はじめに
本記事では、OCI Data Science サービスとベクトル型に対応した Oracle Database 23ai のマネージドサービスである Oracle Base Database Service 23ai (以下、BaseDB) を活用して RAG (Retrieval-Augmented Generation) 構成を設定・実装する手順について詳しく紹介していきます。RAG構成は、大規模言語モデル(LLM)によるテキスト生成に、外部情報(ベクトル型データベース)の検索を組み合わせることで、従来のLLM(ChatGPTなど)によくある事実に基づかない情報を生成する現象(ハルシネーション)を引き起こす確率を大幅に下げ、回答精度を向上させる技術のことです。近年は、生成AIを用いた企業内データの活用方法としても注目されています。
なお、本記事は、筆者が実際に試行錯誤した結果を元に執筆しており、初心者でも手軽にRAG構成を体験できるように執筆いたしました。手順に従って、手を動かしてRAG構成を体験して頂けると幸いです。また、本記事は2部構成のうちの後編となります。まだ前編をご覧になってない方は、前編からご一読して頂ければ幸いです。
参考:RAG構成とは
関連記事:OCI Data ScienceとOracle Database 23aiで体験するお手軽なRAG構成について(前編)
構成図
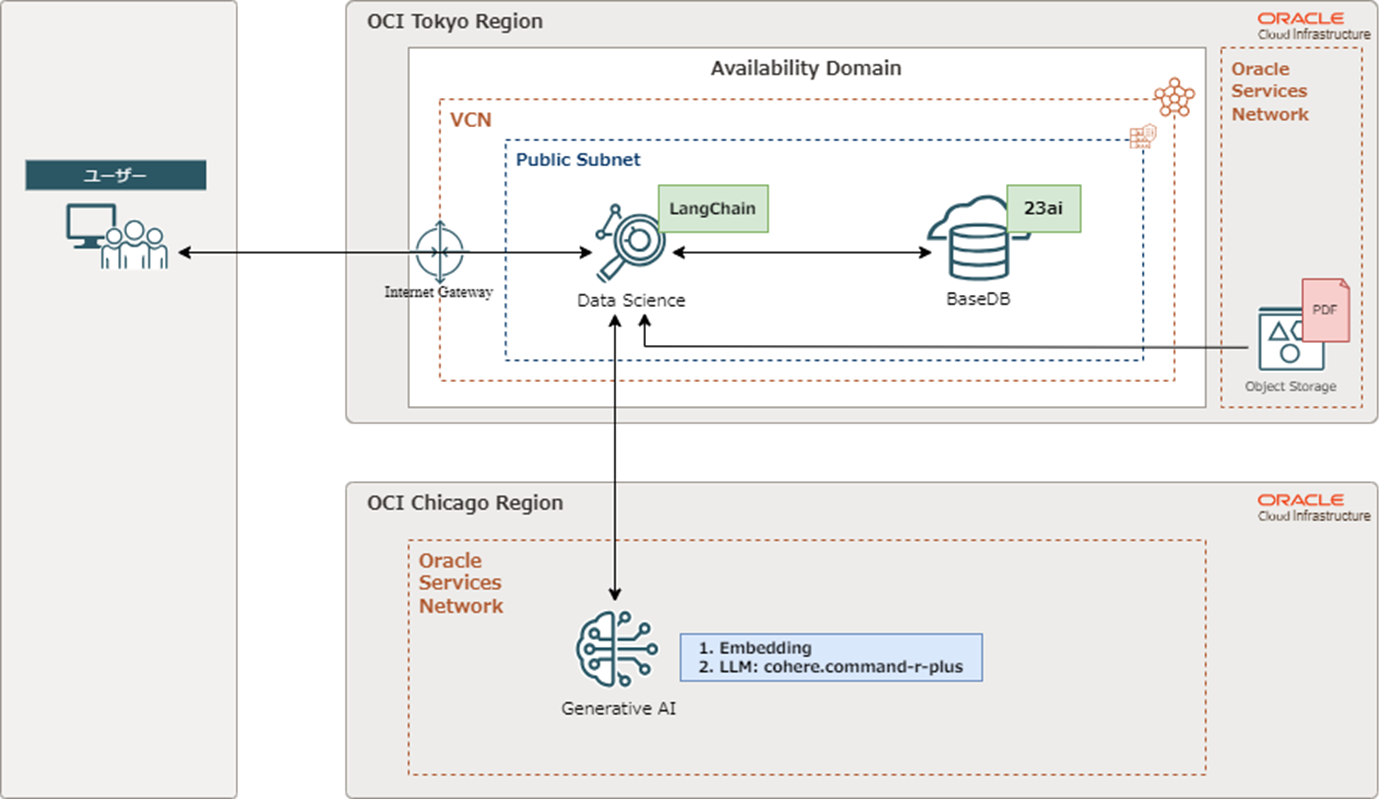
2024年9月時点で、OCI Generative AIサービスを利用できるのは、サンパウロ、フランクフルト、ロンドン、シカゴリージョンのみとなっています。そのため、本記事ではOCI Generative AIサービスを利用するためにシカゴリージョンと東京リージョンを連携することでRAG構成を実現しています。
参考:生成AIを使用するリージョン
前提条件
本記事で紹介する手順の前提条件は以下となります。
- VCNを「インターネット接続性を持つVCNの作成」ウィザードで作成済み
- OCIのユーザ資格情報を取得できる権限をもっていること
- 東京リージョンとシカゴリージョンがサブスクライブされていること
- OCI Data Scienceを作成するにあたる前提条件(ポリシーなど)を満たしていること
参考:OCI Data Science のポリシーの作成
大まかな実施手順
本記事では、大まかに次のステップでRAG構成を実装していきます。なお、ステップ1に関しては、前提条件とさせていただきます。
- OCIの準備:VCNの作成やリージョンのサブスクライブ、各種ポリシーに作成を行います。
- BaseDB 23ai の設定:ベクトルデータ型に対応している BaseDB 23ai を作成し、必要なユーザーと権限を設定します。
- オブジェクト・ストレージの利用:RAG構成で使用するデータ(PDFファイル)をオブジェクト・ストレージにアップロードし、事前認証済みリクエストを設定します。
- OCI Data Scienceプロジェクトの構築:OCI Data Science 内でプロジェクトを作成し、ノートブックセッションを開始します。
