はじめに
今回は先月拡張されたMySQL Database Service(以下MDS)のモニタリング機能とヘルスモニタ―についてご紹介します。
リリースノートはこちらからご覧ください。
MDSのモニタリング機能に関しては以前MySQL Database Service のモニタリングを考えるで触れておりますので、ご興味がある方はご一読ください。
モニタリング拡張
拡張された主な項目としてDisk Space, HeatWave, Backup, Channelsが追加されました。
以下追加メトリックになります。
| メトリック | 説明 |
|---|---|
| Network Receive Bytes | MySQL DBシステムのネットワーク受信バイト |
| Network Transmit Bytes | MySQL DBシステムのネットワーク送信バイト |
| Disk Space Utilization | DBボリュームの合計領域使用率 |
| Total Backup Size | DBシステム当たりのすべてのバックアップの集計サイズ |
| Backup Time | バックアップ操作にかかる時間 |
| HeatWave Health Status | HeatWaveヘルス・ステータス。(0:正常/1:リカバリ/2:失敗) |
| HeatWave Data Load Progress | HeatWaveメモリーへのデータ・ロードの進行状況 |
| HeatWave Statement Count | MySQL Databaseに対して実行され、HeatWaveで実行された文の数 |
| ChannelLag | 最後の間隔で観測された、ソースに対するチャネル遅延 |
| ChannelFailure | 最後の間隔で観測されたチャネル障害イベント |
以前では見れなかったネットワークや、ディスクの使用状況が見えるようになりました。
また新しく追加された機能のインバウンドレプリケーションやHeatWave関連も追加されています。
ヘルスモニター
ヘルスモニター機能はマニュアルによるとディスク容量を監視する機能のようです。
MySQL Health Monitor is a MySQL Server component which monitors the amount of disk space available to you and raises alarms when preconfigured limits are breached. The variables and thresholds are not configurable.
設定されたディスク使用量の閾値を下回った場合、新たな更新を受け付けなくなるようです。
In the event your available disk space drops below a set amount for a specific duration, the MySQL server engages a fallback mode (SUPER_READ_ONLY) which rejects all new incoming SQL write statements (UPDATE, INSERT, DELETE, and DDL), regardless of users and privileges. Running transactions are allowed to complete.
ヘルスモニター用には構成変数があり、プレフィックスとしてhealth_monitor.がついています。
現時点では確認だけで変更は出来ませんが、下記のものがありました。
※下記の表ではhealth_monitor.は割愛してます。
| 構成変数 | 説明 | デフォルト値 |
|---|---|---|
| disk_fallback_enable | フォールバックが有効かどうかを示します。フォールバックモードはSUPER_READ_ONLYとなり、ユーザーと特権に関係なく、すべての新しい着信SQL書き込みステートメント(UPDATE、INSERT、DELETE、およびDDL)を拒否します。 | ON |
| disk_low_space_critical_level | MiBのクリティカルな低ディスク容量を定義します。使用可能なディスク容量が一定期間この値を下回ると、サーバーは読み取り専用モードになります。 | 2000 |
| disk_low_space_duration | サーバーが読み取り専用モードになる前に、使用可能なディスク領域がdisk_low_space_levelかdisk_low_space_percentの低い方の値、または両方を下回ったままにできる時間を秒単位で定義します。 | 300 |
| disk_low_space_level | MiBで予約ストレージとして指定されたディスクスペースの合計マウントを定義します。使用可能なディスク容量がdisk_low_space_durationの値よりも長くこのレベルを下回った場合、サーバーは読み取り専用モードになります。 | 5000 |
| disk_low_space_percent | 低スペースレベルをパーセントで定義します。使用可能なディスク容量が、disk_low_space_durationの値よりも長く使用可能なストレージの合計のこのパーセンテージを下回った場合、サーバーは読み取り専用モードになります。 | 4 |
| disk_monitored | ディスク統計のマウントポイント | /db |
| disk_retention | 保持されるデータサンプルの数 | 86400 |
| disk_running | ヘルスモニターのアクティブ状態を示します | ON |
| disk_sample_rate | データ収集の速度を秒単位で定義します | 60 |
| disk_usage_warning_level_1 | 使用可能なディスク容量がこのレベルを下回ると、警告WARNING_DISK_USAGE_LEVEL_1が表示されます | 20 |
| disk_usage_warning_level_2 | 使用可能なディスク容量がこのレベルを下回ると、警告WARNING_DISK_USAGE_LEVEL_2が表示されます | 10 |
| disk_usage_warning_level_3 | 使用可能なディスク容量がこのレベルを下回ると、警告WARNING_DISK_USAGE_LEVEL_3が表示されます | 5 |
| status_interval | disk_sample_rateステータスの更新がエラーログに書き込まれる頻度を倍数で定義します。たとえば、status_intervalが10でdisk_sample_rate秒が60秒の場合、ステータスメッセージは600秒ごとにログに書き込まれます。 | 10 |
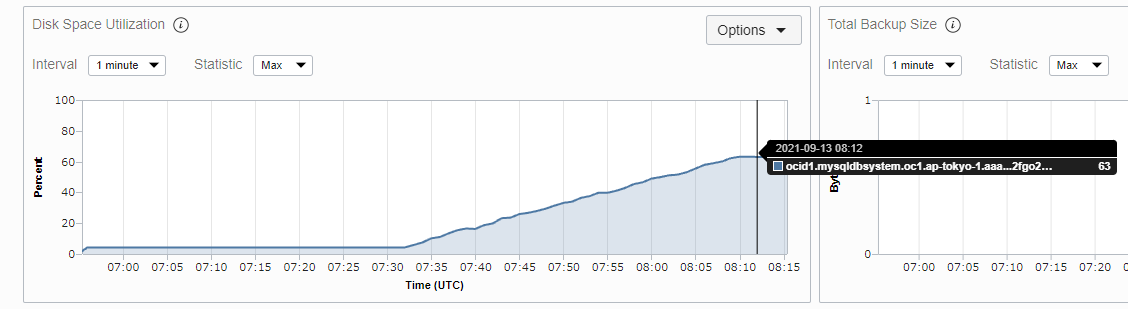
