企業のDXやAI活用が加速する中、多くの組織が直面しているのが「データは増えているのに活かせていない」という課題です。営業データは営業部門、在庫情報は物流部門と、社内のあちこちにデータが散らばり、必要なときに必要な情報が取り出せません。データ活用基盤は、こうした分散データを一元的に収集・蓄積・加工し、分析や可視化へとつなげる土台となる仕組みです。
本記事では、データ活用基盤の役割・構成要素・導入メリットを体系的に解説し、自社に最適な基盤導入と運用のポイントをお伝えします。
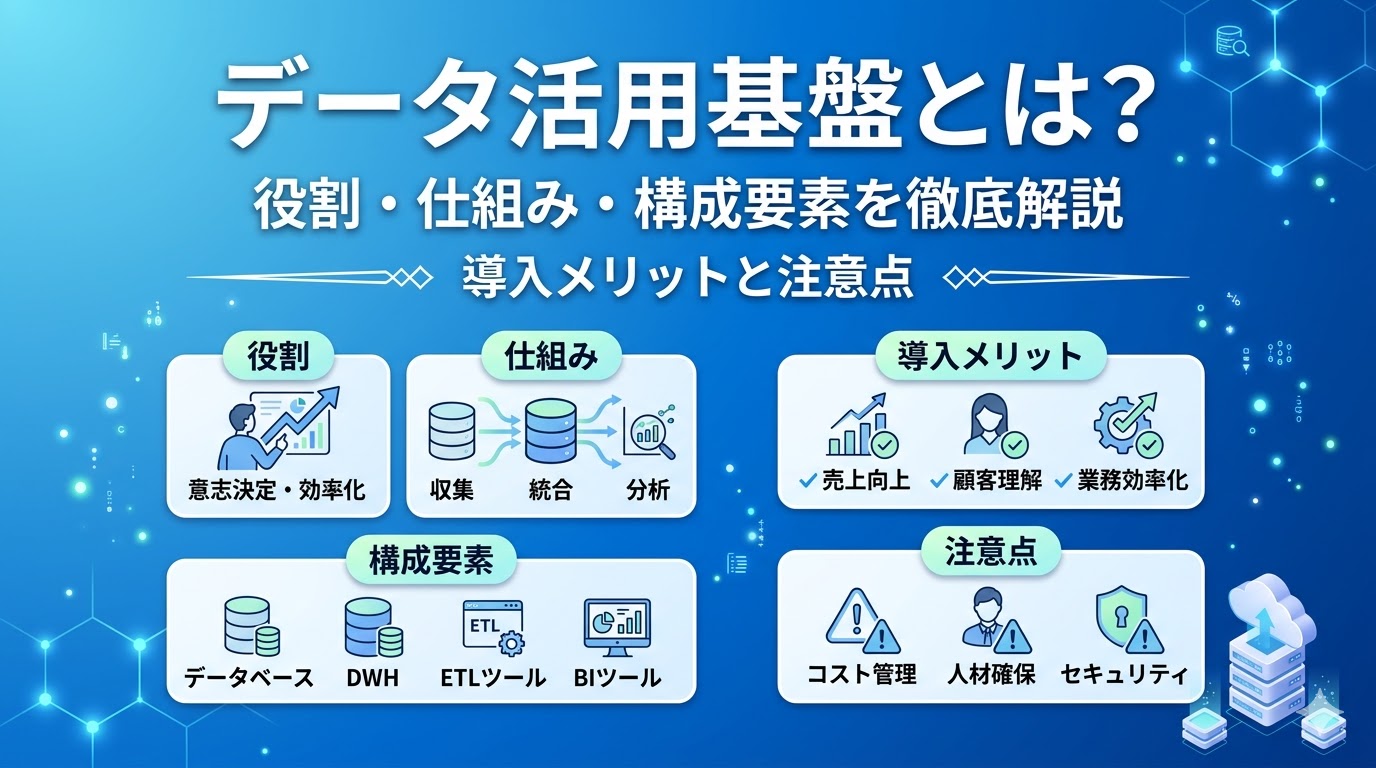
データ活用基盤とは何か
『データ活用基盤』という言葉は聞くけれど、具体的に何を指すのか、その定義や目的がよくわからない」という方もいると思います。データ活用基盤について理解するには、まずその定義と目的を押さえておく必要があります。
データ活用基盤の定義と目的
データ活用基盤とは、社内外の多様なデータを統合的に収集・蓄積・加工し、分析や意思決定に活用できる形で提供するITインフラです。従来のように部門ごとに独立したデータベースや表計算ソフトで業務データを管理していた状態から、全社横断的にデータを一元管理できる環境へと進化させます。その目的は、データの分断を解消し、経営判断や業務改善の質とスピードを飛躍的に高めることにあります。
データ活用基盤は、単なるデータの保管庫ではなく、データを「資産」として戦略的に活用するための基盤という位置づけです。DXやAI活用を進める上でも、データ活用基盤は土台となる存在といえるでしょう。
対象となるデータの種類
データ活用基盤が扱うデータは実に多様です。営業管理システムの顧客情報、ECサイトのアクセスログ、製造ラインのセンサーデータ、SNSの投稿データなど、構造化データと非構造化データの両方が対象になります。
構造化データとは、リレーショナルデータベースに格納される表形式のデータです。一方、非構造化データはテキスト、画像、動画、音声といった形式が定まっていない情報を指します。データ活用基盤は、これらを横断的に取り込み、分析可能な形に整えていきます。
データレイクとDWHの違い
データ活用基盤を構成する要素として、よく耳にするのが「データレイク」と「データウェアハウス(DWH)」です。両者は似ているようですが、実は役割が異なります。
データレイクは、構造化・非構造化を含むデータを原形式のまま(as-is)でも保存できる集中リポジトリで、後段の処理・分析の起点になる場所です。加工せず、まずは集めておくという発想で、後から必要に応じて取り出して分析します。一方、データウェアハウスは、複数ソースの構造化・半構造化データを統合し、分析・レポーティングしやすい形で管理する基盤です。データレイクが「原材料の貯蔵庫」なら、データウェアハウスは「加工済み製品の在庫棚」といえるでしょう。
データパイプラインとETLの違い
データを基盤内で移動・加工する仕組みとして、「データパイプライン」と「ETL」という概念があります。ETLは、Extract(抽出)、Transform(変換)、Load(格納)の頭文字をとったもので、データを取り出し、整形して、目的の場所に格納する一連の処理を指します。
データパイプラインは、ETLを含むより広い概念です。データの流れ全体を自動化し、リアルタイムやバッチ処理でデータを次々と処理していく仕組みを指します。ETLはデータ処理の代表的な手法の一つであり、データパイプラインはデータの取り込み・変換・保存・配信といった処理の流れ全体を自動化して管理する仕組みを指します。
データ活用基盤の必要性
なぜ今、データ活用基盤が企業にとって不可欠なのでしょうか。その背景には、経営環境の変化とデータ量の爆発的増加があります。
DX推進やAI活用が進む背景
デジタルトランスフォーメーションが叫ばれる中、企業は業務プロセスの効率化やビジネスモデルの変革を迫られています。その実現には、データを起点とした意思決定と継続的な改善が欠かせません。