- Conda環境と接続情報等の設定:今回の検証で必要になるライブラリなどをインストールし、作業環境を整えます。
- RAG構成の実装:PDFファイルのテキストをロードし、適切なベクトルに変換してデータベースにロードします。その後、プロンプトテンプレートを作成し、モデルを利用して問い合わせを実施します。
- 非RAG構成の実装:非RAG構成でも問い合わせを実施し、RAG構成との回答の精度を比較します。
では、これからそれぞれの手順を詳しく紹介していきます。なお、「4. OCI Data Scienceプロジェクトの構築」までを前編で扱っており、「5. Conda環境と接続情報等の設定」以降を本記事で扱います。また、本記事で利用するPDFファイルやコードに関しては、GitHubからダウンロードすることが出来ます。
関連記事:OCI Data ScienceとOracle Database 23aiで体験するお手軽なRAG構成について(前編)
参考:本記事で利用するPDFファイルおよびコード(GitHub)
RAG構成の環境準備
前編の記事に引き続き、RAG構成を実装する環境準備を行います。
Conda環境とノートブックの環境設定
まず、Conda環境とノートブックの環境設定をしていきます。
- Conda環境を構築するため、Launcherから「Environment Explorer」「Python3(Create Notebook)」「Terminal」(順不同)をクリックします。
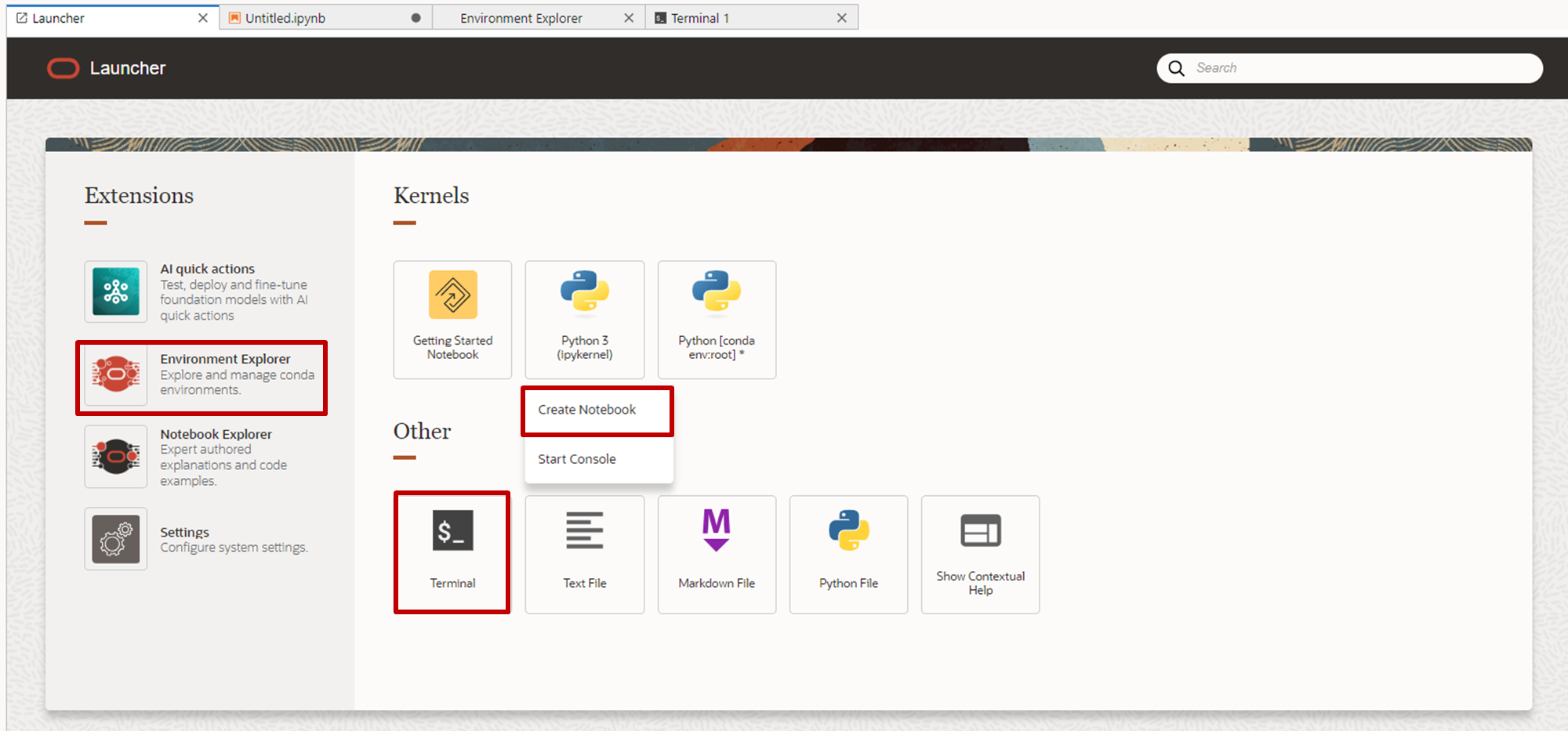
- 「Environment Explorer」タブをクリックし、「AI Forecasting Operator」を見つけ、表示されるコマンドをコピーします。
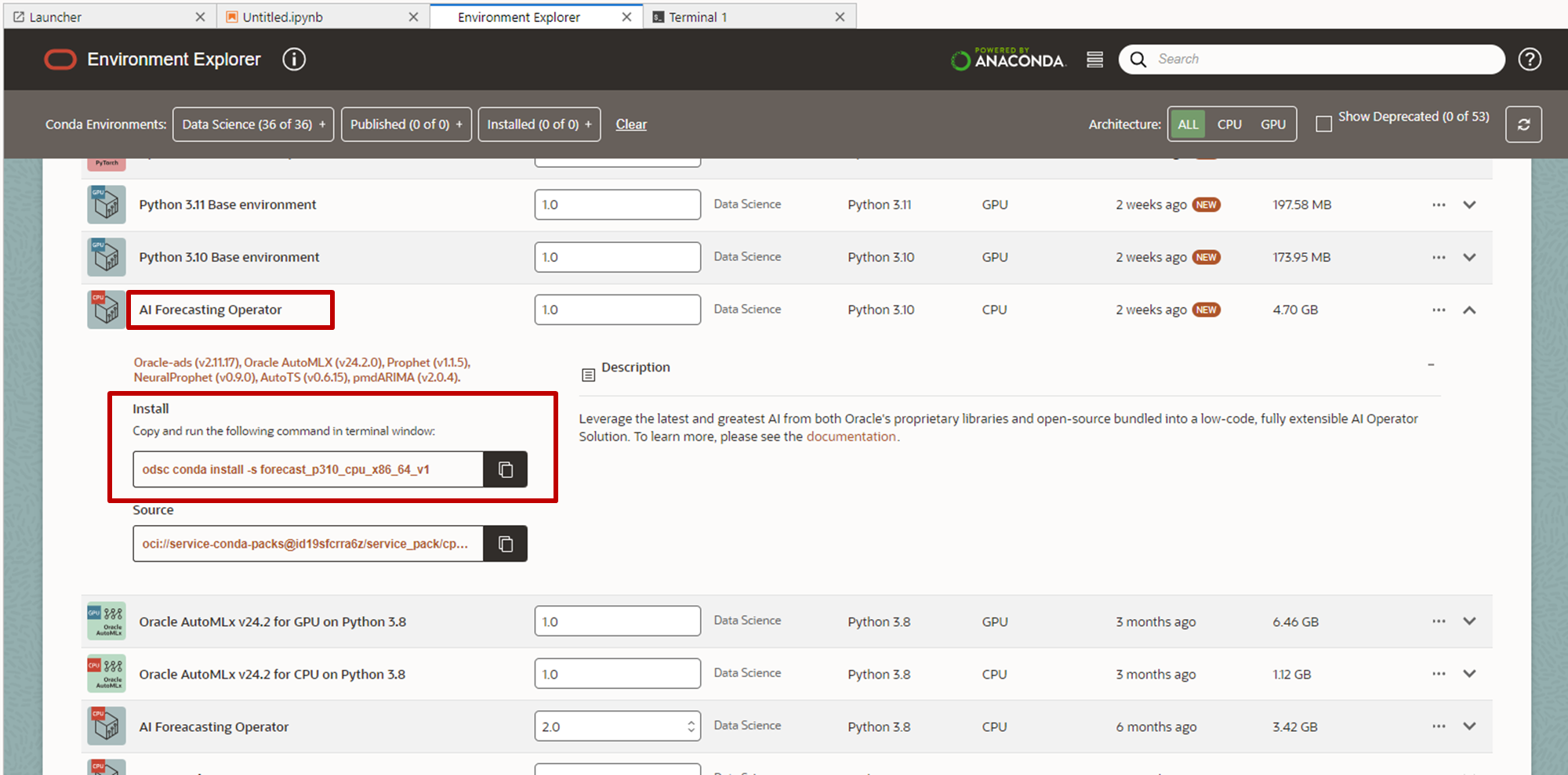
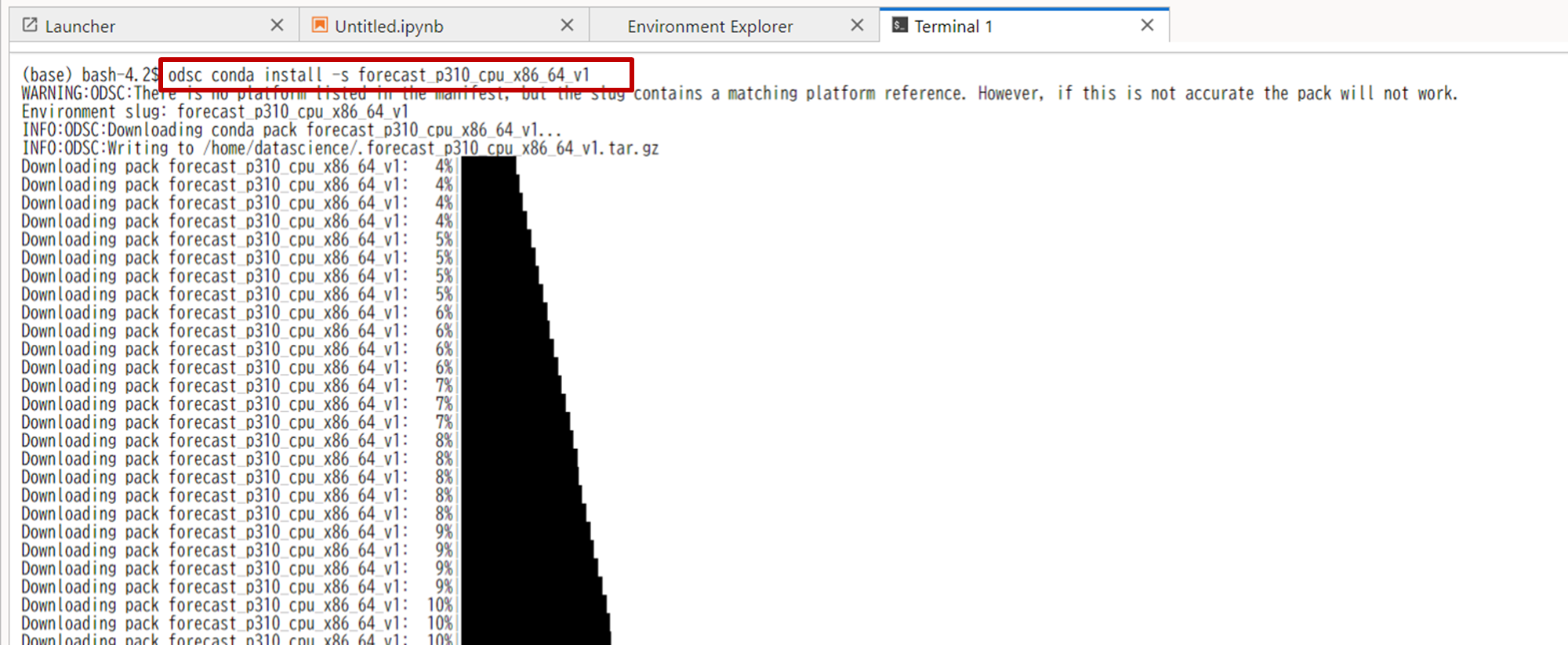
- Terminalタブに移動し、コピーしたコマンドを実行します。完了には15分ほどかかります。
- インストールが完了したことを確認し、「Untitled.ipynb」タブを選択します。右上にある「Python3(ipykernel)」をクリックし、先程インストールしたconda環境を選択します。

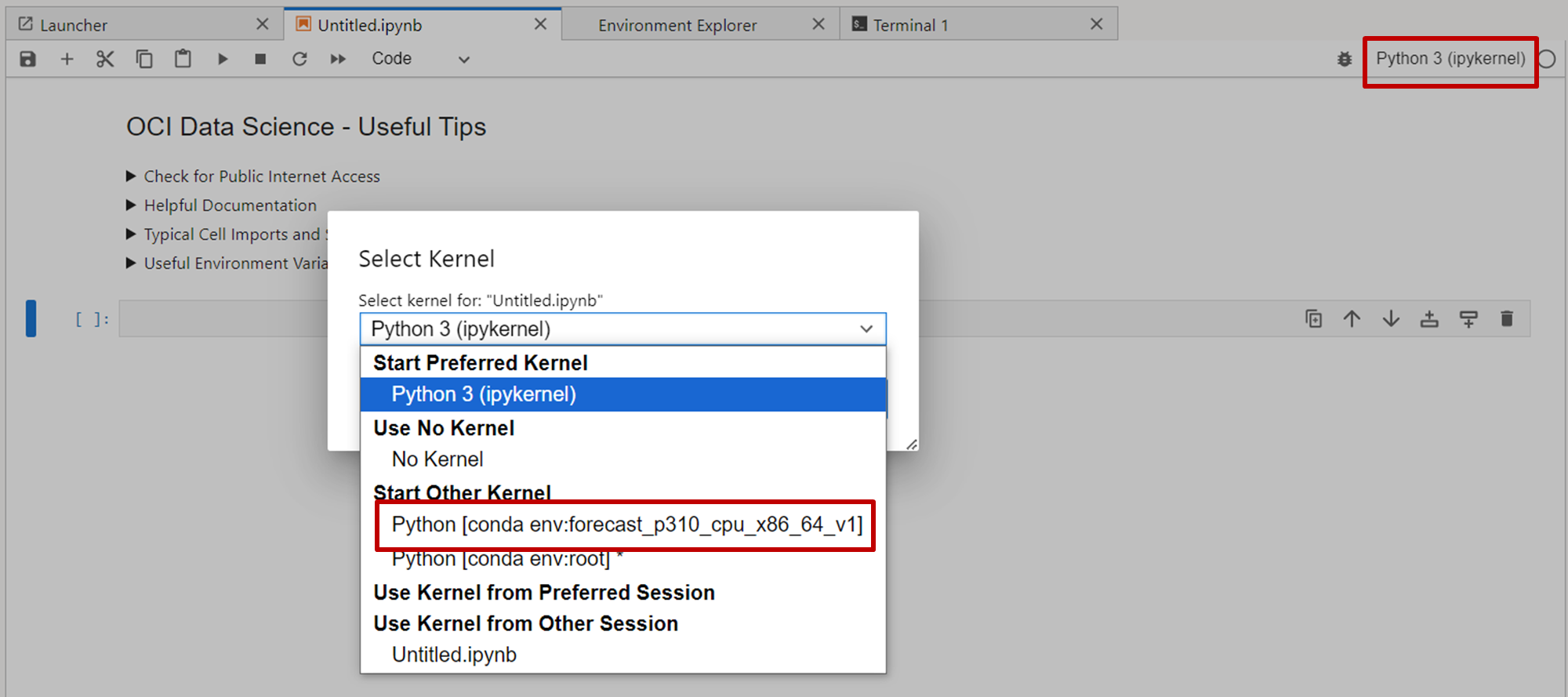
- 「Select」をクリックして、カーネル変更します。
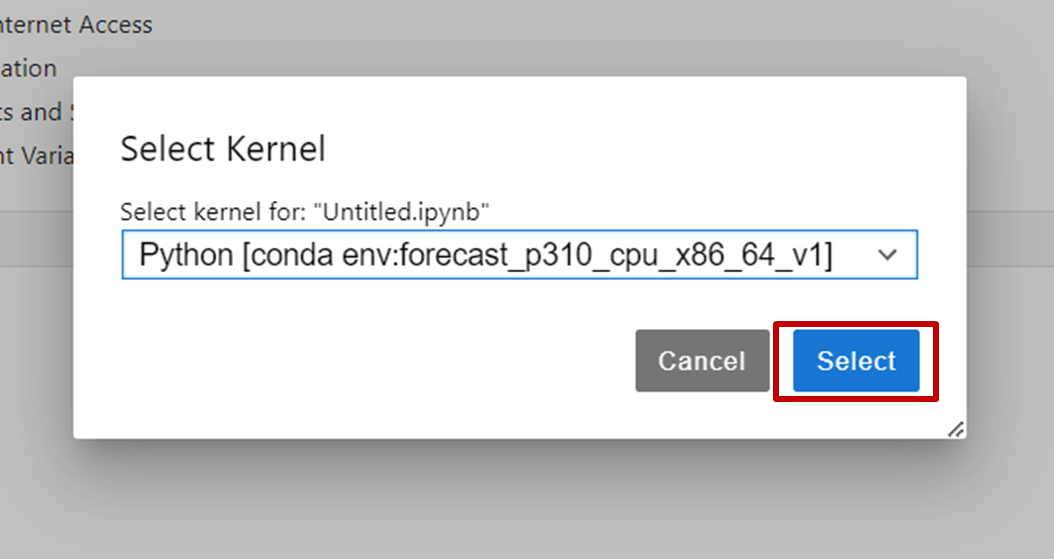
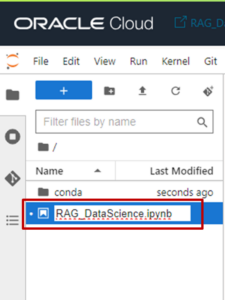
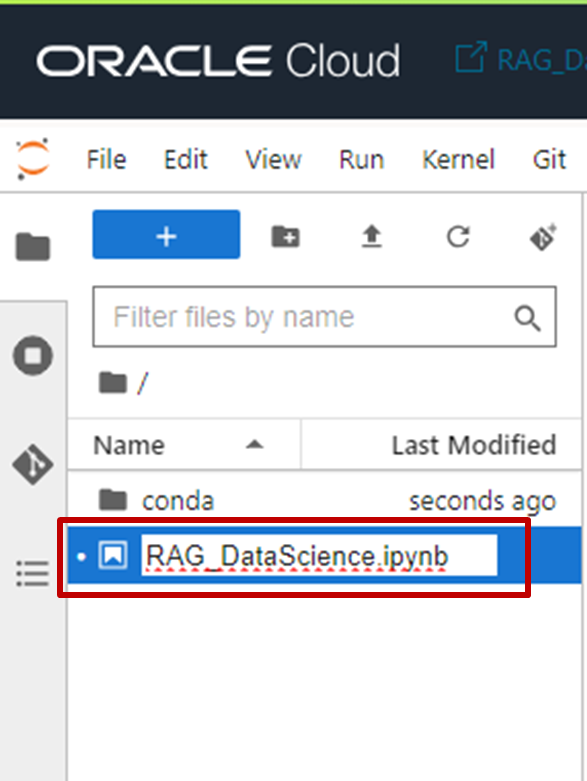
- ノートブックにファイル名を付けて保存(本記事では「RAG_DataScience.ipynb」)します。
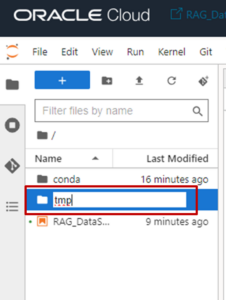
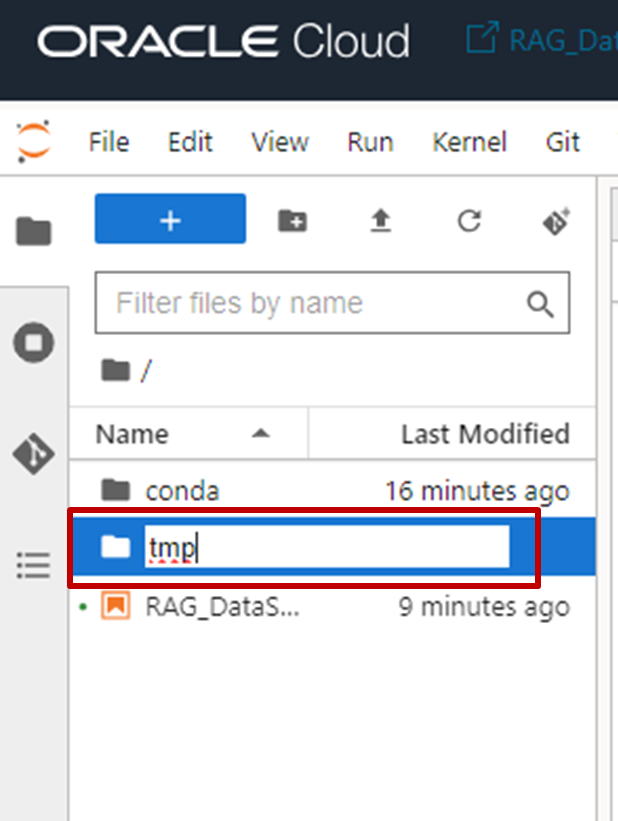
- 今回RAG構成に利用するPDFファイルをノートブック・セッションにインポートするために、tmpフォルダを作成します。
