
MariaDB ColumnStoreからS3を使用する
先日MariaDB Server 10.5.4(GA)がリリースされ、それに含まれる形でMariaDB ColumnStore 1.5.2(Beta)がリリースされました。
MariaDB Enterprise Server 10.4では、先行してMariaDB ColumnStore 1.4がリリースされておりますが、コミュニティでは同梱されるMariaDB Serverのバージョンに合わせて1.5となったようです。
MariaDB ColumnStore 1.4 から導入されたStorege Manager(SM)という機能により、AWS S3及びその互換ストレージをDBRootとして利用可能となっています。
ストレージの故障はデータベースの運用において悩みの種ですが、パブリッククラウドのオブジェクトストレージは非常に可用性も高く、高コストな初期投資無しに利用可能ということでMariaDB ColumnStoreで利用できることは非常に喜ばしいものと思います。
今回はMariaDB ColumnStoreのStorage Manager(SM)からS3互換ストレージを使用する方法についてご紹介致します。
リファレンス
https://mariadb.com/docs/features/mariadb-columnstore/#s3-storage-manager
https://mariadb.com/docs/deploy/enterprise-multi-columnstore/#storage-manager
https://mariadb.com/docs/deploy/enterprise-multi-columnstore-es104-centos8/#storage-manager
環境について
- 今回はCentOS 8.2/MariaDB Server 10.5.4を使用します。
- 同梱されているMariaDB ColumnStore 1.5.2はまだBetaですので、将来的には動作が大きく変更される可能性がございます。
- AWS S3とS3互換ストレージであるGCPのCloud Storageを使用します。
また、S3の準備については以下をご確認ください。
AWS S3
https://docs.aws.amazon.com/cli/latest/userguide/cli-services-s3-commands.html
GCP Cloud Storage
https://cloud.google.com/storage/docs/creating-buckets#storage-create-bucket-gsutil
Storage Managerとは
MariaDB ColumnStoreではPerformance Moduleが利用するマウントポイントであるDBRootとして、以下がもともと利用可能でした。
- ローカルストレージ
- SANなどのハードウェアレベルの共有ストレージ
- GlusterFSなどのソフトウェアレベルの共有ストレージ
これまでは大部分を外部の仕組みに依存していましたが、Storage Managerでは共有ストレージの利用を一括で管理し、さらにS3互換ストレージを共有ディスクとして利用可能となっています。
- AWS S3, Google Cloud Storage, IBM Cloud Storage, Ceph, etc
アーキテクチャ
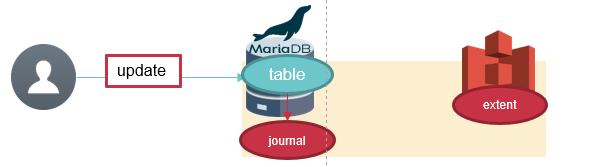
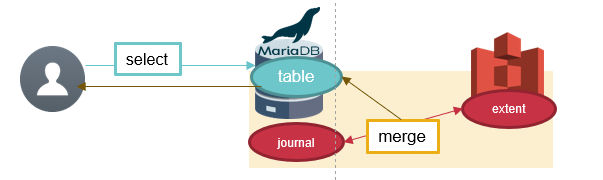
Storage Manager S3は、ローカルに配置するジャーナルファイルと、リモートのS3互換ストレージで構成されます。
一定量の更新データはローカルのジャーナルファイルに保持されます。
何らかのクエリを実行した場合は、ジャーナルファイルとリモートのS3互換ストレージのデータをマージして、クライアントに結果を返します。
ジャーナルファイルは起動・停止時、及びジャーナルファイルの上限を超過した場合にS3にマージされます。
MariaDB Server 10.5でのColumnStoreの起動
MariaDB Server 10.4からはMariaDB ColumnStore Engineがマージされており、より簡単にインストールが可能となっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ dnf install wget $ wget https://downloads.mariadb.com/MariaDB/mariadb_repo_setup $ echo "2de6253842f230bc554d3f5ab0c0dbf717caffbf45ae6893740707961c8407b7 mariadb_repo_setup" \ | sha256sum -c - $ chmod +x mariadb_repo_setup $ ./mariadb_repo_setup \ --mariadb-server-version="mariadb-10.5" $ dnf install MariaDB-server MariaDB-columnstore-engine |
Storage Managerの設定
起動前に /etc/columnstore/storagemanager.cnf に設定を行います。
オリジナルの設定ファイルには様々なコメントが記載されていますが、ここではコメントを削除した内容を記載します。
また今回はLocalStorageを使用していないため該当セクションは除外しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[ObjectStorage] service = S3 object_size = 5M metadata_path = /var/lib/columnstore/storagemanager/metadata journal_path = /var/lib/columnstore/storagemanager/journal max_concurrent_downloads = 21 max_concurrent_uploads = 21 common_prefix_depth = 3 [S3] region = us-east-1 bucket = mcs-s3 # endpoint = storage.googleapis.com aws_access_key_id = XXXXXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [Cache] cache_size = 2g path = /var/lib/columnstore/storagemanager/cache |
