はじめに
OCIには、音声ファイルからテキストを抽出したりすることができる音声サービスがあります。
2022年2月にリリースされたものの、日本語には対応していなかった為、触る機会もなかったのですが、2024年3月に トランスクリプション・ジョブ で OpenAI の Whisper モデルが使用できるようになったことで、日本語にも対応できるようになりました。
リリースから1年以上経過しましたが、この度、初めて使ってみたので記事にしたいと思います。
音声サービスと日本語対応状況
OCIの音声サービスでは、大きく以下のような4つの機能がありますが、このうち Whisper モデルの登場によって日本語に対応したのは「トランスクリプション・ジョブ」のみとなります。
トランスクリプション・ジョブ
音声ファイル(WAV, MP3, MP4など)をアップロードし、そのファイルから文字起こしを非同期処理で行う。
ライブ文字化の使用
リアルタイムに音声ストリームを受信し、即座にテキストに変換する。
テキストから音声への使用
テキストを合成音声に変換して、ナレーションや読み上げ音声を生成する。
カスタマイズの使用
利用者が特定の単語(固有名詞、専門用語など)を事前に登録することで、音声認識時にその単語の認識精度を高める。
検証前確認
制限確認
トランスクリプション・ジョブで、Whisper モデルを使用する場合の対応ファイル形式、ファイルサイズは以下となります。
- ファイル形式
- AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM
- 最大ファイルサイズ
- 最大2 GB
詳細については、以下のリファレンスをご確認下さい。
検証用ファイル
文字起こしする音声ファイルは、 GitHub上で公開されている音声データセットの Kokoro Speech Dataset より、 芥川龍之介の 仙人 を読み上げる10分弱程の音声ファイルを使用させて頂きます。
