はじめに
2021 年 7 月 23 日に、MySQL Database Service の HeatWave において、Auto Parallel Load 機能が追加されています。
これまで、HeatWave クラスタにデータをロードするためには、以下のように個々のテーブルで ALTER TABLE … SECONDARY_LOAD を実行する必要がありました。
|
1 |
mysql> ALTER TABLE sysbench.sbtest1 SECONDARY_LOAD; |
今回追加された Auto Parallel Load 機能では、データをロードする際にデータベースや除外するテーブルなどを指定することが可能になり、複数のテーブルを一括でロードできるようになったので、その詳細について確認してみたいと思います。
使用方法
HeatWave の使用開始方法については、以下の記事に記載されているのでこちらもご参照ください。
MySQLで分析処理を高速化させる HeatWave を使ってみた
Auto Parallel Load 機能は MySQL の sys スキーマにある heatwave_load() という名前のストアドプロシージャとして実装されているため、HeatWave の有効化後は、このコマンドを実行します。
なお、インスタンスを作成後、検証用に sysbench を利用してデータを作成しておきます。
|
1 2 3 4 5 6 7 8 9 |
# sysbench --db-driver=mysql \ --mysql-host=<MySQL Database Service Endpoint> \ --mysql-user=<User> \ --mysql-password=<User Password> \ --mysql-db=sysbench2 \ --tables=3 \ --table_size=5000000 \ oltp_read_only \ prepare |
実行に必要な権限
heatwave_load() を実行するユーザーには、以下の権限が付与されている必要があります。
- PROCESS 権限
- sys スキーマに対する EXECUTE 権限
- パフォーマンススキーマに対する SELECT 権限
コマンドのオプション
heatwave_load() で使用できるオプションを確認したい場合、以下のコマンドからヘルプを表示することが可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
mysql> CALL sys.heatwave_load(JSON_ARRAY(""),JSON_OBJECT("output","help")); +------------------------------------------+ | INITIALIZING HEATWAVE AUTO LOAD | +------------------------------------------+ | Version: 1.15 | | | | Load Mode: normal | | Load Policy: disable_unsupported_columns | | Output Mode: help | | | +------------------------------------------+ 6 rows in set (0.00 sec) +--------------------------------------------------------------------------------------------------------+ | USAGE DOCUMENTATION | +--------------------------------------------------------------------------------------------------------+ | Interface: | | CALL sys.heatwave_load(db_list, options); | | | | Input Arguments: | | db_list: (Mandatory) JSON_ARRAY of schema names | | options: (Optional) JSON_OBJECT for options | | key: "mode", value_type: enum("normal", "dryrun") | | // dryrun mode: Only generates load script (does not load the tables) | | // normal mode (DEFAULT): Generates the load script and also loads data into HeatWave | | key: "output" value_type: enum("normal", "compact", "silent", "help") | | // normal output (DEFAULT): Produces detailed output on stdout in addition to temp table | | // compact output: Produces summarized output (and errors) on stdout in addition to temp table | | // silent output: Only produces temp table output. Useful for scripting | | // help output: Shows this output | | key: "sql_mode" value_type: string | | // valid string containing SQL_MODE (Session variable SQL_MODE is not used by Auto Load) | | key: "policy" value_type: enum("disable_unsupported_columns", "not_disable_unsupported_columns") | | // not_disable_unsupported_columns policy: Does not load table if an unsupported column exists | | // disable_unsupported_columns policy (DEFAULT): Load the table by disabling unsupported columns | | key: "exclude_list" value_type: array of strings (JSON_ARRAY) | | // List of database objects to be explicitly excluded from load | | // Fully qualified names of tables and columns are expected without backticks | | key: "set_load_parallelism" value_type: boolean | | // Enabled by default. When enabled