前編ではPercona XtraDB Clusterでディザスタリカバリー(以下:DR)を行うための構成と障害時に動作するQuorumについて説明しました。
今回は実際にAWSでPercona XtraDB Clusterのフェイルオーバー、フェイルバックの挙動を検証していきたいと思います。
検証環境
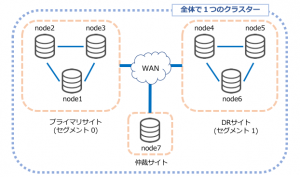
検証環境としてAWSの3拠点(東京、シンガポール、ソウル)を利用したPercona XtraDB ClusterによるDR構成を以下の図のように構築しました。
シンガポールにあるのは仲裁ノード(Arbitrator)です。
仲裁ノードはデータを持たないダミーノードで、通常のノードと同じように振る舞うことでノード数にカウントされます。
■検証用に使用するデータベースをプライマリサイト(東京)のノードで作成
[mysql]
tokyo> create database create_tokyo1;
Query OK, 1 row affected (0.17 sec)
[/mysql]
■DRサイト(ソウル)のノードで検証用データベースが作成されていることを確認
[mysql]
seoul> show databases;
+——————–+
| Database |
+——————–+
| information_schema |
| create_tokyo1 |
| mysql |
| performance_schema |
+——————–+
4 rows in set (0.00 sec)
[/mysql]
フェイルオーバー
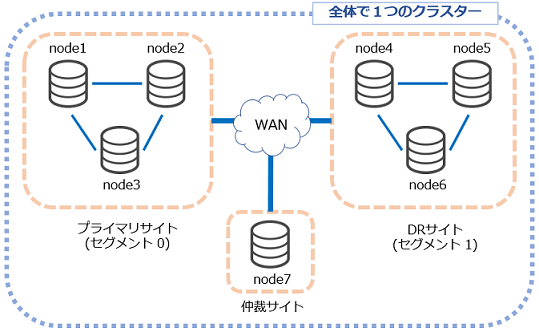
まずはプライマリサイトである東京リージョンで大規模障害が発生したと仮定して、東京リージョンのEC2インスタンスを全て停止します。この時、DRサイトへのフェイルオーバーが必要となります。
■DRサイト(ソウル)のノードでアクティブなノード数を確認
[mysql]
seoul> SHOW STATUS LIKE ‘wsrep_cluster_size’;
+——————–+——-+
| Variable_name | Value |
+——————–+——-+
| wsrep_cluster_size | 4 |
+——————–+——-+
1 row in set (0.00 sec)
[/mysql]
この場合、東京リージョンの3ノードがダウンしていますが、シンガポールの仲裁ノードとソウルを含む4ノード構成となっているため、プライマリーコンポーネントとしてDRサイトはそのまま継続して利用することができます。
■DRサイト(ソウル)のseoul1のノードでテーブルを作成
[mysql]
seoul1> CREATE TABLE create_seoul1_tokyo_down (id int primary key, server varchar(30));
Query OK, 0 rows affected (0.16 sec)
[/mysql]
■seoul2のノードでも先ほど作成したテーブルが反映されていることが確認できます。
[mysql]
seoul2> SHOW TABLES;
+————————–+
| Tables_in_create_tokyo1 |
+————————–+
| create_seoul1_tokyo_down |
+————————–+
1 row in set (0.00 sec)
[/mysql]
このように、Percona XtraDB Clusterではフェイルオーバーに作業が発生しません。
フェイルオーバーに必要なのは、DNSやLBなどでDRサイト側にアクセスを切り替える作業だけです。そのため、DBへのアクセスさえ正しく切り替えできれば、ダウンタイム無しでサービスを継続することが可能です。
仲裁ノードが無い場合だと。。。?