- Terminalタブに移動し、以下のコマンドを実行し、tmpフォルダに今回利用するPDFファイルをインポートします。
12345$ pwd$ cd /home/datascience/tmp$ pwd$ wget <事前認証済リクエストのURL>$ ls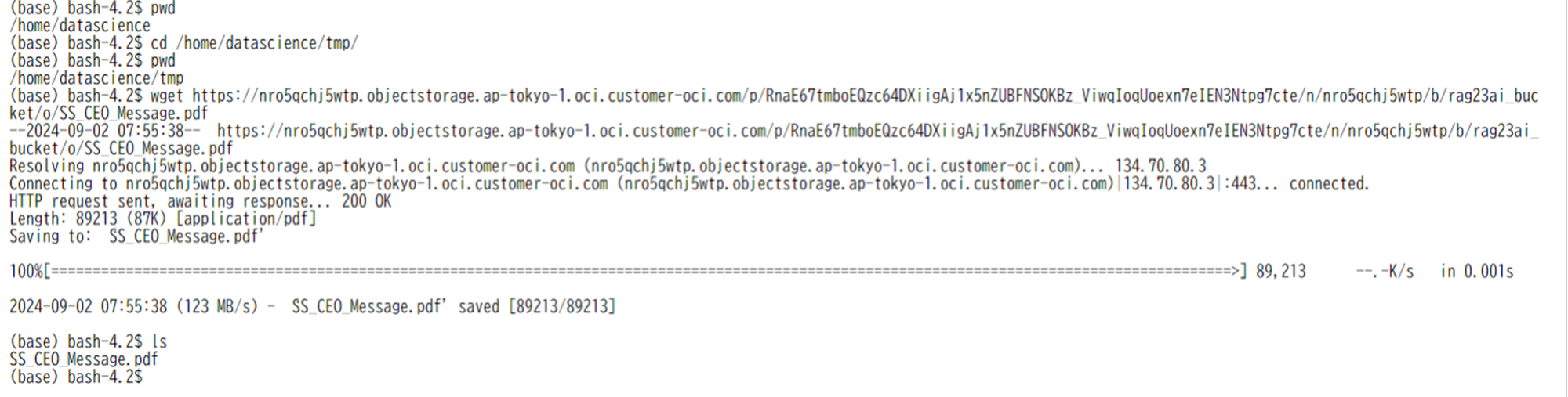
接続情報の設定と確認
次に、ノートブック・セッションとOCIを接続するために各種設定および確認をしていきます。
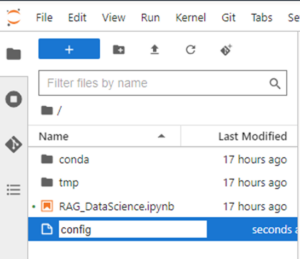
- 左側のペインからconfigファイルをノートブック・セッションに新規作成します。
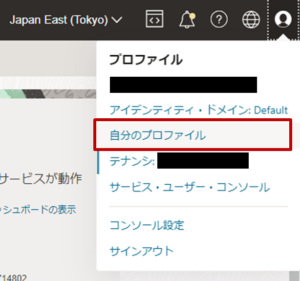
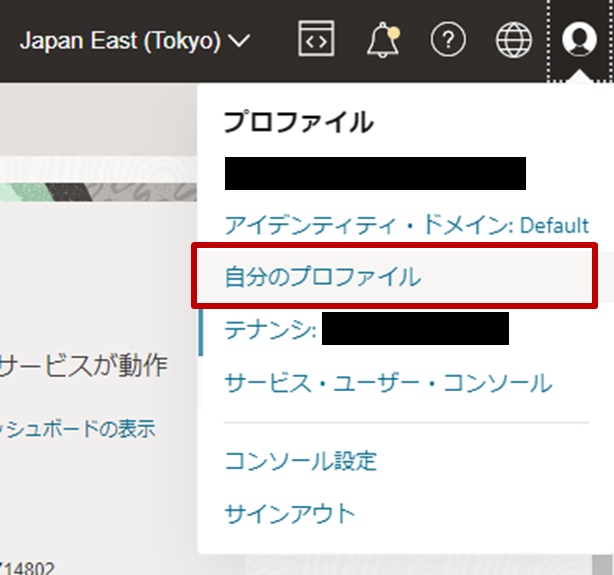
- ユーザ資格情報を取得するために、コンソール画面右上の「プロファイル」から「自分のプロファイル」をクリックします。
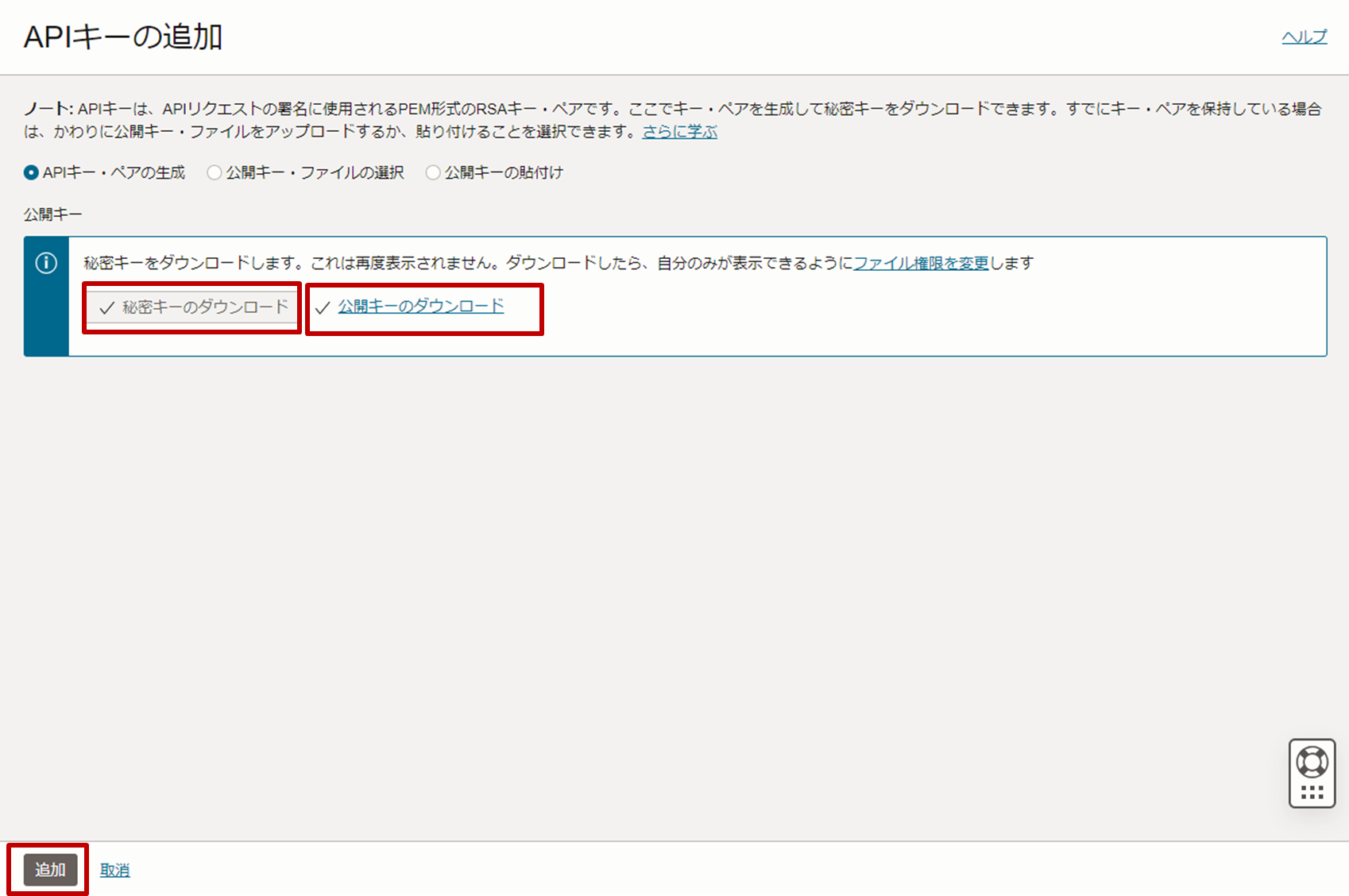
- 左下のリソースペインから「APIキー」をクリックし、「APIキーの追加」をクリックします。

- 秘密鍵と公開鍵をダウンロードし、「追加」をクリックします。
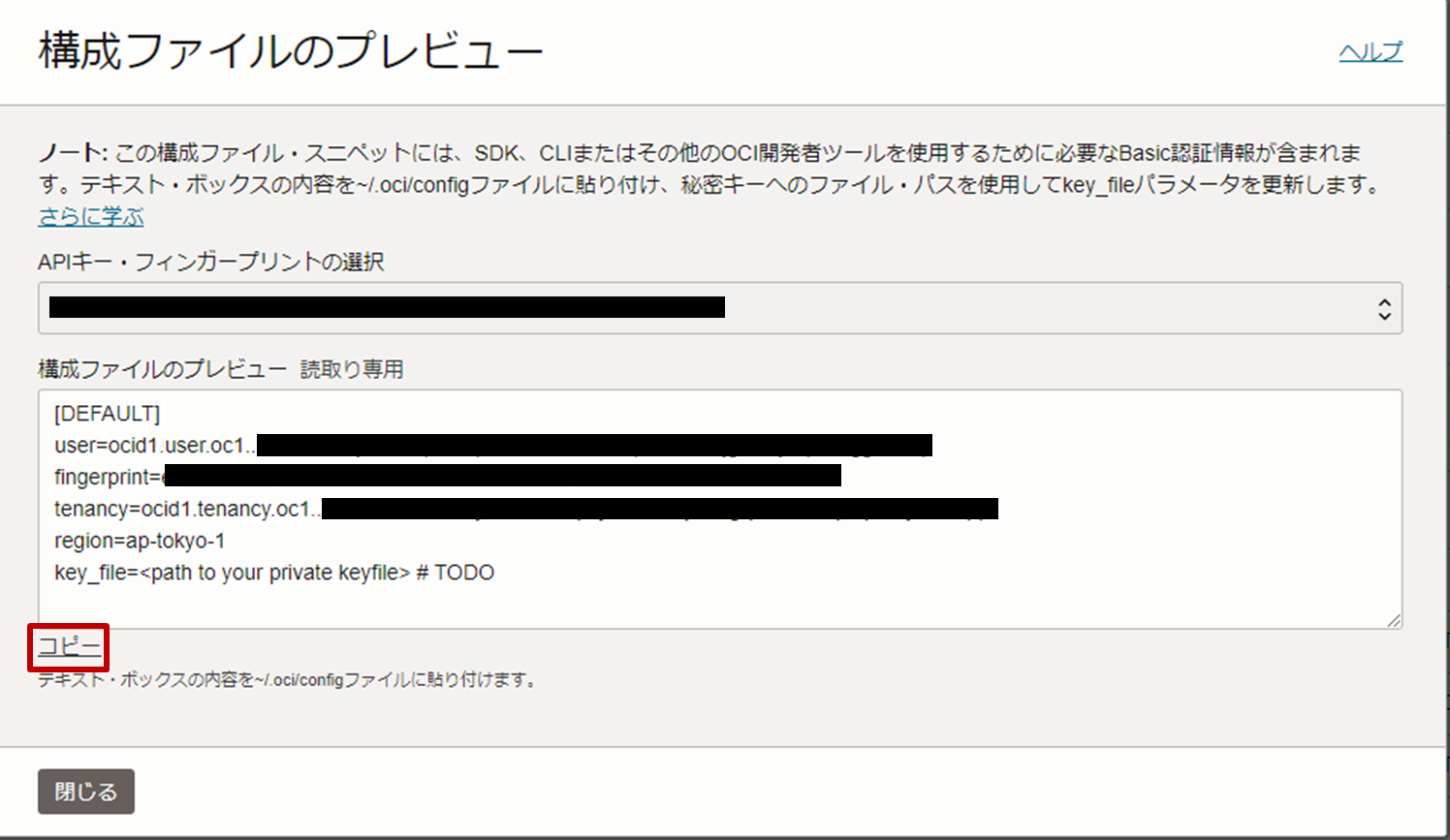
- 構成ファイルのプレビューが表示されるので、構成ファイルをコピーし、閉じます。
- ダウンロードした秘密鍵をアップロードします。
- コピーした構成ファイルを先程作成したconfigに貼り付け、必ずアップロードした秘密鍵のパスを指定し、保存します。

- Terminalタブに移動し、/home/datascience配下に「.oci」フォルダを作成し、configをコピーした後に権限を設定します。
1234567$ cd$ pwd$ mkdir /home/datascience/.oci$ cp config /home/datascience/.oci/$ cd .oci$ chmod 600 config$ cat config
コンパートメントOCIDの取得
次に、今回構築しているコンパートメントのOCIDを確認し、メモ帳などで管理します。
- 、ハンバーガーメニューをクリックし、「アイデンティティとセキュリティ」>「アイデンティティ」>「コンパートメント」をクリックします。
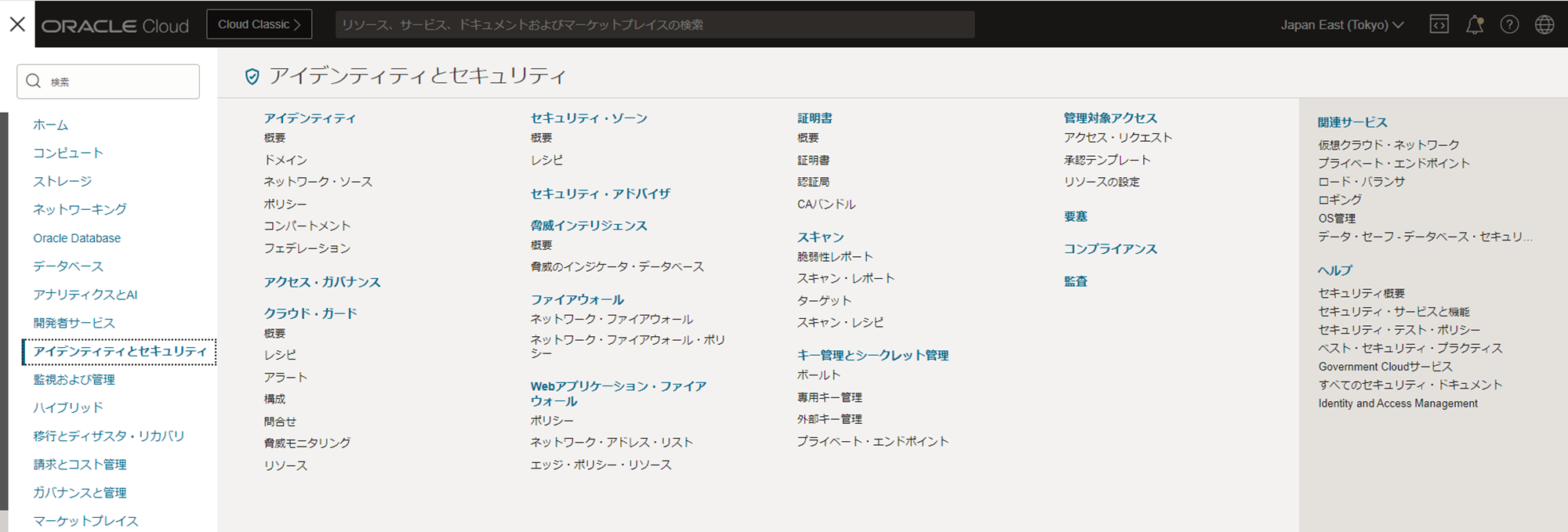
- 今回利用する対象のコンパートメントをクリックします。
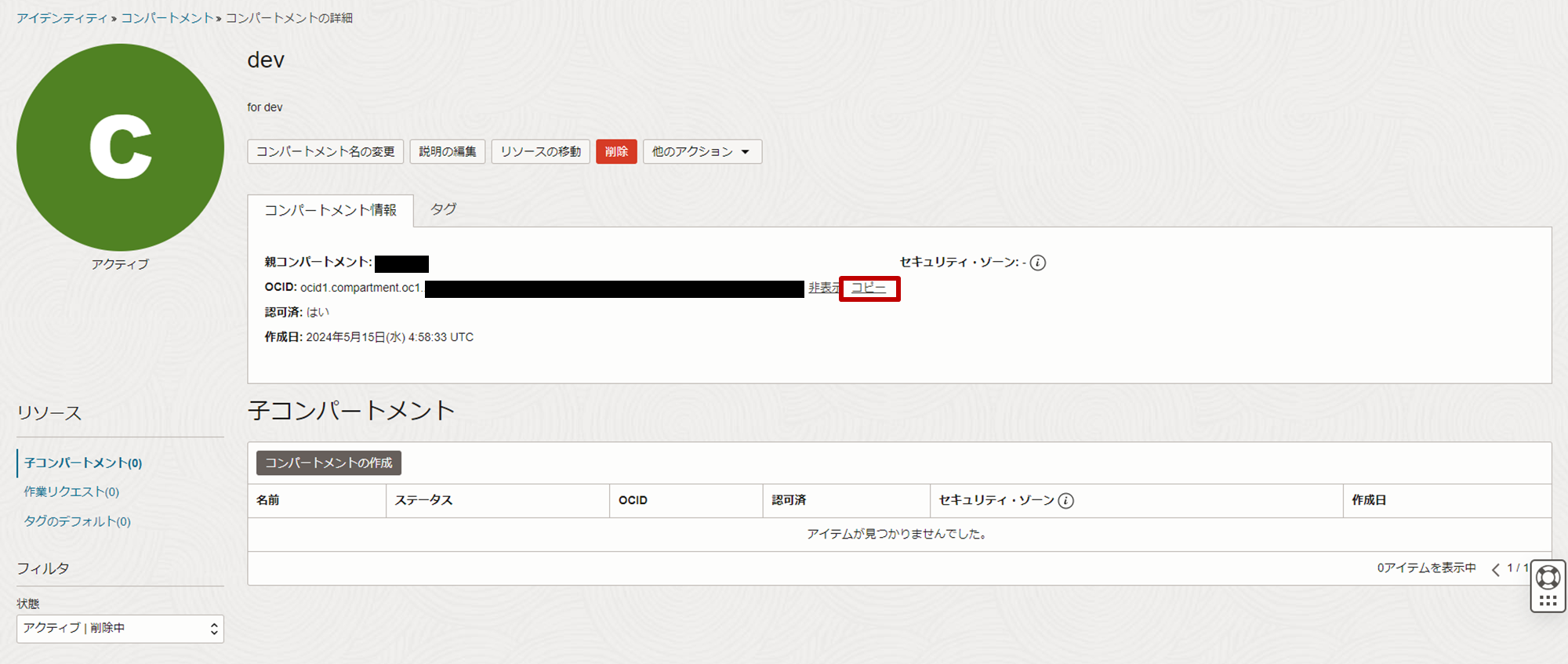
- コンパートメントの詳細画面からOCIDをコピーし、メモ帳などで管理します。
ノートブック環境における事前準備
最後に、RAG構成を実装にあたって必要となるノートブック環境の事前準備を行います。
なお、Notebook 全体は以下で公開しています。
参考:Notebook(GitHub)
-
ノートブックタブ(RAG_DataScience.ipynb)に戻り、以下のコマンドを実行し、ノートブックセッションにパブリック・インターネット・アクセスを有効化させます。