AI技術の進化により、予測分析や自動化が身近になりましたが、AIモデルの精度はデータの質と量に大きく左右されます。AIを企業全体で活用するためには、散在するデータを統合し、分析可能な状態に整備しておくことが重要になります。
データ活用基盤は、こうした次世代技術を支える土台として注目されています。
データの分散・サイロ化が生む課題
多くの企業では、部門ごとに異なるシステムやツールを使っており、データが分散しています。営業部門はCRM、マーケティング部門はMAツール、経理部門は会計システムといった具合です。こうした状態を「データのサイロ化」と呼びます。
サイロ化が進むと、全社視点での分析が困難になり、意思決定の遅れや機会損失につながります。データを統合して一元管理する基盤があれば、部門を越えた横断分析が可能になり、経営の透明性と俊敏性が高まります。
経営判断・業務効率化との関係
経営層が迅速かつ的確な判断を下すには、最新かつ正確なデータが不可欠です。しかし、データが分散していると、レポート作成に時間がかかり、分析結果が古くなってしまいがちです。
データ活用基盤を導入することで、データを集約し、BIツールなどでダッシュボードとして可視化できるようになります。これにより、経営層は市場の変化や業績動向を即座に把握し、スピーディーな意思決定が可能になります。現場の業務でも、データ抽出や加工の手間が減り、本来の業務に集中できる環境が整備されます。
導入しない場合のリスク(属人化・機会損失)
データ活用基盤を整備しないまま放置すると、いくつかのリスクが顕在化します。まず、データ抽出や加工が特定の担当者に依存し、属人化が進みます。また、その担当者が異動や退職すると、業務が滞るだけでなく、データの所在や加工方法が不明になってしまうこともあります。
さらに、データを活用できないことで、市場機会を逃したり、競合に後れを取ったりする機会損失も発生します。データドリブンな経営が当たり前になる時代において、基盤整備の遅れは企業競争力の低下に直結するでしょう。
データ活用基盤に必要な機能と基本構成
データ活用基盤と一言で言っても、それは単にデータを貯める箱ではありません。データを集め、きれいに整え、分析したい人に届けるまで、多くの機能が連携して動いています。ここでは、この基盤を成り立たせるために欠かせない、主要な機能と全体の構成について解説します。
データ収集と連携を実現する仕組み
データ活用基盤の出発点は、社内外のさまざまなデータソースからデータを集めることです。基幹システム、Webサービス、IoTデバイス、外部APIなど、多様なデータソースと連携できる仕組みが求められます。
この役割を担うのがETL/ELTツールやデータ統合ツールです。これらのツールは、データの抽出、変換、格納を自動化し、リアルタイムまたは定期的にデータを基盤へ取り込みます。API連携やファイル転送、データベース接続など、柔軟な接続方法に対応していることが重要です。
データ加工と統合を行う処理プロセス
収集したデータは、そのままでは分析に使えないことが多々あります。それは、フォーマットが異なったり、欠損値があったり、重複していたりするためです。データ加工と統合のプロセスでは、データのクレンジング、正規化、マッピングを行い、分析可能な状態に整えます。
この処理は、ETL/ELT処理を含むデータパイプラインによって実行されます。データ品質を担保しながら、効率的に加工を進めることが、後工程の分析精度を左右します。自動化された処理フローを構築することで、手作業によるミスや遅延を防げます。
データ保管と最適化を行うアーキテクチャ設計
加工されたデータは、適切な保管場所に格納されます。ここで登場するのが、データレイク、データウェアハウス、データマートといった階層型の保管アーキテクチャです。
データレイクには、構造化・非構造化を含む大量のデータを保存し、データウェアハウスには整形済みのデータを蓄積します。さらに、特定の部門や用途に特化したデータマートを作ることで、利用者が必要なデータに素早くアクセスできるようになります。アーキテクチャ設計では、データ量やアクセス頻度、コストを考慮し、最適な保管方法を選択することが求められます。