| セクション | パラメータ名 | 説明 |
|---|---|---|
| ObjectStorage | service | S3互換ストレージを利用するならS3, それ以外ではLocalStorageを指定します |
| ObjectStorage | object_size | S3に保存される1オブジェクトのサイズ。Storage Managerによってデータはこの単位に分割されます |
| ObjectStorage | metadata_path | S3上のオブジェクトが列挙された管理用ファイル(JSON)を保持するディレクトリ |
| ObjectStorage | journal_path | 更新ログを保持するディレクトリ |
| ObjectStorage | max_concurrent_downloads | S3からの最大ダウンロードスレッド数 |
| ObjectStorage | max_concurrent_uploads | S3への最大アップロードスレッド数 |
| ObjectStorage | common_prefix_depth | DBRootが存在するディレクトリの深さ |
| S3 | region | 利用するS3のリージョン名 |
| S3 | bucket | S3バケット名 |
| S3 | endpoint | S3のエンドポイント。AWS S3の場合は必要ありませんがその他のS3互換ストレージの場合に指定します(eg. storage.googleapis.com) |
| S3 | aws_access_key_id | S3 APIを利用する際のアクセスキー。AWSに限らず指定する必要があります。 |
| S3 | aws_secret_access_key | S3 APIを利用する際のシークレットアクセスキー。AWSに限らず指定する必要があります。 |
| Cache | cache_size | ジャーナルファイルの最大サイズ。このサイズを超えるとS3へのアップロードが行われます。 |
| Cache | path | 一時オブジェクトが配置されるディレクトリ |
今回はus-east-1リージョンにmcs-s3バケットを作成しました。
|
1 |
$ aws s3 mb s3://mcs-s3 --region us-east-1 |
準備ができましたら起動します。
|
1 2 |
$ systemctl start mariadb-columnstore $ systemctl start mariadb |
起動した時点で、オブジェクトストレージに必要なファイルが配置されます。
AWS S3の確認
S3上で、object_sizeでのデータファイルが大量に作成されていることが判ります。
|
1 2 3 4 5 6 7 8 9 |
$ aws s3 ls --human-readable --recursive s3://mcs-s3 | sort -n : 2020-07-08 16:24:44 5.0 MiB 25e39c78-763b-4ef9-9938-a09fe0bd50e4_0_5242880_data1~000.dir~000.dir~011.dir~198.dir~000.dir~FILE000.cdf 2020-07-08 16:24:44 5.0 MiB 442873ec-b62a-4eb0-8e1a-fbb332598dcb_68157440_5242880_data1~000.dir~000.dir~011.dir~203.dir~000.dir~FILE000.cdf 2020-07-08 16:24:44 5.0 MiB 757c6d0f-7c24-4f83-929b-329d8363cd0b_15728640_5242880_data1~000.dir~000.dir~011.dir~187.dir~000.dir~FILE000.cdf 2020-07-08 16:24:44 5.0 MiB 89cc1757-4990-4eef-83d3-6bc320e498d1_0_5242880_data1~000.dir~000.dir~011.dir~185.dir~000.dir~FILE000.cdf 2020-07-08 16:24:44 5.0 MiB c299180d-d338-46ca-8261-d584364858c4_0_5242880_data1~000.dir~000.dir~011.dir~200.dir~000.dir~FILE000.cdf 2020-07-08 16:24:44 5.0 MiB ccf766fd-f732-4347-931c-254915a9c554_0_5242880_data1~000.dir~000.dir~011.dir~191.dir~000.dir~FILE000.cdf 2020-07-08 16:24:44 5.0 MiB d40a1ac7-2829-4eda-a219-2decd5d1ecfb_0_5242880_data1~000.dir~000.dir~011.dir~192.dir~000.dir~FILE000.cdf |
GCP Cloud Storage
今度は一旦データをクリーンアップし、GCPのバケットを使用します。
AWS以外のS3互換ストレージでは明示的にendpointの指定が必要です。
|
1 2 3 4 5 6 |
[S3] region = us-east-1 bucket = mcs-gcp-cs endpoint = storage.googleapis.com aws_access_key_id = XXXXXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX |