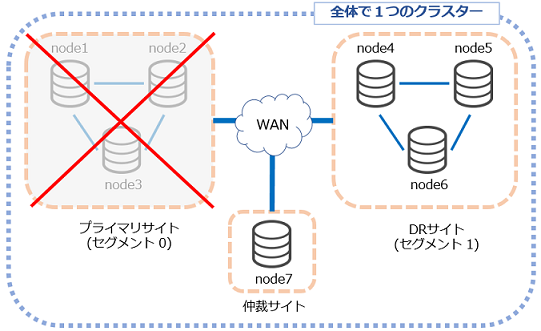
もし、シンガポールの仲裁ノードが無い6台構成の場合、ダウンしたノード数と生きているノード数が同数(3:3)となり、両方ともにNON-PRIMARYになるため、書き込みも読み込みもできなくなります。
(PRIMARYになるのは、ノード数が全体の「半分」より多い場合)
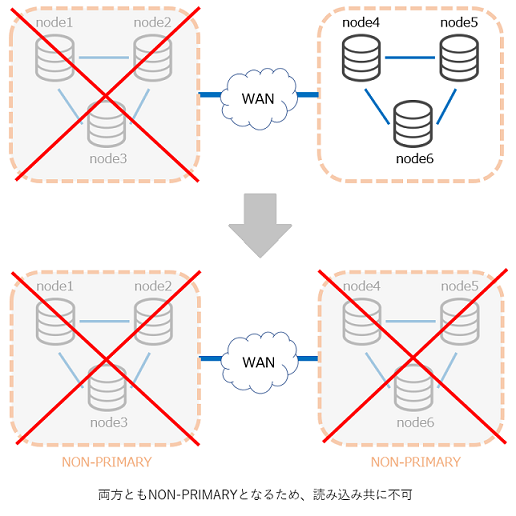
このQuorumの機能があるため、1クラスターの最小構成は3ノードとなります。
※仮に3ノード間のネットワークが一部切断されてしまった場合にも、1ノードと2ノードに分断されることで、2ノード側がPRIMARYコンポーネントとして生き残ります。この時、もし2ノードで構成していた場合には、1ノード・1ノードに分断されてしまうこととなり、仲裁ノードがない場合と同じくどちらもがNON-PRIMARYとなる問題が発生してしまいます。
フェイルバック
プライマリサイトの東京リージョンが復帰したとして東京側のEC2インスタンスを起動します。
Percona XtraDB Clusterのノードが起動すると自動的にクラスターに参加してDRサイト側で受けた更新データをプライマリサイトのノードにも自動的に反映してくれます。
■プライマリサイト(東京)のノードが起動して、アクティブなノード数が7になっていることを確認
[mysql]
tokyo> SHOW STATUS LIKE ‘wsrep_cluster_size’;
+——————–+——-+
| Variable_name | Value |
+——————–+——-+
| wsrep_cluster_size | 7 |
+——————–+——-+
1 row in set (0.00 sec)
[/mysql]
Percona XtraDB Clusterではノードがクラスターに参加したときにダウンしていた間の更新データを自動で他のノードから受け取って反映されます。
■DRサイト(ソウル)の更新データがプライマリサイト(東京)にも反映されていることを確認(tokyo1のノードで実行)
[mysql]
tokyo> SHOW TABLES;
+————————–+
| Tables_in_create_tokyo1 |
+————————–+
| create_seoul1_tokyo_down |
+————————–+
1 row in set (0.00 sec)
[/mysql]
フェイルバックの作業も、Percona XtraDB Clusterではノードが起動すればクラスターへの参加や、更新データの反映まで自動で行ってくれるため、特別な作業は必要ありません。
更新データの反映が完了したら、DNSやLBでプライマリサイト側にアクセスを切り替えるだけでフェイルバックも完了です。
また、仮にDNSのキャッシュなどでプライマリサイトに切り替え後もDRサイト側にアクセスがあり、更新処理が発生したとしても全てのノードに更新情報が反映されるため、DRサイト側のアプリケーションなどでメンテナンス画面の表示やリダイレクト処理のような特別な作業も必要ありません。
DRサイト(ソウル)での更新もプライマリサイト(東京)に反映されることを確認します。
■ソウルのノードでデータ挿入
[mysql]
seoul> INSERT INTO create_seoul1_tokyo_down (id,server) \
-> VALUES (1,’insert_tokyo1′);
Query OK, 1 row affected (0.11 sec)
[/mysql]
■東京のノードで反映されていることを確認
[mysql]
tokyo> SELECT * FROM create_seoul1_tokyo_down;
+—-+—————+
| id | server |
+—-+—————+
| 1 | insert_tokyo1 |
+—-+—————+
