はじめに
本記事では、OCI Data Science サービスとベクトル型に対応した Oracle Database 23ai のマネージドサービスである Oracle Base Database Service 23ai (以下、BaseDB) を活用して RAG (Retrieval-Augmented Generation) 構成を設定・実装する手順について詳しく紹介していきます。RAG構成は、大規模言語モデル(LLM)によるテキスト生成に、外部情報(ベクトル型データベース)の検索を組み合わせることで、従来のLLM(ChatGPTなど)によくある事実に基づかない情報を生成する現象(ハルシネーション)を引き起こす可能性を大幅に下げ、回答精度を向上させる技術のことです。近年は、生成AIを用いた企業内データの活用方法としても注目されています。
なお、本記事は、筆者が実際に試行錯誤した結果を元に執筆しており、初心者でも手軽にRAG構成を体験できるように執筆いたしました。手順に従って、手を動かしてRAG構成を体験して頂けると幸いです。また、本記事は2部構成のうちの前編となります。
参考:RAG構成とは
関連記事:OCI Data ScienceとOracle Database 23aiで体験するお手軽なRAG構成について(後編)
OCI Data Science サービスとは
OCI Data Scienceサービスでは、Pythonとオープン・ソース・ツールを使用して、機械学習(ML)モデルを構築、トレーニング、導入、管理することができます。また、JupyterLabベースの環境を使用して、モデルを実験および開発することができます。今回は、機械学習を実施するわけではありませんが、LangChainを構築するPython環境としてOCI Data Scienceサービスを活用します。
構成図
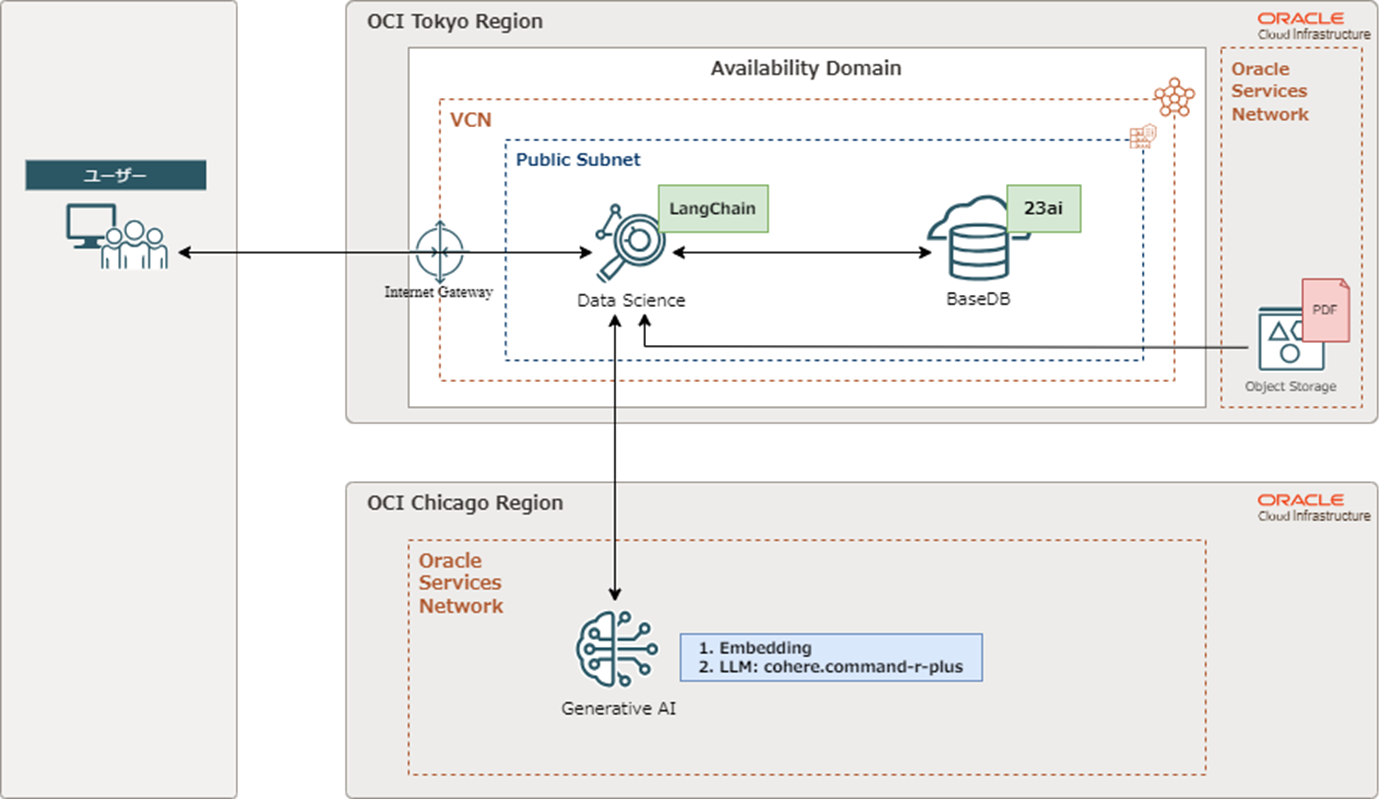
2024年9月時点で、OCI Generative AIサービスを利用できるのは、サンパウロ、フランクフルト、ロンドン、シカゴリージョンのみとなっています。そのため、本記事ではOCI Generative AIサービスを利用するためにシカゴリージョンと東京リージョンを連携することでRAG構成を実現しています。
参考:生成AIを使用できるリージョン
前提条件
本記事で紹介する手順の前提条件は以下となります。