1234# パブリック・インターネット・アクセスを有効にしますimport requestsresponse = requests.get("https://oracle.com")assert response.status_code==200, "Internet connection failed"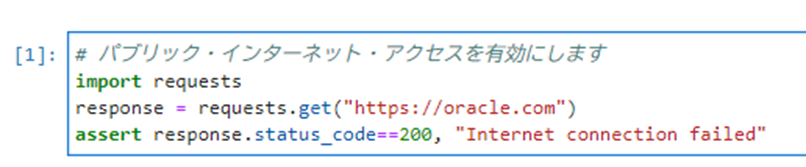
-
以下のコマンドを実行し、pip自体をアップデートさせます。
12# pip自体をアップデートさせます!pip install -qU --upgrade pip
-
以下のコマンドを実行し、必要なライブラリをインストールします。必要に応じて、個別にインストールしてください。
123456789101112# 必要なライブラリをまとめてインストールします!pip install -qU langchain langchain-community pypdf datapane==0.17.0 pandas==1.4.0 oracledb oci oci-cli# まとめてインストールできない場合(依存関係に問題がある場合)は、個別にインストールします# pip install -qU langchain# pip install -qU langchain-community# pip install -qU pypdf# pip install -qU sktime==0.24.0# pip install -qU datapane==0.17.0# pip install -qU pandas==1.4.0# pip install -qU oracledb# pip install -qU oci# pip install -qU oci-cli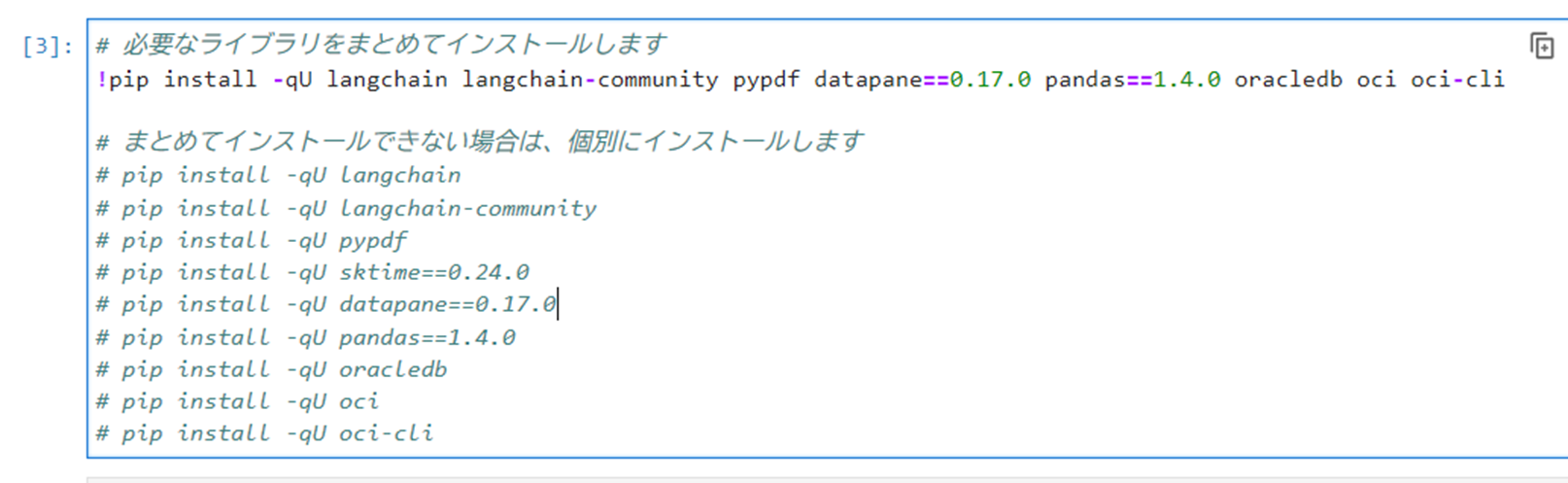
-
以下のコマンドを実行し、先程インポートしたPDFファイルが/tmpフォルダ内に存在するか確認します。
1234567import os# PDFが存在するか確認しますpdf_path = "/home/datascience/tmp/SS_CEO_Message.pdf"if os.path.exists(pdf_path):print("PDF exists")else:print("PDF does not exist")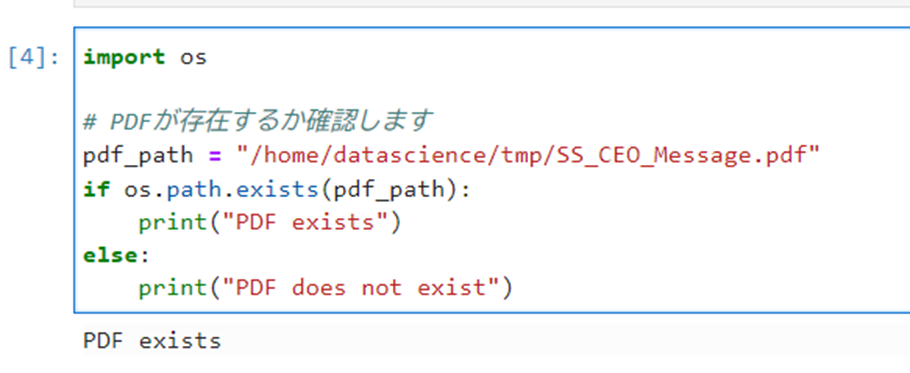
-
以下のコマンドを実行し、作成したBaseDBに接続します。dsnの箇所は、BaseDBのパブリックIPアドレスとPDBの接続文字列(「:1521/」以降の文字列)を入力してください。
