Apache ShardingSphere でシャーディングしてみた
IoTや機械学習ブームもあり、データベースのデータ量は年々増えていき、最近ではTB/PBクラスのサイズになることも珍しいことではありません。
MySQLのレプリケーションクラスタでは、書き込みが許可されるのはマスターノードのみであり、高負荷なWrite処理がスケールできないという点が長年の課題としてあります。
このような場合、複数のマスタにデータを水平分割する(シャーディング)ということを思いつくかと思います。
これまでにも、この課題をミドルウェアで解決しようといくつかの製品がリリースされてきました。一例としては以下があります。
- MySQL Fabric
- Spider Storage Engine
また、MySQLフォークの製品として、シャーディングをネイティブに実装している製品もいくつかあります。
- Vitess
- TiDB
今回は、このシャーディングに焦点を当て、MySQLにも利用可能なミドルウェアである Apache Sharding Sphere を使ってみようと思います。
Apache ShardingSphere(以下ShardingSphere) は、2022/4/16 にApacheでもトップレベルプロジェクトとなっています。
ShardingSphere became an Apache Top-Level Project on April 16, 2020.
MySQLの起動
事前に3ノードのMySQLを起動しました。
|
1 2 3 4 5 6 |
$ dnf -y install perl-Digest-SHA $ curl -s https://raw.githubusercontent.com/datacharmer/dbdeployer/master/scripts/dbdeployer-install.sh | bash $ dbdeployer init $ dbdeployer deploy multiple --sandbox-directory=d -n 3 8.0 $ echo "export PATH=\$PATH:~/opt/mysql/8.0.27/bin" > ~/.bashrc $ . ~/.bashrc |
ShardingSphereの種類
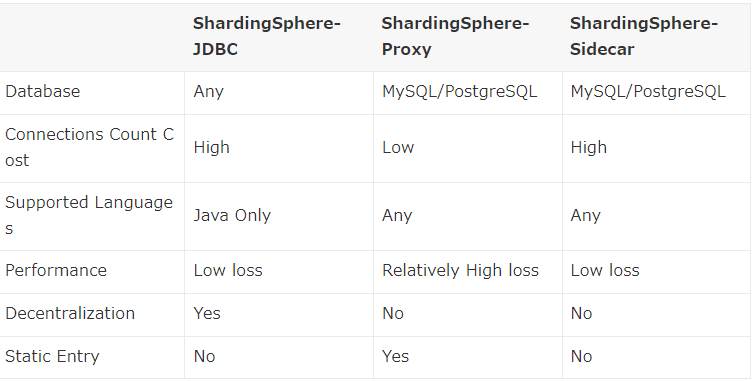
ShardingSphere は、以下の2パターンのミドルウェアを提供しています。
- ShardingSphere-JDBC
- ShardingSphere-Proxy
いずれも基本的な機能としては同様ですが、Java アプリケーションであればShardingSphere-JDBCを利用することが良いと考えられます。
一方で、ShardingSphere-Proxy を使用することで、どのような言語のアプリケーションでもShardingSphereの機能を利用できるというメリットがあります。
オフィシャルの比較表を見ていただくとわかりやすいと思います。
https://shardingsphere.apache.org/document/current/en/concepts/adaptor/
今回は、ShardingSphere-Proxy を使用します。
ShardingSphereドキュメントの注意
https://shardingsphere.apache.org/document/current は最新のバージョンを一部反映していないようです。
各バージョンのブランチのGithubソースに含まれるdocumentディレクトリを参照することで適切な情報が確認できます。
ShardingSphereのインストール
ShardingSphereはJava製のミドルウェアになりますので、JDKのインストールが必要です。
|
1 |
$ yum install -y java-1.8.0-openjdk |
Downloadページ から最新のパッケージをダウンロードします。
執筆時点では、v5.1.1 になります。
※ 程なくしてv5.1.2がリリースされたため、現在のダウンロードリンクは以下になります。
https://dlcdn.apache.org/shardingsphere/5.1.2/apache-shardingsphere-5.1.2-shardingsphere-proxy-bin.tar.gz
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ wget https://dlcdn.apache.org/shardingsphere/5.1.1/apache-shardingsphere-5.1.1-shardingsphere-proxy-bin.tar.gz $ tar xf apache-shardingsphere-5.1.1-shardingsphere-proxy-bin.tar.gz $ tree apache-shardingsphere-5.1.1-shardingsphere-proxy-bin -L 1 . |-- LICENSE |-- NOTICE |-- README.txt |-- bin |-- conf |-- lib |-- licenses `-- logs |
インストール作業を進めます。
ユーザ追加と、ディレクトリの配置のみです。
今回のインストール先は /opt/shardingsphere としました。
|
1 2 3 4 |
$ useradd -r shardingsphere $ mv apache-shardingsphere-5.1.1-shardingsphere-proxy-bin /opt $ chown -R shardingsphere. /opt/apache-shardingsphere-5.1.1-shardingsphere-proxy-bin $ ln -s /opt/apache-shardingsphere-5.1.1-shardingsphere-proxy-bin /opt/shardingsphere |
JDBC Driverの配置
クイックスタートに記載の通り、各データベースへの接続のためにJDBC Driverをlibもしくはext-lib配下に配置する必要があります。
https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/
If the backend database is MySQL, please download mysql-connector-java-5.1.47.jar or mysql-connector-java-8.0.11.jar and put it into the %SHARDINGSPHERE_PROXY_HOME%/ext-lib directory.