実際にMDS内で確認した結果は下記になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mysql> show variables like 'health%'; +----------------------------------------------+-------+ | Variable_name | Value | +----------------------------------------------+-------+ | health_monitor.disk_fallback_enable | ON | | health_monitor.disk_low_space_critical_level | 2000 | | health_monitor.disk_low_space_duration | 300 | | health_monitor.disk_low_space_level | 5000 | | health_monitor.disk_low_space_percent | 4 | | health_monitor.disk_monitored | /db | | health_monitor.disk_retention | 86400 | | health_monitor.disk_running | ON | | health_monitor.disk_sample_rate | 60 | | health_monitor.disk_usage_warning_level_1 | 20 | | health_monitor.disk_usage_warning_level_2 | 10 | | health_monitor.disk_usage_warning_level_3 | 5 | | health_monitor.status_interval | 10 | +----------------------------------------------+-------+ |
データ量を増やして、コマンドラインから使用可能なディスク容量の確認してみます。
パフォーマンススキーマのhealth_block_deviceテーブル内にモニタリングで蓄積されたデータがありますので、下記のようにSELECT文を実行することで確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
mysql> select * from performance_schema.health_block_device; +-------------------------+---------------------+-------------+-----------------+-------------+-------------+ | DEVICE | TIMESTAMP | TOTAL_BYTES | AVAILABLE_BYTES | USE_PERCENT | MOUNT_POINT | +-------------------------+---------------------+-------------+-----------------+-------------+-------------+ | /dev/mapper/vg_db-lv_db | 2021-09-13 06:55:12 | 53656686592 | 51364196352 | 4.27 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 06:56:11 | 53656686592 | 51364315136 | 4.27 | /db | ※省略 以下テスト用データ投入 | /dev/mapper/vg_db-lv_db | 2021-09-13 07:33:11 | 53656686592 | 49899388928 | 7.00 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:34:11 | 53656686592 | 49411915776 | 7.91 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:35:11 | 53656686592 | 48131448832 | 10.30 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:36:12 | 53656686592 | 47518904320 | 11.44 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:37:11 | 53656686592 | 46370197504 | 13.58 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:38:11 | 53656686592 | 45489344512 | 15.22 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:39:11 | 53656686592 | 45183672320 | 15.79 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:40:11 | 53656686592 | 44701261824 | 16.69 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:41:11 | 53656686592 | 43489107968 | 18.95 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:42:11 | 53656686592 | 42612322304 | 20.58 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:43:11 | 53656686592 | 41056563200 | 23.48 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:44:11 | 53656686592 | 40928518144 | 23.72 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:45:11 | 53656686592 | 39640866816 | 26.12 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 07:46:11 | 53656686592 | 39028322304 | 27.26 | /db | ※省略 | /dev/mapper/vg_db-lv_db | 2021-09-13 08:08:11 | 53656686592 | 21046263808 | 60.78 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 08:09:11 | 53656686592 | 20318846976 | 62.13 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 08:10:11 | 53656686592 | 19952418816 | 62.81 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 08:11:11 | 53656686592 | 19852734464 | 63.00 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 08:12:12 | 53656686592 | 19852734464 | 63.00 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 08:13:11 | 53656686592 | 19852734464 | 63.00 | /db | | /dev/mapper/vg_db-lv_db | 2021-09-13 08:14:11 | 53656686592 | 19852734464 | 63.00 | /db | +-------------------------+---------------------+-------------+-----------------+-------------+-------------+ 80 rows in set (0.00 sec) |