トランスクリプション・ジョブを作成する前に、事前に音声ファイルを オブジェクト・ストレージ にアップロードしておく必要がありますので、上記音声ファイルをアップロードしました。
検証
トランスクリプション・ジョブの作成
まずは、コンソール画面の「ナビゲーションメニュー」-「アナリティクスとAI」を押下し、「AIサービス」下の「音声」を押下します。
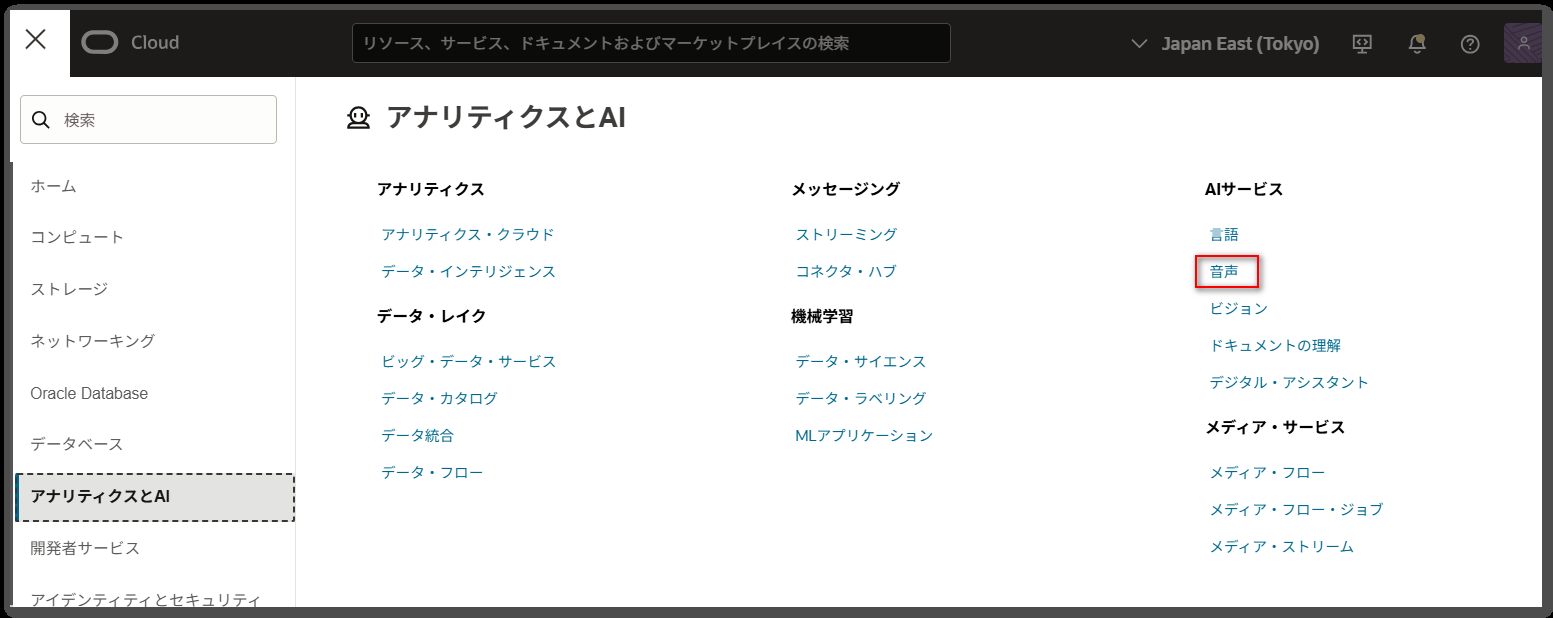
表示された画面の「ジョブの作成」ボタンを押下します。
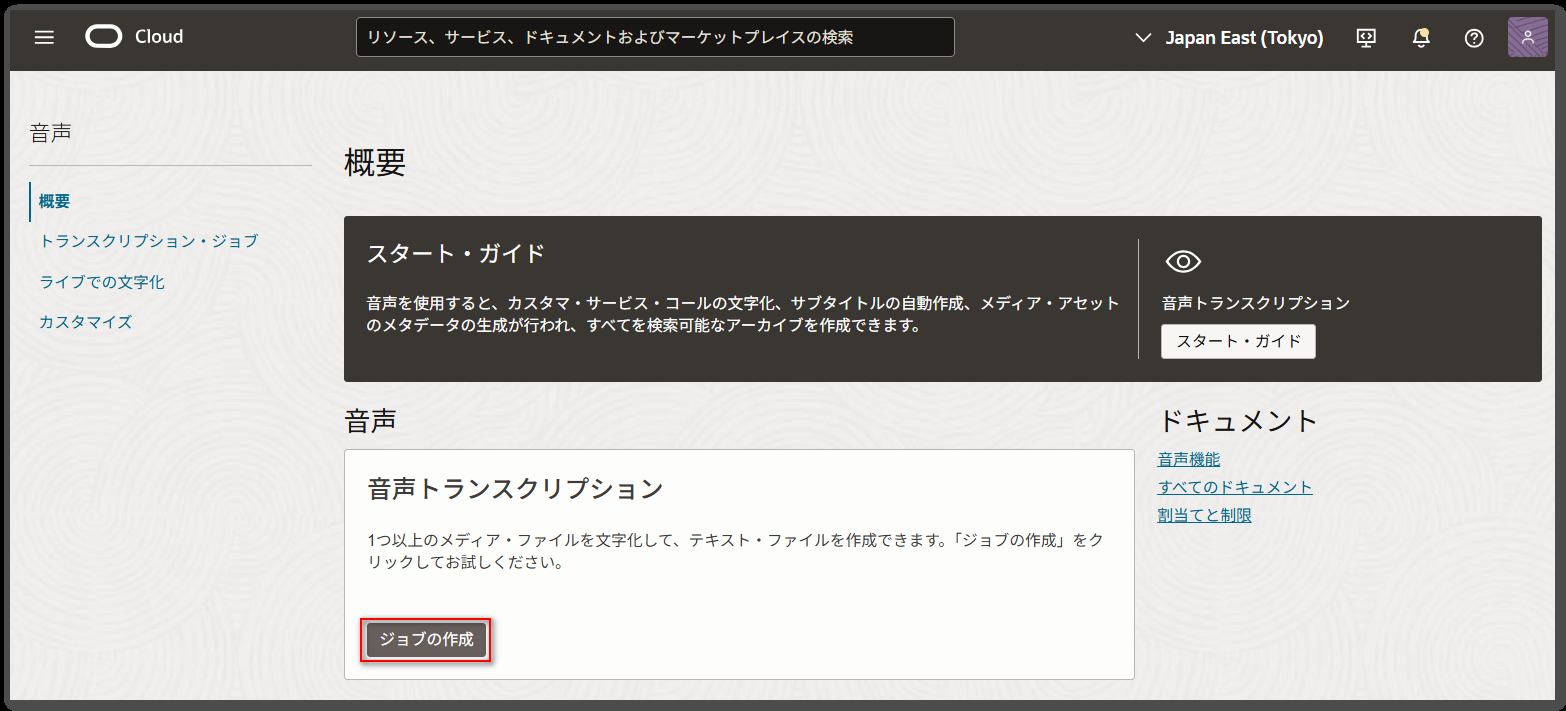
ジョブの作成画面で、必要な情報を入力します。
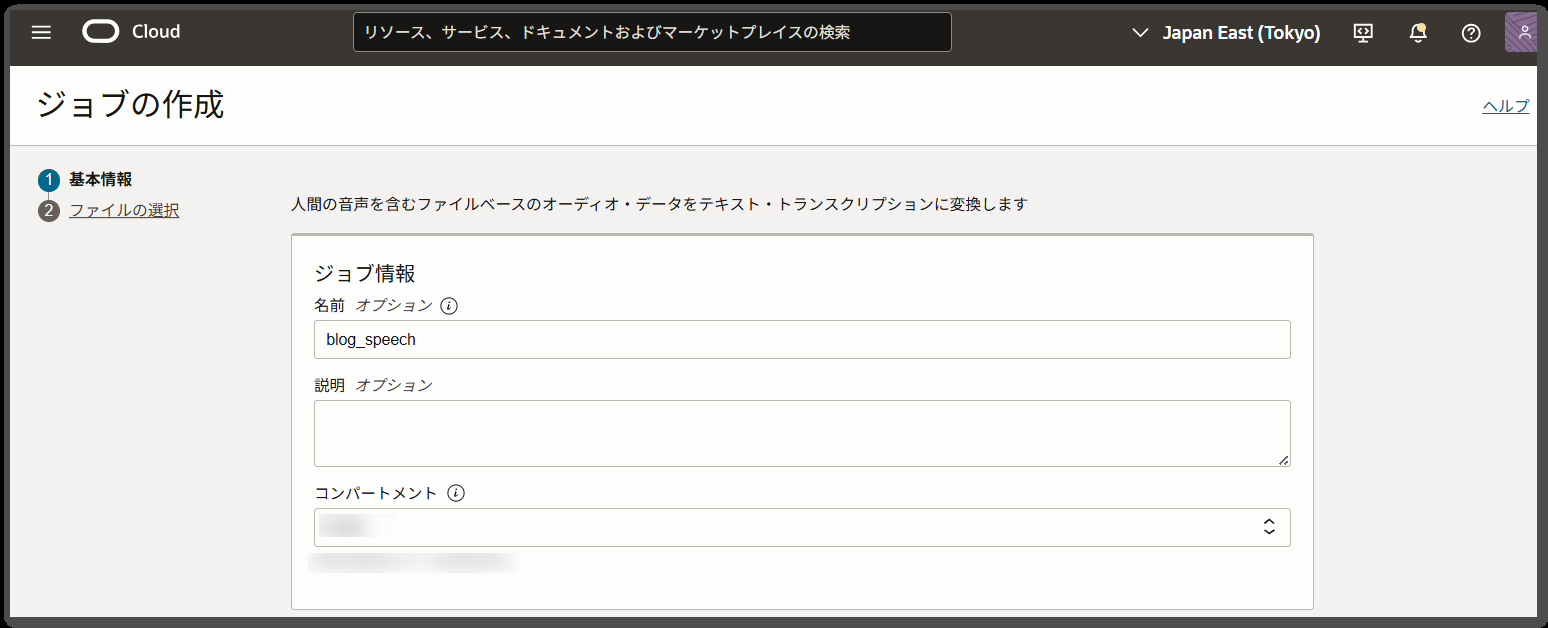
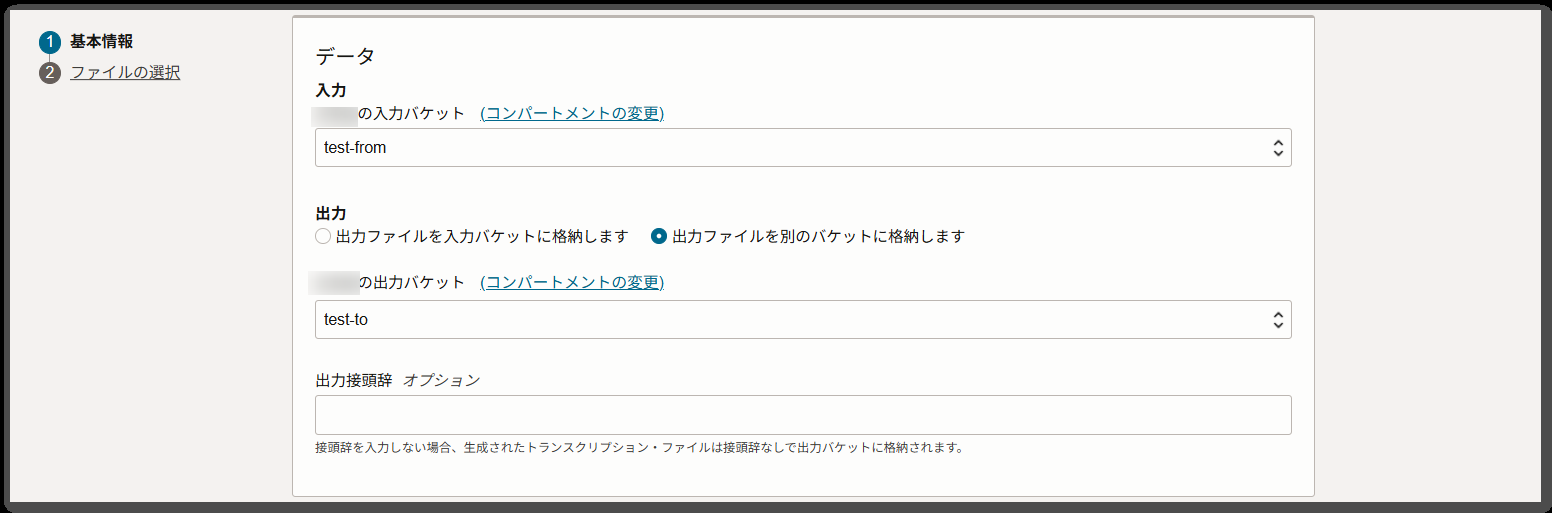
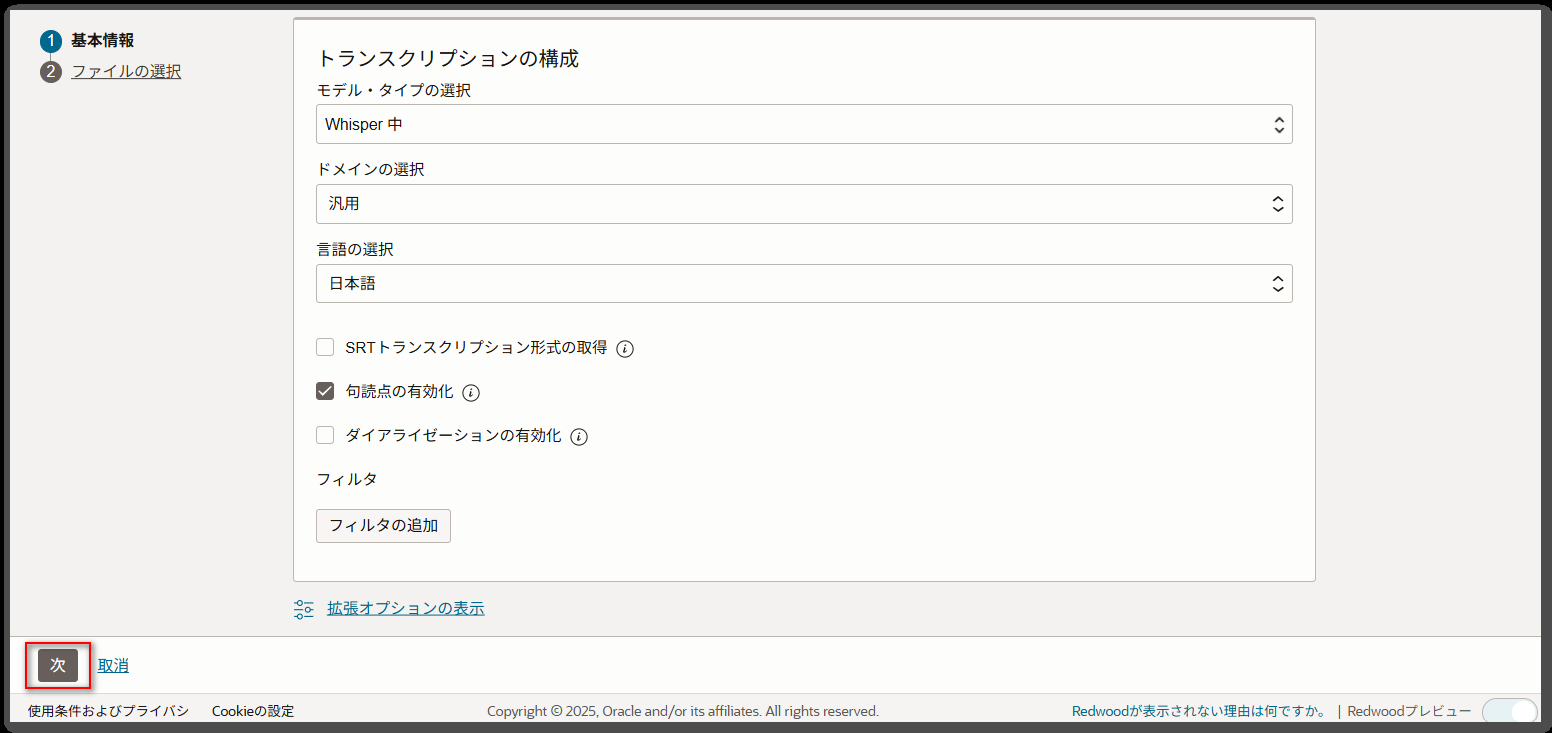
今回は以下のように設定して、「次へ」ボタンを押下します。
| 項目 | 設定 | 備考 |
|---|---|---|
| 名前 | blog_speech | |
| 説明 | 未設定 | |
| コンパートメント | <コンパートメントを選択> | |
| 入力バケット | test-from | |
| 出力 | 「出力ファイルを別のバケットに格納します」を選択 | |
| 出力バケット | test-to | |
| モデル・タイプの選択 | Whisper 中 | Whisper モデルを使用する場合は「Whisper 中」を選択します。 |
| ドメインの選択 | 汎用 | 現時点で「汎用」のみが選択可能となっています。 |
| 言語の選択 | 日本語 | |
| SRTトランスクリプション形式の取得 | 未チェック | これをチェックすると、動画の字幕等に使えるSRT形式のファイルも一緒に作成されますが、今回は未チェックとしています。 |
| 句読点の有効化 | チェック | |