分析と可視化の仕組み
データ活用基盤の最終的な価値は、分析と可視化にあります。蓄積されたデータを元に、BIツールやダッシュボードで可視化し、誰でも直感的に理解できる形で提供します。
BIツールは、グラフやチャートを用いてデータを視覚化し、トレンドやパターンを浮かび上がらせます。また、機械学習モデルと連携すれば、予測分析や異常検知といった高度な分析も可能です。利用者が自由にデータを探索できるセルフサービスBIの環境を整えることで、データ活用の民主化が進みます。
データガバナンスとセキュリティで押さえるべき要素
データ活用基盤の構築において、見落としてはならないのがデータガバナンスとセキュリティです。データの品質管理、アクセス権限の設定、プライバシー保護、コンプライアンス対応など、データの信頼性と安全性を担保する仕組みが不可欠です。
データガバナンスでは、データの所有者や管理ルールを明確にし、データ品質を継続的に監視します。セキュリティ面では、暗号化、アクセスログの監視、定期的な脆弱性診断などを実施し、情報漏洩や不正アクセスのリスクを最小化します。
クラウドとオンプレミスのアーキテクチャ比較
データ活用基盤の構築には、クラウドとオンプレミスという2つの選択肢があります。クラウド基盤は、初期投資を抑え、柔軟にスケールできるのが特徴です。データ量の増減に応じてリソースを調整でき、最新のサービスをすぐに利用できます。
一方、オンプレミス基盤は、自社でハードウェアやソフトウェアを保有し、運用する形態です。セキュリティや規制対応の要件が厳しい場合や、既存システムとの密接な連携が必要な場合に選ばれます。近年では、クラウドとオンプレミスを組み合わせたハイブリッド構成も増えているため、企業のニーズに応じた柔軟な設計が可能となっています。
| 項目 | クラウド基盤 | オンプレミス基盤 |
| 初期投資 | 低い(従量課金) | 高い(設備購入) |
| 拡張性 | 柔軟(即座にスケール) | 限定的(増設が必要) |
| 運用負荷 | 低い(ベンダー管理) | 高い(自社管理) |
| セキュリティ | クラウド事業者と利用者の共同責任 | 自社でコントロール可能 |
| 適用ケース | スタートアップ、急成長企業 | 規制対応、既存システム連携重視 |
クラウドとオンプレミス、どちらを選ぶかは、企業の規模、業種、セキュリティ要件、既存システムの状況などを総合的に判断する必要があります。
データ活用基盤導入で得られる効果と指標
「データ活用基盤を導入するメリットはわかったけれど、具体的にどんな効果が得られるのか、どうやって測ればいいのか」がよくわからないという方もいると思います。データ活用基盤を導入することで、具体的にどのような効果が期待できるのでしょうか。ここでは、主要なメリットと効果測定の指標を紹介します。
業務効率化と意思決定の高速化
データ活用基盤の最大のメリットは、業務効率の大幅な向上です。従来は、部門ごとにデータを手作業で集計し、Excelで加工してレポートを作成していました。この作業に数時間から数日かかることも珍しくありません。
基盤導入後は、データが自動的に集約・加工され、ダッシュボードでリアルタイムまたは定期更新で可視化されます。これにより、レポート作成の時間が大幅に短縮され、担当者は分析や改善施策の立案に時間を使えるようになります。経営層も最新データを即座に確認できるため、意思決定のスピードが格段に上がります。
データ品質向上と信頼性の確保
データ活用基盤では、データのクレンジングや標準化が自動化しやすくなるため、データ品質が安定し、信頼性が向上します。手作業による転記ミスや、部門ごとに異なる定義でデータを集計する問題が解消されます。
統一されたデータ定義とガバナンスルールに基づいて管理されることで、全社で同じ指標を見て議論できるようになります。データの正確性と一貫性が担保されることで、経営判断の質も高まります。