ext-libを使用する場合、ディレクトリを作成する必要があります。ここでは、lib配下にダウンロードしました。
|
1 2 |
$ cd lib $ wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.11/mysql-connector-java-8.0.11.jar |
ShardingSphereの設定
ShardingSphereは起動スクリプト(start.sh)の親階層のconfディレクトリ以下のyamlファイルを読み取ります。
いくつかのサンプルコンフィグが含まれていますが、シャーディングなどは後ほど行うことにし、server.yamlを編集し基本的な設定で起動します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
mode: type: Standalone repository: type: File props: path: /opt/shardingsphere/.shardingsphere rules: - !AUTHORITY users: - root@%:root - sharding@:sharding provider: type: ALL_PRIVILEGES_PERMITTED - !TRANSACTION defaultType: XA providerType: Atomikos - !SQL_PARSER sqlCommentParseEnabled: true sqlStatementCache: initialCapacity: 2000 maximumSize: 65535 concurrencyLevel: 4 parseTreeCache: initialCapacity: 128 maximumSize: 1024 concurrencyLevel: 4 : 略 |
起動停止を簡単にするためにサービス化し、起動します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
$ cat >> /etc/systemd/system/shardingsphere.service <<-EOF [Unit] Description=Apache ShardingSphere-Proxy [Service] Type=forking ExecStart=/opt/shardingsphere/bin/start.sh ExecStop=/opt/shardingsphere/bin/stop.sh ExecReload=/opt/shardingsphere/bin/stop.sh && /opt/shardingsphere/bin/start.sh Restart=on-failure RestartSec=60 [Install] WantedBy=multi-user.target EOF $ systemctl daemon-reload $ systemctl start shardingsphere.service $ systemctl status shardingsphere.service ● shardingsphere.service - Apache ShardingSphere-Proxy Loaded: loaded (/etc/systemd/system/shardingsphere.service; disabled; vendor preset: disabled) Active: active (running) since Tue 2022-06-14 05:48:23 UTC; 48s ago Process: 11121 ExecStart=/opt/shardingsphere/bin/start.sh (code=exited, status=0/SUCCESS) : 略 |
デフォルトでは、3307ポートでリッスンします。
|
1 2 |
$ ss -nltp | grep java LISTEN 0 128 *:3307 *:* users:(("java",pid=11156,fd=240)) |
rules[0].!AUTHORITY.users に指定したユーザで接続が可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ mysql -uroot -proot -h127.0.0.1 -P3307 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.7.22-ShardingSphere-Proxy 5.1.1 Copyright (c) 2000, 2022, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> |
DistSQLについて
ShardingSphere では、管理操作のために DistSQL という独自のコマンドを使用します。
https://shardingsphere.apache.org/document/current/en/concepts/distsql/
DistSQL is divided into RDL, RQL and RAL.
RDL (Resource & Rule Definition Language) responsible for the definition of resources and rules;
RQL (Resource & Rule Query Language) responsible for the query of resources and rules;
RAL (Resource & Rule Administration Language) responsible for the added-on administrator feature of hint, transaction type switch, sharding execute planning and so on.
