
OrchestratorとはGithub社のDBAであるShlomi Noach氏が開発した、MySQL用レプリケーション管理用ソフトウェアです。
自動フェイルオーバ、自動フェイルバックの機能を備えており、MHAやPacemakerの代替となりうるソリューションです。
今回は、ごく一般的なマスタースレーブ構成のMySQLを、Orchestratorで管理する方法についてご紹介します。
環境構成
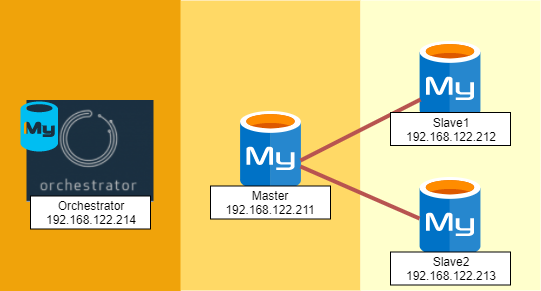
検証に使用する環境は以下の構成です。
| Hostname | IP | 用途 |
|---|---|---|
| test1 | 192.168.122.211 | MySQL マスタサーバ |
| test2 | 192.168.122.212 | MySQL スレーブサーバ1 |
| test3 | 192.168.122.213 | MySQL スレーブサーバ2 |
| test4 | 192.168.122.214 | Orchestrator + バックエンド用MySQLサーバ |
OSにはCentOS7を使用しました。
MySQLサーバは一般的な非同期レプリケーション構成までセットアップ済みとします。
Orchestratorのインストール
Orchestratorにはプレインストール用スクリプトが用意されていますので、そちらを使用します。
|
1 2 |
$ curl -s https://packagecloud.io/install/repositories/github/orchestrator/script.rpm.sh | sudo bash $ yum -y install orchestrator |
Orchestratorは以下のディレクトリにインストールされました。
|
1 2 3 4 5 6 7 8 9 |
$ rpm -ql orchestrator /etc/init.d/orchestrator /usr/local/orchestrator/orchestrator /usr/local/orchestrator/orchestrator-sample-sqlite.conf.json /usr/local/orchestrator/orchestrator-sample.conf.json /usr/local/orchestrator/resources/bin/orchestrator-client /usr/local/orchestrator/resources/metrics/orchestrator-grafana.json : : |
バックエンドDBの作成
OrchestratorはバックエンドデータベースサーバにSQLITE3かMySQLを使用します。
今回はMySQLをインストールしました。
|
1 2 3 4 5 |
$ yum -y install https://dev.mysql.com/get/mysql80-community-release-el7-1.noarch.rpm $ yum install -y mysql-community-server $ PASS=$(grep -i temporary /var/log/mysqld.log | rev | cut -d" " -f1 | rev) $ mysql -uroot -p$PASS -e "alter user root@localhost identified by 'MySQL8.0'" --connect-expired-password $ mysql -uroot -pMySQL8.0 |
Orchestrator用のスキーマ、ユーザーをMySQLに作成します。
なお、今回はローカルホストにインストールしたMySQLを使用していますが、Orchestrator自身の可用性を高めるために、リモートのレプリケーション構成のMySQLを使用することも可能です。
|
1 2 3 |
mysql> CREATE DATABASE IF NOT EXISTS orchestrator; mysql> CREATE USER orchestrator@localhost identified with mysql_native_password by "MySQL8.0" ; mysql> GRANT ALL PRIVILEGES ON `orchestrator`.* TO 'orchestrator'@'localhost'; |
設定ファイルの作成
Orchestratorは、以下の順序で設定ファイルを探します。
- orchestrator -c オプションで指定したファイル
- /etc/orchestrator.conf.json
- conf/orchestrator.conf.json
- orchestrator.conf.json
今回は、
/etc/orchestrator.cnf.jsonに設定ファイルを作成します。
/usr/local/orchestrator/orchestrator-sample.conf.json をベースに必要な部分のみ変更します。
|
1 2 |
$ cp -pi {/usr/local/orchestrator/orchestrator-sample,/etc/orchestrator}.conf.json $ vi /etc/orchestrator.conf.json |
サンプル設定ファイルから以下を変更します。
データベース接続情報
バックエンドDB、ターゲットDBへの接続情報を設定する必要があります。
接続ユーザー、パスワードは以下の部分に設定する事が可能です。
|
1 2 3 4 5 6 |