ビジネス成果を測るKPIと評価方法
データ活用基盤の導入効果を測るには、明確なKPIを設定することが重要です。代表的な指標として、レポート作成時間の短縮率、データ分析にかかる工数、意思決定のリードタイムなどが挙げられます。
また、ビジネス成果としては、データ活用を通じた売上改善、コスト削減、顧客満足度の改善、新規事業の立ち上げスピードなどを評価します。導入前後でこれらの指標を比較し、投資対効果を検証することで、継続的な改善につなげられます。
- レポート作成時間の短縮率(例:週10時間→2時間)
- データ分析にかかる工数の削減度合い(例:月間50時間→10時間)
- 意思決定のリードタイムの短縮度合い(例:1週間→1日)
- 売上向上率(例:前年比10%増)
- コスト削減額(例:年間500万円削減)
これらのKPIを定期的にモニタリングし、基盤の運用改善に活かしていくことが、持続的な成果を生み出す鍵です。
データ基盤構築を成功させるポイント
データ活用基盤の構築は、技術面だけでなく、組織や運用の側面からも注意すべき点があります。ここでは、成功に導くためのポイントを紹介します。
導入目的の明確化とスモールスタート
基盤構築の第一歩は、導入目的を明確にすることです。何のためにデータを活用するのか、どの業務課題を解決したいのかをはっきりさせないと、過剰なシステムを構築してしまったり、使われない基盤になったりします。
最初から大規模な基盤を構築するのではなく、スモールスタートで始めることも重要です。特定の部門やプロジェクトに絞って基盤を構築し、成果を確認しながら段階的に拡大していく方が、リスクを抑えながら確実に進められます。
経営・現場・ITの連携体制
データ活用基盤の成功には、経営層のコミットメント、現場の巻き込み、IT部門の技術力という3つの要素が不可欠です。経営層が基盤構築の意義を理解し、予算や人材を投入する姿勢を示すことで、全社的な取り組みとして推進できます。
現場の担当者は、実際にデータを使う立場として、どのような分析が必要かを具体的に伝える役割を担います。IT部門は、技術的な実現方法を提案し、基盤の構築と運用を支えます。三者が連携し、定期的にコミュニケーションを取ることで、現場のニーズに合った基盤が実現します。
データ品質・ガバナンスの設計
データ活用基盤の価値は、データの品質に大きく依存します。不正確なデータや古いデータでは、分析結果も信頼できません。そのため、データ品質管理とガバナンスの仕組みを導入初期から設計しておくことが重要です。
データのオーナーシップを明確にし、データ定義やメタデータを整備します。また、データの入力ルールや承認フローを定め、品質を保つ運用体制を構築します。これにより、全社で一貫性のあるデータ管理が実現します。
運用自動化と継続改善サイクル
基盤を構築した後も、運用と改善を継続することが不可欠です。データパイプラインの自動化を進めることで、手作業を減らし、運用負荷を軽減できます。定期的なモニタリングやアラート設定により、異常を早期に発見し、対応できる体制を整えます。
また、利用者のフィードバックを収集し、基盤の改善につなげるPDCAサイクルを回すことが重要です。新たなデータソースの追加、分析ニーズの変化に柔軟に対応しながら、基盤を進化させていきます。
成功企業に共通する特徴(事例要素)
データ活用基盤を成功させた多くの成功事例に共通して見られる特徴があります。まず、経営層がデータ活用の重要性を理解し、全社的な取り組みとして推進している点です。次に、現場の声を反映した設計を行い、利用者が使いやすい環境を整えています。
また、データガバナンスとセキュリティを初期から重視し、信頼性の高い基盤を構築しています。そして、スモールスタートで始め、段階的に拡大していくアプローチを取っている点も特徴的です。こうした取り組みにより、基盤導入の成果を最大化していきます。
データ活用基盤構築の進め方とよくある課題への対策
