はじめに
MySQL InnoDB ClusterをAWS上で稼働させた場合に、同AZで稼働させる場合と、DRの観点から異なるAZで稼働させた場合の動きをみたくて試してみました。
切り替わり時の挙動確認が目的のため、データサイズやワークロードについては一切考慮しておりませんのでご容赦ください。
環境構築については下記の記事とほぼ同様の設定をしております。
MySQL 8.0.13 で MySQL InnoDB Cluster を構築する
*異なるサブネット(AZ)でClusterを構築する際には別途オプションが必要となりますので、そちらは下部に記載しております。
環境
| – | info |
|---|---|
| OS | CentOS Linux release 7.5.1804 (Core) |
| MySQL | 8.0.13 MySQL Community Server – GPL |
| EC2 TYPE | t2.micro |
同じAZ
まずは全て同一のAZ(1a)で実行してみました。
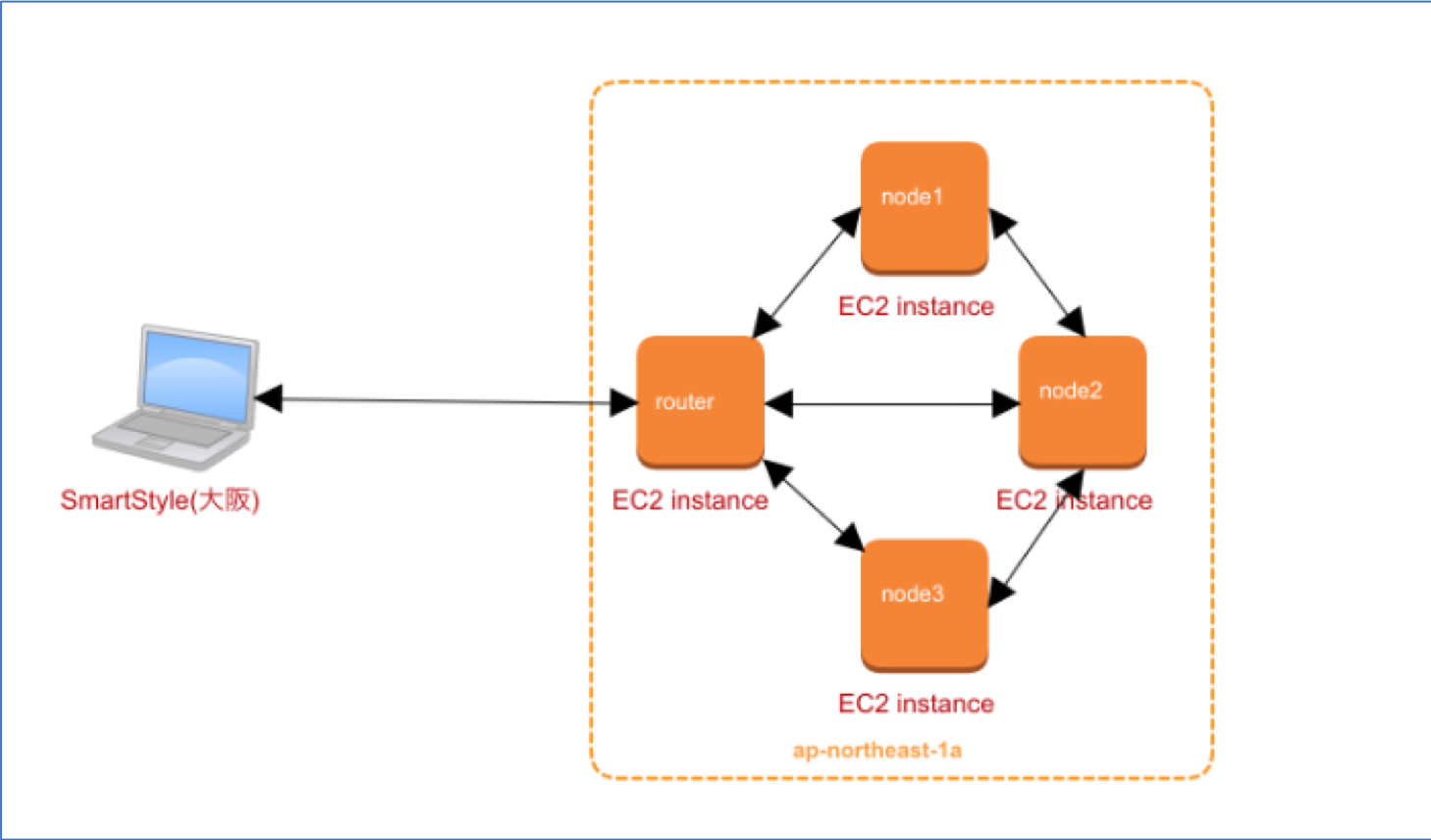
構成
| マシン | IP |
|---|---|
| node1 | 172.26.100.7 |
| node2 | 172.26.100.95 |
| node3 | 172.26.100.112 |
| router(shell) | 172.26.100.117 |
テーブル作成
定期的(1秒間隔)にPrimaryへ書き込みを行い、切り替わりまでの時間を見るため、テスト用のテーブルを作成します。
|
1 |
(root@ec2node1) [ss]> create table t1(id int auto_increment primary key,created_at datetime); |
書き込み開始
下記のようなスクリプトを用意して書き込み実施します。
|
1 2 3 4 5 |
while true do mysql --user=root --password=Password1! -hec2node1 -P6446 ss --execute="INSERT INTO t1 (created_at) VALUES (NOW())" sleep 1 done; |
PrimaryのMySQLサーバーをダウンさせて擬似的に障害状態に
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
MySQL 172.26.100.7:33060+ ssl JS > cluster.status() { "clusterName": "mycluster", "defaultReplicaSet": { "name": "default", "primary": "172.26.100.7:3306", "ssl": "REQUIRED", "status": "OK", "statusText": "Cluster is ONLINE and can tolerate up to ONE failure.", "topology": { "172.26.100.112:3306": { "address": "172.26.100.112:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "ONLINE" }, "172.26.100.7:3306": { "address": "172.26.100.7:3306", "mode": "R/W", "readReplicas": {}, "role": "HA", "status": "ONLINE" }, "172.26.100.95:3306": { "address": "172.26.100.95:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "ONLINE" } } }, "groupInformationSourceMember": "mysql://rpl_user@172.26.100.7:3306" } |