| ダイアライゼーションの有効化 | 未チェック | 複数の話者がいる音声ファイルで、誰が話しているかを自動的に判別する機能ですが、今回は複数の話者がいる訳ではないのでチェックしていません。 |
「ファイルの選択」画面では、アップロードしたファイルを選択して「送信」ボタンを押下します。
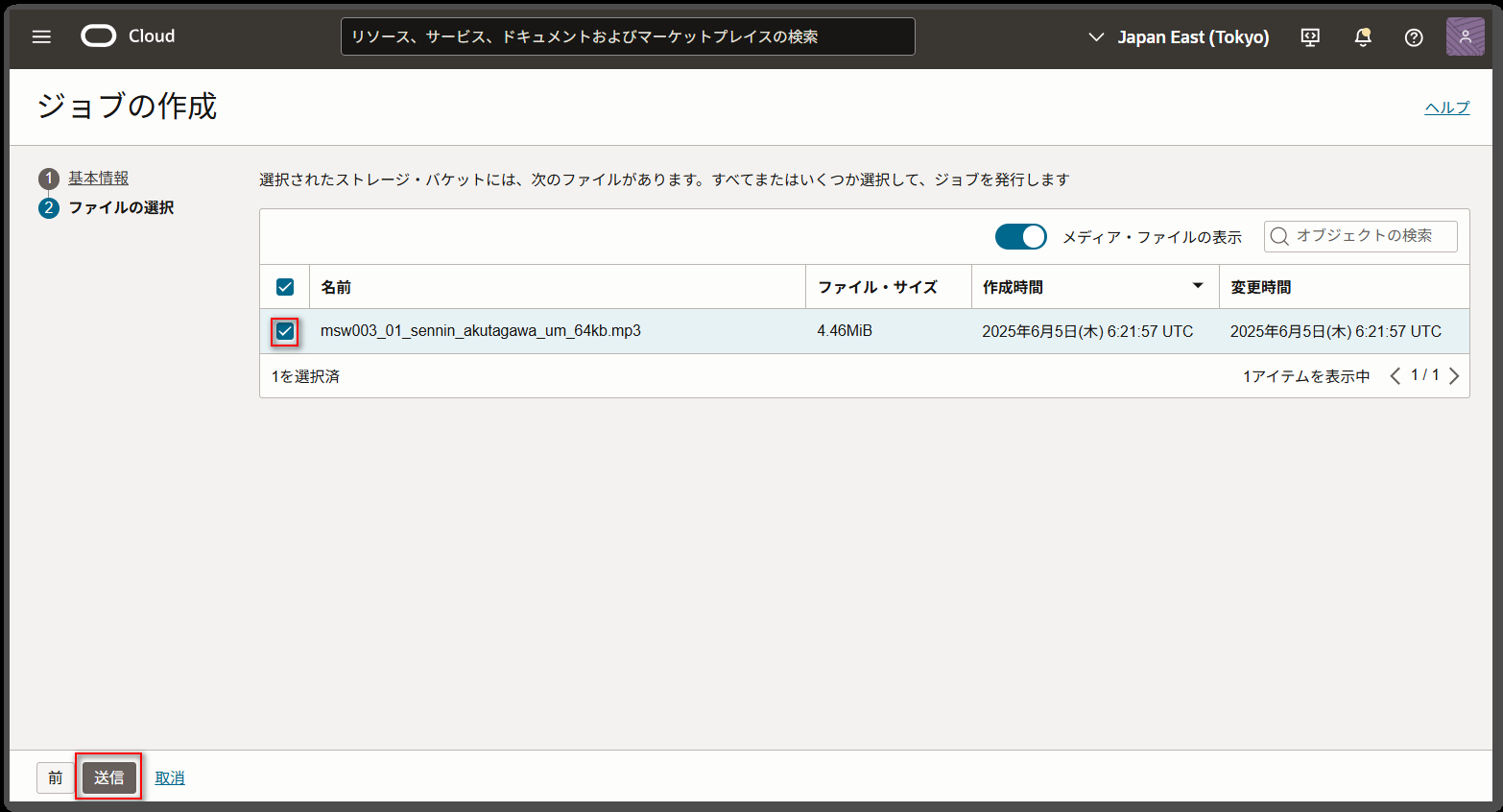
すると、一覧画面に「ステータス」が「受入れ済」として表示されます。
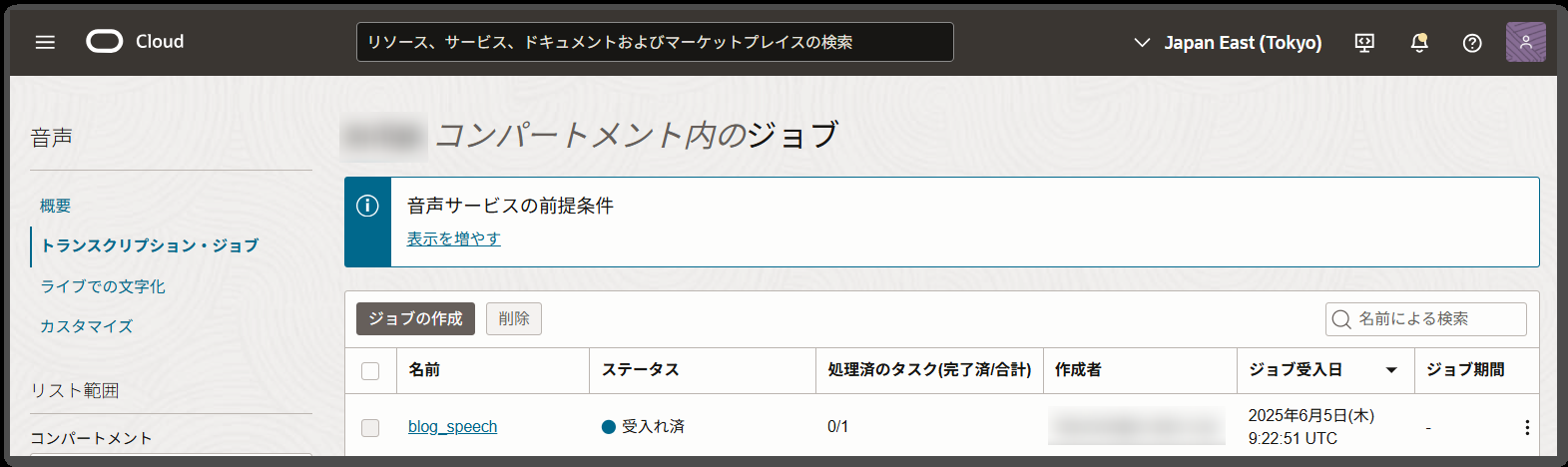
しばらくして、「ステータス」が「成功」となれば処理の完了となります。
10分弱の音声ファイルで、ジョブ期間は1分50秒となっています。
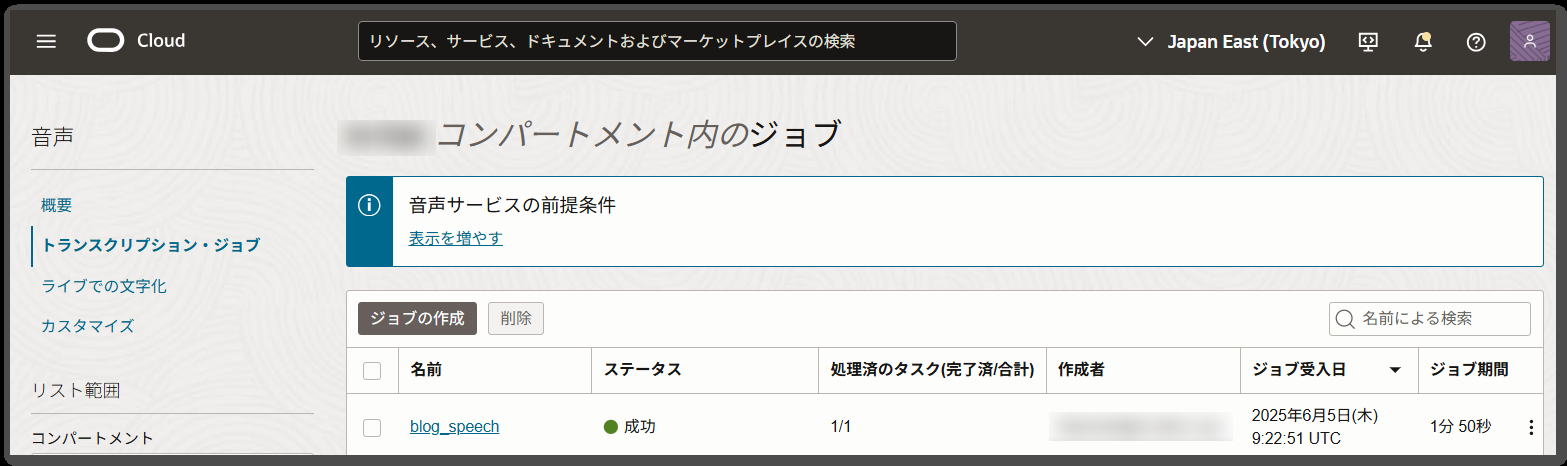
成功後に出力バケットに指定したバケットを見ると、以下のようにジョブに割り当てられた接頭辞のフォルダ内に、JSONファイルが作成されます。
ファイルの確認
作成されたJSONファイルを確認してみます。
実際のファイルは改行がなく見にくいので、jqコマンドで見やすくしたのが以下となります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
{ "status": "SUCCESS", "timeCreated": "2025-06-05 06:35:12.538", "modelDetails": { "domain": "GENERIC", "languageCode": "ja", "modelType": "WHISPER_MEDIUM" }, "audioFormatDetails": { "format": "MP3", "numberOfChannels": 1, "encoding": "MPEG", "sampleRateInHz": 22050 }, "transcriptions": [ { "transcription": "L ib ri V ox. org の ため に 録 音 さ れ ました。 