「基盤を作ったものの、現場のニーズと合わなかった」「データの品質が担保できない」。こうした課題は、データ活用基盤の構築プロジェクトでよく耳にします。ここでは、そうした失敗を避け、確実に成果を出すために、どのような手順で構築を進めるべきか、そして直面しやすい課題への具体的な対策をセットで見ていきます。
導入前の目的定義と体制づくり
基盤構築の最初のステップは、導入目的の明確化と推進体制の構築です。何を解決したいのか、どの部門やプロジェクトから始めるのかを決定します。経営層、現場、IT部門の代表者を集めたプロジェクトチームを立ち上げ、役割と責任を明確にします。
次に、現状のデータ環境を調査し、どのようなデータがどこに存在するかを把握します。この段階で、データの品質や利用状況、課題を洗い出し、基盤構築の要件を定義します。
設計とツール選定のポイント
要件が固まったら、基盤の設計とツール選定に移ります。データの流れ、アーキテクチャ、セキュリティポリシーを設計し、必要な機能を洗い出します。クラウドかオンプレミスか、どのETL/ELTツールやBIツールを使うかなど、技術選定を行います。
ツール選定では、既存システムとの連携性、拡張性、コスト、サポート体制などを総合的に評価します。また、利用者のスキルレベルに合わせた操作性も重要なポイントです。
構築フェーズの実務ステップ
設計が完了したら、実際の構築作業に入ります。データソースとの接続、データパイプラインの構築、データウェアハウスの設定、BIツールの導入といった作業を順次進めます。小規模なパイロットプロジェクトで動作を検証し、問題がないことを確認してから本格展開にとりかかります。
構築中は、現場と密にコミュニケーションを取り、ニーズのズレがないかを確認します。テストと改善を繰り返しながら、実用に耐える基盤を作り上げていきます。
運用と継続的改善の体制
基盤が稼働したら、運用フェーズへ移行します。定期的なモニタリング、データ品質チェック、パフォーマンスの最適化を継続的に実施します。利用者からのフィードバックを収集し、改善要望に対応していきましょう。
また、新たなデータソースの追加や分析ニーズの変化に対応し、基盤を進化させる体制を整えます。四半期ごとにレビュー会議を開き、KPIの達成状況や課題を共有し、次のアクションを決定します。
よくある課題と実用的な対策
データ活用基盤の構築には、いくつかの典型的な課題があります。まず問題として挙げられるのは、データ品質の低さです。元データに欠損や誤りが多いと、基盤を整えても意味がありません。対策としては、データ入力ルールの徹底やクレンジング処理の自動化が有効です。
次に、現場の協力が得られないという課題です。現場がメリットを感じなければ、データ提供や活用が進みません。対策としては、早期から現場を巻き込み、成果を見せることで協力を引き出します。
また、セキュリティやガバナンスの不備も大きなリスクです。情報漏洩や不正アクセスを防ぐため、初期段階からセキュリティ設計とガバナンスルールを整備し、定期的に監査を実施します。
- データ品質の低さ → 入力ルール徹底とクレンジング自動化
- 現場の協力不足 → 早期巻き込みと成果の可視化
- セキュリティ不備 → 初期設計と定期監査の実施
- 過剰な機能実装 → スモールスタートで必要機能を絞る
- 運用負荷の増大 → 自動化と監視体制の整備
これらの課題を事前に想定し、対策を講じることで、基盤構築の成功確率が高まります。
OCIで実現するデータ活用基盤
OCIで実現するデータ活用基盤(代表的サービス)
クラウド環境を利用すれば、データ活用基盤は比較的短期間で構築できます。その代表例の一つが Oracle Cloud Infrastructure(OCI) です。OCIでは、データの収集、保存、加工、分析、可視化、ガバナンスまでをクラウドサービスとして提供しており、企業のデータ活用を包括的に支えるエコシステムが整備されています。
ここでは、OCIを活用したデータ活用基盤の代表的な構成要素を紹介します。
データレイク(保存)|OCI Object Storage