1234567891011121314import oracledb# 利用するBaseDBに接続します。接続が成功した場合は、「Connection successful!」と出力されますoracledb.init_oracle_client()username = "docuser"password = "WelCome123#123#"dsn = "<BaseDBのパブリックIPアドレス>:1521/<PDBの接続文字列>"try:connection = oracledb.connect(user=username, password=password, dsn=dsn)print("Connection successful!")except oracledb.DatabaseError as e:error, = e.argsprint(f"Database connection faild: {error.code} - {error.masege}")except Exception as e:print(f"Connection failed: {str(e)}")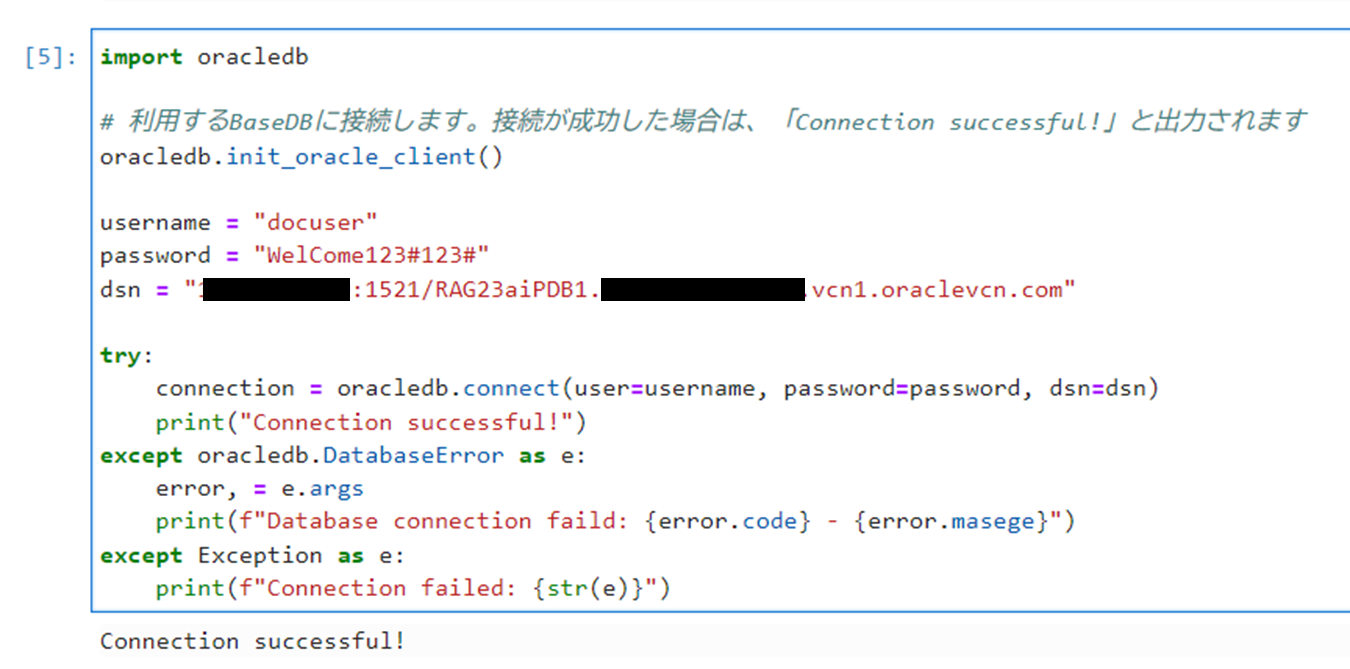
RAG構成と非RAG構成の実装比較
今までの手順でRAG構成を実装する準備が出来ました。実際にRAG構成と非RAG構成を比較し、回答の精度を検証していきたいと思います。具体的には、弊社スマートスタイルに関する質問をRAG構成と非RAG構成で実装し、ハルシネーションが起きていないか確認します。
RAG構成の実装
-
以下のコマンドを実行し、インポートしたPDFファイルのテキストをロードします。
12345from langchain.document_loaders import PyPDFLoader# 利用するPDFファイルのテキストをロードしますloader = PyPDFLoader("/home/datascience/tmp/SS_CEO_Message.pdf")documents1 = loader.load_and_split()print(documents1)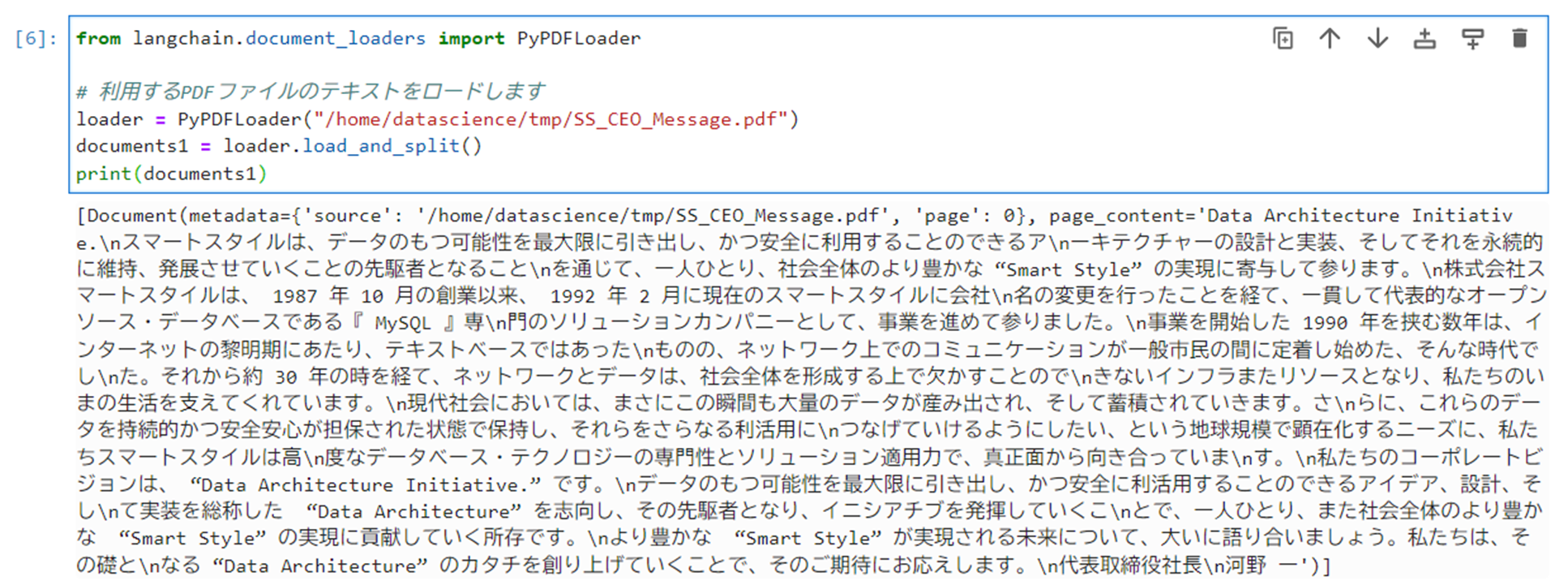
-
以下のコマンドを実行し、テキストを任意のサイズに分割します。
12345from langchain.text_splitter import CharacterTextSplitter# テキストを任意のサイズに分割しますtext_splitter = CharacterTextSplitter(separator="。", chunk_size=200, chunk_overlap=10)docs1 = text_splitter.split_documents(documents1)print(docs1)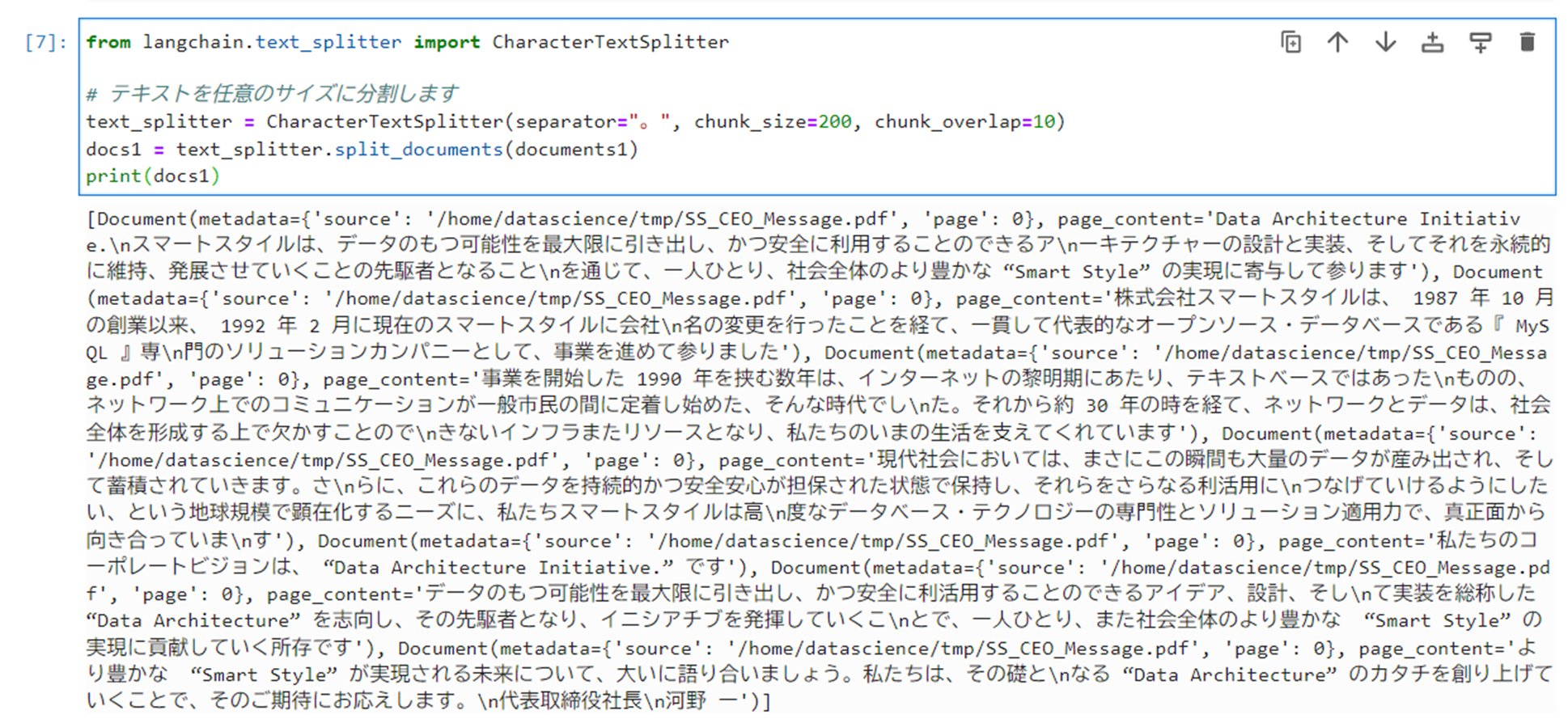
-
以下のコマンドを実行し、分割したテキストを整理します。
123456import pandas as pd# 分割したテキストを整理しますcontents = []for doc in docs1:contents.append(doc.page_content)pd.DataFrame(contents)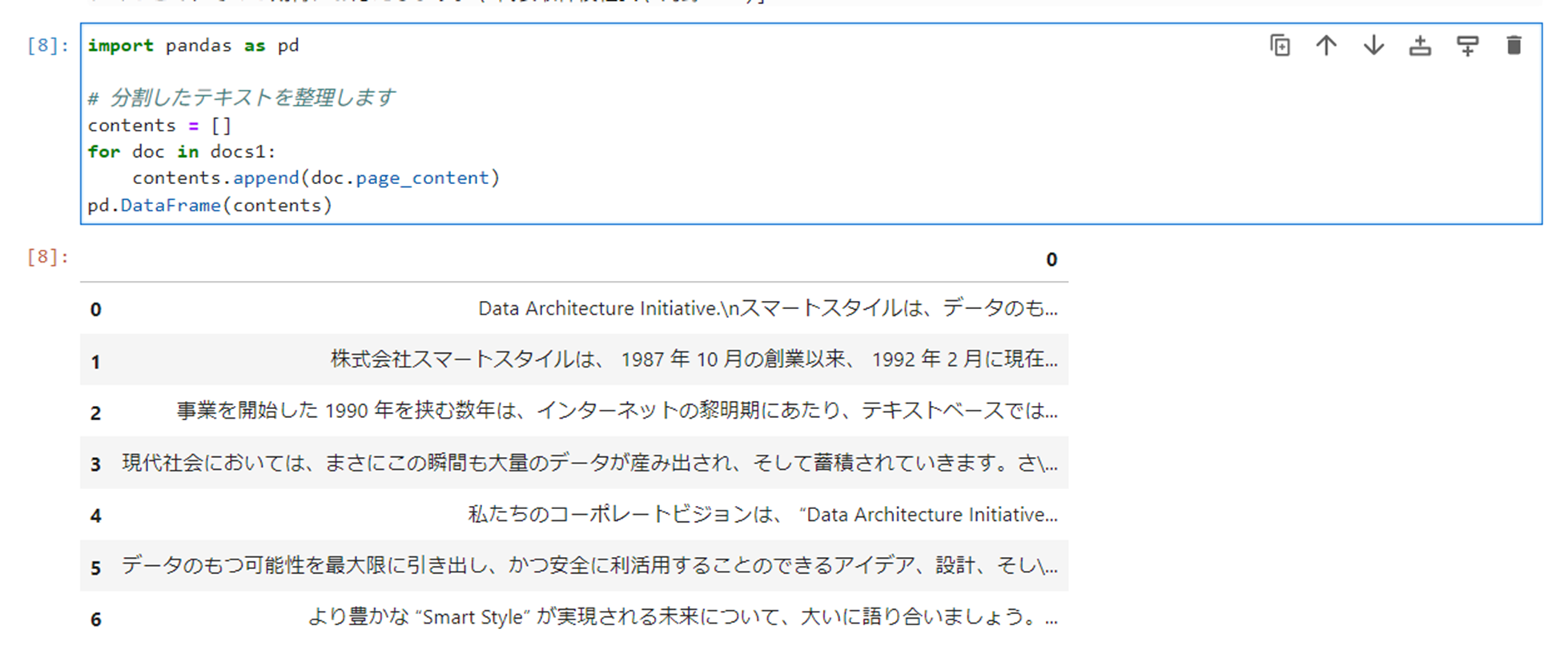
-
以下のコマンドを実行し、必要なライブラリをインポートします。