ここでは、シャーディングを達成するための基本的なチュートリアルのみをご紹介しますが、どのようなDistSQL構文があるかはマニュアルをご確認ください。
https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-proxy/distsql/
シャーディングについて
シャーディングを実現するためには、以下が最低限必要です。
- スキーマの作成
- リソース(データベース接続)の登録
- シャーディングテーブルルールの作成
- テーブルを作成
リソースは必ずしも複数無くても構いませんが、スケールアウト戦略を考えている場合は複数になるでしょう。
スキーマの作成
ShardingSphereにスキーマを作成します。
ここでCREATE DATABASEによって作成されるのは、MySQLのデータベースとは関係ありません。
|
1 2 |
mysql> CREATE DATABASE shard; mysql> USE shard; |
データソースの登録
ShardingSphereにデータベース接続情報を登録します。
起動しているmysqldのポートを確認します。
|
1 2 3 4 5 6 |
$ dbdeployer global status # Running "status_all" on d MULTIPLE ~/sandboxes/d node1 : node1 on - port 26728 (26728) node2 : node2 on - port 26729 (26729) node3 : node3 on - port 26730 (26730) |
SSL接続は可能ですが、ここでは簡略化のためにSSL接続を必要としないmysql_native_passwordを設定します。
|
1 |
$ ~/sandboxes/d/use_all -e "alter user msandbox@\<code>127.%\</code> identified with mysql_native_password by 'msandbox'" |
リソースを以下のように登録します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
mysql> ADD RESOURCE resource_0 ( HOST=127.0.0.1, PORT=26728, DB=test, USER=msandbox, PASSWORD=msandbox), resource_1 ( HOST=127.0.0.1, PORT=26729, DB=test, USER=msandbox, PASSWORD=msandbox), resource_2 ( HOST=127.0.0.1, PORT=26730, DB=test, USER=msandbox, PASSWORD=msandbox); mysql> show schema resources\G *************************** 1. row *************************** name: resource_2 type: MySQL host: 127.0.0.1 port: 26730 db: test connection_timeout_milliseconds: 30000 idle_timeout_milliseconds: 60000 max_lifetime_milliseconds: 2100000 max_pool_size: 50 min_pool_size: 1 read_only: false other_attributes: {"dataSourceProperties":{"cacheServerConfiguration":"true","elideSetAutoCommits":"true","useServerPrepStmts":"true","cachePrepStmts":"true","useSSL":"false","rewriteBatchedStatements":"true","cacheResultSetMetadata":"false","useLocalSessionState":"true","maintainTimeStats":"false","prepStmtCacheSize":"200000","tinyInt1isBit":"false","prepStmtCacheSqlLimit":"2048","serverTimezone":"UTC","netTimeoutForStreamingResults":"0","zeroDateTimeBehavior":"round"},"healthCheckProperties":{},"initializationFailTimeout":1,"validationTimeout":5000,"leakDetectionThreshold":0,"registerMbeans":false,"allowPoolSuspension":false,"autoCommit":true,"isolateInternalQueries":false} *************************** 2. row *************************** name: resource_1 type: MySQL host: 127.0.0.1 port: 26729 db: test connection_timeout_milliseconds: 30000 idle_timeout_milliseconds: 60000 max_lifetime_milliseconds: 2100000 max_pool_size: 50 min_pool_size: 1 read_only: false other_attributes: {"dataSourceProperties":{"cacheServerConfiguration":"true","elideSetAutoCommits":"true","useServerPrepStmts":"true","cachePrepStmts":"true","useSSL":"false","rewriteBatchedStatements":"true","cacheResultSetMetadata":"false","useLocalSessionState":"true","maintainTimeStats":"false","prepStmtCacheSize":"200000","tinyInt1isBit":"false","prepStmtCacheSqlLimit":"2048","serverTimezone":"UTC","netTimeoutForStreamingResults":"0","zeroDateTimeBehavior":"round"},"healthCheckProperties":{},"initializationFailTimeout":1,"validationTimeout":5000,"leakDetectionThreshold":0,"registerMbeans":false,"allowPoolSuspension":false,"autoCommit":true,"isolateInternalQueries":false} *************************** 