先 人 芥 川 龍 之 介 み な さん、 私 は 今 大 阪 に います。 です から、 大 阪 の 話 を し ましょう。 昔、 大 阪 の 町 へ 方 向 に 来 た 男 は あり ました。 (・・省略)", "confidence": "0.8995", "tokens": [ { "token": "L", "startTime": "0.930s", "endTime": "1.110s", "confidence": "0.0790", "type": "WORD" }, { "token": "ib", "startTime": "1.110s", "endTime": "1.210s", "confidence": "0.7590", "type": "WORD" }, { "token": "ri", "startTime": "1.210s", "endTime": "1.270s", "confidence": "0.9570", "type": "WORD" }, (以下、省略) |
この出力内容の "modelType": "WHISPER_MEDIUM" から、リファレンスに記載が見当たりませんでしたが、Whisper の MEDIUM モデルが使用されていることが予想されます。
また、抽出されたテキストは、 transcriptions->transcription に出力されます。
ここに出力された文字数が多いため、最初の部分をピックアップして以下に記載します。
※冒頭の案内は対象外とし、実際の文字列に改行はありませんが、見やすくするために改行を入れています。
|
1 2 3 4 5 6 7 |
み な さん、 私 は 今 大 阪 に います。 です から、 大 阪 の 話 を し ましょう。 昔、 大 阪 の 町 へ 方 向 に 来 た 男 は あり ました。 名 は 何 と 言 った か わか り ません。 ただ、 飯 滝 方 向 に 来 た 男 です から、 ゴ ン ス ケ と だけ 伝 わ って います。 