node1のmysqldを停止
|
1 |
mysqladmin shutdown -uroot -pPassword1! |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
MySQL 172.26.100.95:33060+ ssl JS > cluster.status() { "clusterName": "mycluster", "defaultReplicaSet": { "name": "default", "primary": "172.26.100.112:3306", "ssl": "REQUIRED", "status": "OK_NO_TOLERANCE", "statusText": "Cluster is NOT tolerant to any failures. 1 member is not active", "topology": { "172.26.100.112:3306": { "address": "172.26.100.112:3306", "mode": "R/W", "readReplicas": {}, "role": "HA", "status": "ONLINE" }, "172.26.100.7:3306": { "address": "172.26.100.7:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "(MISSING)" }, "172.26.100.95:3306": { "address": "172.26.100.95:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "ONLINE" } } }, "groupInformationSourceMember": "mysql://rpl_user@172.26.100.112:3306" } |
書き込み結果
|
1 2 3 4 5 6 7 8 9 10 |
| 548 | 2018-12-05 05:46:52 | | 549 | 2018-12-05 05:46:54 | | 550 | 2018-12-05 05:46:55 | #サービス断発生 | 551 | 2018-12-05 05:47:00 | | 552 | 2018-12-05 05:47:01 | | 553 | 2018-12-05 05:47:02 | | 554 | 2018-12-05 05:47:04 | |
5秒で書き込みが再開出来ました。
異なるAZ
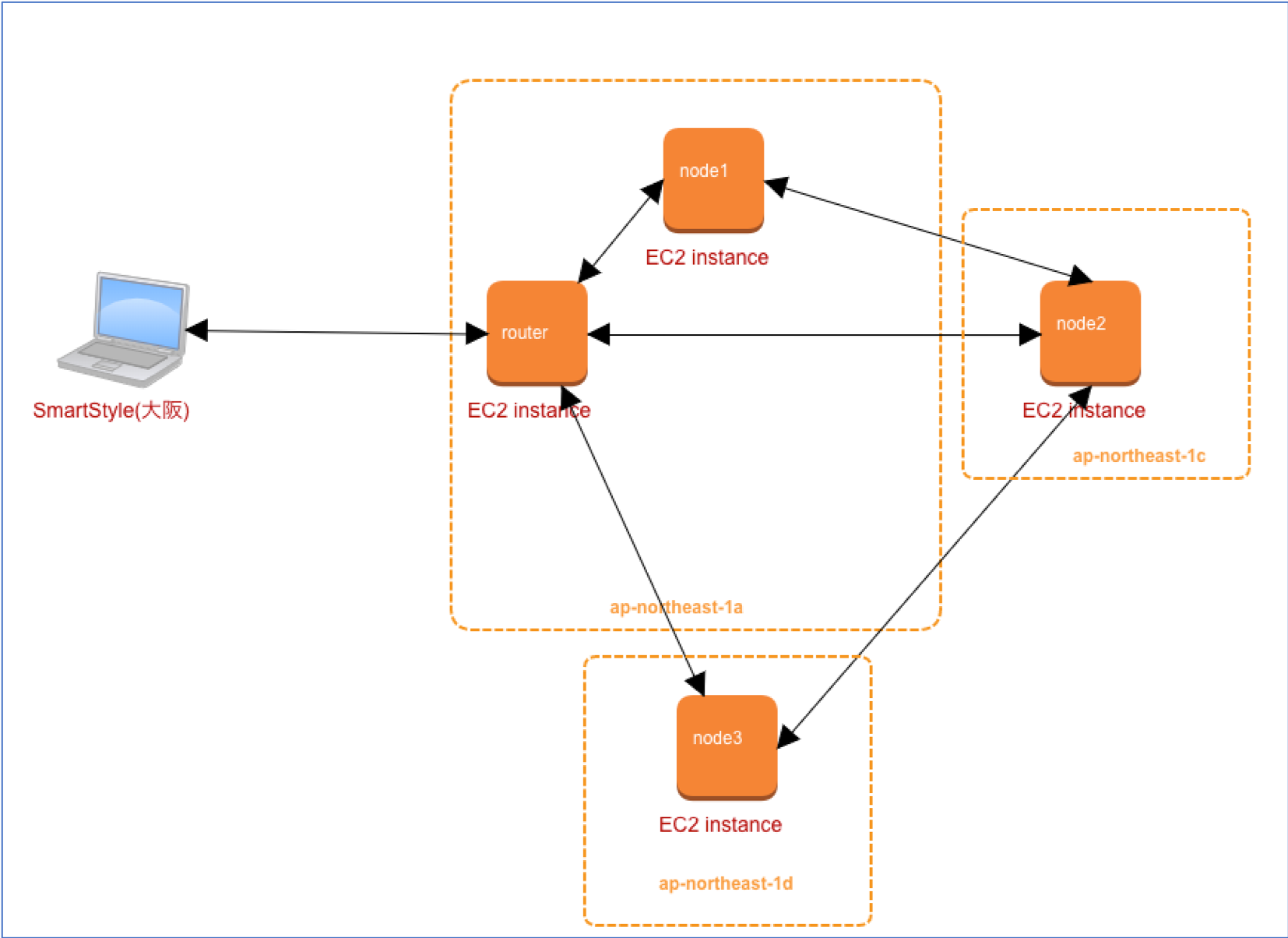
上記の図からRouterと同じAZに所属しているNode1(Primary)を停止させます。
構成
| マシン | IP |
|---|---|
| node1 | 172.26.100.154 |
| node2 | 172.26.101.102 |
| node3 | 172.26.104.254 |
| router(shell) | 172.26.100.210 |
追加手順
構築手順はほとんど同じですが、clusterを作成する際と、clusterにインスタンスを追加する際にWhitelistの追加が必要です。
|
1 2 |
mysql-js> cluster = dba.createCluster('myCluster', {ipWhitelist:'172.26.0.0/16,127.0.0.1/8'}); mysql-js> cluster.addInstance('rpl_user@追加するインスタンスIPアドレス', {ipWhitelist:'172.26.0.0/16,127.0.0.1/8'}); |