- VCNを「インターネット接続性を持つVCNの作成」ウィザードで作成済みであること
- OCIのユーザ資格情報を取得できる権限をもっていること
- 東京リージョンとシカゴリージョンがサブスクライブされていること
- OCI Data Scienceを作成するにあたる前提条件(ポリシーなど)を満たしていること
参考:OCI Data Science のポリシーの作成
大まかな実施手順
本記事では、大まかに次のステップでRAG構成を実装していきます。なお、ステップ1に関しては、前提条件とさせていただきます。
- OCIの準備:VCNの作成やリージョンのサブスクライブ、各種ポリシーに作成を行います。
- BaseDBの設定:ベクトルデータ型に対応している Oracle Base Database Service 23ai (BaseDB)を作成し、必要なユーザーと権限を設定します。
- オブジェクト・ストレージの利用:RAG構成で使用するデータ(PDFファイル)をオブジェクト・ストレージにアップロードし、事前認証済みリクエストを設定します。
- OCI Data Scienceプロジェクトの構築:OCI Data Science 内でプロジェクトを作成し、ノートブックセッションを開始します。
- Conda環境と接続情報等の設定:今回の検証で必要になるライブラリなどをインストールし、作業環境を整えます。
- RAG構成の実装:PDFファイルのテキストをロードし、適切なベクトルに変換してデータベースにロードします。その後、プロンプトテンプレートを作成し、モデルを利用して問い合わせを実施します。
- 非RAG構成の実装:非RAG構成でも問い合わせを実施し、RAG構成との回答の精度を比較します。
では、これからそれぞれの手順を詳しく紹介していきます。なお、「4. OCI Data Scienceプロジェクトの構築」までを本記事で扱い、「5. Conda環境と接続情報等の設定」以降は後編の記事で扱います。また、本記事で利用するPDFファイルやコードに関しては、GitHubからダウンロードすることが出来ます。
関連記事:OCI Data ScienceとOracle Database 23aiで体験するお手軽なRAG構成について(後編)
参考:本記事で利用するPDFファイルおよびコード(GitHub)
BaseDB 23ai に関する作業