ご ん す け は、 く ち い れ や の の れ ん を く ぐ る と、 き せ る を く わ えて いた ば ん とう に、 こう く ち の せ や を た の み ました。 ば ん とう さん、 わ た し は、 せ ん に ん にな り たい の だから、 そう いう ところ へ す み こ ませ て ください。 ば ん とう は、 あっ け に と ら れた ように、 し ば ら く は く ち も き か ず に いました。 ば んと う さん、 き こ え ません か? わ た し は、 せ ん に ん にな り たい の だから、 そう いう ところ へ す み こ ませ て ください。 |
実際の読み上げられた内容は、以下にあるので、こちらも同じ部分をピックアップして記載します。
|
1 2 3 4 5 6 7 8 |
皆さん。 私は今大阪にいます、ですから大阪の話をしましょう。 昔、大阪の町へ奉公に来た男がありました。名は何と云ったかわかりません。 ただ飯炊奉公に来た男ですから、権助とだけ伝わっています。 権助は口入れ屋やの暖簾をくぐると、煙管を啣えていた番頭に、こう口の世話を頼みました。 「番頭さん。私は仙人になりたいのだから、そう云う所へ住みこませて下さい。」 番頭は呆気にとられたように、しばらくは口も利かずにいました。 「番頭さん。聞えませんか?私は仙人になりたいのだから、そう云う所へ住みこませて下さい。」 |
どうでしょうか?
まず、最初に気になったのは、ほとんどの文字間に半角スペースが入ってしまってます。
ベースとなる OpenAI の Whisper API を直接使用した場合、このような形式にはなりませんが、OCIの音声サービスで Whisper を使用すると、テキストが細かく分かち書き(トークナイズ)されているように見えます。
この違いは、OCI側で追加のテキスト処理が行われていることが予想されますが、この処理の詳細については、OCIのリファレンスには記載がなく、具体的な仕組みは不明です。