123456# 必要なライブラリをimportしますfrom langchain_community.vectorstores import oraclevsfrom langchain_community.vectorstores.oraclevs import OracleVSfrom langchain_community.vectorstores.utils import DistanceStrategyfrom langchain_core.documents import Documentfrom langchain_community.embeddings import OCIGenAIEmbeddings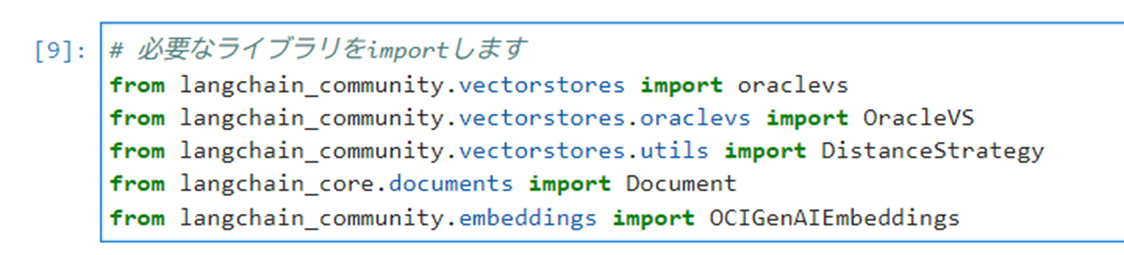
-
以下のコマンドを実行し、分割したテキストを埋め込みモデル(本記事では「cohere.embed-multilingual-v3.0」)でベクトルに変換します。以下の参考より他のモデルを指定して実装可能です。なお、コンパートメントOCIDはメモなどで管理していたものを使用します。
123456# 分割したテキストを埋め込みモデル(OCI Generative AI Serviceのembed-multilingual-v3.0)でベクトルに変換しますembeddings = OCIGenAIEmbeddings(model_id="cohere.embed-multilingual-v3.0",service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",compartment_id="<コンパートメントOCID>") -
以下のコマンドを実行し、ベクトル変換したテキストをベクトル・データベースにロードします。なお、距離計算は別のものでも構いません。
12345678# ベクトル変換したテキストをベクトル・データベースにロードしますvector_store_dot = OracleVS.from_documents(docs1, # 分割済みのテキストembeddings, # 定義済の埋め込みモデルclient=connection, # 利用するBaseDBデータベースとのconnectionオブジェクトtable_name="doc_table_ss", # 新規作成する表の名前を指定distance_strategy=DistanceStrategy.DOT_PRODUCT, # ベクトル検索時に使う距離計算の方法) -
以下のコマンドを実行し、索引を作成します。
12# 索引を作成しますoraclevs.create_index(connection, vector_store_dot, params={"idx_name": "SS", "idx_type": "IVF"})
-
以下のコマンドを実行し、プロンプトのテンプレートを作成します。
12345678from langchain_core.prompts import ChatPromptTemplatefrom langchain_core.messages import AIMessage, HumanMessage, SystemMessage# プロンプトのテンプレートを以下で作成しますtemplate = """contextに従って回答してください:{context}質問: {question}"""prompt = ChatPromptTemplate.from_template(template)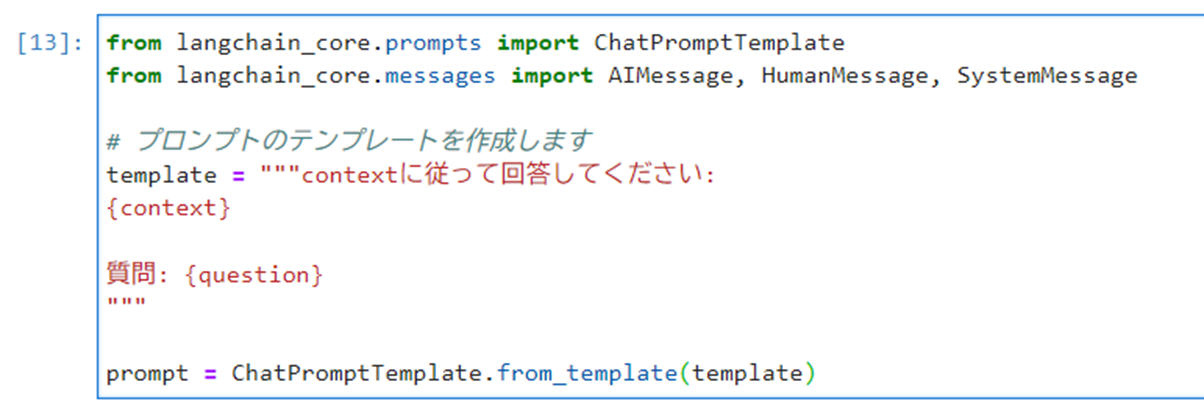