: "MySQLTopologyUser": "orchestrator", "MySQLTopologyPassword": "MySQL8.0", : "MySQLOrchestratorUser": "orchestrator", "MySQLOrchestratorPassword": "MySQL8.0", |
別の指定方法として、MySQLTopologyCredentialsConfigFileや、MySQLOrchestratorCredentialsConfigFileがあります。
|
1 2 3 |
"MySQLTopologyCredentialsConfigFile": "/etc/orchestrator-topology.cnf", : "MySQLOrchestratorCredentialsConfigFile": "/etc/orchestrator-backend.cnf", |
パスに指定するファイルは以下の内容です。
|
1 2 3 |
[client] user=orchestrator password=${ORCHESTRATOR_PASSWORD} |
この方法が優れているのは、環境変数が使用できる点です。よりセキュアに設定を行うことができます。
|
1 |
$ export ORCHESTRATOR_PASSWORD=MySQL8.0 |
リカバリフィルタ
サンプルではリカバリターゲットフィルタ部分が適当な文字列になっています。
追加するクラスタ名がここにマッチしないと停止時のフェイルオーバは行われません。
今回はワイルドカードを指定します。
|
1 2 3 4 5 6 7 8 |
: "RecoverMasterClusterFilters": [ "*" ], "RecoverIntermediateMasterClusterFilters": [ "*" ], : |
ターゲットデータベースサーバの設定
orchestratorからの監視用ユーザーを作成する必要があります。
|
1 2 |
mysql> CREATE USER orchestrator@`192.168.122.214` identified with mysql_native_password by "MySQL8.0" ; mysql> GRANT ALL ON *.* TO orchestrator@`192.168.122.214`; |
my.cnfでは、バイナリログ、GTIDの有効化と、いくつかの設定を行いました。
なおGTIDは必須ではありません。
|
1 2 3 4 5 6 7 |
log_bin=mysql-bin enforce-gtid-consistency gtid-mode=ON log_slave_updates slave_net_timeout = 4; global max_connect_erorrs = 100000000 |
Orchestratorは監視対象となるMySQL自身から正常であるかどうか、という情報を収集します。
ですので、各ターゲットDBにおいてなるべく早いタイミングで異常を検知することで迅速なフェイルオーバが可能となります。
slave_net_timeoutを短くすることに加え、再接続間隔も短いほうが良いでしょう。
|
1 |
mysql> CHANGE MASTER TO MASTER_CONNECT_RETRY=1, MASTER_RETRY_COUNT=86400; |
上記の設定を行うと、問題が発生した場合に非常に短い間隔で再接続とエラーを繰り返します。
通常、適切な設定が行われていればスレーブからマスタへの接続に失敗する事はありませんが、接続失敗回数が max_connect_errorsの回数を超えるとマスタへの接続がブロックされてしまいます。
ですので、念の為max_connect_errorsも引き上げています。
Orchestratorの実行
設定が済んだところでOrchestratorを起動します。
|
1 2 3 4 |
$ /etc/init.d/orchestrator start Starting orchestrator... Ok $ /etc/init.d/orchestrator status Checking orchestrator... Running |
orchestrator-clientによる操作
今回Orchestratorの操作にはorchestrator-clientを使用しました。
orchestrator-clientはorchestratorへREST API経由で操作を行うためのCLIツールです。
orchestrator本体と概ね同じ事が実行できます。
orchestrator-clientの準備
内部的にjqを使用しているため、別途インストールします。
|
1 2 |
$ yum -y install epel-release $ yum -y install jq |
利用前にORCHESTRATOR_API環境変数にREST APIのエンドポイントのベースURLを設定する必要があります。
orchestrator-clientのPATHと一緒に.bashrcに記載しておきます。
|
1 2 3 |
$ echo "export ORCHESTRATOR_API=http://localhost:3000/api" >> ~/.bashrc $ echo "export PATH=$PATH:/usr/local/orchestrator/resources/bin" >> ~/.bashrc $ source ~/.bashrc |
データベースクラスタの追加と管理