1 row in set (0.00 sec)
[/mysql]
ベンチマーク
Galera Clusterでは、更新情報を全ノードに伝播させてから更新処理の完了となるため、ネットワークのレイテンシを低くしないと更新処理のパフォーマンスが下がってしまいます。
では実際に、リージョン間のネットワークレイテンシによって更新処理のパフォーマンスがどれほど変わってくるのかを確認します。
まずは以下のパターンでそれぞれpingを実行しました。
① tokyo-tokyo間
[shell]
[root@ip-172-21-10-40 tpcc-mysql]# ping 172.21.10.10
PING 172.21.10.10 (172.21.10.10) 56(84) bytes of data.
64 bytes from 172.21.10.10: icmp_seq=1 ttl=255 time=0.643 ms
64 bytes from 172.21.10.10: icmp_seq=2 ttl=255 time=0.490 ms
64 bytes from 172.21.10.10: icmp_seq=3 ttl=255 time=0.518 ms
64 bytes from 172.21.10.10: icmp_seq=4 ttl=255 time=0.408 ms
64 bytes from 172.21.10.10: icmp_seq=5 ttl=255 time=0.437 ms
64 bytes from 172.21.10.10: icmp_seq=6 ttl=255 time=0.356 ms
^C
— 172.21.10.10 ping statistics —
6 packets transmitted, 6 received, 0% packet loss, time 4998ms
rtt min/avg/max/mdev = 0.356/0.475/0.643/0.093 ms
[/shell]
② tokyo-seoul間
[shell]
[ec2-user@ip-172-21-10-40 ~]$ ping 10.1.10.10
PING 10.1.10.10 (10.1.10.10) 56(84) bytes of data.
64 bytes from 10.1.10.10: icmp_seq=1 ttl=253 time=32.4 ms
64 bytes from 10.1.10.10: icmp_seq=2 ttl=253 time=32.1 ms
64 bytes from 10.1.10.10: icmp_seq=3 ttl=253 time=32.7 ms
64 bytes from 10.1.10.10: icmp_seq=4 ttl=253 time=32.4 ms
64 bytes from 10.1.10.10: icmp_seq=5 ttl=253 time=32.3 ms
64 bytes from 10.1.10.10: icmp_seq=6 ttl=253 time=32.5 ms
64 bytes from 10.1.10.10: icmp_seq=7 ttl=253 time=32.3 ms
64 bytes from 10.1.10.10: icmp_seq=8 ttl=253 time=32.2 ms
^C
— 10.1.10.10 ping statistics —
8 packets transmitted, 8 received, 0% packet loss, time 7011ms
rtt min/avg/max/mdev = 32.147/32.414/32.715/0.161 ms
[/shell]
③ tokyo-singapore間
[shell]
[ec2-user@ip-172-21-10-40 ~]$ ping 10.2.10.10
PING 10.2.10.10 (10.2.10.10) 56(84) bytes of data.