ここでは、ベクトルデータ型に対応しているOracle Database 23ai を Oracle Base Database Service 23ai (以下、BaseDB) で作成していきます。また、今回使用するデータベースユーザを追加し、権限を与えていきます。
BaseDBの作成
まずは、手順に従いBaseDBを作成していきます。
-
ハンバーガーメニューをクリックし、「Oracle Database」>「Oracleベース・データベース・サービス」をクリックします。
-
「DBシステムの作成」をクリックし、「DBシステムの作成」ページで、以下の情報を参考にBaseDBを作成します。
-
コンパートメント:任意のコンパートメント
-
DBシステムの名前:任意の名前(本記事では「RAG23ai」)
-
可用性ドメインの選択 : AD1(東京リージョンでの作成を想定)
-
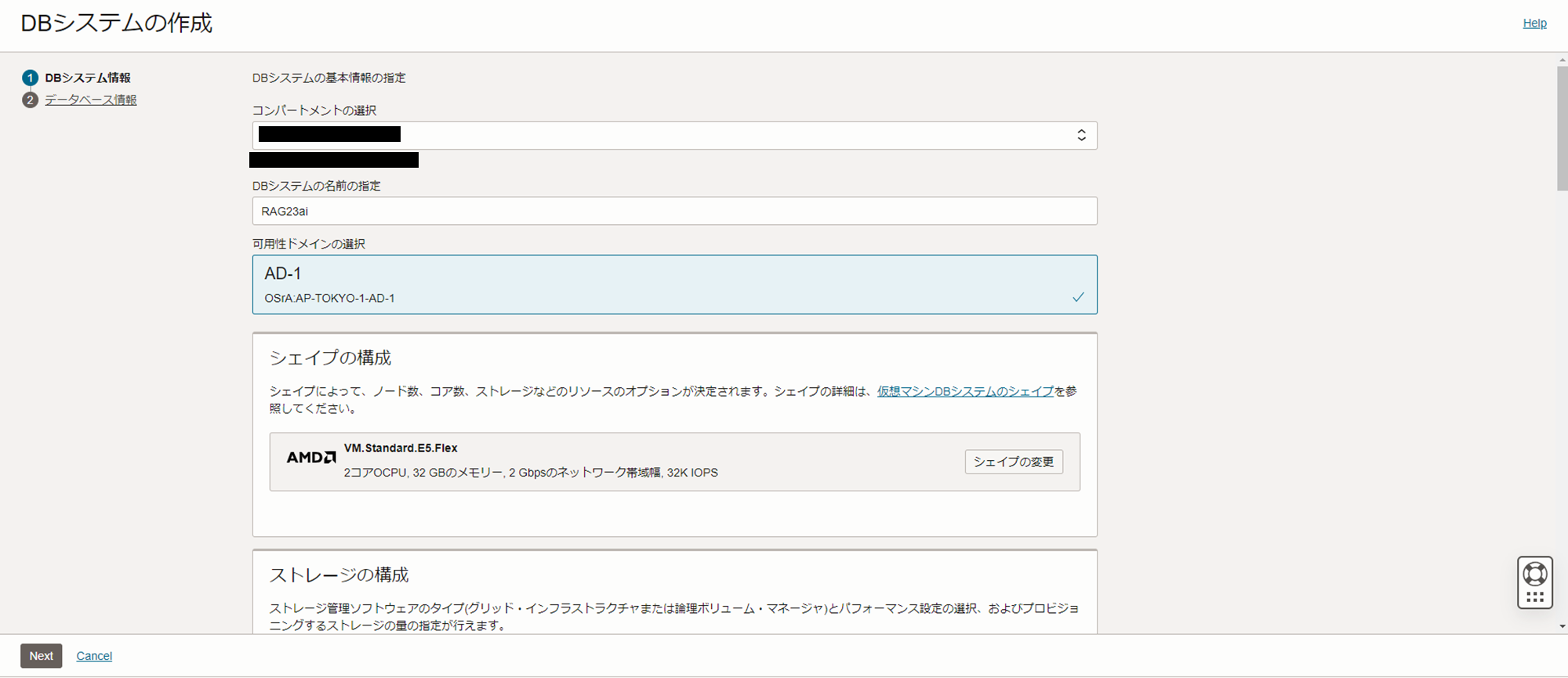
シェイプの構成
- シェイプシリーズ : AMD
- OCPUの構成:VM.Standard.E5.Flex
- OCPU数:2OCPU
-
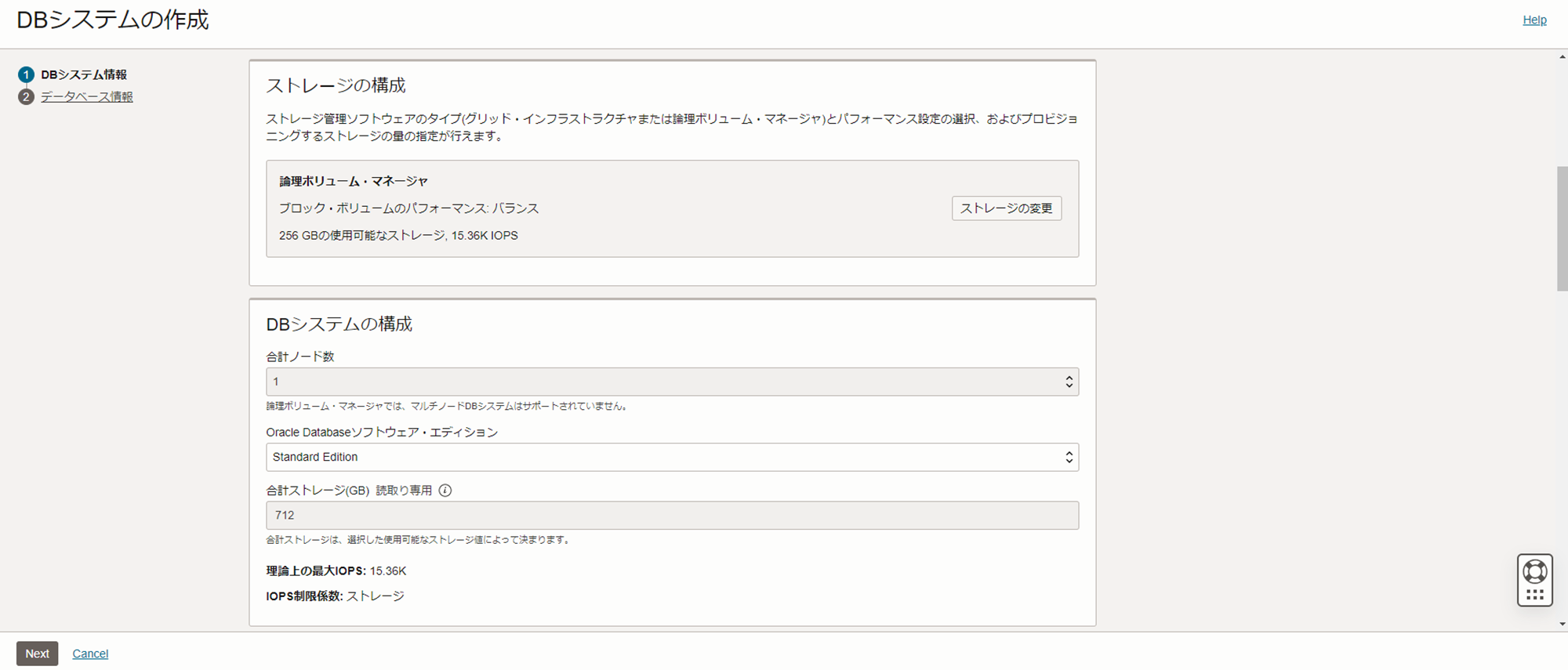
ストレージの構成
- ストレージ管理ソフトウェアの選択 :論理ボリュームマネージャー
- ストレージボリュームのパフォーマンス : バランス
- データ・ストレージ : 256GB
-
DBシステムの構成
- Oracle Databaseソフトウェアエディション : Standard Edition
- Oracle Databaseソフトウェアエディション : Standard Edition
-
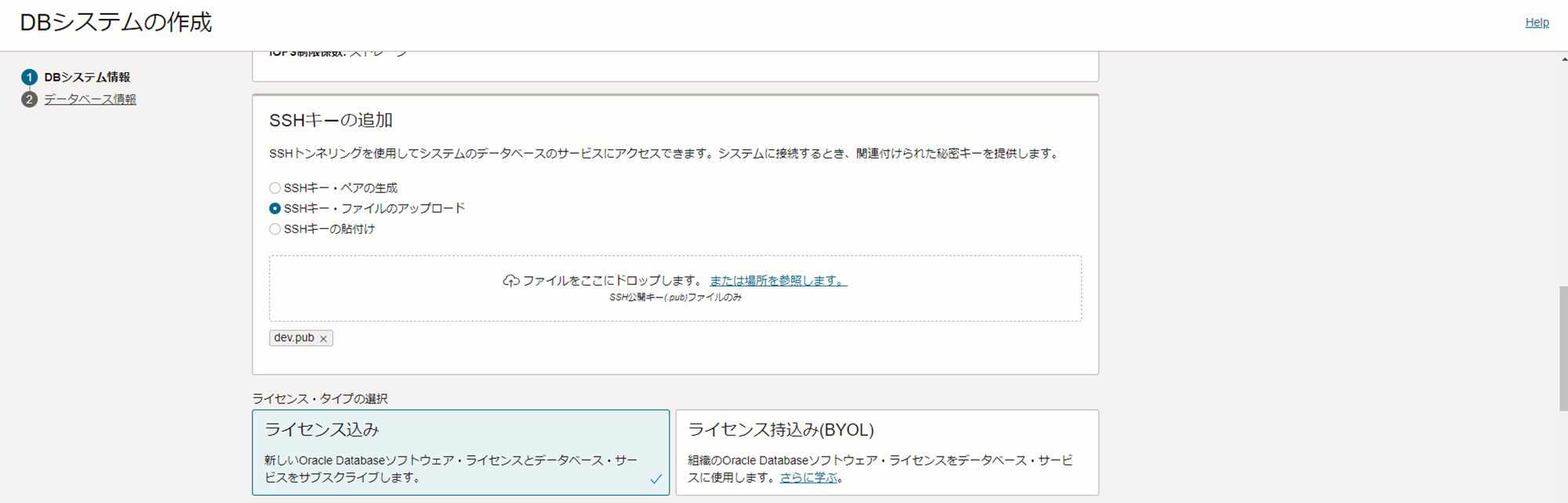
SSHキーの追加 : SSHキーをダウンロードもしくはアップロード(本記事ではアップロード)
-
ライセンスタイプ : ライセンス込み
-
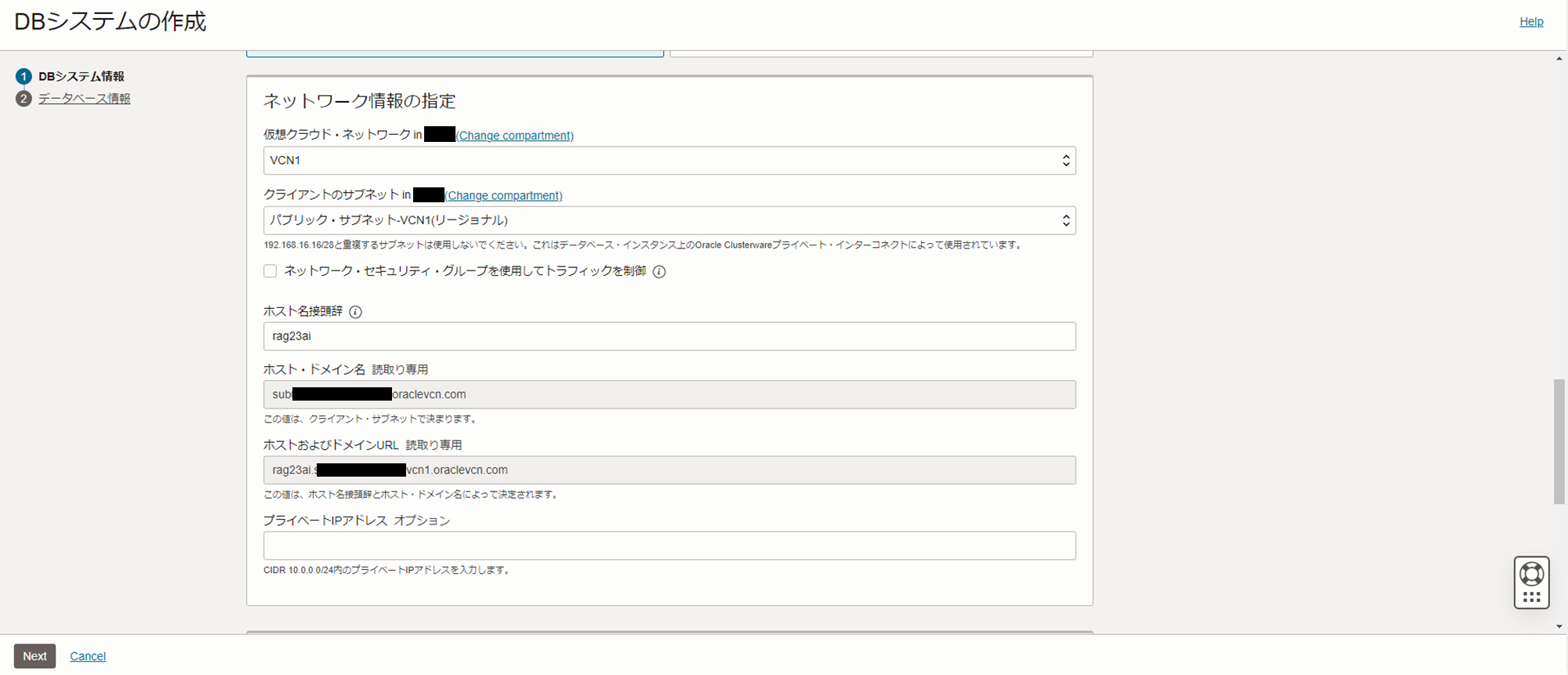
ネットワーク情報
- VCN : 作成済みのVCNを指定
- サブネット : 作成済みのパブリックサブネットを指定
- ホスト名接頭辞 : rag23ai
- プライベートIPアドレス オプション : 指定なし(デフォルト)
-
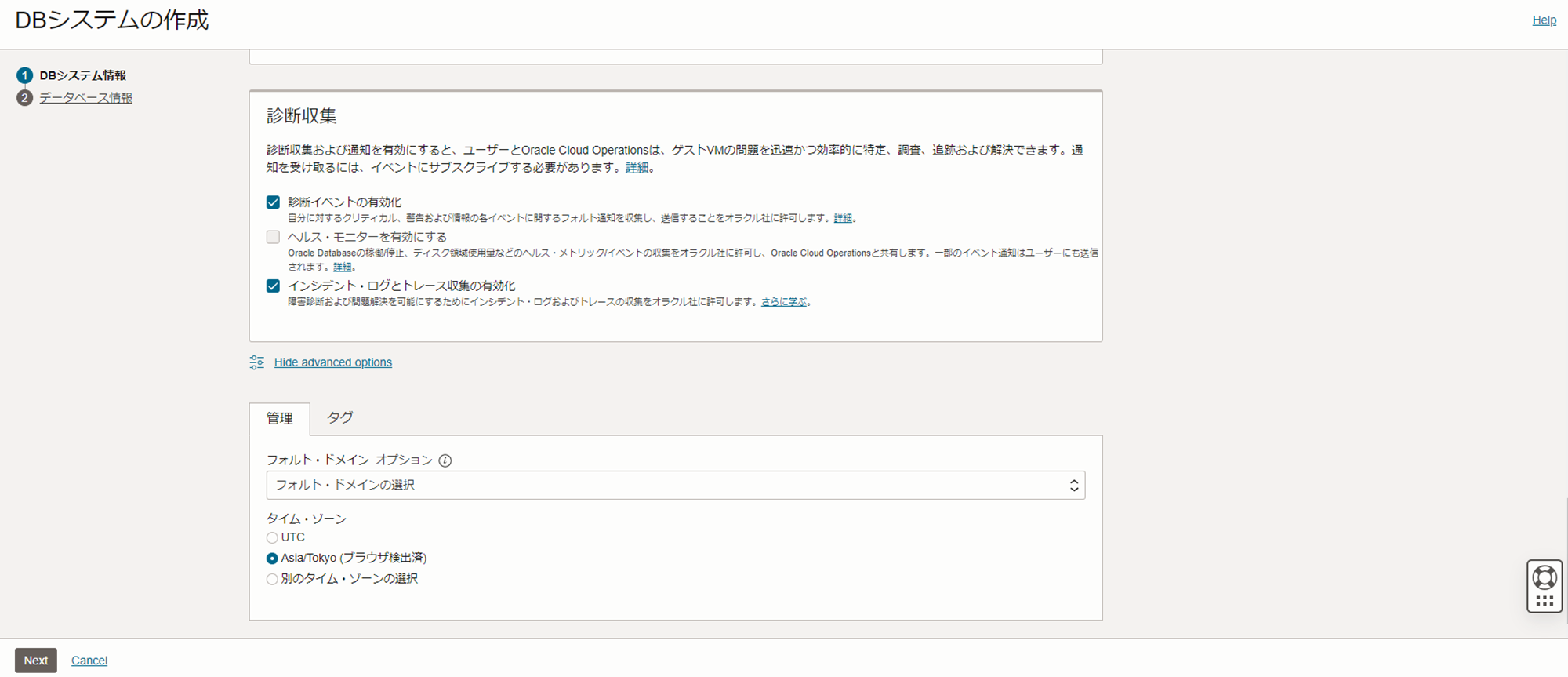
診断収集
- 診断イベントの有効化 : 有効
- ヘルス・モニターを有効にする : 無効(選択不可)