OCI Object Storage は、大量のデータを低コストで保存できるクラウドストレージサービスです。ログデータ、CSVファイル、画像、動画など、構造化データ・非構造化データを問わず保存できるため、データ活用基盤における データレイク(Data Lake) として利用されることが多いサービスです。
企業の各システムやアプリケーションから収集したデータをまずObject Storageに蓄積することで、データの一元管理が可能になります。また、高い耐久性とスケーラビリティを備えているため、データ量が増加しても柔軟に対応できます。
データウェアハウス(分析基盤)|Autonomous Data Warehouse
分析用途のデータを蓄積する基盤として利用できるのが Oracle Autonomous Data Warehouse(ADW) です。Autonomous Data Warehouseは、チューニングやバックアップ、パッチ適用などの運用作業を自動化したクラウド型データウェアハウスです。
大量データに対して高速な分析クエリを実行できるため、BIツールやデータ分析の基盤として利用されます。データレイクや業務システムから収集したデータを統合し、分析しやすい形式で管理する役割を担います。
データ連携・加工(ETL/ELT)|OCI Data Integration
OCI Data Integration は、データの抽出・変換・格納を行う ETL/ELTツールです。GUIベースでデータパイプラインを設計できるため、専門的なプログラミングスキルがなくてもデータ処理フローを構築できます。
データベース、アプリケーション、ファイルストレージなどさまざまなデータソースからデータを取り込み、加工してデータレイクやデータウェアハウスへ連携します。データパイプラインの自動化により、手作業によるデータ処理の負担を大幅に削減できます。
リアルタイムデータ連携|OCI GoldenGate
業務システムのデータ更新をリアルタイムに分析基盤へ反映したい場合には OCI GoldenGate が利用されます。GoldenGateは、データベースの変更データ(CDC:Change Data Capture)を検知し、他のシステムへ転送する仕組みを提供します。
これにより、業務システムで更新されたデータをほぼリアルタイムでデータ基盤へ反映させることが可能になります。リアルタイム分析やデータ同期が必要なシステムで特に有効です。
データ分析・可視化|Oracle Analytics Cloud
蓄積されたデータを分析・可視化するためのBIツールとして Oracle Analytics Cloud(OAC) を利用できます。Oracle Analytics Cloudでは、ダッシュボードやレポートを作成し、データの傾向やパターンを視覚的に把握できます。
ドラッグ&ドロップ操作によるデータ分析が可能なため、専門的なデータ分析スキルがなくてもビジネスユーザーがデータ活用を進めやすい環境を構築できます。
データガバナンスとセキュリティ|Oracle Data Safe・OCI Audit
データ活用基盤の運用では、セキュリティやガバナンスの確保も重要です。OCIでは Oracle Data Safe や OCI Audit などのサービスを利用することで、データアクセスの監査、機密データの保護、操作ログの管理を行えます。
これにより、企業のセキュリティポリシーやコンプライアンス要件を満たしながら、安全にデータ基盤を運用することができます。
レイクハウスアーキテクチャ|Autonomous Database × Object Storage
近年のデータ基盤では、データレイクとデータウェアハウスを統合する レイクハウス(Lakehouse)アーキテクチャ が注目されています。OCIでは、OCI Object Storage と Autonomous Database を組み合わせることで、このレイクハウス構成を実現できます。
