※ この記事は前回からの続きになっています
前回、調査しきれなかった以下の点について確認していきたいと思います。
- MySQL InnoDB ClusterにおけるCLONE機能の利用
- CLONE機能を使用するうえでのデメリット(制限)
- リモートCLONEが内部的に実行しているコマンド
- CLONEと従来のバックアップツールの比較
1. MySQL InnoDB ClusterにおけるCLONE機能の利用
MySQL InnoDB Cluster(MIC)において、CLONE機能は以下のようなケースで利用できます。
- 各ノードのバックアップ
- ノードの配下に非同期スレーブを追加
- ノードのプロビジョニング
特に注目すべきは「3. ノードのプロビジョニング」です。これはCLONE機能でノードのデータを丸ごと別ノードにコピーすることで、「新規ノード追加」や「障害ノードの復旧」を実現できます。
PXCなどGalera Clusterを使用しているユーザには、「GaleraのSST」と同様の機能と言えば分かりやすいかと思います。
それでは早速このプロビジョニング機能を試してみましょう。
dbdeployerを使用した前回の記事とは異なり、MySQL Shell内のsandbox機能を用いてMIC検証環境を構築します。
参考:
21.2.6 Sandbox Deployment of InnoDB Cluster
まずはローカル環境にMySQL Server と MySQL Shell をインストールします(必要であればClientも)。
|
1 2 3 4 |
$ wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm $ sudo rpm -ivh ./mysql80-community-release-el7-3.noarch.rpm $ sudo yum install mysql-community-server mysql-shell mysql-community-client ... |
次に、MySQL Shell にログインしてインスタンスを3つ立ち上げます。
この時 mysqld のポートを指定する必要がありますが、InnoDB Cluster用のポートが mysqldのポート × 10 + 1 で自動計算される仕様上、ポート番号の上限である”65535″を超えないよう注意してください。
→ ここで”7000″ポートと指定するとデプロイ時にエラーが起こります
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ mysqlsh JS > dba.deploySandboxInstance(3310) ... Please enter a MySQL root password for the new instance: ******** → パスワードは"MySQL8.0"にする(以下2ノードも同様) ... Instance localhost:3310 successfully deployed and started. Use shell.connect('root@localhost:3310'); to connect to the instance. JS > dba.deploySandboxInstance(3320) JS > dba.deploySandboxInstance(3330) |
次に3310ポートのインスタンス(node1とする)に接続し、クラスタを作成します。
|
1 2 3 4 5 6 7 8 9 10 |
JS > \connect root@localhost:3310 Creating a session to 'root@localhost:3310' Please provide the password for 'root@localhost:3310': ******** Save password for 'root@localhost:3310'? [Y]es/[N]o/Ne[v]er (default No): Y ... localhost:3310 ssl JS > var cluster = dba.createCluster('testCluster') ... Cluster successfully created. Use Cluster.addInstance() to add MySQL instances. At least 3 instances are needed for the cluster to be able to withstand up to one server failure. |
続いて、node2 / node3 もクラスタに参加させます。
その中でノードのリカバリ(同期)方法についてのメッセージ(★)が出力されますが、そこに”CLONE”の選択肢が追加されているのが分かります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
localhost:3310 ssl JS > cluster.addInstance('root@localhost:3320') Please provide the password for 'root@localhost:3320': ******** Save password for 'root@localhost:3320'? [Y]es/[N]o/Ne[v]er (default No): Y ... ★Please select a recovery method [C]lone/[I]ncremental recovery/[A]bort (default Clone): C ... * Waiting for server restart... ready * 127.0.0.1:3320 has restarted, waiting for clone to finish... * Clone process has finished: 59.55 MB transferred in about 1 second (~inf TB/s) State recovery already finished for 'localhost:3320' The instance 'localhost:3320' was successfully added to the cluster. localhost:3310 ssl JS > cluster.addInstance('root@localhost:3330') ... |
