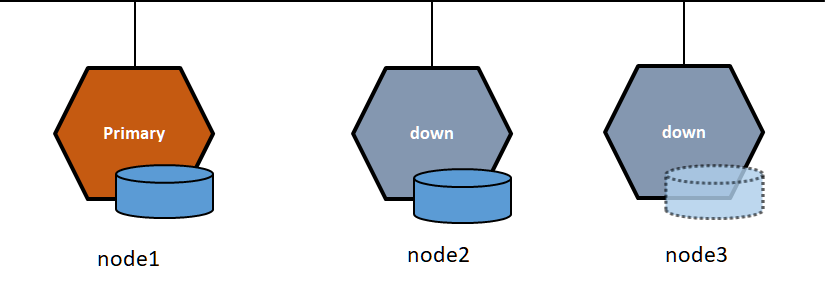
正常に停止した場合には、停止のつどノード総数が減るため、Quorum機能は作動しません。
node2、node3との接続を遮断した場合
次に通信障害でnode1とnode2、node3との通信が切れた場合を試します。
node1をアクティブな状態で、node2、node3との接続を切断します。
|
1 |
[root@node1 ~]# iptables -I INPUT -i enp0s8 -j DROP |
node1は引き続きアクティブな状態ですが、Quorum設定により、DRBDの領域には書き込みが出来ない状態になります。
|
1 2 3 4 5 6 7 8 |
[root@node1 ~]# drbdsetup status r0 role:Primary disk:UpToDate quorum:no node2 connection:Connecting node3 connection:Connecting [root@node1 ~]# touch /drbd/test-file touch: cannot touch '/drbd/test-file': Input/output error |
マウントしたディレクトリへの書き込みがエラーになります。
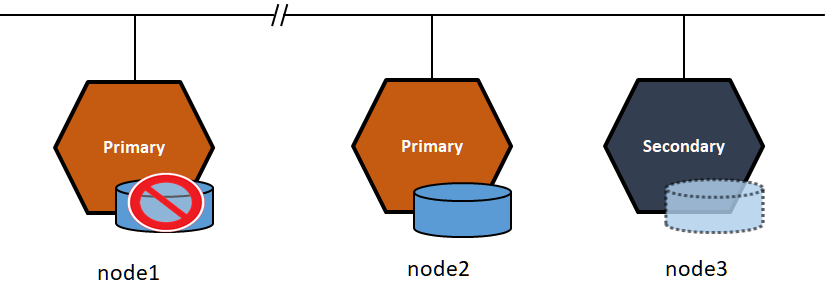
node2ではデバイスをマウント出来ます。
|
1 2 3 4 5 6 7 8 9 10 11 |
[root@node2 heartbeat]# drbdadm status r0 r0 role:Secondary disk:UpToDate node1 connection:Connecting node3 role:Secondary peer-disk:Diskless [root@node2 heartbeat]# touch /drbd/test-file-node2 [root@node2 heartbeat]# ls -l /drbd total 3 -rw-r--r-- 1 root root 0 Jul 1 14:56 test-file-node2 |
node2でファイルシステムを更新しましたが、node1では書き込みが禁止されているため、データの同時更新は発生しません。
一旦node1でのマウントを解除して、回線を復活するとnode2で更新したファイルはnode1へ同期されます。
|
1 2 |
[root@node1 ~]# umount /dev/drbd0 [root@node1 ~]# iptables -D INPUT -i enp0s8 -j DROP |
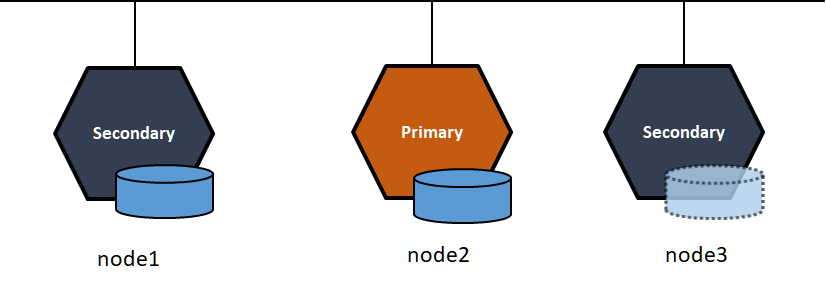
node2でマウントを解除して、あらためてnode1にマウントすると、node2で作成したファイルがnode1でも確認出来ます。
|
1 2 3 4 |
[root@node1 ~]# mount /dev/drbd0 /drbd [root@node1 ~]# ls -l /drbd/ total 3 -rw-r--r-- 1 root root 0 Jul 1 14:56 test-file-node2 |
このようにnode1がアクティブなままnode2でマウントしても、同時マウントとして認識されないため、スプリットブレインは発生しません。node1では回線が切れている間、/drbdへのアクセスがエラーになるので、このエラーを検知してフェールオーバーするようにPacemakerを設定すると、スプリットブレインによる障害が発生しないクラスタシステムを構築することが出来ます。
Pacemakerへの応用
DRBD9のQuorumを使ってHAクラスタを動かしてみます。HA化するサービスとして、MySQLコミュニティ版のサーバを動作させる構築例を紹介します。
Pacemakerの設定は次になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