まずは、Orchestratorにデータベースクラスタを追加します。
マスタサーバを追加すると、スレーブサーバはクラスタの一部として自動的に追加されます。
クラスタ名にはデフォルトではマスタサーバの名前が使用されます。
|
1 2 |
$ orchestrator-client -c discover -i test1:3306 test1:3306 |
登録したクラスタを確認します。
|
1 2 |
$ orchestrator-client -c clusters test1:3306 |
クラスタ内のトポロジを確認すると、全てのサーバが監視対象となっている事がわかります。
|
1 2 3 4 |
$ orchestrator-client -c topology -i test1:3306 test1:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] + test2:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] + test3:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] |
おっと、スレーブサーバをread_onlyにするのを忘れていました。
その場合もわざわざ各サーバにログインする必要は無く、orchestrator-clientから実行できます。
|
1 2 3 4 5 6 7 8 9 |
$ O=orchestrator-client $ $O -client -c which-cluster-instances -alias test1 | grep -v test1 | while read i do $O -client -c set-read-only -i $i done $ $O -client -c topology -i test1:3306 test1:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] + test2:3306 [0s,ok,8.0.13,ro,ROW,>>,GTID] + test3:3306 [0s,ok,8.0.13,ro,ROW,>>,GTID] |
他にもOrchestratorから様々な管理操作が行えます。
ちなみにクラスタを削除したいときは、
forget-cluster、サーバを削除したいときは
forgetです。
詳しくは
orchestrator-client -c helpをご確認ください。
フェイルオーバの準備
フェイルオーバについては、以下のドキュメントにまとまっています。
https://github.com/github/orchestrator/blob/master/docs/topology-recovery.md
Orchestratorはフェイルオーバがトリガされると以下の順序で処理を行います。
- Pre-recovery hooks (external processes execution)
- Healing of topology
- Post-recovery hooks(Post-recovery failer hooks)
OrchestratorはHealing of topologyのフェーズでレプリケーションマスタの切り替えを自動的に行いますが、
Pre-recovery hooksやPost-recovery hooksでどのように前処理を行い、アプリケーションからの接続先を切り替えるのかという点はユーザーが作り込む必要があります。
今回はシンプルに、Orchestrator上のdnsmasqのAレコードを書き換える事でサービス側のフェイルオーバを実現します。
dnsmasqの準備
masterサーバのIPを解決するように設定しておきます。
なお、今回は検証ですので確認のための接続もOrchestrator上から行います。
|
1 2 3 4 5 6 7 8 9 10 |
$ yum -y install dnsmasq $ cat >> /usr/local/orchestrator/hosts-local.conf <<EOF 192.168.122.211 master 192.168.122.211 test1 192.168.122.212 test2 192.168.122.213 test3 $ dnsmasq --port=53 --no-hosts --addn-hosts=/usr/local/orchestrator/hosts-local.conf --user=root $ echo "nameserver 127.0.0.1" > /etc/resolv.conf $ dig master +short 192.168.122.211 |
/etc/orchestrator.conf.jsonにフェイルオーバ後の処理を追加します。
PostMasterFailoverProcessesにJSONのリスト形式で実行したい処理を追記していきます。
FailureDetectionPeriodBlockMinutesはフラッピングが発生した際に再度フェイルバックするような動作を行わないための時間(分)です。
今回は検証のために1としました。
|
1 2 3 4 5 6 7 |
"FailureDetectionPeriodBlockMinutes": 1, : "PostMasterFailoverProcesses": [ "echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log" ,"/usr/local/orchestrator/change_master_arec.sh {successorHost} /usr/local/orchestrator/hosts-local.conf" ] : |