- インシデント・ログとトレース収集の有効化 : 有効
-
拡張オプション
- 管理
- フォルトドメインオプション : 指定なし(デフォルト)
- タイムゾーン : Asia/Tokyo(ブラウザ検出済)
- 管理
-
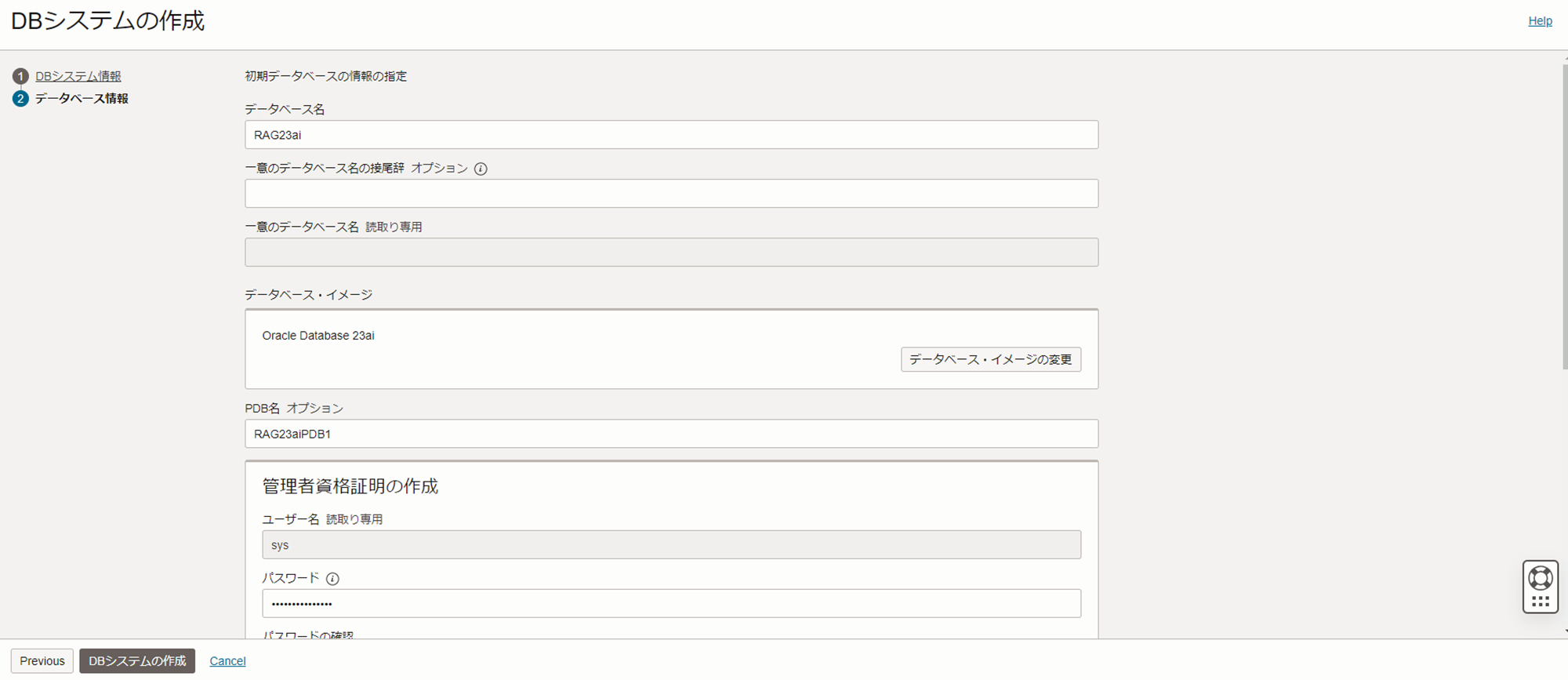
データベース名:任意の名前(本記事では「RAG23ai」)
-
データベース・イメージ : Oracle Database 23ai
-
PDB名 : 任意の名前(本記事では「RAG23aiPDB1」)
-
管理者資格証明の作成
- ユーザー名:sys(変更不可)
- パスワード:任意のパスワード(本記事では「WelCome123#123#」)
- 管理者パスワードをTDEウォレットに使用:チェックオン(有効化)
-
データベース・バックアップの構成
- 自動バックアップの有効化:チェックアウト(無効化)
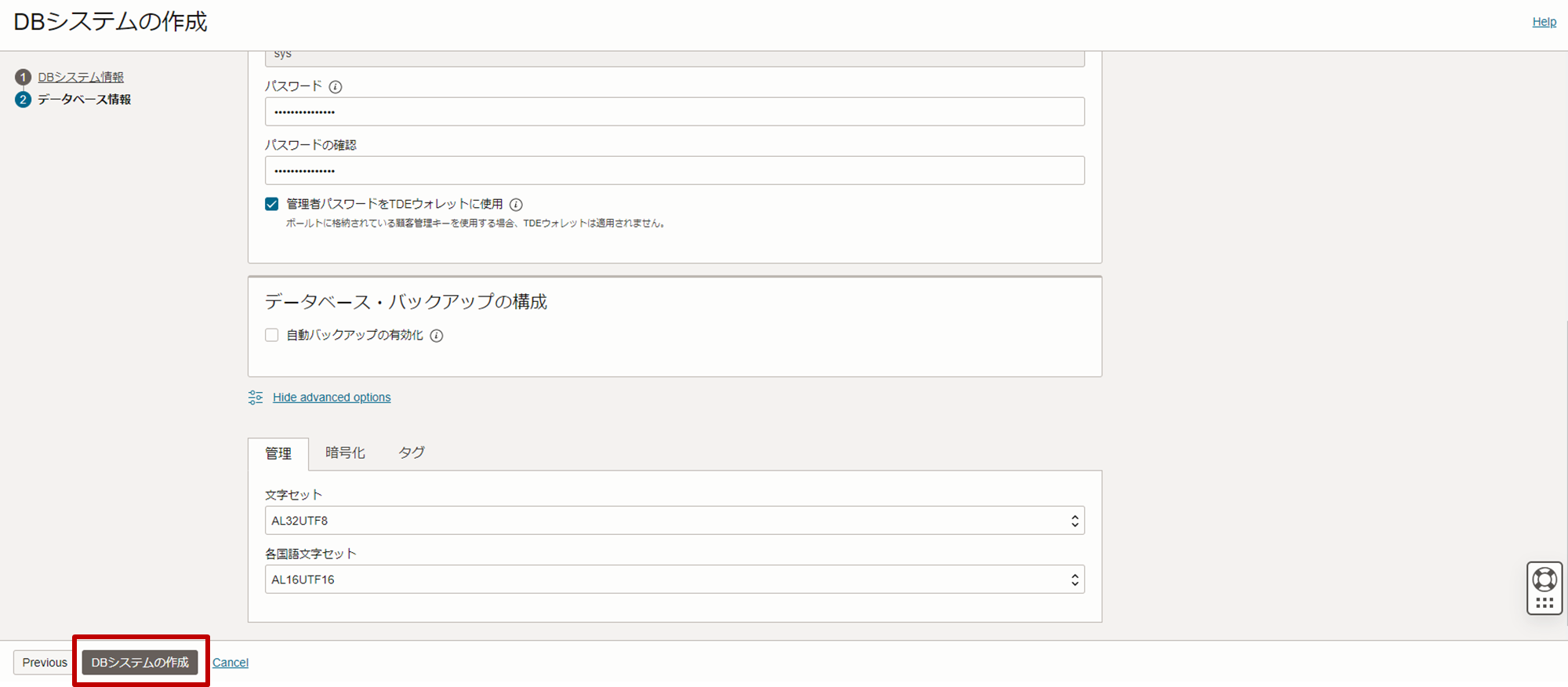
- 自動バックアップの有効化:チェックアウト(無効化)
-
-
DBシステムを作成してから20-30分ほどで「ACTIVE」状態となります。
対象のPDBへの接続
次に、作成したPDBにCloud Shellを用いて接続するために、各種情報を確認します。
-
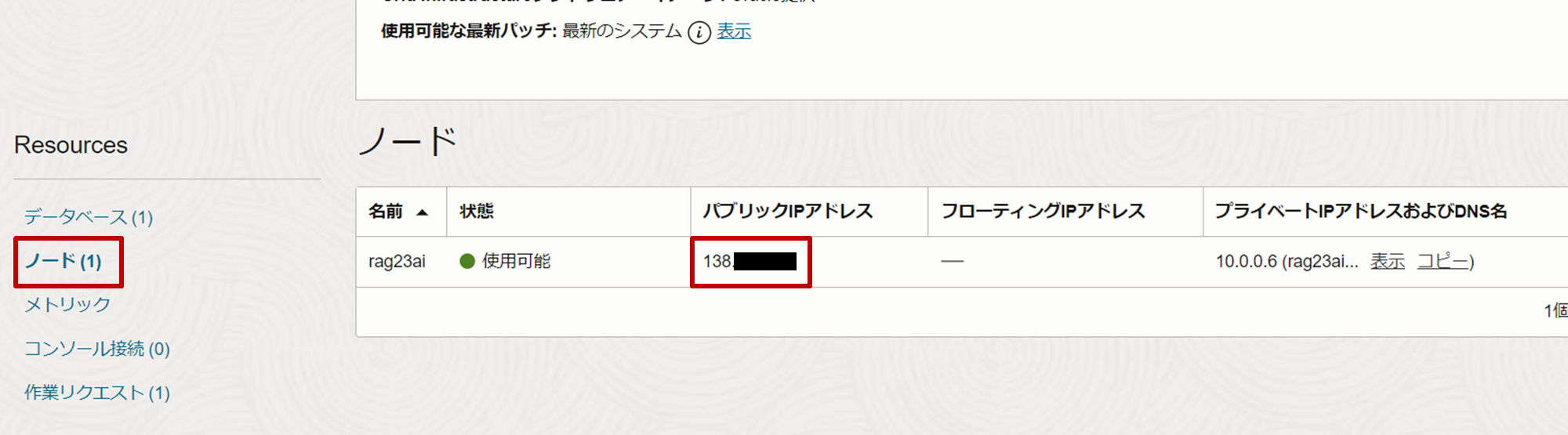
BaseDBの詳細画面の左下にあるResourcesペインから「ノード」をクリックし、パブリックIPアドレスを確認します。
-
右上にある「開発者ツール」から「Cloud Shell」をクリックして、起動させます。
-
秘密鍵をCloud Shellにアップロードするため、右にある「Cloud Shell」のメニューをクリックし、「アップロード」を選択し、秘密鍵をアップロードします。
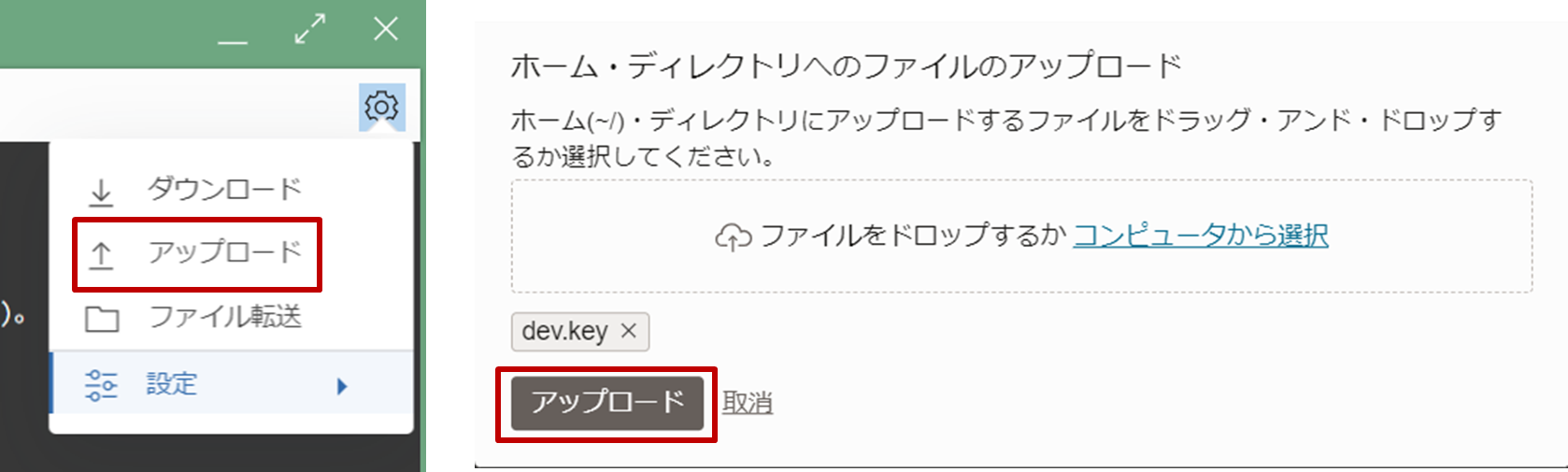
-
アップロードした秘密鍵の権限を与えるため、以下のコマンドを実行します。
12$ ls$ chmod 400 <アップロードした秘密鍵>.key -
先程確認したBaseDBのパブリックIPアドレスを用いて、以下の通りにBaseDBへSSH接続します。
1$ ssh -i <秘密鍵>.key opc@<BaseDBのパブリックIPアドレス>※確認が出てきたら「yes」と入力してください