3. row *************************** name: resource_0 type: MySQL host: 127.0.0.1 port: 26728 db: test connection_timeout_milliseconds: 30000 idle_timeout_milliseconds: 60000 max_lifetime_milliseconds: 2100000 max_pool_size: 50 min_pool_size: 1 read_only: false other_attributes: {"dataSourceProperties":{"cacheServerConfiguration":"true","elideSetAutoCommits":"true","useServerPrepStmts":"true","cachePrepStmts":"true","useSSL":"false","rewriteBatchedStatements":"true","cacheResultSetMetadata":"false","useLocalSessionState":"true","maintainTimeStats":"false","prepStmtCacheSize":"200000","tinyInt1isBit":"false","prepStmtCacheSqlLimit":"2048","serverTimezone":"UTC","netTimeoutForStreamingResults":"0","zeroDateTimeBehavior":"round"},"healthCheckProperties":{},"initializationFailTimeout":1,"validationTimeout":5000,"leakDetectionThreshold":0,"registerMbeans":false,"allowPoolSuspension":false,"autoCommit":true,"isolateInternalQueries":false} |
シャーディングテーブルの作成
まずはドキュメントの例をもとにシャーディングルールとテーブルを作成します。
このルールでは、シャーディングするデータソースを3つ登録し、自動シャーディングルールによって3つのシャードテーブルに分散させるという内容になっています。
order_idのhash_mod(ハッシュ値の剰余)で対象データソースを決定します。
シャーディングアルゴリズムは、以下に記載があります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mysql> CREATE SHARDING TABLE RULE t_order( RESOURCES(resource_0,resource_1,resource_2), SHARDING_COLUMN=order_id, TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=3)), KEY_GENERATE_STRATEGY(COLUMN=order_id,TYPE(NAME=snowflake)) ); mysql> CREATE TABLE <code>t_order</code> ( order_id</code> int NOT NULL, user_id</code> int NOT NULL, status</code> varchar(45) DEFAULT NULL, PRIMARY KEY (<code>order_id</code>) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; |
CREATE TABLEの結果、データソース側に t_order_<シャードNo> というテーブルが作成されました。
|
1 2 3 4 5 6 7 8 9 10 |
$ ~/sandboxes/d/use_all -e "show tables from test" # server: 1 Tables_in_test t_order_0 # server: 2 Tables_in_test t_order_1 # server: 3 Tables_in_test t_order_2 |
適当なデータをINSERTしてみましょう。
|
1 2 3 4 |
for i in {1..10000} do mysql -uroot -proot -h127.0.0.1 -P3307 -e "insert into shard.t_order values ($i, $(expr $i + 10000), \"status${i}\")" done |
単純な1~10000の数値をキーにした場合、均等に分散されました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
$ ~/sandboxes/d/n1 -e "select count(*) from test.t_order_0" +----------+ | count(*) | +----------+ | 3333 | +----------+ $ ~/sandboxes/d/n2 -e "select count(*) from test.t_order_1" +----------+ | count(*) | +----------+ | 3334 | +----------+ $ ~/sandboxes/d/n3 -e "select count(*) from test.t_order_2" +----------+ | count(*) | +----------+ | 3333 | +----------+ |
ShardingSphereからクエリするとすべてのレコードを取得できました。
|
1 2 3 4 5 6 7 |
mysql> select * from t_order order by order_id; +----------+ | count(*) | +----------+ | 10000 | +----------+ |
ShardingSphereにおけるプライマリキーの自動採番
MySQLでは、Auto Incrementによる自動増分値をプライマリキー(もしくはユニークキー)のデフォルト値として利用できます。
当然ながらMySQLの機能としては、複数のmysqldにまたがった連続値の採番などはサポートしていませんので、これは利用できません。
ShardingSphereには、一意のキー生成の仕組み(Key generator)があります。
先程の CREATE SHARDING TABLE RULE に含まれる KEY_GENERATE_STRATEGY がそれにあたります。
今度は、プライマリキーに値を指定せずにINSERTしてみましょう。
その前に、自動生成される値を格納できるように、プライマリキーをBIGINTに変更しておきます。
|
1 |
mysql> ALTER TABLE shard.t_order MODIFY order_id bigint; |
insertを実行しましょう。
|
1 2 3 4 5 6 |