あとは、漢字を正しく認識出来ていない以外は、それなりにテキスト抽出できているようにも思います。
とはいえ、流石にこのままだと、改行もないし見るに堪えないので、OCIの Generative AI を使って、LLMに整形してもらいました。
|
1 2 3 4 5 6 |
みなさん、私は今大阪にいます。ですから、大阪の話をしましょう。 昔、大阪の方角に来た男がありました。名は何といったかわかりません。ただ、飯滝の方角に来た男ですから、ゴンスケとだけ伝わっています。 ゴンスケは、口入れ屋の暖簾をくぐると、煙草をくわえていた番頭に、こう頼みました。 「番頭さん、私は仙人になりたいのですから、そういうところへ住み込ませてください。」 番頭は、あっけにとられたように、しばらく口もきかずにおいでした。 「番頭さん、聞こえませんか?私は仙人になりたいのですから、そういうところへ住み込ませてください。」 |
抽出時点での漢字の誤り「飯炊奉公」→「飯滝の方角」等は、誤ったままですが、かなり実用的に使えそうな感じになったように思います。
ちなみに、整形した際のプログラムはこちらです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import oci import json from langchain_community.chat_models import ChatOCIGenAI from langchain_core.prompts import ChatPromptTemplate llm = ChatOCIGenAI( model_id="cohere.command-a-03-2025", service_endpoint="https://inference.generativeai.ap-osaka-1.oci.oraclecloud.com", compartment_id="ocid1.compartment.oc1..aaaaaaaaXXXXXXXXXXXXXXXXXXXXXX", is_stream=True, model_kwargs={ "temperature": 0, "max_tokens": 4000, "top_p": 0, "top_k": 0, "frequency_penalty": 0, "presence_penalty": 0 } ) prompt = ChatPromptTemplate.from_template( """ 次の文章は音声ファイルからテキスト抽出したもので、漢字に変換できていないケースや漢字に誤りがあるものがあります。 - 間違いなく漢字に誤りがある場合のみ修正して下さい。 - 間違いなく漢字に変換がある場合のみ変換して下さい。 - 上記以外には変更を加えないで下さい。 - 適度に句点、読点、改行を追加して見やすい文章にして下さい。 :\n\n\"\"\"\n{input_text}\n\"\"\"\n\n """ ) chain = prompt | llm config = oci.config.from_file() object_storage = oci.object_storage.ObjectStorageClient(config) response = object_storage.get_object("<namespace>", "test-to", "job-amaaaaaazif6lvyasgd4ggaeuflarpv6t5bxdmdhmth2ot6wq7f2b457qzma/nro5qchj5wtp_test-from_msw003_01_sennin_akutagawa_um_64kb.mp3.json") json_string = response.data.content.decode('utf-8') json_data = json.loads(json_string) raw_text = "" for item in json_data.get("transcriptions", []): raw_text = item.get("transcription") response = chain.invoke({"input_text": raw_text}) print("\nレスポンス:\n", response.content) |