モニタリング拡張で追加された[Disk Space Utilization]と同じ内容でした。
またヘルスモニターでの警告とエラーはperformance_schema.error_logテーブルに記録されます。
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM performance_schema.error_log WHERE SUBSYSTEM='Health'\G ※省略 *************************** 70. row *************************** LOGGED: 2021-09-13 08:24:12.000188 THREAD_ID: 0 PRIO: Note ERROR_CODE: MY-013694 SUBSYSTEM: Health DATA: Disk Collector: RUNNING: mount point='/db', available=18.5G, total=50.0G, used=63.0%, low limit=2.0G, critical=2.0G, warnings=11.6G/6.8G/4.4G 70 rows in set (0.00 sec) |
試しにテストデータを増やしてみたところavailableが11.6Gを下回ったところでワーニングが出力されました。
|
1 2 3 4 5 6 7 8 |
*************************** 316. row *************************** LOGGED: 2021-09-15 01:20:12.000153 THREAD_ID: 0 PRIO: Warning ERROR_CODE: MY-013695 SUBSYSTEM: Health DATA: Disk Collector: WARNING LEVEL 1 (11.6G): mount point='/db', available=10.6G, total=50.0G, used=78.8%, low limit=2.0G, critical=2.0G, warnings=11.6G/6.8G/4.4G *************************** 317. row *************************** |
さらに続けてavailableが6.8G,4.4Gを下回るとワーニングレベルが上がっていき、最終的に2Gを下回るとクリティカルとなりOFFLINE_MODEとなりました。
OFFLINE_MODEとなるとCONNECTION_ADMIN特権を持たないクライアントユーザーを切断し、以降のアクセスをブロックします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
*************************** 319. row *************************** LOGGED: 2021-09-15 01:40:12.000222 THREAD_ID: 0 PRIO: Warning ERROR_CODE: MY-013695 SUBSYSTEM: Health DATA: Disk Collector: WARNING LEVEL 2 (6.8G): mount point='/db', available=6.8G, total=50.0G, used=86.5%, low limit=2.0G, critical=2.0G, warnings=11.6G/6.8G/4.4G *************************** 320. row *************************** LOGGED: 2021-09-15 01:43:12.000169 THREAD_ID: 0 PRIO: Warning ERROR_CODE: MY-013695 SUBSYSTEM: Health DATA: Disk Collector: WARNING LEVEL 3 (4.4G): mount point='/db', available=4.0G, total=50.0G, used=92.0%, low limit=2.0G, critical=2.0G, warnings=11.6G/6.8G/4.4G *************************** 321. row *************************** LOGGED: 2021-09-15 01:46:12.001796 THREAD_ID: 0 PRIO: Warning ERROR_CODE: MY-013695 SUBSYSTEM: Health DATA: Disk Collector: CRITICAL LEVEL (2.0G): OFFLINE_MODE=ON: mount point='/db', available=1.5G, total=50.0G, used=97.0%, low limit=2.0G, critical=2.0G, warnings=11.6G/6.8G/4.4G |
この状態になってしまうとテストデータを削除しても、システムの再起動をするまでOFFLINE_MODEが解除されないため注意が必要です。
なお、データ投入後一定時間経過すると不要なログデータ等が削除されているのか、ディスク使用量が減少します。
その状態であれば、SUPER_READ_ONLYが解除されデータを消すことが出来ましたが、使用量が減らないとデータを消すことも出来ませんのでくれぐれもご注意ください。
まとめ
本記事作成時点(2021年9月15日)では、MDSのストレージを動的に増やすことが出来ません。
より大容量のストレージが必要となった場合、今年6月から利用出来るようになったバックアップからストレージサイズを増やして新しく起動させるか、新規に起動させたMDSにデータを移行するといった手順が必要です。
そのため、現状ではMDSのストレージ管理は非常に重要となっています。
今回モニタリングで拡張された ディスク領域使用率(Disk Space Utilization)メトリックを利用し、アラーム設定をして備えておく事が良いかと思います。
アラーム設定等の通知に関しては、以前の記事MySQL Database Service のイベントを通知してみるにて触れておりますので、ご覧いただけたらと思います。