node 1: node1.sios.com node 2: node2.sios.com primitive res_filesystem Filesystem \ params device="/dev/drbd0" directory="/drbd" fstype=xfs options=noatime \ op start interval=0 timeout=60 \ op stop interval=0 timeout=60 \ op monitor interval=20 timeout=40 OCF_CHECK_LEVEL=20 primitive res_mysql mysql \ params binary="/usr/sbin/mysqld" datadir="/drbd" \ op start interval=0 timeout=120 \ op stop interval=0 timeout=120 \ op monitor interval=20 timeout=30 primitive res_vip IPaddr2 \ params ip=192.168.3.80 cidr_netmask=24 nic=enp0s3 \ op start interval=0 timeout=20 \ op stop interval=0 timeout=20 \ op monitor interval=10 timeout=20 \ meta target-role=Started group rg_service res_vip res_filesystem res_mysql location l1 rg_service inf: node1.sios.com property cib-bootstrap-options: \ have-watchdog=false \ dc-version=1.1.21.linbit-4.0.el7-f14e36fd43 \ cluster-infrastructure=corosync \ cluster-name=cluster_test \ stonith-enabled=false \ no-quorum-policy=ignore \ last-lrm-refresh=1593558077 rsc_defaults rsc-options: \ resource-stickiness=200 |
※ MySQLのデータディレクトリを /drbd としています。
フェンシング(fencing)を使う場合、DRBDのリソースを定義する必要がありますが、Quorum設定の場合は定義が不要になり、Pacemakerの設定を簡略に書くことができます。
また上の設定にあるようにFilesystemリソースのmonitor設定にOCF_CHECK_LEVEL=20を追加すると、/drbdに.Filesystem_statusという名称のディレクトリが作成され、20秒毎にテストファイルが書き込まれます。ファイルシステムへの定期的な書き込みが失敗するとres_filesystemがnode1で起動不能になり、node2へフェールオーバーします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[root@node2 heartbeat]# crm_mon -frAD Online: [ node1.sios.com node2.sios.com ] Full list of resources: Resource Group: rg_service res_vip (ocf::heartbeat:IPaddr2): Started node1.sios.com res_filesystem (ocf::heartbeat:Filesystem): Started node1.sios.com res_mysql (ocf::heartbeat:mysql): Started node1.sios.com Node Attributes: * Node node1.sios.com: * Node node2.sios.com: Migration Summary: * Node node2.sios.com: * Node node1.sios.com: |
HAクラスタの初期状態です。node1でMySQLサーバが起動しています。
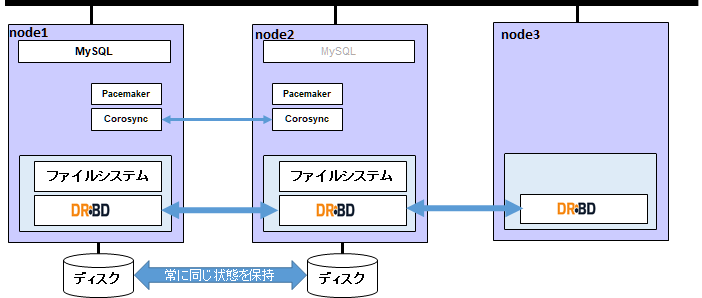
次に通信障害のためnode2、node3への疎通が切れた想定で、iptablesコマンドを用いて回線を切断します。
|
1 |
[root@node1 ~]# iptables -I INPUT -i enp0s8 -j DROP |
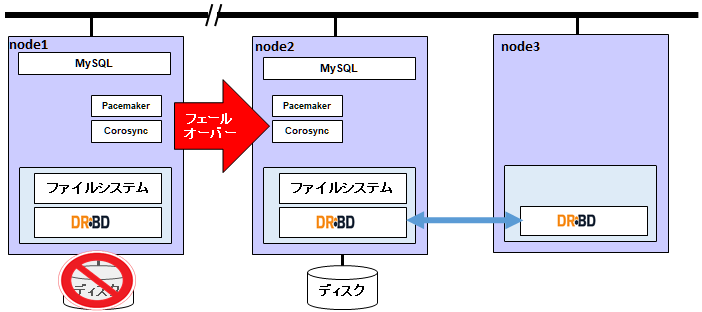
node1は孤立したノードになり、/drbdへの書き込みが失敗してnode2へフェールオーバーしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