また、Google Colabを使って、OpenAIの Whisper で medium モデルを使って文字起こししたのが、以下となります。
こちらも、最初の部分をピックアップして以下に記載します。
※冒頭の案内は対象外とし、実際の文字列に改行はありませんが、見やすくするために改行を入れています。
|
1 2 3 4 5 6 |
みなさん、私は今大阪にいます。ですから、大阪の話をしましょう。 昔、大阪の町へ方向に来た男はありました。名は何と言ったかわかりません。ただ、飯滝方向に来た男ですから、ゴンスケとだけ伝わっています。 ゴンスケは口入れ屋ののれんをくぐると、木せるを加えていた番頭に、こう口のせやを頼みました。 番頭さん、私は先人になりたいのだから、そういうところへ住み込ませてください。 番頭はあっけに取られたように、しばらくは口も聞かずにいました。 番頭さん、聞こえませんか?私は先人になりたいのだから、そういうところへ住み込ませてください。 |
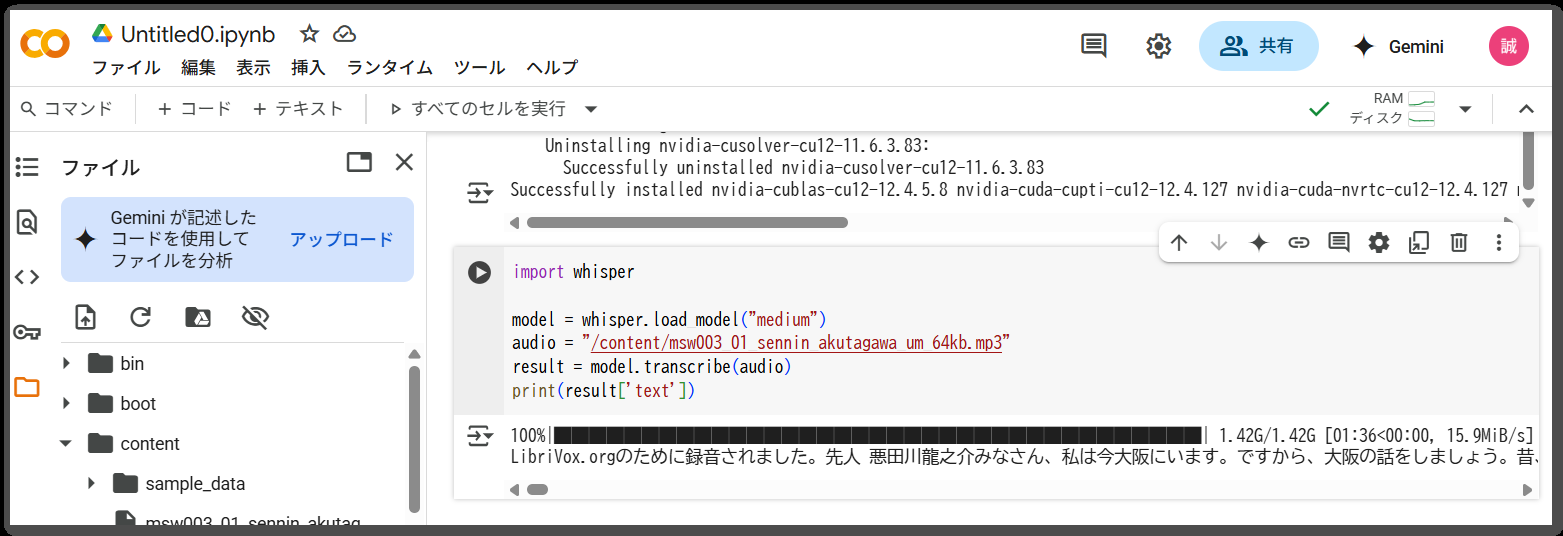
LLMで整形しなくても、ある程度読める文章になっている点から、OpenAIの Whisper から、OCIの音声サービスに乗り換えた場合には、抽出したテキストを整形するという手順が必要になりそうです。
まとめ
OCIの音声サービスで Whisper モデルを使用した場合、漢字の認識に誤りがある場合等はありますが、全体的に高い精度でテキストが抽出されています。
抽出されたテキストは、LLMを使用して整形することで、より読みやすい文章に変換し、実用的なテキストデータとして活用できます。
OCIの音声サービスで、「トランスクリプション・ジョブ」以外の機能にも日本語対応が行われるよう、今後のアップデートに期待したいと思います。