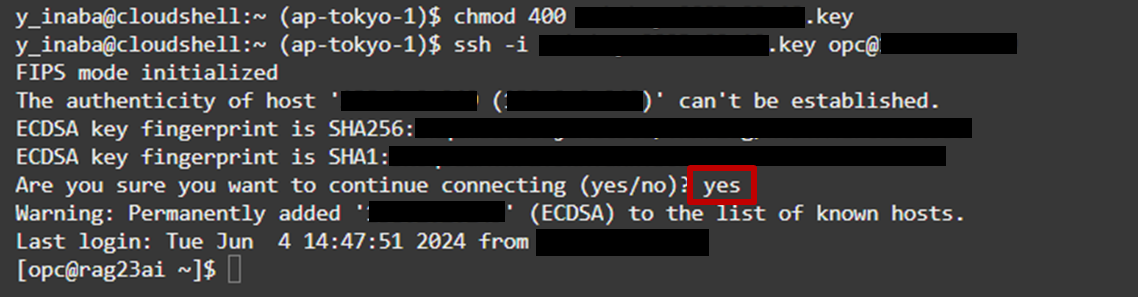
-
PDBへの接続文字列を取得するために、コンソール画面に移動し、左下にあるResourcesペインから「データベース」から対象のBaseDB(本記事では「RAG23ai」)をクリックします。
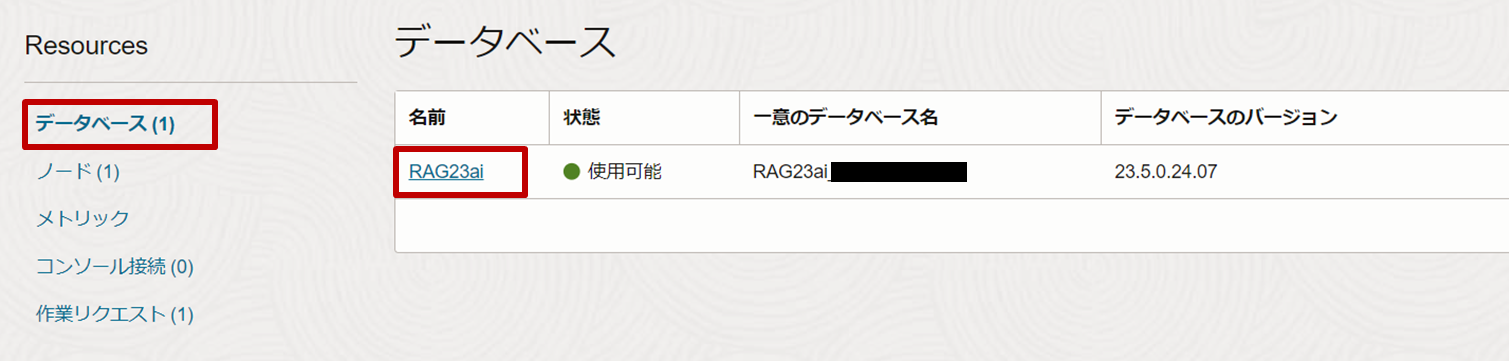
-
BaseDBの詳細画面から、左下にあるResourcesペインから「プラガブル・データベース」を選択し、対象のPDB(本記事では「RAG23aiPDB1」)をクリックします。
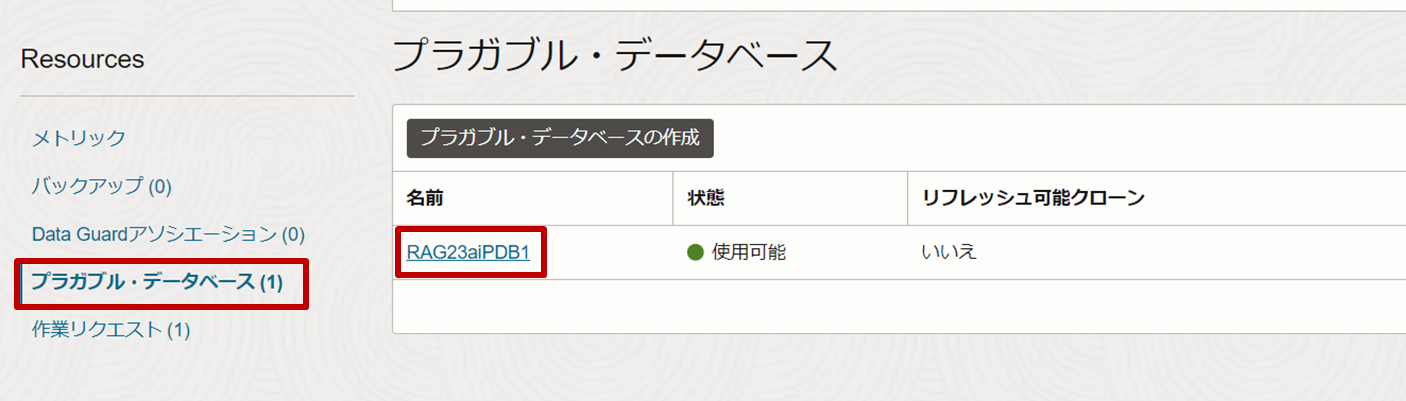
-
「PDB接続」ボタンをクリックし、簡易接続に関する接続文字列をコピーします。
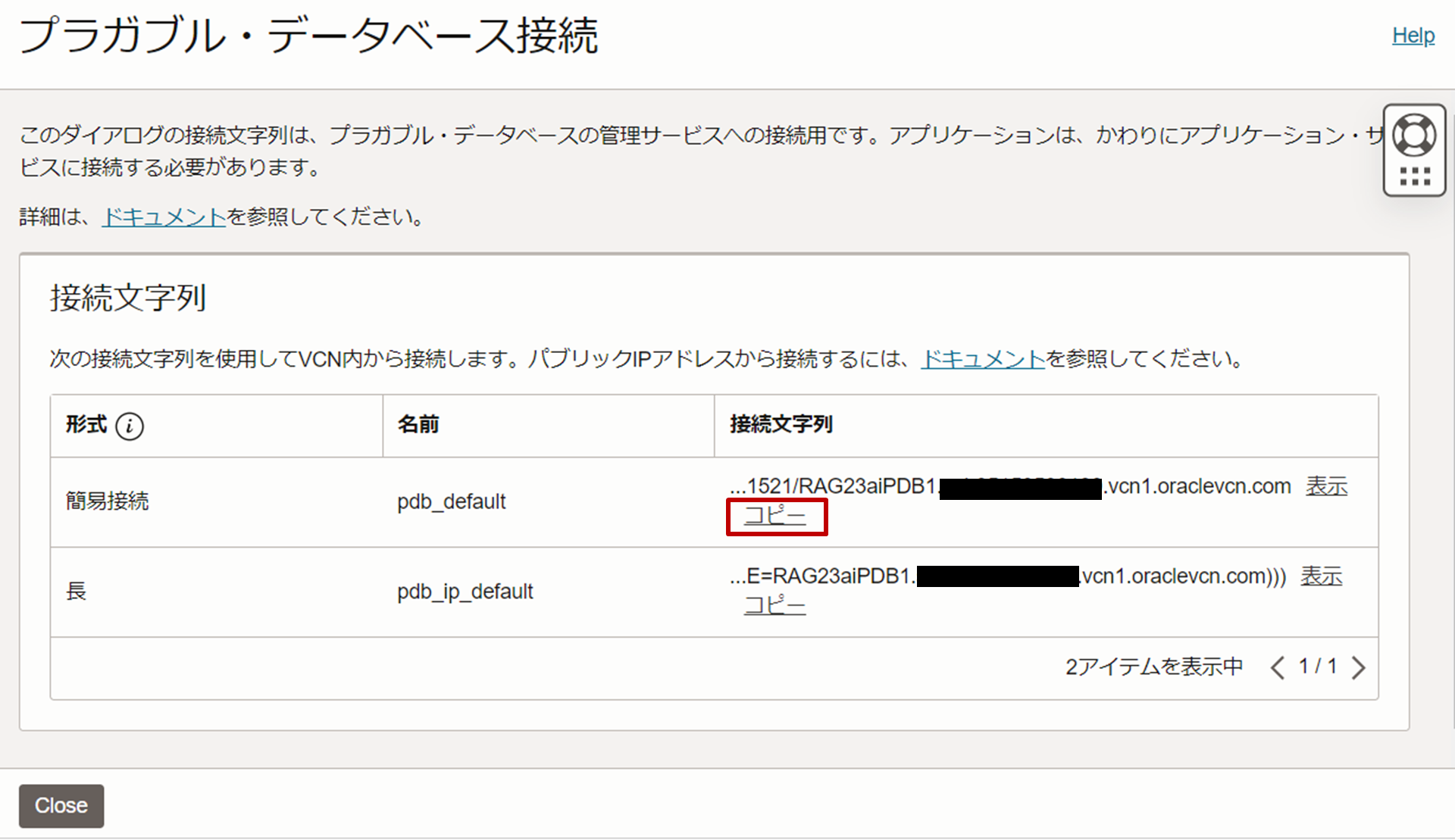
-
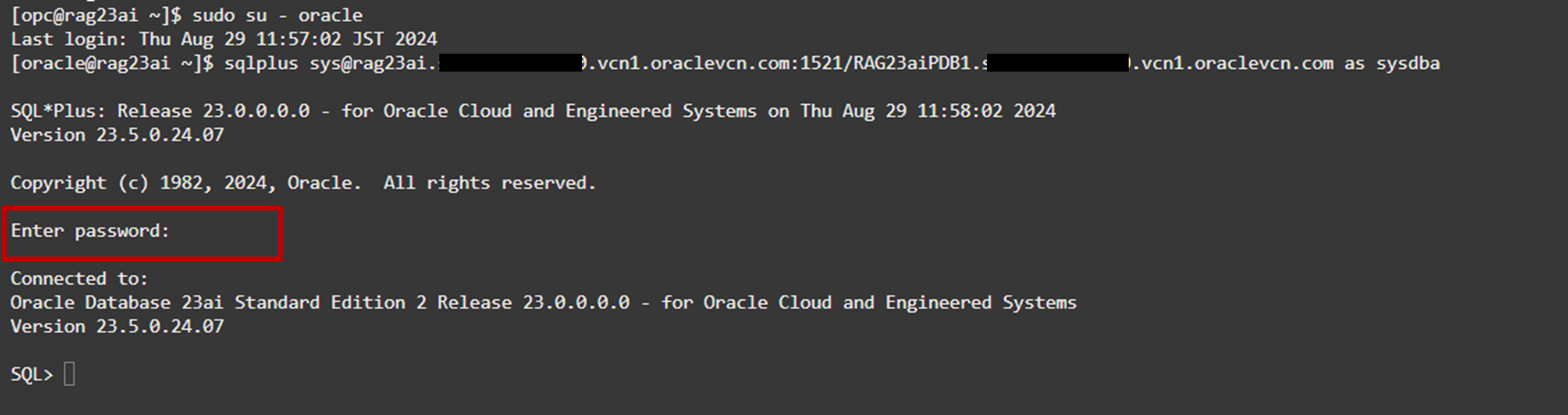
再びCloud Shellに戻り、ユーザを変更して、SQL*Plusで接続文字列利用してPDBへ接続します。
12[opc@rag23ai ~]$ sudo su - oracle[oracle@rag23ai ~]$ sqlplus sys@<接続文字列> as sysdba※sysユーザのパスワードが求められるため、BaseDB作成時に指定したパスワードを入力します
ユーザの追加と権限の追加
PDBに接続することが出来たので、最後に今回使用するユーザーと権限を設定します。
- 今回使用するdocuserユーザを作成し、権限を付与し、SQLプロシージャを実行します。
1234567891011121314SQL> grant connect, ctxapp, unlimited tablespace, create credential, create procedure, create table to docuser identified by WelCome123#123#;SQL> grant execute on sys.dmutil_lib to docuser;SQL> grant create mining model to docuser;SQL> BEGINDBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(host => '*',ace => xs$ace_type(privilege_list => xs$name_list('connect'),principal_name => 'docuser',principal_type => xs_acl.ptype_db));END;/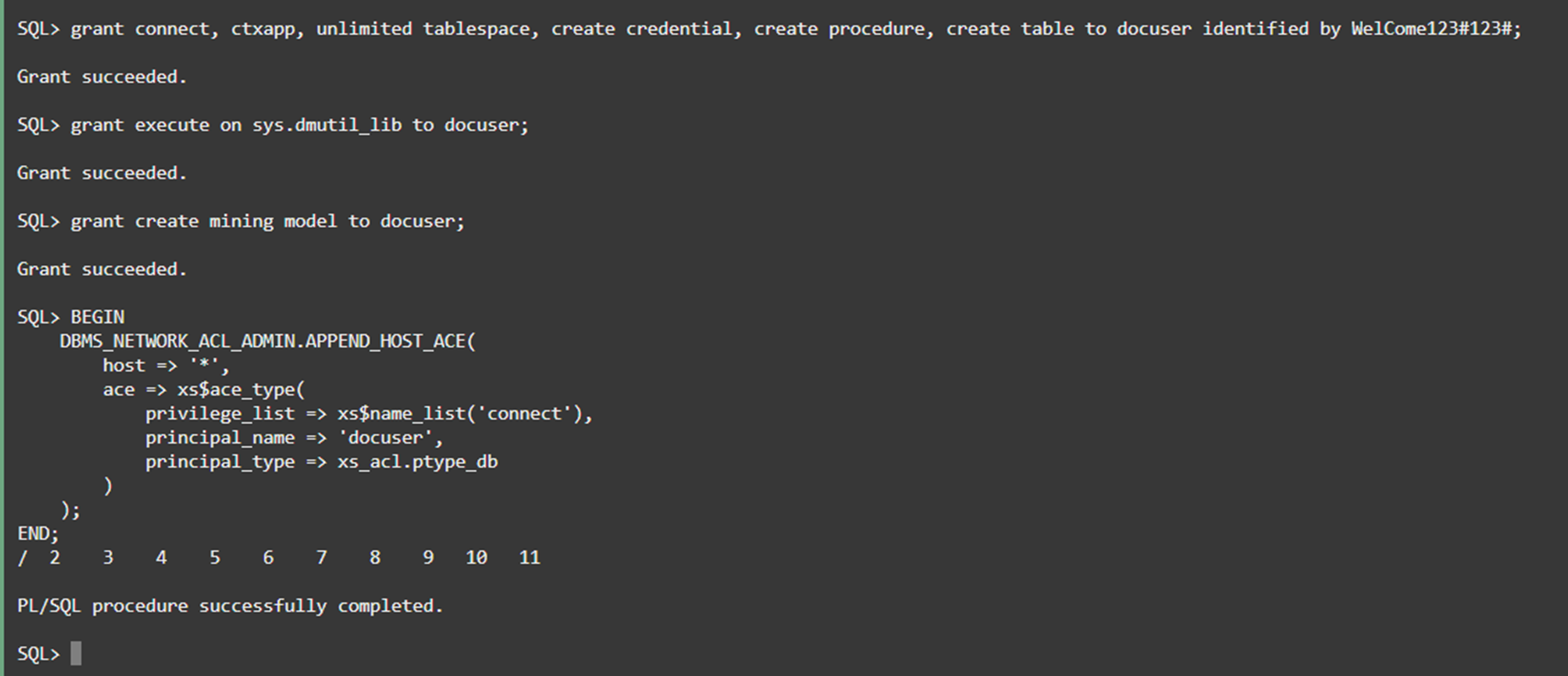