これで、node1~node3のクラスタが完成しました。従来は mysqldump や MySQL Enterprise Backup などでノードをコピーする必要がありましたが、CLONE機能のおかげで簡単に構築ができるようになりました。
また上記の過程でCLONEプラグインがインストールされているため、初期構築時のみでなく通常運用時もCLONE機能が使えます。
|
1 2 3 4 5 6 |
localhost:3310 ssl JS > \sql show plugins; ... | group_replication | ACTIVE | GROUP REPLICATION | group_replication.so | GPL | | clone | ACTIVE | CLONE | mysql_clone.so | GPL | +---------------------------------+----------+--------------------+----------------------+---------+ 46 rows in set (0.0018 sec) |
以下は、ノード障害が発生した時に復旧させる場合にCLONE機能を使う例です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
localhost:3310 ssl JS > \sql CREATE DATABASE d1 localhost:3310 ssl JS > \sql CREATE TABLE d1.t1 (id int primary key) localhost:3310 ssl JS > \sql INSERT INTO d1.t1 VALUES (1),(2),(3) localhost:3310 ssl JS > \q Bye! $ ~/mysql-sandboxes/3330/stop.sh Stopping MySQL sandbox using mysqladmin shutdown... Root password is required. Enter password: $ rm -f ~/mysql-sandboxes/3330/sandboxdata/d1/t1.ibd → d1.t1 テーブルの.ibdファイルを削除する(データ破損を想定) $ ~/mysql-sandboxes/3330/start.sh & $ mysqlsh JS > \connect root@localhost:3310 JS > \sql INSERT INTO d1.t1 VALUES (4) localhost:3310 ssl JS > var cluster = dba.getCluster('testCluster'); localhost:3310 ssl JS > cluster.status(); { "clusterName": "testCluster", ... "127.0.0.1:3330": { "address": "127.0.0.1:3330", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "(MISSING)" } ... → node3の d1.t1 テーブルは存在しないため、エラーが発生 localhost:3310 ssl JS > cluster.rejoinInstance('root@localhost:3330') ... Cluster.rejoinInstance: Group Replication failed to start: MySQL Error 3092 (HY000): localhost:3330: The server is not configured properly to be an active member of the group. Please see more details on error log. (RuntimeError) → rejoinInstanceもできないため、ノード再作成が必要 localhost:3310 ssl JS > cluster.removeInstance('root@localhost:3330', {force:true}) → クラスタからnode3を強制的に削除 localhost:3310 ssl JS > dba.stopSandboxInstance(3330) localhost:3310 ssl JS > dba.deleteSandboxInstance(3330) Deleting MySQL instance... Instance localhost:3330 successfully deleted. localhost:3310 ssl JS > dba.deploySandboxInstance(3330) ... localhost:3310 ssl JS > cluster.checkInstanceState('root@localhost:3330') Analyzing the instance 'localhost:3330' replication state... There are transactions in the cluster that can't be recovered on the instance, however, Clone is available and can be used when adding it to a cluster. { "reason": "lost_transactions", "state": "warning" } → CLONE機能でリカバリできることを確認 ### 別コンソールを開く $ for i in {10..130}; do \ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3310 -e"INSERT INTO d1.t1 VALUES ($i)"; \ sleep 1s; \ done → 1秒おきにINSERTするスクリプト実行中に、node3のリカバリを実行 localhost:3310 ssl JS > cluster.addInstance('root@localhost:3330') localhost:3310 ssl JS > \connect root@localhost:3330 MySQL localhost:3330 ssl JS > \sql SELECT * FROM d1.t1 LIMIT 4; +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | +------+ 4 rows in set (0.0010 sec) MySQL localhost:3330 ssl JS > \sql SELECT count(*) FROM d1.t1; +----------+ | count(*) | +----------+ | 36 | +----------+ 1 row in set (0.0016 sec) → 問題なくデータが同期されていることを確認 |
2. CLONE機能を使用するうえでのデメリット(制限)
ここまでCLONEの良い点ばかりを紹介してきましたが、逆にデメリットについても調査しました。
マニュアルベースでは以下のような制限事項があります。
◆ DDL(TRUNCATE含む)はCLONE中は実行できない
実際に試してみます。前回の記事で構築した dbdeployer の環境を使用しても良いのですが、折角なので今回 MySQL Shell で構築したMIC環境を使用しましょう。
まずは、node1上で適当な大きさのテストデータを作成します。以下では、前回の記事同様 sysbench を使用した例を記載します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ mysqlsh JS > dba.deploySandboxInstance(3340) JS > \connect root@localhost:3340 localhost:3340 ssl JS > \sql CREATE USER sbuser@localhost IDENTIFIED WITH mysql_native_password BY 'password' localhost:3340 ssl JS > \sql GRANT ALL ON *.* TO sbuser@localhost localhost:3340 ssl JS > \q $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e "CREATE DATABASE sbtest" $ sysbench --db-driver=mysql --mysql-host=127.0.0.1 --mysql-port=3340 \ --mysql-user=sbuser --mysql-password=password --table-size=1000000 \ oltp_read_write prepare |
作成したテーブルに対してDDLを実行している間、別コンソールでCLONEの作成を試みると、たしかにCLONE処理が待機させられていることが分かります。
→ processlist の”Waiting for backup lock”状態
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
$ mkdir /tmp/cloned_data/ $ sudo chmod 777 /tmp/cloned_data/ $ sudo chown -R mysql:mysql /tmp/cloned_data/ $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e "INSTALL PLUGIN clone SONAME 'mysql_clone.so'" $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"ALTER TABLE sbtest.sbtest1 ADD INDEX idx01(c,pad)" ### 別コンソールで実行 $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"CLONE LOCAL DATA DIRECTORY '/tmp/cloned_data/first_clone/' " & $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"show processlist" +----+-----------------+-----------------+------+---------+------+-------------------------+------------------------------------------------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-----------------+-----------------+------+---------+------+-------------------------+------------------------------------------------------------+ | 4 | event_scheduler | localhost | NULL | Daemon | 4938 | Waiting on empty queue | NULL | | 39 | root | localhost:45154 | NULL | Query | 7 | altering table | ALTER TABLE sbtest.sbtest1 ADD INDEX idx01(c,pad) | | 40 | root | localhost:45156 | NULL | Query | 7 | Waiting for backup lock | CLONE LOCAL DATA DIRECTORY '/tmp/cloned_data/first_clone/' | | 41 | root | localhost:45164 | NULL | Query | 0 | starting | show processlist | +----+-----------------+-----------------+------+---------+------+-------------------------+------------------------------------------------------------+ |