mysql -uroot -proot -h127.0.0.1 -P3307 -e "truncate table shard.t_order" for i in {10001..20000} do mysql -uroot -proot -h127.0.0.1 -P3307 -e "insert into shard.t_order (user_id, status) values ($(expr $i + 10000), \"status${i}\")" done |
18桁のランダムな番号が更新されました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> select * from shard.t_order where user_id > 20000 limit 10; +--------------------+---------+-------------+ | order_id | user_id | status | +--------------------+---------+-------------+ | 743400859882225664 | 20004 | status10004 | | 743400860054192128 | 20006 | status10006 | | 743400860125495297 | 20007 | status10007 | | 743400860205187072 | 20008 | status10008 | | 743400860284878849 | 20009 | status10009 | | 743400860716892160 | 20014 | status10014 | | 743400861153099776 | 20018 | status10018 | | 743400861236985857 | 20019 | status10019 | | 743400861450895361 | 20021 | status10021 | | 743400861547364352 | 20022 | status10022 | +--------------------+---------+-------------+ |
この例では、KEY_GENERATE_STRATEGYにSNOWFLAKEを選択しています。
SNOWFLAKEは、Twitter社が開発したエポック時間とその他のビットからなる64bitの一意の数値です。
ランダムな番号ではあるものの、常に最上位bitは0で、次の41bitはエポック時間になるため、Auto increment値のようにソートすることが可能です。
KEY_GENERATE_STRATEGYには他にUUID(32桁の重複しないランダム文字列)も選択できます。
アプリケーションから利用しやすいものを選択するとよいでしょう。
ロードバランス
ShardingSphereは、シャーディングの機能を利用せずにL7ロードバランサとしても動作することが可能です。
MySQLとしてあると嬉しいのが、一般的なソース、レプリカからなるレプリケーション環境をターゲットとした読み書き分割ルーティングですが、
ShardingSphereの機能として備わっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- レプリケーション環境をリソースとして追加 mysql> ADD RESOURCE primary ( HOST=127.0.0.1, PORT=21728, DB=test, USER=msandbox, PASSWORD=msandbox), replica1 ( HOST=127.0.0.1, PORT=21729, DB=test, USER=msandbox, PASSWORD=msandbox), replica2 ( HOST=127.0.0.1, PORT=21730, DB=test, USER=msandbox, PASSWORD=msandbox); -- ルーティングルールの設定 mysql> CREATE READWRITE_SPLITTING RULE group_0 ( WRITE_RESOURCE=primary, READ_RESOURCES(replica1,replica2), TYPE(NAME=random) ); |
この状態でテーブルを作成してみましょう。
なお、ShardingSphereによって実行される実際のSQLは、PREVIEW コマンドによって確認することができます。
テーブルの作成(CREATE TABLE)はprimaryへルーティングされることが確認できました。
|
1 2 3 4 5 6 |
mysql> preview create table t (i int primary key); +------------------+------------------------------------+ | data_source_name | actual_sql | +------------------+------------------------------------+ | primary | create table t (i int primary key) | +------------------+------------------------------------+ |
INSERT や DELETE, UPDATEも同様にprimaryへルーティングされます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
mysql> preview insert into t values (1); +------------------+--------------------------+ | data_source_name | actual_sql | +------------------+--------------------------+ | primary | insert into t values (1) | +------------------+--------------------------+ mysql> preview delete from t; +------------------+---------------+ | data_source_name | actual_sql | +------------------+---------------+ | primary | delete from t | +------------------+---------------+ mysql> preview update t set i = 10; +------------------+---------------------+ | data_source_name | actual_sql | +------------------+---------------------+ | primary | update t set i = 10 | +------------------+---------------------+ |