PrimaryのMySQLサーバーをダウンさせて擬似的に障害状態に
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
MySQL 172.26.100.154:33060+ ssl JS > cluster.status() { "clusterName": "myCluster", "defaultReplicaSet": { "name": "default", "primary": "172.26.100.154:3306", "ssl": "REQUIRED", "status": "OK", "statusText": "Cluster is ONLINE and can tolerate up to ONE failure.", "topology": { "172.26.100.154:3306": { "address": "172.26.100.154:3306", "mode": "R/W", "readReplicas": {}, "role": "HA", "status": "ONLINE" }, "172.26.101.102:3306": { "address": "172.26.101.102:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "ONLINE" }, "172.26.104.254:3306": { "address": "172.26.104.254:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "ONLINE" } } }, "groupInformationSourceMember": "mysql://rpl_user@172.26.100.154:3306" } |
node1のmysqldを停止
|
1 |
mysqladmin shutdown -uroot -pPassword1! |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
MySQL 172.26.101.102:33060+ ssl JS > cluster.status(); { "clusterName": "myCluster", "defaultReplicaSet": { "name": "default", "primary": "172.26.104.254:3306", "ssl": "REQUIRED", "status": "OK_NO_TOLERANCE", "statusText": "Cluster is NOT tolerant to any failures . 1 member is not active", "topology": { "172.26.100.154:3306": { "address": "172.26.100.154:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "(MISSING)" }, "172.26.101.102:3306": { "address": "172.26.101.102:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "ONLINE" }, "172.26.104.254:3306": { "address": "172.26.104.254:3306", "mode": "R/W", "readReplicas": {}, "role": "HA", "status": "ONLINE" } } }, "groupInformationSourceMember": "mysql://rpl_user@172.26.104.254:3306" } |