従来は、データレイクとデータウェアハウスを別々のシステムとして構築し、ETL処理によってデータを移動・加工する必要がありました。しかしレイクハウスでは、データレイクに保存された大量データをそのまま分析基盤から利用できるため、データパイプラインを簡素化できます。
OCIでは、Object Storageに保存されたデータを Autonomous Data Warehouse や Autonomous Transaction Processing から直接参照することができ、構造化データと非構造化データを統合的に分析できます。これにより、データの保存コストを抑えながら柔軟な分析基盤を構築することが可能です。
このようなレイクハウス構成は、データ分析だけでなく、AIや機械学習のデータ基盤としても活用されるケースが増えています。
AI・機械学習基盤|OCI Data Science
データ活用基盤では、蓄積されたデータをAIや機械学習に活用するケースも増えています。OCIでは OCI Data Science を利用することで、機械学習モデルの開発・学習・デプロイまでをクラウド上で実行できます。
OCI Data Scienceでは、Pythonベースのノートブック環境を利用してデータ分析やモデル開発を行うことができ、データレイクやデータウェアハウスに保存されたデータを直接利用できます。また、AutoML機能を利用することで、機械学習モデルの作成を効率化することも可能です。
このようにOCIでは、データ収集から分析・可視化までの一連のプロセスをクラウドサービスとして統合的に提供しており、企業は柔軟かつ拡張性の高いデータ活用基盤を構築できます。
株式会社パソナデータ&デザインの『AI Ready Platform on OCI 導入支援サービス』でデータ活用基盤構築を支援
AIを活用するためには、データを蓄積するだけでなく、収集・統合・分析までをスムーズに行えるデータ基盤が必要になります。
株式会社パソナデータ&デザインでは、Oracle Cloud Infrastructure(OCI)上に AI活用を前提としたデータ基盤を構築する「AI Ready Platform on OCI 導入支援サービス」を提供しています。
データレイク、データウェアハウス、データ連携、BIなどのOCIサービスを組み合わせ、AIやデータ分析に活用できる基盤の設計・構築を支援します。
導入にあたっては、まずお客様のデータ環境や課題を整理し、最適なアーキテクチャを設計します。その後、OCI上でデータ基盤を構築し、動作検証を行います。導入後も運用支援や改善提案を通じて、継続的なデータ活用をサポートします。
株式会社パソナデータ&デザインはOCIパートナーとしての知見を活かし、企業のAI活用を支えるデータ基盤の構築を支援しています。
データ活用基盤の導入をご検討の際は、ぜひお気軽にご相談ください。
AI Ready Platform on OCI導入支援サービスの詳細はこちら
まとめ|データ活用基盤はAI活用の土台になる
データ活用基盤は、企業が持つデータを収集・蓄積・加工・分析し、意思決定や業務改善に活用するための重要な基盤です。DXや生成AIの活用が進む現在、データを戦略的に活用できる企業ほど競争力を高めています。
本記事のポイントは以下の通りです。
- データ活用基盤は「収集・保存・加工・分析」の仕組みを支える基盤
- データレイクやデータウェアハウスを組み合わせた構成が一般的
- 業務効率化や意思決定の高速化などの効果が期待できる
- 成功には目的の明確化やデータガバナンス設計が重要
- 小さく始めて段階的に拡張するアプローチが有効
特に生成AIの活用においては、モデルの性能だけでなく データの品質や統合、管理体制が成果を大きく左右します。企業のデータを「AIが活用できる状態」に整えることが、AI活用の成功につながります。
データ活用基盤の構築は、単なるIT導入ではなく、企業全体でデータを活用するための基盤づくりです。まずは小さな取り組みから始め、段階的に拡張していくことで、無理なくAI Readyな環境を整えることができます。