dynamically sets the load parallelism for each table | | key: "use_load_time_estimation" value_type: boolean | | // Enabled by default. When enabled, produces load time estimates. | | key: "auto_enc" value_type: JSON_OBJECT for configuring Auto Encoding | | key: "mode" value_type: enum("off", "check") | | // check (DEFAULT). Produce MySQL node footprint estimates for tables | | | | Output: | | Temporary table: "sys.heatwave_load_report" | | | | Examples: | | CALL sys.heatwave_load(JSON_ARRAY("db1"),NULL); | | CALL sys.heatwave_load(JSON_ARRAY("db1","db2"), JSON_OBJECT("mode","normal","policy", | | "disable_unsupported_columns","exclude_list",JSON_ARRAY("db1.tbl1","db2.tbl1.col1"))); | +--------------------------------------------------------------------------------------------------------+ 37 rows in set (0.01 sec) Query OK, 0 rows affected (0.01 sec) |
まず、db_list としてロードするデータをスキーマ単位で指定します。その際、リストは JSON_ARRAY("db1","db2",...) という形式で入力します。なお、ヘルプを表示する場合以外、ひとつ以上の値を入力する必要があります。
その後、各オプションを JSON_OBJECT("key","value",...) という形式で入力していきます。オプションを指定しない場合、NULL を指定することも可能です。このとき、省略した項目については各オプションのデフォルト値が指定されます。
各オプションの説明は以下の通りです。
- mode : 操作モードを指定します。
- normal : ロード用スクリプトを生成して実行します。この値がデフォルト値です。
- dryrun : ロード用スクリプトのみを生成して実行しません。なお、HeatWave クラスタが有効でない場合、自動的にこのモードで実行されます。
- output : 実行結果の出力方法を指定します。
- normal : 標準出力および heatwave_load_report テーブルに結果を出力します。この値がデフォルト値です。
- silent : heatwave_load_report テーブルにのみ結果を出力します。結果をその場で確認する必要がない場合などはこちらの方が良いかと思います。
- compact : 結果をコンパクトな形式で出力します。
- help : コマンドラインヘルプを表示する際に指定します。
- sql_mode : データのロード中に使用される SQL モードを指定します。Auto Parallel Load 機能では sql_mode システム変数をサポートしていないため、デフォルト値以外の SQL モードを使用してロードをおこなう場合、このオプションを指定する必要があります。
-
policy : サポートされていないデータ型を含むテーブルを処理する際の挙動を指定します。
- disable_unsupported_columns : サポートされていないデータ型のカラムは無効にして、それ以外のカラムをロードします。なお、NOT SECONDARY が明示的に定義されている列はロードの際に無視されます。この値がデフォルト値です。
- not_disable_unsupported_columns : サポートされていないデータ型のカラムを含むテーブルの全データをロード対象から除外します。
- exclude : ロード対象から除外するデータベースオブジェクト(スキーマ、テーブル、カラム)のリストを指定します。指定する際には、
JSON_OBJECT("exclude_list", JSON_ARRAY("db0.t1","db0.t2")));のようにバッククォートを使用しないで修飾する必要があります。なお、システムスキーマや InnoDB ストレージエンジンでないテーブル、HeatWave に既にロードされているテーブルは自動的に除外されます。 -
set_load_parallelism : ロードの並列処理を最適化します。デフォルトで有効になっており、innodb_parallel_read_threads システム変数によって並列数を制御できます。
-
auto_enc : MySQL ノードで Dictionary Encoding されたカラムの実行に十分なメモリーがあるかどうかを確認します。
- mode : auto_enc の操作モードを指定します。
- off : auto_enc オプションを無効にします。
- check : ロードをおこなう際に十分なメモリーがあるかどうかを確認します。メモリーが不足している場合、dryrun モードで実行され、メモリー不足に関する警告が出力されます。
コマンドの実行
必要な権限を持ったユーザーから heatwave_load() を実行します。
なお、HeatWave を有効化する際に「ノード数の見積もり」を選択することで、全てのオブジェクトをロードするためのコマンドを確認することができます。
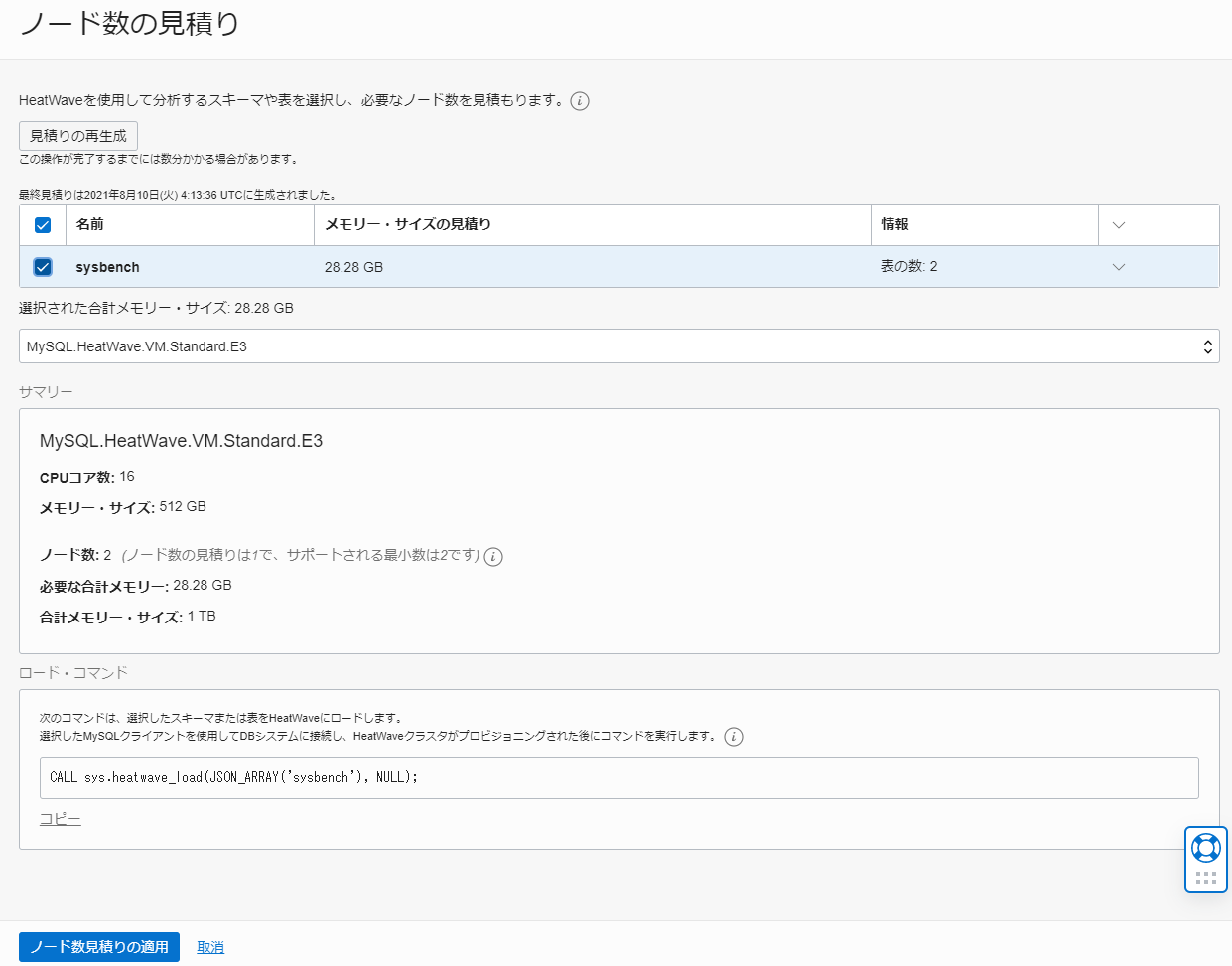
ここでは、sysbench で作成した 3 つのテーブルに対してデータロードを実行してみます。
なお、実行すると以下の内容が自動で出力されていきます。
1. コマンドの実行
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mysql> CALL sys.heatwave_load(JSON_ARRAY('sysbench2'), NULL); +------------------------------------------+ | INITIALIZING HEATWAVE AUTO LOAD | +------------------------------------------+ | Version: 1.15 | | | | Load Mode: normal | | Load Policy: disable_unsupported_columns | | Output Mode: normal | | | +------------------------------------------+ 6 rows in set (0.01 sec) |
2. 実行時間の見積もりおよびロード用スクリプトの生成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