ただし、MySQL8.0で追加された INSTANT DDLなどを活用すれば、影響を最小限に抑えつつ運用ができそうです。
◆ 異なるバージョン間のCLONEの復元はできない
クローンの取得元と復元先のMySQLは同じバージョンであることが求められます。
また、CLONEはMySQL8.0.17からの新機能なのでそれ以前のバージョン(MySQL5.7含む)では復元することができません。
◆ 複数インスタンスから同時にCLONEはできない
1回のCLONE操作で複数のMySQLインスタンスからデータを取得することはできません。
その場合は、各インスタンスに対して1回ずつCLONEを実行していきましょう。
◆ X Protocolを利用したリモートCLONEはできない
mysqlx_port 変数で指定した X Protocol 用ポートを指定して、CLONE操作を行うことはできません。
セキュリティ上の理由から利用できるポートを制限している場合などは注意が必要です。
◆ サーバの設定情報はCLONEでコピーされない
CLONEデータには my.cnf などの設定ファイルが含まれないため、Donorノードのパラメータ設定などはコピーされません。
また、SET PERSISTで変更した変数の情報も同様にコピーされません。
◆ バイナリログはコピーされない
設定ファイルと同様に、バイナリログもコピー対象から外れています。
◆ CLONEの対象はInnoDBのみ
CLONEプラグインが正式にサポートしているのはInnoDBのみです。そのため、MyISAMやCSV、sysスキーマなどのテーブルは、データが空の状態で復元されます。
◆ MySQL Router 経由でDonorノードに接続できない
MySQL Routerから直接DonorとなるMySQLに接続できません。これは運用時に注意が必要です。
◆ 絶対パスの一般テーブルスペースはサポート外
ローカル上でCLONEを作成する場合、絶対パスで作成された一般テーブルスペースはサポート対象外になります。
これはCLONE実行時に既存のファイルと同じパス上にCLONEデータを作成しようとして、競合してしまうためです。
また、このマニュアルには明記されていませんが以下のような制限事項もあるようでした。
◆ Group Replication 実行中は、手動のCLONEコマンドは実行できない
MIC環境で試したところ、以下のエラーが発生しました。
|
1 2 3 |
$ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3310 -e"CLONE LOCAL DATA DIRECTORY '/tmp/cloned_data/first_clone/' " mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 3875 (HY000) at line 1: The clone operation cannot be executed when Group Replication is running. |
3. リモートCLONEが内部的に実行しているコマンド
次に、CLONEがInnoDBテーブルのデータをコピーする際に、内部的にどのような挙動をしているのか見てみたいと思います。
本来はソースコードを細かく読み解くのが確実ですが、今回はCLONE関連の Worklog を基に考えたいと思います。
まず、WL#9209: InnoDB: Clone local replicaのチケットを読むと、以下のことが分かります。
- CLONEプラグインは「単なるデータ転送」ではなく、「InnoDBのスナップショットの取得」を目的にデザインされている(copy & apply)
- スナップショットの送受信はCLONEプラグインと SE(ストレージエンジン)層のClone Handleで行われる(現時点ではシングルタスクのみ対応)
- InnoDB の “Page Tracking” と “Redo Archiving” 機能が利用されている
- スナップショットの取得は以下のようなステップで行われる
【各フェーズの説明】
cloneオブジェクトの初期化
2. FILE COPY
全てのデータベースファイルをコピーし、呼び出し元(clone plugin)に送信
3. PAGE COPY
コピー開始/終了(バッファプールから読み取ったCLONE START LSN / CLONE FILE END LSN)までの間に変更されたページ(Page ID)を、送信
→ donor のランダムREAD, recipient のランダムWRITEを回避する
4. REDO COPY
LSNが記録されたRedoログを送信(レプリケーション開始に必要な座標も含む、詳細は[#9211](https://dev.mysql.com/worklog/task/?id=9211))
5. Done
処理の終了、cloneオブジェクト自体はsnapshot_end()が呼び出されるまで残る
次に、WL#9210: InnoDB: Clone remote replicaではリモート間のCLONE操作に関して説明がされています。これを読むと以下のことが分かります。
- ローカルサーバ(RECIPIENT)上で、リモートサーバ(DONOR)を対象にCLONEコマンドを実行することでリモートCLONEが開始する