64 bytes from 10.2.10.10: icmp_seq=1 ttl=253 time=68.9 ms
64 bytes from 10.2.10.10: icmp_seq=2 ttl=253 time=68.9 ms
64 bytes from 10.2.10.10: icmp_seq=3 ttl=253 time=68.7 ms
64 bytes from 10.2.10.10: icmp_seq=4 ttl=253 time=68.9 ms
64 bytes from 10.2.10.10: icmp_seq=5 ttl=253 time=68.7 ms
64 bytes from 10.2.10.10: icmp_seq=6 ttl=253 time=68.8 ms
64 bytes from 10.2.10.10: icmp_seq=7 ttl=253 time=69.3 ms
64 bytes from 10.2.10.10: icmp_seq=8 ttl=253 time=69.0 ms
^C
— 10.2.10.10 ping statistics —
8 packets transmitted, 8 received, 0% packet loss, time 7010ms
rtt min/avg/max/mdev = 68.705/68.951/69.398/0.376 ms
[/shell]
④ seoul-singapore間
[shell]
[ec2-user@ip-10-1-10-10 ~]$ ping 10.2.10.10
PING 10.2.10.10 (10.2.10.10) 56(84) bytes of data.
64 bytes from 10.2.10.10: icmp_seq=1 ttl=253 time=97.4 ms
64 bytes from 10.2.10.10: icmp_seq=2 ttl=253 time=97.5 ms
64 bytes from 10.2.10.10: icmp_seq=3 ttl=253 time=97.3 ms
64 bytes from 10.2.10.10: icmp_seq=4 ttl=253 time=97.3 ms
64 bytes from 10.2.10.10: icmp_seq=5 ttl=253 time=97.4 ms
64 bytes from 10.2.10.10: icmp_seq=6 ttl=253 time=97.5 ms
64 bytes from 10.2.10.10: icmp_seq=7 ttl=253 time=97.5 ms
64 bytes from 10.2.10.10: icmp_seq=8 ttl=253 time=97.9 ms
64 bytes from 10.2.10.10: icmp_seq=9 ttl=253 time=97.2 ms
^C
— 10.2.10.10 ping statistics —
9 packets transmitted, 9 received, 0% packet loss, time 8012ms
rtt min/avg/max/mdev = 97.240/97.500/97.975/0.201 ms
[/shell]
以上の結果より、拠点をまたがる場合(②・③・④)と、同じ拠点間の場合(①)とではネットワークレイテンシが大きく異なっていることが分かります。
(ネットワークレイテンシ:3拠点にまたがる場合 > 全て1拠点の場合)
このことを踏まえて、以下の項目それぞれベンチマークを取得しました。
* 3拠点にまたがる場合(tokyo3台+seoul3台+singapore1台)
* 全て1拠点の場合 (tokyo7台)
※ 使用したベンチマークツール:tpcc-mysql
* クラスター構成とは別に東京リージョンに設置したインスタンスより実行
* クラスター構成東京リージョン3ノードのうち、1ノードに向けて実行
| 検証環境・tpccパラメータ | |
|---|---|
| ec2インスタンス | t2.micro |
| warehouse | 1 |
| connection | 5 |
| rampup | 180sec |
| measure | 600sec |
結果は以下の通りです。(単位:tpmC)
| 3拠点にまたがる場合 | 全て1拠点の場合 | |
|---|---|---|
| 1回目 | 479.333 | 2553.000 |
| 2回目 | 444.000 | 2628.333 |
| 3回目 | 459.500 | 2624.400 |
| 4回目 | 467.000 | 3091.200 |
| 平均 | 462.458 | 2724.233 |
3拠点にまたがる場合の方が、
1拠点での場合に比べて、スコアが低いことが分かります。
以上のことから、ネットワークレイテンシが高い(=拠点を多くまたがる)場合に
更新処理を含め、パフォーマンスが低下することを確認できました。
まとめ
- Percona XtraDB Clusterを使うとフェイルオーバー、フェイルバック共にダウンタイム無しでサービスを継続できる
- フェイルオーバーだけでなくフェイルバックもPercona XtraDB Clusterでの操作はほとんど必要ない
- Quorumの仕組み上、3拠点で合計7台必要
- 更新処理のパフォーマンスはネットワークのレイテンシが大きく依存する