+------------------------------------------------------------------------+ | OFFLOAD ANALYSIS | +------------------------------------------------------------------------+ | Verifying input schemas: 1 | | User excluded items: 0 | | | | SCHEMA OFFLOADABLE OFFLOADABLE SUMMARY OF | | NAME TABLES COLUMNS ISSUES | | ------ ----------- ----------- ---------- | | `sysbench2` 3 12 | | | | Total offloadable schemas: 1 | | | +------------------------------------------------------------------------+ 10 rows in set (0.19 sec) +-----------------------------------------------------------------------------------------------------------------------------+ | CAPACITY ESTIMATION | +-----------------------------------------------------------------------------------------------------------------------------+ | Default load pool for tables: TRANSACTIONAL | | Default encoding for string columns: VARLEN (unless specified in the schema) | | Estimating memory footprint for 1 schema(s) | | | | TOTAL ESTIMATED ESTIMATED TOTAL DICTIONARY VARLEN ESTIMATED | | SCHEMA OFFLOADABLE HEATWAVE NODE MYSQL NODE STRING ENCODED ENCODED LOAD | | NAME TABLES FOOTPRINT FOOTPRINT COLUMNS COLUMNS COLUMNS TIME | | ------ ----------- --------- --------- ------- ---------- ------- --------- | | `sysbench2` 3 5.81 GiB 12.00 MiB 6 0 6 14.00 s | | | | Sufficient MySQL host memory available to load all tables. | | Sufficient HeatWave cluster memory available to load all tables. | | | +-----------------------------------------------------------------------------------------------------------------------------+ 13 rows in set (0.20 sec) +---------------------------------------------------------------------------------------------------------------------------------------+ | EXECUTING LOAD | +---------------------------------------------------------------------------------------------------------------------------------------+ | HeatWave Load script generated | | Retrieve load script containing 9 generated DDL command(s) using the query below: | | SELECT log->>"$.sql" AS "Load Script" FROM sys.heatwave_load_report WHERE type = "sql" ORDER BY id; | | | | Adjusting load parallelism dynamically per table | | Using current parallelism of 32 thread(s) as maximum | | | | Using SQL_MODE: ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION | | | | Proceeding to load 3 tables into HeatWave | | | | Applying changes will take approximately 13.26 s | | | +---------------------------------------------------------------------------------------------------------------------------------------+ 13 rows in set (0.21 sec) |
3. 各テーブルのデータをロード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
+----------------------------------------+ | LOADING TABLE | +----------------------------------------+ | TABLE (1 of 3): `sysbench2`.`sbtest1` | | Commands executed successfully: 3 of 3 | | Warnings encountered: 0 | | Table loaded successfully! | | Total columns loaded: 4 | | Table loaded using 32 thread(s) | | | +----------------------------------------+ 7 rows in set (35.68 sec) +----------------------------------------+ | LOADING TABLE | +----------------------------------------+ | TABLE (2 of 3): `sysbench2`.