- この時の操作はRPC(リモートプロシージャコール)”COM_CLONE”として行われる
→ RPCコマンドとレスポンスコードをまとめて”CLONE PROTOCOL”と呼ぶ - RECIPIENT / DONOR 間の処理の流れはワークログに記載された以下の図が分かりやすい
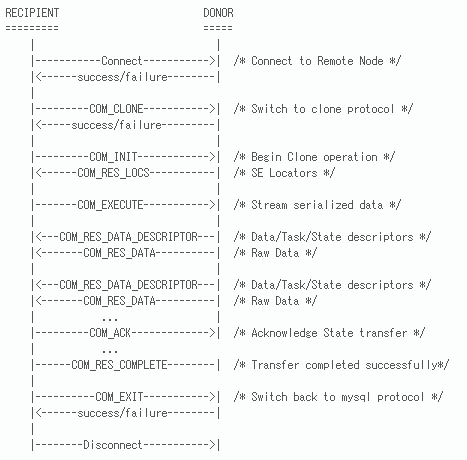
【図内の処理の説明】(一部、図に含まれないものもあります)
clone protocol のバージョンを確認し、DONORのSE層とCLONEクライアント間でCLONE操作を開始する。将来的には内部的にバージョンの差異を埋めるように通信を行う機能も追加予定。
2. COM_ATTACH
進行中のCLONE操作にアタッチする新しい制御スレッドを指します。マルチスレッド処理をサポートします。
3. COM_REINIT
ネットワーク障害後にクローン操作を再開します。障害が発生すると、全てのCLONEクライアント/サーバのマスタスレッドがその他の全スレッドのクローズを待ったあと、再接続を試みます。これに成功した場合、CLONEクライアントはサーバに対して最新のSEロケータ情報を送信します。
クローン操作のロケータはスナップショットの論理ポインタのことです。サーバはスナップショットを再初期化してロケータを返します。
4. COM_EXECUTE
CLONE操作を開始し、クライアントにストリーミングデータを返します。シリアル化されたディスクリプタはSE固有のものであり、RECIPIENTがデータを保存している間に直接SEに渡されます。
DONORはネットワーク経由でスナップショットからデータをストリーミングします。データは応答データパケットとして複数チャンクで送信されます。
A) COM_RES_LOCS
クライアントからサーバへのロケータセット。
B) COM_RES_DATA_DESC
データパケットの情報を持つディスクリプタ。ヘッダがCLONEプラグインのSEインデックスになっている。その後の部分には、ステータス情報やタスク情報、ファイルのメタデータ、次ブロックの情報などが含まれている。
C) COM_RES_DATA
lengthデータ形式の生データ
D) COM_RES_COMPLETE
CLONE操作が問題なく終了した。
E) COM_RES_ERROR
CLONE操作がエラーで終了した。
COM_RES_DATA を使用すると、データ全体がこのような複数チャンクで転送されます。全て転送された後、DONORは CLONE_COM_END を送って終了します。
5. COM_ACK
異なるCLONEステータスへの切り替えが正常に行われたことを確認します。DONORはRECIPIENTから正常ACKを受け取れた時のみ、次の段階に移行します。動的スナップショットを前のステージに戻すことはできません。
これはCLONEクライアントのエラーをCLONEサーバに伝える時にも使用されます。COM_EXECUTE中はデータがCLONEサーバ→CLONEクライアントの一方向にのみストリーミングされることに注意してください。
6. COM_EXIT
CLONEプラグイン、およびプロトコルを終了し、通常のサーバプロトコルに戻ります。
以上2点のワークログから、CLONE機能はプラグイン、ストレージエンジン間で直接データ(スナップショット)をやり取りしていることが分かります。また、その送受信は並列化で実行されています。
こうした挙動を柔軟に制御するため、CLONE機能用のシステム変数が用意されています。詳細は前回の記事を参照してください。
また、performance_schema.clone_progressテーブルを参照すれば、実行中のCLONE操作が現在どの段階を実行中なのかを確認することもできます(CLONEのモニタリング)。また、以下のようにCLONE関連の instruments を有効にすることでも情報収集が可能です。
|
1 2 |
mysql> UPDATE performance_schema.setup_instruments SET ENABLED = 'YES' WHERE NAME LIKE 'stage/innodb/clone%'; mysql> UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE '%stages%'; |
4. CLONEと従来のバックアップツールの比較
最後に同じテーブルデータに対し、mysqldump / MySQL Enterprise Backup / CLONE の取得・リストアを実施し、それぞれの操作にかかった時間を比較します。
※ MySQL Enterprise Backup(以下、MEB)は、MySQL Enterprise Editionで利用できるバックアップツールです
比較方法
以下のような手順で比較を行います。MySQLインスタンスは、上記で作成したテスト用インスタンス(port : 3340)を使用します。
(1) sysbench でテストデータを作成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
$ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"DROP DATABASE IF EXISTS sbtest" $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"DROP DATABASE IF EXISTS sbtest2" $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"CREATE DATABASE sbtest" $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"CREATE DATABASE sbtest2" $ sysbench --db-driver=mysql --mysql-host=127.0.0.1 --mysql-port=3340 \ --mysql-user=sbuser --mysql-password=password --mysql-db=sbtest \ --tables=10 --table-size=1000000 oltp_read_write \ prepare $ sysbench --db-driver=mysql --mysql-host=127.0.0.1 --mysql-port=3340 \ --mysql-user=sbuser --mysql-password=password --mysql-db=sbtest2 \ --tables=5 --table-size=1000000 oltp_read_write \ prepare $ sudo ls -lh ./mysql-sandboxes/3340/sandboxdata/sbtest 合計 2.4G -rw-r----- 1 takahashi takahashi 240M 11月 19 11:18 sbtest1.ibd … $ sudo ls -lh ./mysql-sandboxes/3340/sandboxdata/sbtest2 合計 1.2G -rw-r----- 1 takahashi takahashi 240M 11月 19 11:25 sbtest1.ibd ... |
(2) 調査対象のツールでバックアップを実行
CLONE機能の場合全データベースがバックアップ対象になるので、その他のバックアップツールも全データベースを対象としたフルバックアップを使用します。
ツール実行時にtimeコマンドをつけて、”real”の時間を計測します。
【A】mysqldump
|
1 2 3 4 |
$ mysqldump --version mysqldump Ver 8.0.18 for Linux on x86_64 (MySQL Community Server - GPL) $ time mysqldump -uroot -pMySQL8.0 -h127.0.0.1 -P3340 --all-databases --set-gtid-purged=OFF --single-transaction > ~/full_dump.sql |
【B】MEB
|
1 2 3 4 5 |
$ mysqlbackup --version MySQL Enterprise Backup Ver 8.0.18-commercial for Linux on x86_64 (MySQL Enterprise - Commercial) $ mkdir ./meb_backup $ time sudo mysqlbackup --user=root --password=MySQL8.0 --host=127.0.0.1 --port=3340 --backup-dir=./meb_backup backup-and-apply-log |
【B】CLONE
|
1 |
$ time mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e "CLONE LOCAL DATA DIRECTORY '/home/takahashi/cloned_data/' " |
(3) 調査対象のツールでリストアを実行
sbtest / sbtest2 データベースを削除したのち、各ツールのバックアップリストアを実行します。ここでも time コマンドで時間を計測します。
|
1 2 |
$ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"DROP DATABASE sbtest" $ mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 -e"DROP DATABASE sbtest2" |
【A】mysqldump
|
1 |
$ time mysql -uroot -pMySQL8.0 -h127.0.0.1 -P3340 < ~/full_dump.sql |
【B】MEB
|
1 2 3 4 5 6 7 |
$ ./mysql-sandboxes/3340/stop.sh $ rm -rf ./mysql-sandboxes/3340/sandboxdata/* $ time sudo mysqlbackup --backup-dir=./meb_backup --datadir=./mysql-sandboxes/3340/sandboxdata/ copy-back $ sudo chown takahashi:takahashi ./mysql-sandboxes/3340/sandboxdata/ $ ./mysql-sandboxes/3340/start.sh & |
【C】CLONE
|
1 2 3 |
$ ./mysql-sandboxes/3340/stop.sh $ time cp -rf ./cloned_data/* ./mysql-sandboxes/3340/sandboxdata/ $ ./mysql-sandboxes/3340/start.sh & |
(4) ステップ(1)に戻り、別のツールで試験を実施
テスト結果
各ツールのバックアップ・リストアにかかった時間は、以下のようになりました。
もちろん環境やデータ、試験方法によっても変わってくると思うので、参考程度に捉えて頂ければと思います。
| mysqldump | MEB | CLONE | |
|---|---|---|---|
| バックアップ | 1m18.366s | 48.923s | 24.444s |
| リストア | 11m30.922s | 55.729s | 20.699s |
バックアップ対象の差異などもありますが、CLONEの実行時間がかなり速いことが分かりました。
まとめ
ここまで2つの記事に渡ってCLONE機能を取り上げてきましたが、実際に触ってみた体感としてもとても便利な機能だと思います。
今後のMySQL8.0運用の形が変わる可能性もあり、今後の機能改善や拡張からも目が離せません。
その他、参考にしたページ
A Breakthrough in Usability – Automatic Node Provisioning
21.2.5 Using MySQL Clone with InnoDB cluster