書き込み結果
node3がPrimaryに昇格しました。
そして、データ書き込み再開は
|
1 2 3 4 5 6 7 8 9 |
| 32 | 2018-12-05 06:55:52 | | 33 | 2018-12-05 06:55:54 | | 34 | 2018-12-05 06:55:55 | #サービス断発生 | 35 | 2018-12-05 06:56:00 | | 36 | 2018-12-05 06:56:01 | | 37 | 2018-12-05 06:56:03 | |
同じAZと変わりなく使用できています!
注意
公式ドキュメントのよくある質問に下記のWarningが記載されています。
|
1 2 3 4 5 6 7 |
Can I deploy Group Replication across wide-area networks? Yes, but the network connection between each member must be reliable and have suitable perfomance. Low latency, high bandwidth network connections are a requirement for optimal performance. If network bandwidth alone is an issue, then Section 18.10.7.2, “Message Compression” can be used to lower the bandwidth required. However, if the network drops packets, leading to re-transmissions and higher end-to-end latency, throughput and latency are both negatively affected. Warning When the network round-trip time (RTT) between any group members is 2 seconds or more you could encounter problems as the built-in failure detection mechanism could be incorrectly triggered. |
グループメンバー間のレイテンシーには十分注意してください。
ちなみに今回AZを跨いでrouterからそれぞれのnodeに対してPingで確認した結果は下記でした。
|
1 2 3 4 5 6 7 8 9 10 11 |
--- 172.26.100.154 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 9000ms rtt min/avg/max/mdev = 0.392/0.482/0.647/0.072 ms --- 172.26.101.102 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 9014ms rtt min/avg/max/mdev = 2.646/2.782/3.576/0.277 ms --- 172.26.104.254 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 9014ms rtt min/avg/max/mdev = 1.767/1.824/2.030/0.088 ms |
まとめ
可用性を考え、異なるAZで起動させれるのは嬉しいですね。
また書き込み開始もAZを跨いでも遜色ないところはすごいです。