`sbtest2` | | Commands executed successfully: 3 of 3 | | Warnings encountered: 0 | | Table loaded successfully! | | Total columns loaded: 4 | | Table loaded using 32 thread(s) | | | +----------------------------------------+ 7 rows in set (1 min 12.19 sec) +----------------------------------------+ | LOADING TABLE | +----------------------------------------+ | TABLE (3 of 3): `sysbench2`.`sbtest3` | | Commands executed successfully: 3 of 3 | | Warnings encountered: 0 | | Table loaded successfully! | | Total columns loaded: 4 | | Table loaded using 32 thread(s) | | | +----------------------------------------+ 7 rows in set (1 min 48.71 sec) |
4. 実行結果の表示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
+-------------------------------------------------------------------------------+ | LOAD SUMMARY | +-------------------------------------------------------------------------------+ | | | SCHEMA TABLES TABLES COLUMNS LOAD | | NAME LOADED FAILED LOADED DURATION | | ------ ------ ------ ------- -------- | | `sysbench2` 3 0 12 1.81 min | | | +-------------------------------------------------------------------------------+ 6 rows in set (1 min 48.71 sec) Query OK, 0 rows affected (1 min 48.71 sec) |
コマンドの実行結果
heatwave_load() を実行すると、sys.heatwave_load_report テーブルに実行結果が格納されます。
なお、このテーブルは一時テーブルであるため、heatwave_load() を実行したセッションからでないと確認することができない点に注意してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mysql> DESC sys.heatwave_load_report; +-------+-------------------------------------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------------------------------------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | ts | timestamp(6) | NO | | NULL | NULL | | comp | varchar(15) | YES | | NULL | NULL | | stage | text | YES | | NULL | NULL | | type | enum('error','warn','info','msg','debug','sql') | NO | | NULL | NULL | | log | json | YES | | NULL | NULL | +-------+-------------------------------------------------+------+-----+---------+----------------+ 6 rows in set (0.00 sec) |
たとえば、実行した結果で何かエラーが発生していないかを確認する場合、以下のような SQL で確認できます。
|
1 2 |
mysql> SELECT log FROM sys.heatwave_load_report WHERE type IN ("error","warn"); Empty set (0.00 sec) |
また、実行された DDL を確認したい場合、以下のような SQL で確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> SELECT log->>"$.sql" AS "Load Script" FROM sys.heatwave_load_report WHERE type = "sql" ORDER BY id; +-----------------------------------------------------------+ | Load Script | +-----------------------------------------------------------+ | SET SESSION innodb_parallel_read_threads = 32; | | ALTER TABLE `sysbench2`.`sbtest1` SECONDARY_ENGINE=RAPID; | | ALTER TABLE `sysbench2`.`sbtest1` SECONDARY_LOAD; | | SET SESSION innodb_parallel_read_threads = 32; | | ALTER TABLE `sysbench2`.`sbtest2` SECONDARY_ENGINE=RAPID; | | ALTER TABLE `sysbench2`.`sbtest2` SECONDARY_LOAD; | | SET SESSION innodb_parallel_read_threads = 32; | | ALTER TABLE `sysbench2`.`sbtest3` SECONDARY_ENGINE=RAPID; | | ALTER TABLE `sysbench2`.`sbtest3` SECONDARY_LOAD; | +-----------------------------------------------------------+ 9 rows in set (0.00 sec) |
まとめ
ここまで、Auto Parallel Load 機能について使用方法を確認してきました。
従来の HeatWave へのロード方法はテーブル単位に手動でコマンドを実行する必要があったのに対して、heatwave_load() ではスキーマ単位で自動実行することが可能になったため、HeatWave を利用するまでの流れがスムーズになったのではないかと思います。
より利用しやすくなった HeatWave を使用して、手軽に検証をおこなってみてはいかがでしょうか?