SELECTはreplica1, replica2へルーティングされました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mysql> preview select * from t; +------------------+-----------------+ | data_source_name | actual_sql | +------------------+-----------------+ | replica1 | select * from t | +------------------+-----------------+ mysql> preview select * from t; +------------------+-----------------+ | data_source_name | actual_sql | +------------------+-----------------+ | replica2 | select * from t | +------------------+-----------------+ |
データベースのHA機能について
残念ながら、ShardingSphereには組み込みのデータベースに適したHA機能はありません。
ただし、RESOURCEにJDBC URLを登録することができ、JDBCの機能で簡単なフェイルオーバを実装することが可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mysql> CREATE DATABASE ds; mysql> USE ds; mysql> ADD RESOURCE ds_failover ( URL="jdbc:mysql://127.0.0.1:21728,127.0.0.1:21729,127.0.0.1:21730/test?serverTimezone=UTC&useSSL=false&connectTimeout=1000", USER=msandbox, PASSWORD=msandbox, PROPERTIES("maximumPoolSize"=10,"idleTimeout"="30000") ); mysql> CREATE TABLE t (i INT PRIMARY KEY); mysql> CREATE DEFAULT SINGLE TABLE RULE RESOURCE = ds_failover; mysql> INSERT INTO t VALUES(1); |
フェイルオーバすることがわかります。
|
1 2 3 4 5 6 7 8 9 10 11 |
$ while :;do MYSQL_PWD=root mysql -NB -uroot -h127.0.0.1 -P3307 -D ds -e "select @@hostname,@@port,i from ds.t";sleep 1;done 127.0.0.1 21728 1 127.0.0.1 21728 1 127.0.0.1 21728 1 127.0.0.1 21728 1 127.0.0.1 21729 1 <-- 127.0.0.1:21728のmysqldを停止 127.0.0.1 21729 1 127.0.0.1 21729 1 127.0.0.1 21729 1 127.0.0.1 21729 1 127.0.0.1 21729 1 |
なお、ShardingSphereには DB_DISCOVERY という機能があり、本来それを使用してフェイルオーバすることが可能ですが、現在サポートされているのはMySQL Group Replication環境のみでした。
次期リリース候補である5.1.2のバージョンから、非同期レプリケーションの機能が追加されるようです。
また、HAと言っておきながらではありますが、ShardingSphereは データベースとしてのHA機能を提供していません。
例の通り、接続ができないノードからフェイルオーバすることは可能ですが、一般にMySQLレプリケーション環境においては不十分です。
まず、フェイルオーバ先のデータベース(レプリカ)は通常時READ_ONLYとすることが推奨ですがShardingSphereのフェイルオーバプロセスでそれを解除することはできません。
では、運用カバーするとしてREAD_ONLYは有効化しない場合も、非同期レプリケーションではフェイルオーバ時にレプリカが最新であるか担保されません。
一般的なレプリケーションを考慮したHAソフトウェア(Orchestrator, MHA)は、バイナリログがすべて適用されたことを確認した上でフェイルオーバを完了させます。
レプリカでバイナリログの適用中に更新を入れた場合、更新順序がソースデータベースと異なってしまい、結果的に内容の異なるデータセットになり得るためです。
このような事情もあり、ノード間の整合性が強固に保たれるMySQL Group ReplicationはShardingSphereのようにデータベース製品の整合性を考慮しないプロキシ向けと言えるでしょう。
ただし、最低3ノードが必要ですので、1セット3ノードのシャードを今後追加していくことができるか考慮が必要かと思います。
JDBCのフェイルオーバを利用するのであれば、OrchestratorやMHAのようなソフトウェアと一緒に利用するか、マニュアルでデータベース側の確認、開放を行うかということになります。
という訳でGroup Replication環境を追加しようとしましたが、ドキュメントの例のコマンドは動作しませんでした。
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql> ADD RESOURCE gr_0 ( HOST=127.0.0.1, PORT=22728, DB=test, USER=msandbox, PASSWORD=msandbox), gr_1 ( HOST=127.0.0.1, PORT=22729, DB=test, USER=msandbox, PASSWORD=msandbox), gr_2 ( HOST=127.0.0.1, PORT=22730, DB=test, USER=msandbox, PASSWORD=msandbox); mysql> CREATE DB_DISCOVERY RULE ha_group_0 ( RESOURCES(gr_0,gr_1), TYPE(NAME=MGR,PROPERTIES(groupName="00022727-bbbb-cccc-dddd-eeeeeeeeeeee")), HEARTBEAT(PROPERTIES("keepAliveCron"="0/5 * * * * ?")) ); ERROR 1235 (42000): This version of ShardingSphere-Proxy doesn't yet support this SQL. 'You have an error in your SQL syntax' |
ドキュメントと最新リリースのバージョンが合っていない可能性がありますが、現在も活発に開発が続けられていますので今後に期待したいと思います。
まとめ
パーティショニング、シャーディングといった技術は、サービスが成長するにつれていずれ避けられないことになります。
ネイティブに機能を実装しているソフトウェアを利用しない限り、実施するとなった場合、インスタンスごとに分ける、データベースごとに分けるなど、様々なオプションはありますが、どの方法も一長一短あります。
Apache ShardingSphereのようなプロキシを使ったシャーディングは、ソフトウェアの出来がよければ理想的なソリューションになり得ます。
スケールアウトのために今から製品を検討してみてはいかがでしょうか。