/usr/local/orchestrator/change_master_arec.shは以下のように作成しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#!/bin/bash -eu func_restart_dnsmasq(){ pgrep dnsmasq | xargs kill -9 dnsmasq --port=53 --no-hosts --addn-hosts=/usr/local/orchestrator/hosts-local.conf --user=root } MYSQL_PWD=MySQL8.0 NEW_MASTER_IP=$(/usr/bin/mysql -uroot -BN -e "SELECT Ipv4 FROM orchestrator.hostname_ips WHERE hostname = \"${1}\"") sed -i "1s/.*/$NEW_MASTER_IP master/g" /usr/local/orchestrator/hosts-local.conf func_restart_dnsmasq |
実行権限を付与します。
|
1 |
$ chmod +x change_master_arec.sh |
フェイルオーバの実行
それではやっとフェイルオーバを実行してみましょう。
ターミナルをいくつか用意し、クラスタのトポロジの監視、Aレコードの監視、リカバリログの監視を行います。
トポロジの監視
|
1 2 3 4 5 |
$ while :;do $O -c clusters | xargs -I{} $O -c topology -i {};sleep 1;done test1:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] + test2:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] + test3:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] : |
A レコードの監視
|
1 |
$ while :;do dig master +short;sleep 1;done |
ログの監視
|
1 |
$ tail -f /tmp/recovery.log |
test1(現マスタ)をsytemctlで停止します。
|
1 |
$ systemctl stop mysqld |
最初はOrchestratorのトポロジ上で、test1が停止されたことが検知されます。
マスタの停止によってスレーブではレプリケーションが止まりました。
|
1 2 3 4 |
test1:3306 [unknown,invalid,8.0.13,rw,ROW,>>,GTID] - test2:3306 [null,nonreplicating,8.0.13,rw,ROW,>>,GTID] - test3:3306 [null,nonreplicating,8.0.13,rw,ROW,>>,GTID] : |
recovery.logには、フェイルオーバが行われたという出力が確認できます。
|
1 2 3 4 5 |
Detected UnreachableMaster on test1:3306. Affected replicas: 2 Detected DeadMaster on test1:3306. Affected replicas: 2 Will recover from DeadMaster on test1:3306 Recovered from DeadMaster on test1:3306. Failed: test1:3306; Promoted: test2:3306 (for all types) Recovered from DeadMaster on test1:3306. Failed: test1:3306; Successor: test2:3306 |
フェイルオーバまでは30秒程度要しましたが、最終的には失敗したtest1が切り離され、test2をマスタとしたレプリケーションになりました。
|
1 2 3 4 5 |
: test1:3306 [unknown,invalid,8.0.13,rw,ROW,>>,GTID,downtimed] test2:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] + test3:3306 [0s,ok,8.0.13,rw,ROW,>>,GTID] : |
正常にAレコードも切り替わったようです。
|
1 2 3 4 5 6 |
192.168.122.211 192.168.122.211 192.168.122.212 192.168.122.212 192.168.122.212 : |
まとめ
現状Orchestratorの情報自体が少ないこともあり設定に手間取る点もありますが、期待通りの動作を行えることが確認できました。
consulやetcdなどのサービスディスカバリソリューション、DNS切り替え、VIP切り替え等、柔軟にユーザー側でカスタマイズしてフェイルオーバ処理前後に加えられる点も魅力です。
MHAで使用していたスクリプトなど過去の資産も大部分はそのまま利用可能でしょう。
レガシーなHAソリューションから脱却したいとお考えの方は、Orchestratorはいかがでしょうか。