-
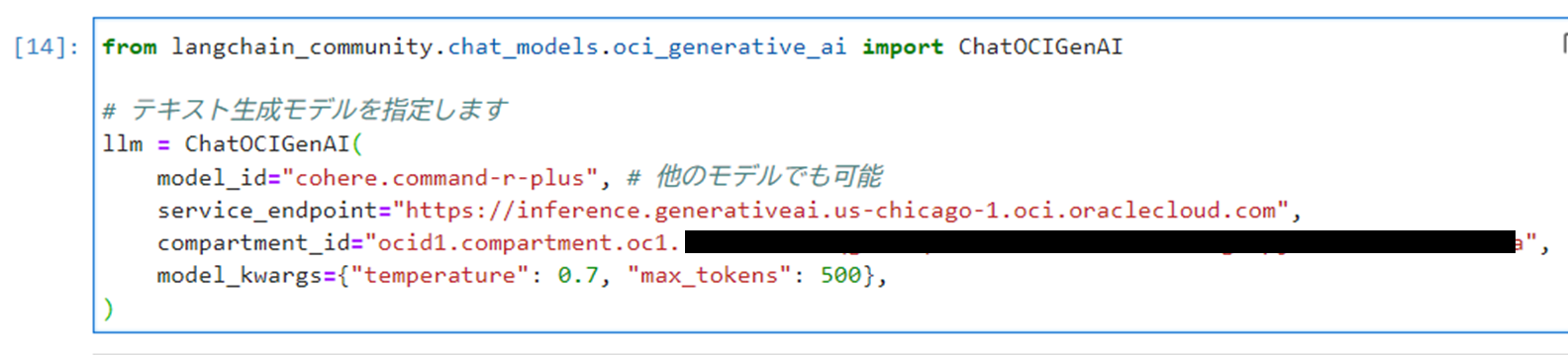
以下のコマンドを実行し、テキストを生成するモデル(本記事では「cohere.command-r-plus」)を指定します。以下の参考より他のモデルを指定して実装可能です。
12345678from langchain_community.chat_models.oci_generative_ai import ChatOCIGenAI# テキスト生成モデルを指定しますllm = ChatOCIGenAI(model_id="cohere.command-r-plus", # 他のモデルでも可能service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",compartment_id="<コンパートメントOCID>",model_kwargs={"temperature": 0.7, "max_tokens": 500},) -
以下のコマンドを実行し、ベクトル検索を実行するベクトルデータベースを定義します。
12# ベクトル検索を実行するベクトルデータベースを定義しますretriever = vector_store_dot.as_retriever()
-
以下のコマンドを実行し、今まで定義したものをChain(RAG構成)として繋ぎます。
123456789from langchain.schema.runnable import RunnablePassthroughfrom langchain.schema.output_parser import StrOutputParser# 今まで定義したものをChain(RAG構成)として繋ぎますchain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser())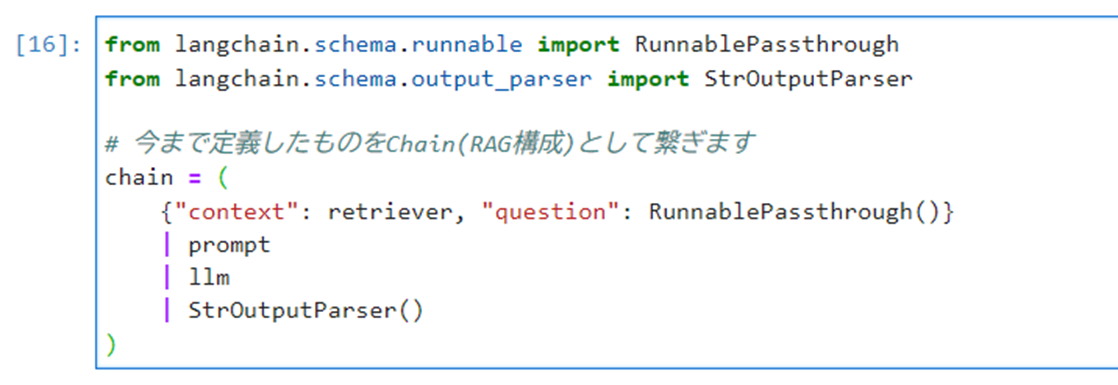
-
以下のコマンドを実行し、定義したChain(RAG構成)を利用して問い合わせます。
12345# 定義したChain(RAG構成)を利用して、問い合わせますprint(chain.invoke("スマートスタイルの社長は誰ですか?"))print(chain.invoke("スマートスタイルの創業はいつですか?"))print(chain.invoke("スマートスタイルの専門性は何ですか?"))print(chain.invoke("スマートスタイルのコーポレートビジョンはなんですか?"))

弊社の社長名、創業年、専門性、コーポレートビジョン、全てHPで公表している通りに正しい情報となっています。それでは次に、非RAG構成でも同様に問い合わせをし、比較していきます。


非RAG構成での実装
先程のRAG構成では、ハルシネーションを起こすことなく、弊社スマートスタイルの企業情報を出力させることが出来ました。では、非RAG構成では、どのように出力されるのか確認していきたいと思います。