オブジェクト・ストレージでの設定
ここでは、BaseDBで利用する外部情報としてPDFファイルをオブジェクト・ストレージにアップロードし、事前認証済リクエストを作成します。
バケットの作成
まずは、オブジェクト・ストレージのバケットを作成します。
-
ハンバーガーメニューをクリックし、「ストレージ」>「オブジェクト・ストレージ & アーカイブ・ストレージ」>「バケット」をクリックします。
-
左側にあるResourcesペインで、コンパートメントが適切か確認します。
-
「バケットの作成」をクリックします。「バケットの作成」ダイアログ・ボックスが表示されます。
-
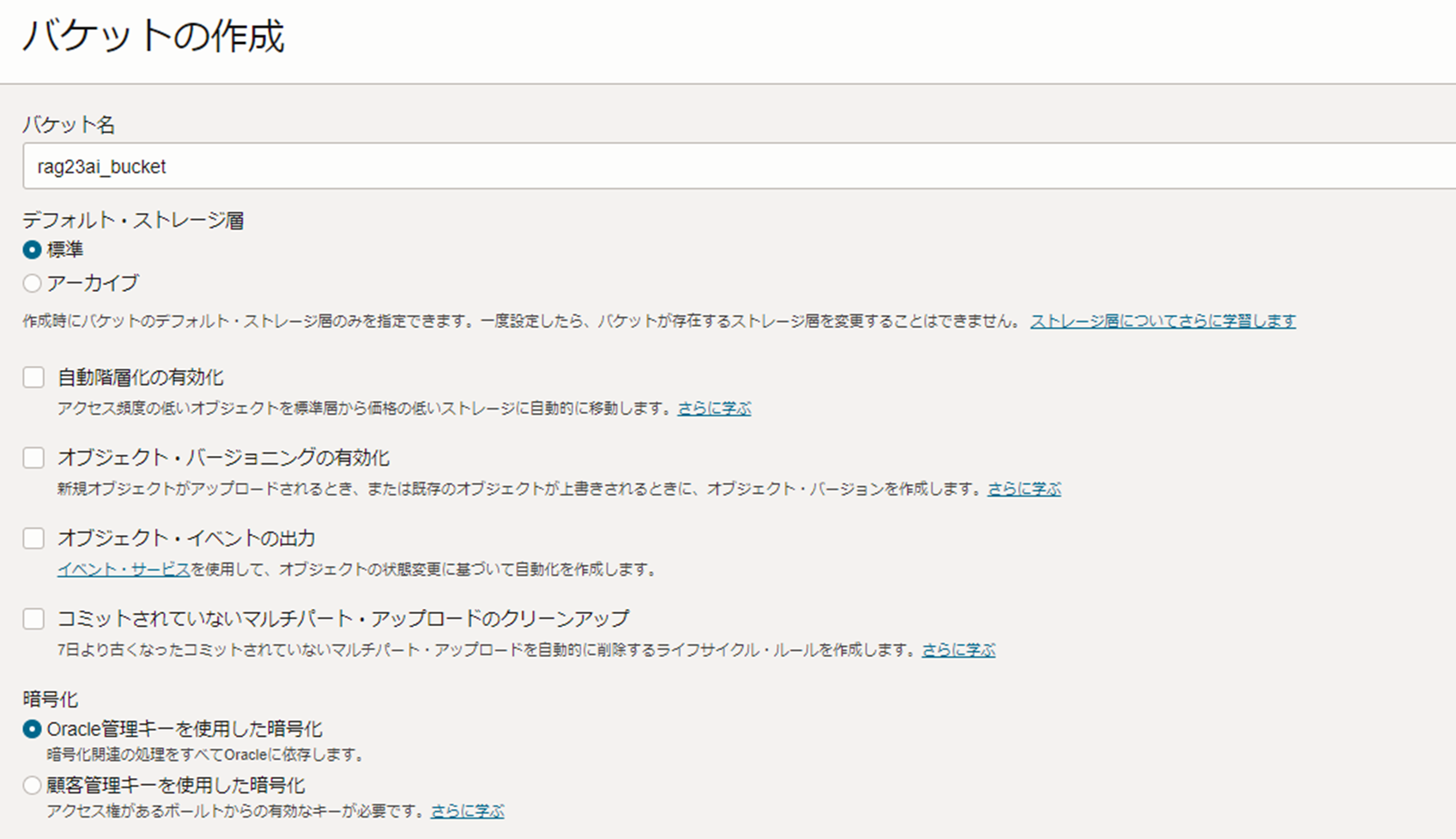
以下の情報に従い、作成するバケットを指定します。
- バケット名:rag23ai_bucket
- デフォルト・ストレージ: 標準
- 自動階層化の有効化:チェックアウト
- オブジェクト・イベントの出力:チェックアウト
- コミットされていないマルチパート・アップロードのクリーンアップ:チェックアウト
- 暗号化:Oracle管理キーを使用した暗号化
-
「作成」をクリックし、バケットを作成します。
PDFファイルのアップロード
今回利用するPDFファイルをオブジェクト・ストレージにアップロードします。
なお、本記事で利用するPDFファイルは弊社スマートスタイルの社長メッセージとなります。
PDFファイルは、GitHubにて公開しています。必要に応じて、ダウンロードしてください。
参考:社長メッセージ
参考:GitHub(社長メッセージPDF)
- 作成したバケットを選択し、バケットの詳細画面に移動します。
- 左側にあるResourcesペインの中にある「オブジェクト」をクリックします。「オブジェクト」リストが表示されます。
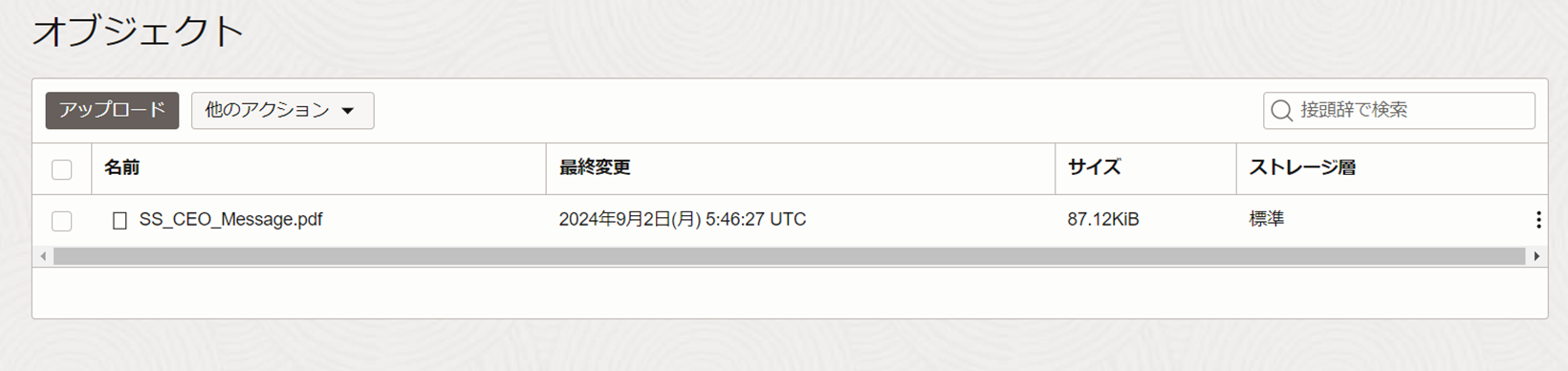
- 「アップロード」をクリックします。ストレージ層が「標準」になっていることを確認し、対象のPDFファイルをアップロードします。
事前認証済リクエストの作成