同様にDBT-3のデータをロードし、内容を確認しました。
|
1 2 3 4 5 6 7 |
$ gsutil ls -lh -r gs://mcs-gcp-cs/** | sort -k2 : 2.5 MiB 2020-07-08T08:03:38Z gs://mcs-gcp-cs/d629baed-9c1c-4301-b8a2-17ad0a41ceb7_20971520_2621440_data1~000.dir~000.dir~011.dir~187.dir~000.dir~FILE000.cdf 5 MiB 2020-07-08T08:03:38Z gs://mcs-gcp-cs/f9aa1d67-8348-462e-a53c-7bb4009329bd_68157440_5242880_data1~000.dir~000.dir~011.dir~203.dir~000.dir~FILE000.cdf 3.05 MiB 2020-07-08T08:03:39Z gs://mcs-gcp-cs/27fad7d2-4208-4bc8-98d9-f431bcbbe90c_20971520_3194880_data1~000.dir~000.dir~011.dir~186.dir~000.dir~FILE000.cdf 5 MiB 2020-07-08T08:03:39Z gs://mcs-gcp-cs/eeb46e11-7aff-46e2-bcf1-921f136e589e_20971520_5242880_data1~000.dir~000.dir~011.dir~190.dir~000.dir~FILE000.cdf 5 MiB 2020-07-08T08:03:40Z gs://mcs-gcp-cs/5f43d46b-f22d-4fc6-89f0-d7a22ac29d05_62914560_5242880_data1~000.dir~000.dir~011.dir~203.dir~000.dir~FILE000.cdf |
正常に格納されており、S3 互換ストレージであれば利用可能な事が確認できました。
DBT-3の実行
今回はDBT-3の最も大きいテーブル(725M)をColumnstoreにインポートしてみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
$ ls -lh /data/lineitem.tbl -rw-r--r--. 1 root root 725M Jul 8 07:22 /data/lineitem.tbl $ mariadb -e "create database dbt3" $ cat | mariadb dbt3 <<-EOS CREATE TABLE lineitem ( l_orderkey int(11) DEFAULT NULL, l_partkey int(11) DEFAULT NULL, l_suppkey int(11) DEFAULT NULL, l_linenumber int(11) DEFAULT NULL, l_quantity decimal(10,2) DEFAULT NULL, l_extendedprice decimal(10,2) DEFAULT NULL, l_discount decimal(10,2) DEFAULT NULL, l_tax decimal(10,2) DEFAULT NULL, l_returnflag char(1) DEFAULT NULL, l_linestatus char(1) DEFAULT NULL, l_shipDATE date DEFAULT NULL, l_commitDATE date DEFAULT NULL, l_receiptDATE date DEFAULT NULL, l_shipinstruct char(25) DEFAULT NULL, l_shipmode char(10) DEFAULT NULL, l_comment varchar(44) DEFAULT NULL ) ENGINE=Columnstore DEFAULT CHARSET=latin1 EOS $ cpimport -s \| dbt3 lineitem lineitem.tbl |
また、DBT-3のQuery-1を実行し、速度差異について確認しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from lineitem where l_shipdate <= date_sub('1998-12-01', interval 3 day) group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus; |
パフォーマンス結果
今回の検証環境はMemory 2GB/CPU 2 coreというスペックですので、性能自体は参考程度とお考えください。
| cpimport | DBT-QUERY-1 | |
|---|---|---|
| S3 | 96s | 11s |
| GCP CS | 75s | 11s |
| Local | 28s | 11s |
ネットワーク通信の影響により、データローディングは顕著に遅い状況となりました。
一方でcache_sizeに収まる程度のデータが対象であればSELECTの速度はあまり落ちないようです。
所感
ネットワーク越しのストレージを使用する場合、どうしてもI/O性能が下がってしまうという点がデメリットとしてありますが、その代わりにマネージドサービスによる恩恵が受けられ管理運用の手間がなくなるという点は魅力的だと思います。
今回、オンプレの検証環境からS3を利用したため速度差が顕著でしたので、実稼働時には同じパブリッククラウド内にMariaDB Columnstoreを構築する等のNWに関する工夫が必要なようです。
また、すでにRados Gatewayを含むCeph Clusterをストレージサーバとして運用されている場合は、オンプレで完結することも可能です。
ご興味がありましたらぜひお試しください。