[root@node2 heartbeat]# crm_mon -frAD Online: [ node1.sios.com node2.sios.com ] Full list of resources: Resource Group: rg_service res_vip (ocf::heartbeat:IPaddr2): Started node2.sios.com res_filesystem (ocf::heartbeat:Filesystem): Started node2.sios.com res_mysql (ocf::heartbeat:mysql): Started node2.sios.com Node Attributes: * Node node1.sios.com: * Node node2.sios.com: Migration Summary: * Node node2.sios.com: * Node node1.sios.com: res_filesystem: migration-threshold=1000000 fail-count=1000000 last-failure='Wed Jul 1 15:17 :35 2020' Failed Resource Actions: * res_filesystem_start_0 on node1.sios.com 'unknown error' (1): call=23, status=complete, exitre ason='Couldn't mount device [/dev/drbd0] as /drbd', last-rc-change='Wed Jul 1 15:17:35 2020', queued=0ms, exec=86ms |
通信障害が回復して、node1で検知したPacemakerのエラーをクリーンアップすると、node2からnode1へサービスが復帰(フェールバック)します。
|
1 |
[root@node1 ~]# iptables -D INPUT -i enp0s8 -j DROP |
エラー情報のクリーンアップにはcrm resourceコマンドを使います。
|
1 2 3 4 5 6 7 8 |
[root@node1 ~]# crm resource cleanup res_filesystem Cleaned up res_vip on node2.sios.com Cleaned up res_vip on node1.sios.com Cleaned up res_filesystem on node2.sios.com Cleaned up res_filesystem on node1.sios.com Cleaned up res_mysql on node2.sios.com Cleaned up res_mysql on node1.sios.com Waiting for 1 reply from the CRMd. OK |
エラー情報がクリーンアップされたら、HAクラスタの状態を確認します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[root@node2 heartbeat]# crm_mon -frAD Online: [ node1.sios.com node2.sios.com ] Full list of resources: Resource Group: rg_service res_vip (ocf::heartbeat:IPaddr2): Started node1.sios.com res_filesystem (ocf::heartbeat:Filesystem): Started node1.sios.com res_mysql (ocf::heartbeat:mysql): Started node1.sios.com Node Attributes: * Node node1.sios.com: * Node node2.sios.com: Migration Summary: * Node node2.sios.com: * Node node1.sios.com: |
node1でMySQLサーバが起動しています。
まとめ
このようにDRBD9のQuorum機能を使うと、従来のフェンシング(Fencing)を使うより簡単かつ確実にDRBDの制御が可能になるため、スプリットブレインの発生を減らし、データの信頼性を高めることができます。
参考URL:
LINBITによるDRBD Quorumの紹介Blog
https://www.linbit.com/split-brain-ibm-drbd-quorum
また、AWS上でのDRBD + PacemakerによるHAクラスタの構築手順も公開しておりますので、興味のある方は、ご一読下さい。