アップロードしたオブジェクトをData Scienceのノートブックセッションでダウンロードできるように、事前認証済リクエストを作成します。
-
アップロードしたオブジェクトの右端にある「
 」をクリックします。
」をクリックします。 -
表示されたリストの中から「事前認証済リクエストの作成」をクリックします。
-
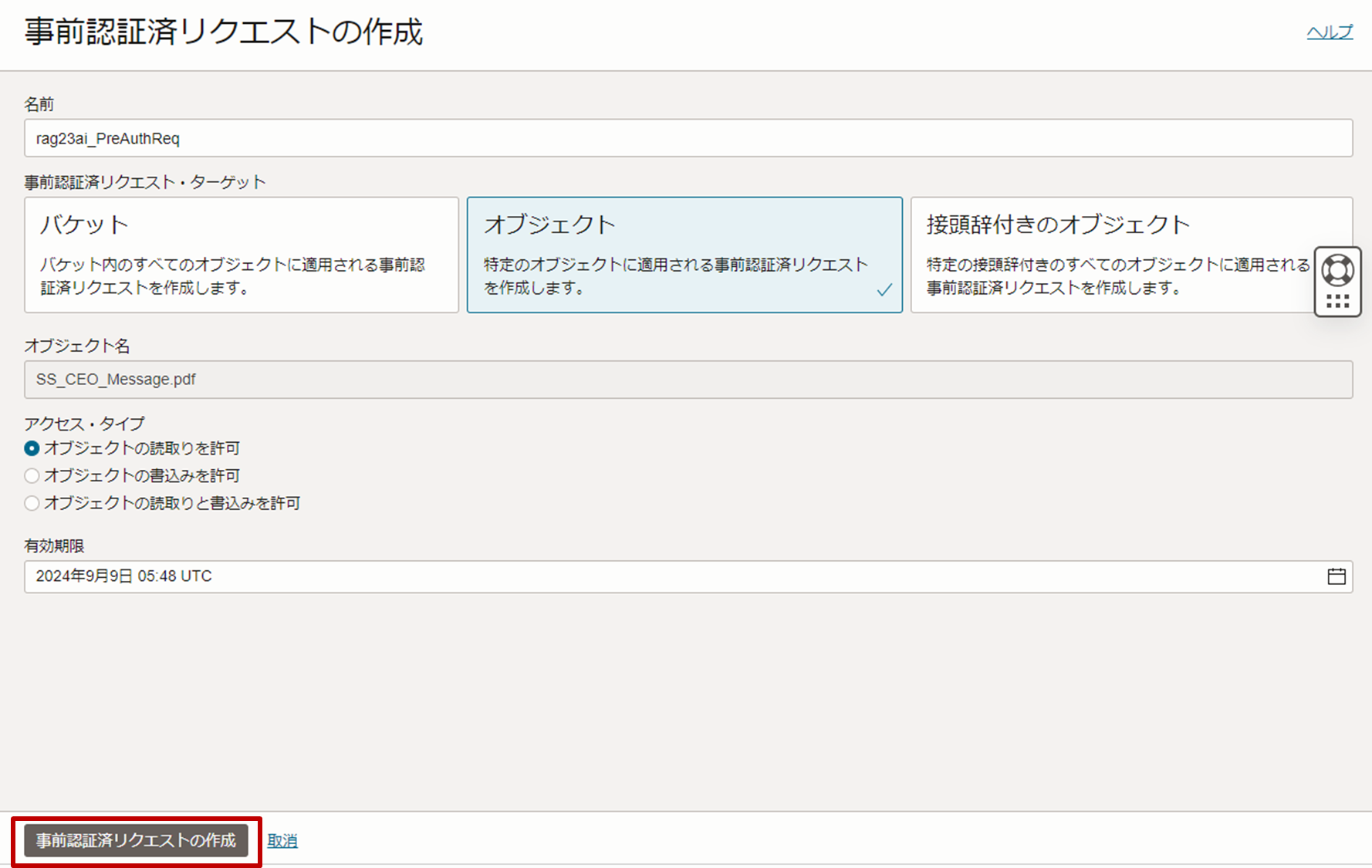
以下の情報に従い、作成する事前認証済リクエストを指定します。
- 名前:rag23ai_PreAuthReq
- 事前認証済リクエスト・ターゲット: オブジェクト
- オブジェクト名:デフォルト
- アクセス・タイプ:オブジェクトの読取りを許可
- 有効期限:デフォルト
-
内容を確認し、「事前認証済リクエストの作成」をクリックします。
-
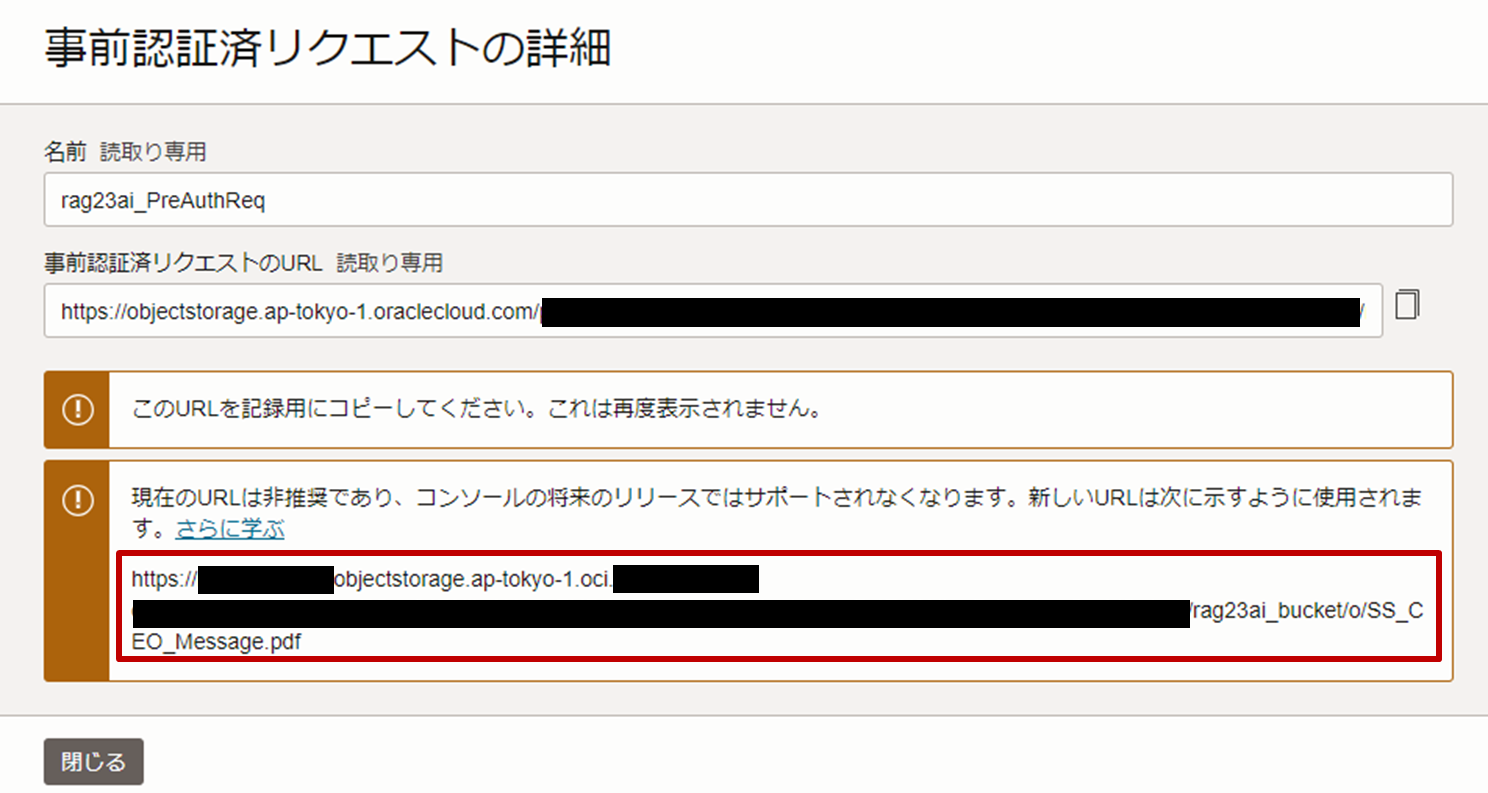
「事前認証済リクエストの詳細」ダイアログ・ボックスが表示され、オブジェクトへのアクセスに使用されるURLが表示されます。表示されるURLをコピーし、メモ帳などで管理します。
なお、バケットにアクセスするために2パターンのURLが表示されます。よりセキュアにアクセスするため、下部に表示されているURLをコピーしてください。
参考:オブジェクト・ストレージの専用エンドポイント
OCI Data Science の準備
ここでは、LangChainを利用したRAG構成を実装する前に、環境の準備をしておきます。
プロジェクトの作成
まずは、OCI Data Science のプロジェクトを作成してきます。
- ハンバーガーメニューをクリックし、「アナリティクスとAI」>「機械学習」>「データ・サイエンス」をクリックします。
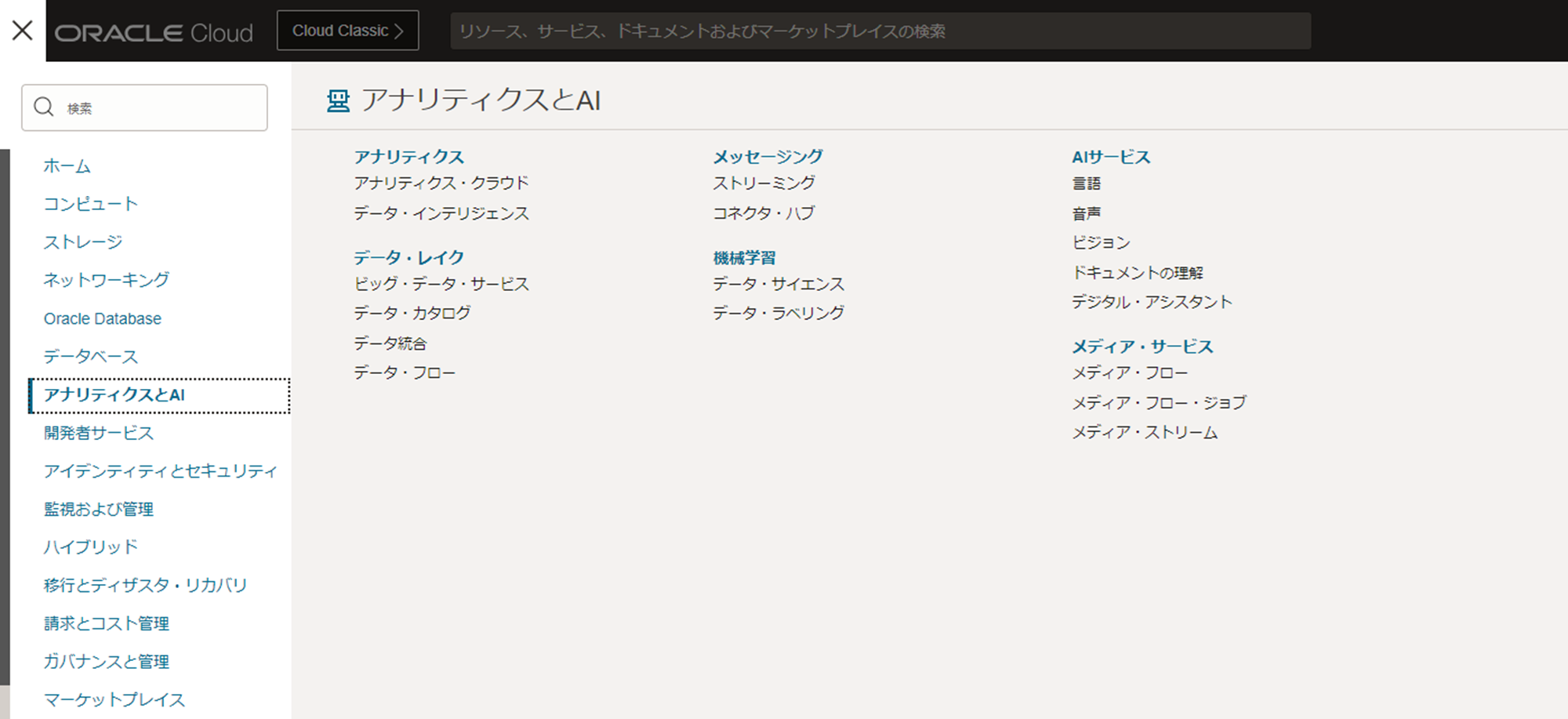
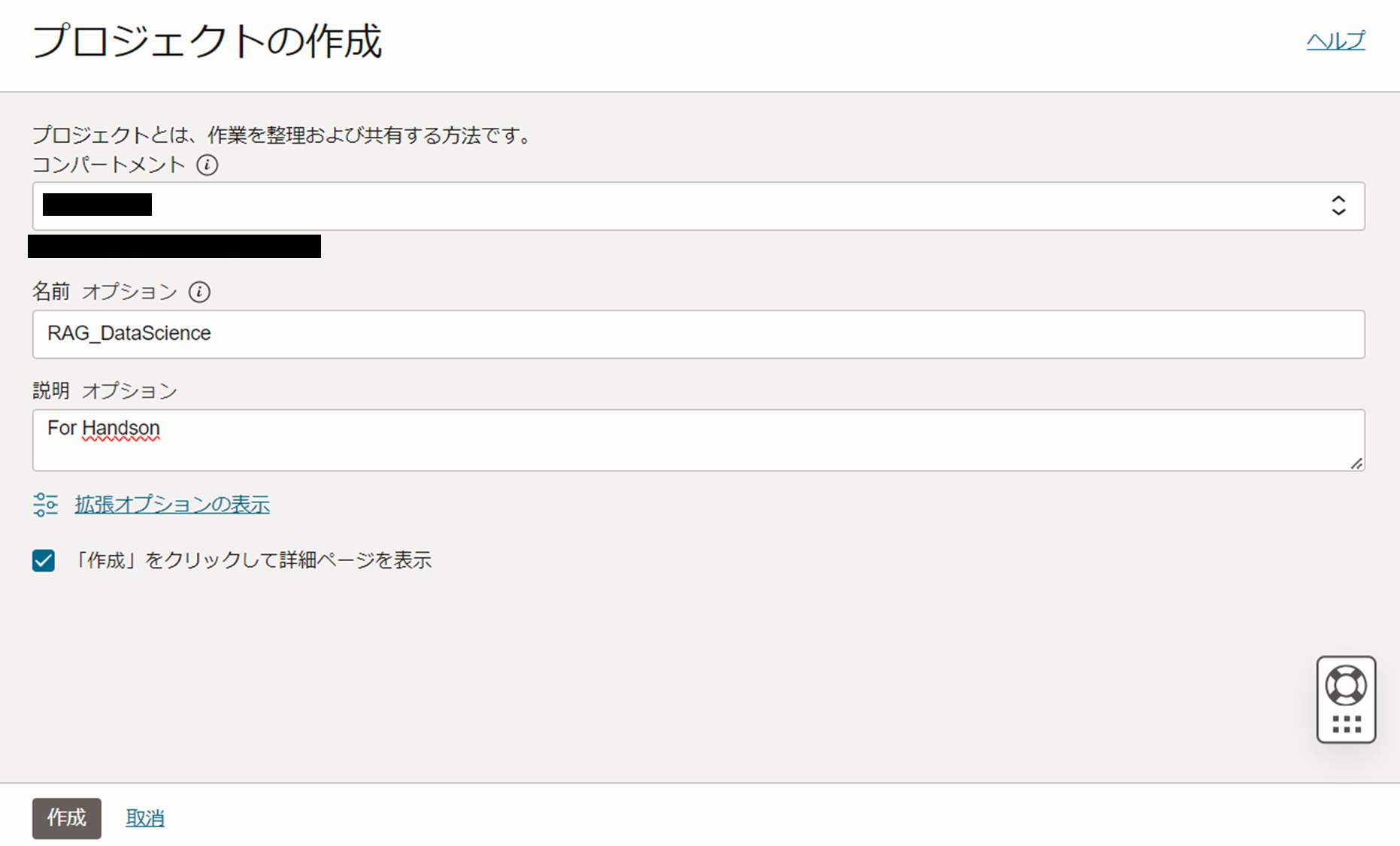
- プロジェクトの作成をクリックし、今回作成したいコンパートメントを選択し、以下の情報を参考にプロジェクトを作成します。
- 名前:任意の名前(本記事では「RAG_DataScience」)
- 説明:任意の説明(本記事では「For Handson」)
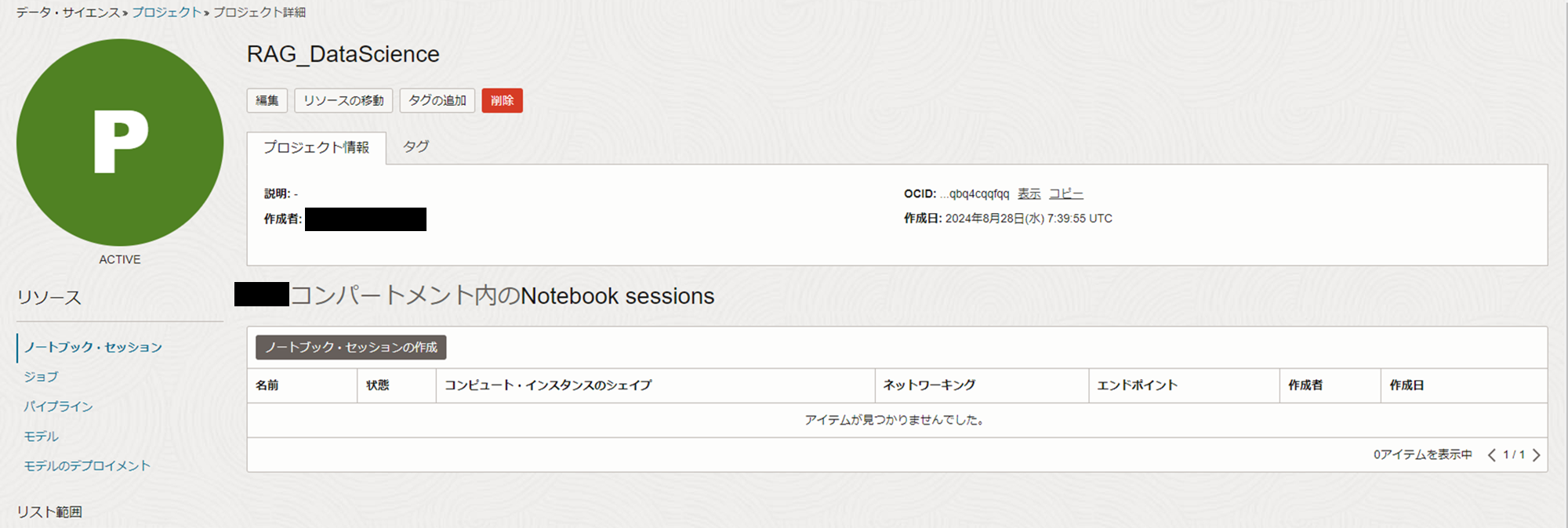
- しばらくすると、プロジェクトがACTIVEに変化します。