- 以下のコマンドを実行し、Chainを利用しない(非RAG構成)で問い合わせます。
123456789# Chainを利用しない(非RAG構成)で問い合わせますresponse1 = llm.invoke("スマートスタイルの社長は誰ですか?")print(response1.content)response2 = llm.invoke("スマートスタイルの創業はいつですか?")print(response2.content)response3 = llm.invoke("スマートスタイルの専門性は何ですか?")print(response3.content)response4 = llm.invoke("スマートスタイルのコーポレートビジョンはなんですか?")print(response4.content)
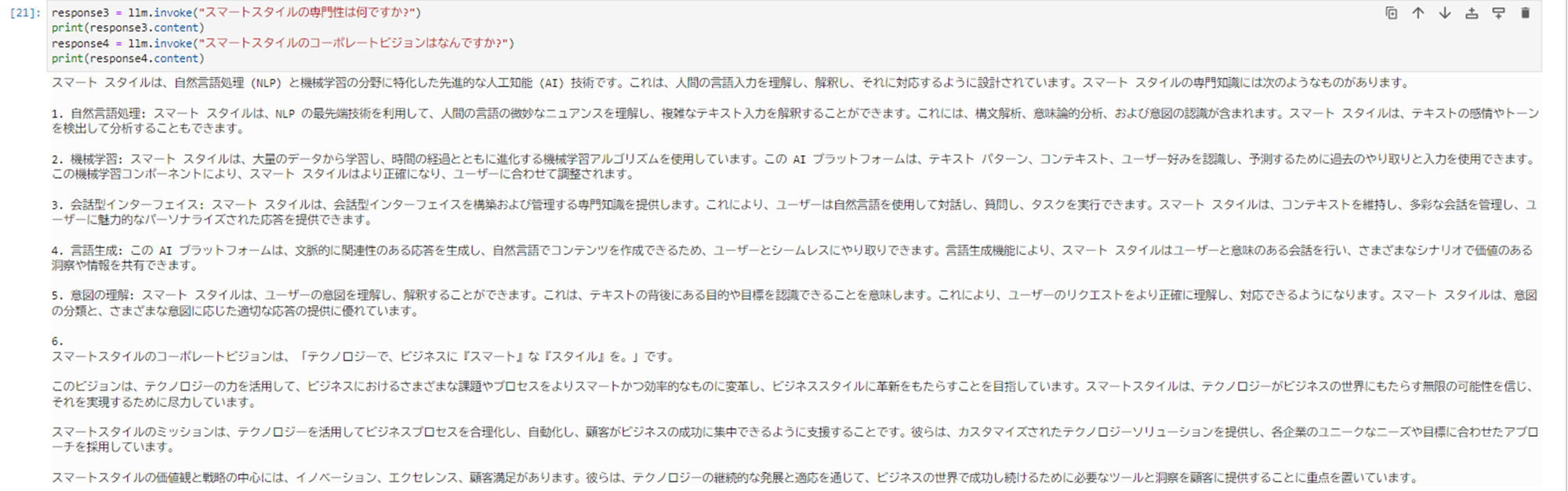
それらしい出力を返してくれましたが、弊社スマートスタイルが公表している情報ではなく、全てにおいてハルシネーションが起きています。RAG構成と非RAG構成を比較することで、RAG構成の威力を実感することが出来ました!
参考
Oracle Database 23ai
OCI Data Science
- Oracle Cloud Infrastructure Data Science Service 初期セットアップ
- [Oracle Cloud] OCI Data Sciense ノートブック・セッションの作成してみた(2023/08/15)
LangChainを利用したRAG構成
- OCI Generative AI と LangChain を使用した AI アプリケーションの開発
- [LangChain編] 新リリース Oracle Database 23ai で実装するエンタープライズRAG
- [LangChain編] Oracle Cloud Infrastructure Data ScienceとOracle Database 23aiで実装するRAG
- Oracle Database 23ai + LangChainを使いローカル環境のみでRAGを試してみた
- LangChain で Oracle ベクトル索引の効果を検証
まとめ
前編と後編に分けて、OCI Data Science サービスと Oracle Base Database Service 23ai (BaseDB) を利用してRAG構成を実装するための一連の手順を紹介してきました。RAG構成により、LLMで学習されていない情報であっても、正確な情報の出力が可能となります。また、OCIの各種サービスを活用することで、このRAG構成を簡単に実装できることを実感していただけたのではないでしょうか。本記事以外にも、様々なパターンで生成AIを活用したアーキテクチャが公開されています。本記事と併せて他の記事を参照し、実際のプロジェクトで応用してみてください。
関連記事:OCI Data ScienceとOracle Database 23aiで体験するお手軽なRAG構成について(前編)