ノートブック・セッションの作成とセッションへのログイン
次に作成したプロジェクトにノートブック・セッションを作成し、セッションへログインしていきます。
-
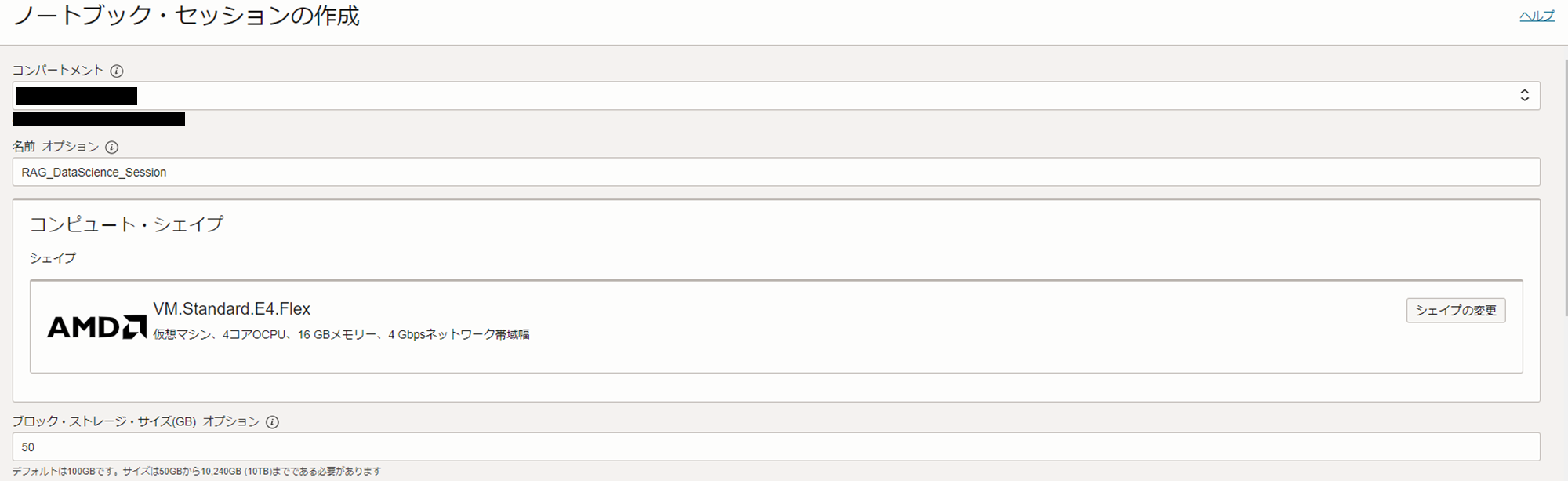
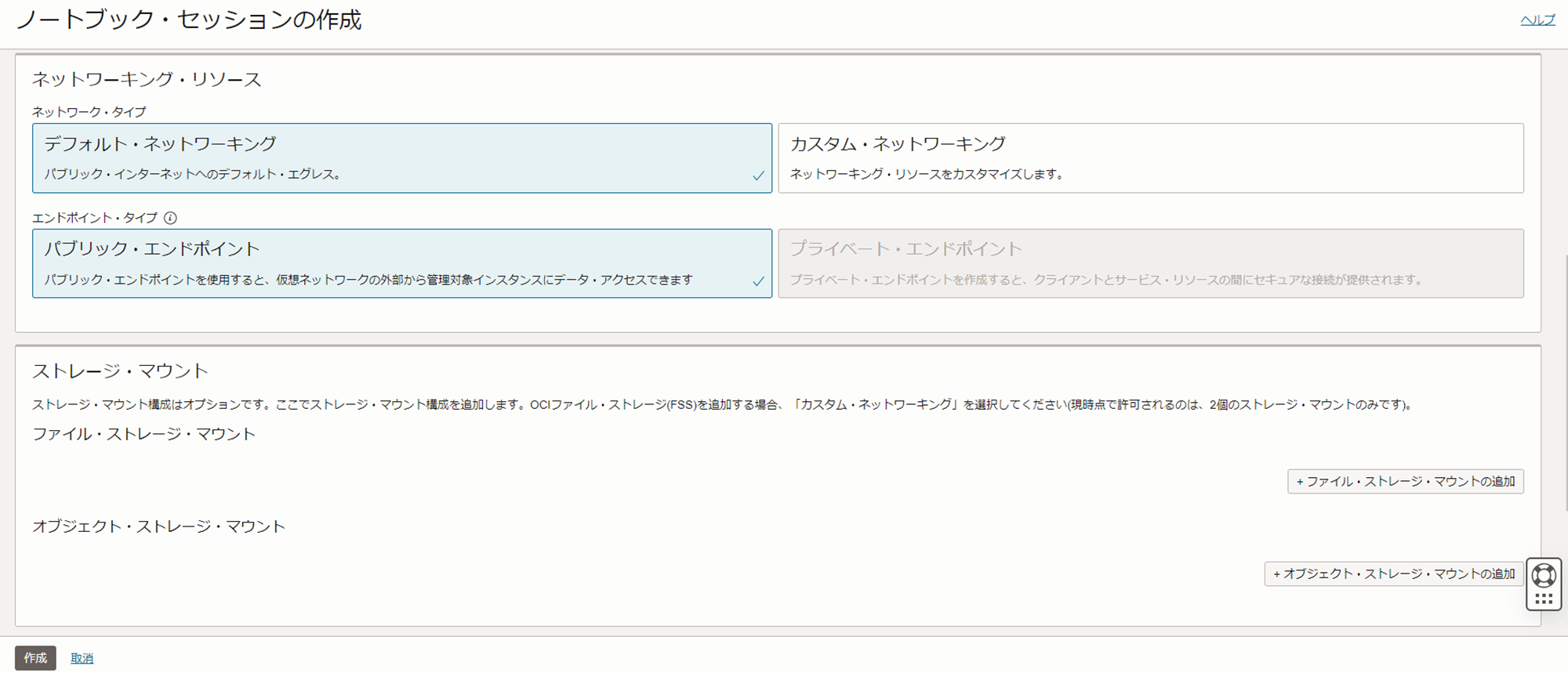
「ノートブック・セッションの」作成をクリックし、以下の情報を参考にノートブック・セッションを作成します。
- コンパートメント:任意のコンパートメント
- 名前:任意の名前(本記事では「RAG_DataScience_Session」)
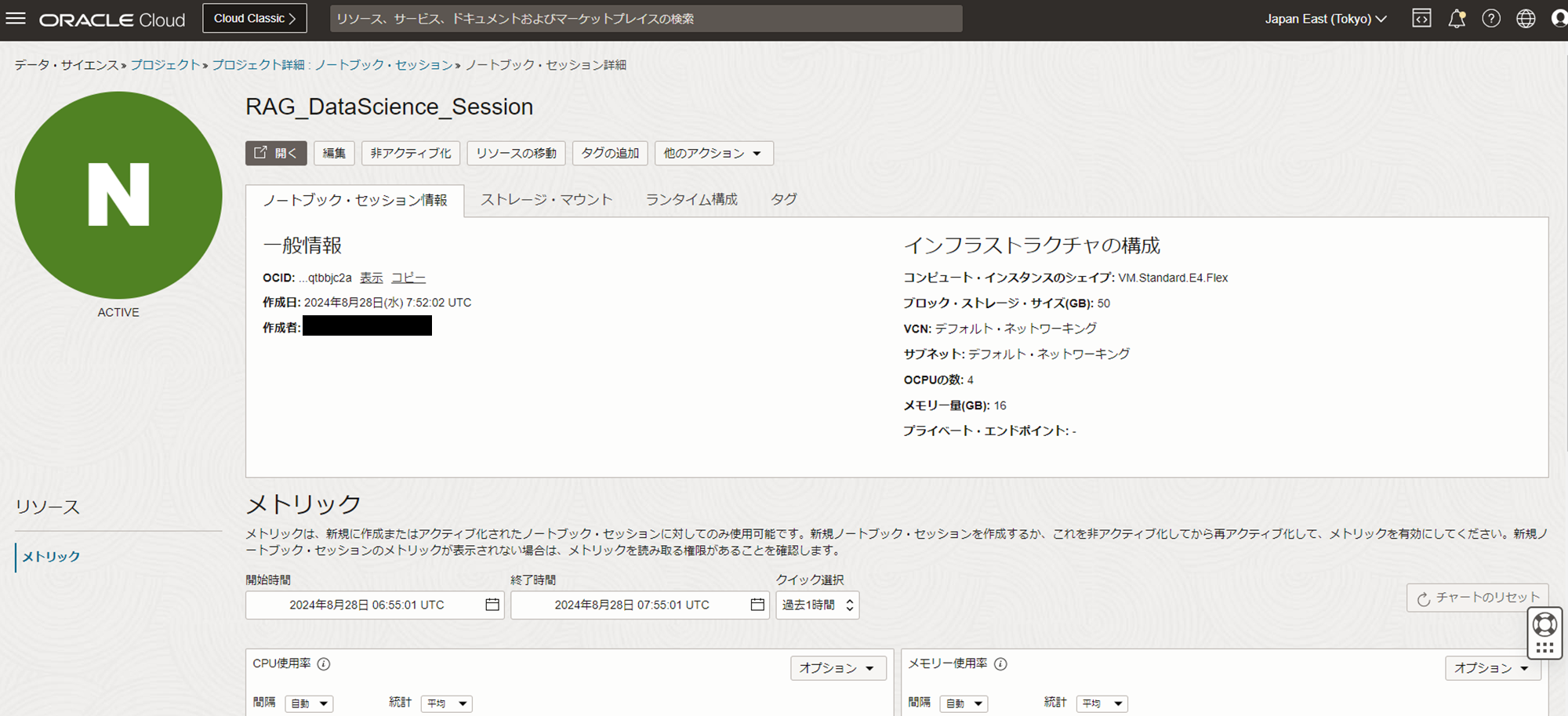
- シェイプ:VM.Standard.E4.Flex
- OCPU:4OCPU
- メモリ:16GB
- ブロック・ストレージ:50GB
- ネットワーク・タイプ:デフォルト・ネットワーキング
- エンドポイント・タイプ:パブリックエンドポイント
-
5分ほど待つとACTIVEとなり、ノートブック・セッションが利用できるようになります。
-
作成したノートブックセッションの「開く」ボタンをクリックします。
-
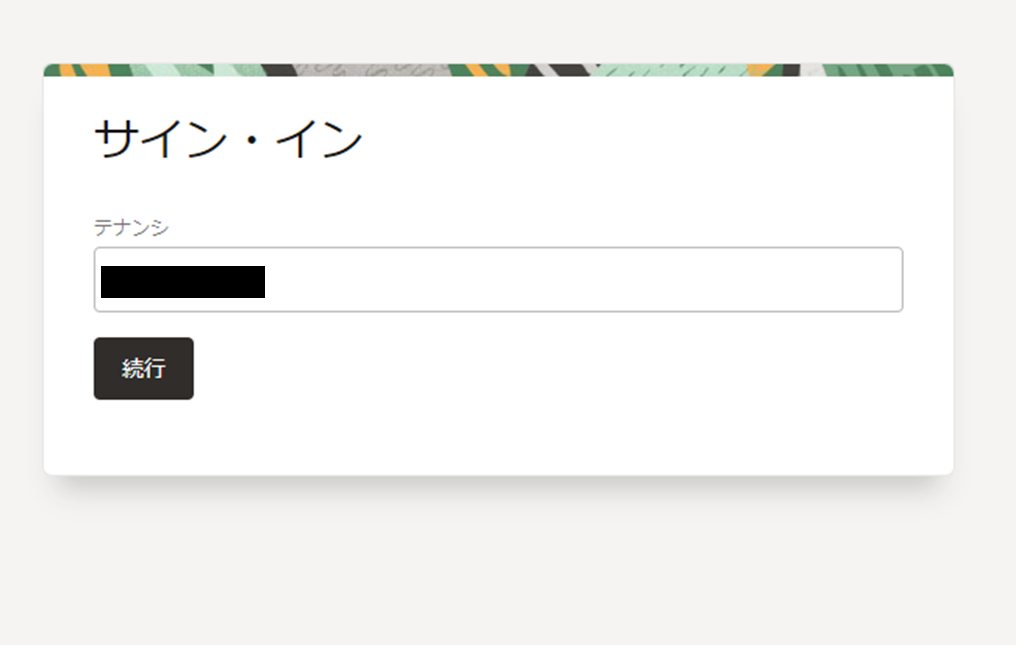
サインインの画面が表示されますのでテナント名を入力し、「続行」ボタンをクリックします。
-
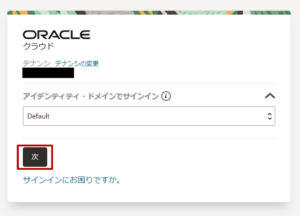
適切なアイデンティティ・ドメイン名を選択し、「次」をクリックします。
-
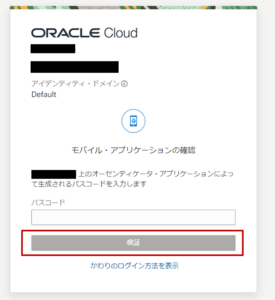
MFA設定をしている場合は、生成されるパスワードを入力し「検証」をクリックします。
-
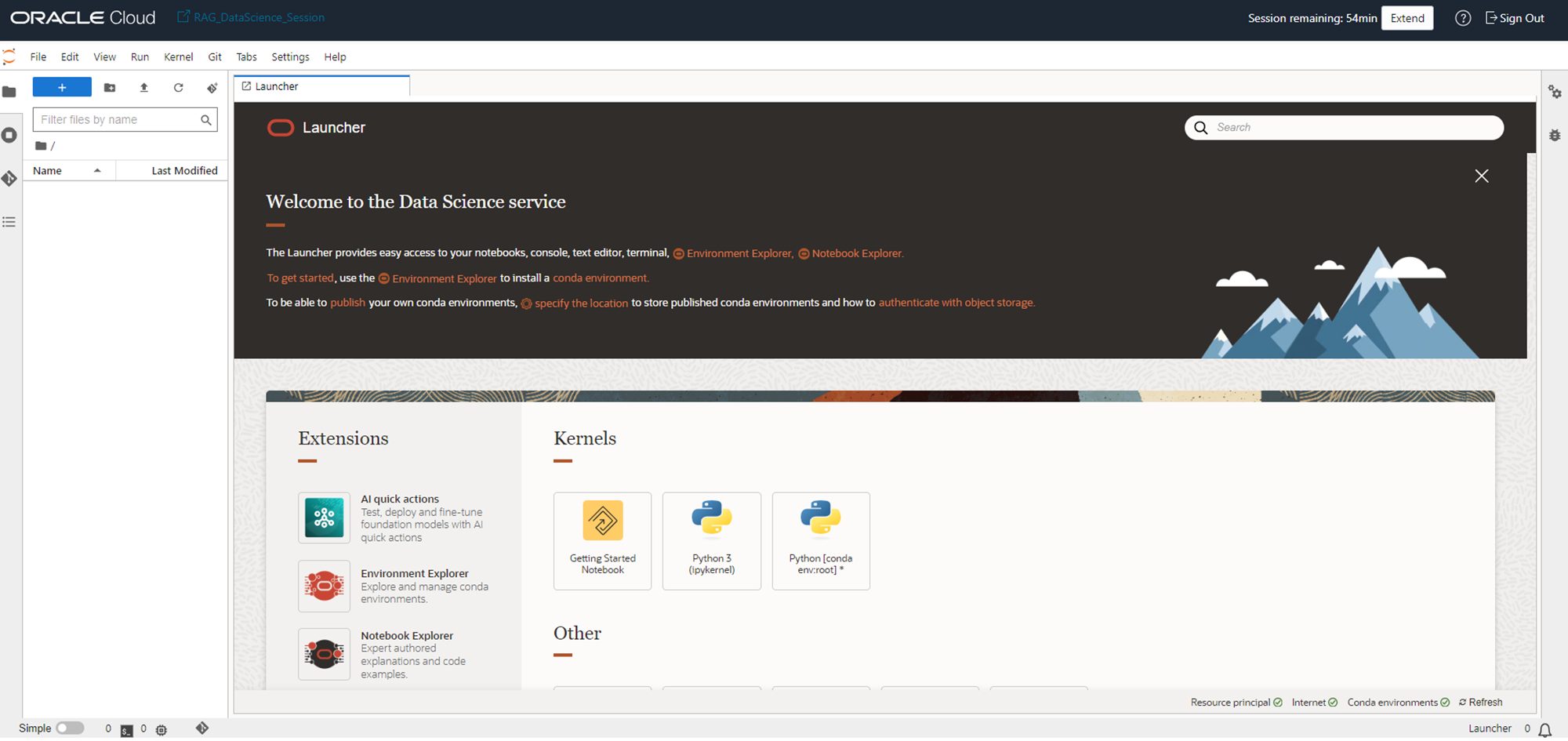
しばらくすると、ノートブック・セッションのトップ画面(Launcher)が表示されます。
まとめ
本記事では、前編としてRAG構成を実装するための準備に関する手順を紹介しました。RAG構成で利用するPDFファイルに弊社スマートスタイルの社長メッセージを利用しましたが、他のドキュメントでも実装することが出来ます。後編も参考にしながら、RAG構成を体験して頂ければと思います。
関連記事:OCI Data ScienceとOracle Database 23aiで体験するお手軽なRAG構成について(後編)