MySQL Innovation Release 8.2.0 より、 MySQL Routerに待望の Read/Write Splitting 機能が追加されました。
類似の機能は MariaDB MaxScaleではすでに実装されていた り、 ProxySQLではユーザが設定すれば実現できた りしましたが、やっとMySQL Routerにも来たか…!という感じです。
今回はこの機能を検証してみたいと思います。
Read/Write Splitting とは
Read/Write Splitting とは MySQL Router のルーティング候補の選択方法の一つです。
MySQL の従来からの非同期レプリケーションは、書込みが可能なプライマリノードが一つだけ存在し、そこからデータの複製(レプリケーション)を行うレプリカノードが複数ある、という構成になります。
レプリカノードは、負荷分散(+フェイルオーバ候補/バックアップ)のために利用するのが一般的であり、実現のためにはロードバランサとなるSW or HWを利用することになります。
しかしながら、一般的なロードバランサは実行された処理が 更新系の処理 なのか 参照系の処理 なのか判断してルーティングする機能はありません。
そのためロードバランサの疑似IPやポート番号ごとにプライマリ用、レプリカ用というように分け、アプリケーション主導で使い分けるというのが通常です。
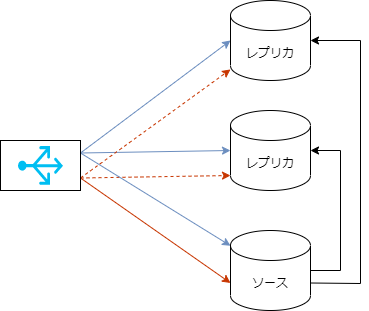
MySQL Routerもこれまでは基本的に上記の動作となっていました。
Read Write Split Routing 機能は、 SQLが更新系なのか参照系なのかをMySQL Routerが判断して適切な候補ノードに処理を振り分ける というものです。
これによってアプリケーション側から意識せずにレプリケーション環境を適切に使用する事ができます。
MySQL Routerのルーティングの設定
MySQL Router は設定ファイル(デフォルト: /etc/mysqlrouter/mysqlrouter.cnf) の個々の routing セクションにルーティング方法を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[routing:mycluster_rw] bind_address=0.0.0.0 bind_port=6446 socket=/tmp/mysql.sock destinations=metadata-cache://mycluster/?role=PRIMARY routing_strategy=first-available protocol=classic [routing:mycluster_ro] bind_address=0.0.0.0 bind_port=6447 socket=/tmp/mysqlro.sock destinations=metadata-cache://mycluster/?role=SECONDARY routing_strategy=round-robin-with-fallback protocol=classic : |
v8.1.0以前は、大きくはroutingセクション内の2つのオプションでルーティング先を決めていました
| オプション | 説明 |
|---|---|
| destinations | ルーティング候補 |
| routing_strategy | ルーティングの候補の選択基準 |
Read/Write Splitting も、 routing_strategy の選択肢なのかと思いきや、 access_mode という第三の基準が導入され、これによって実現されます。
access_mode はデフォルトで設定されておらず auto を設定するとRead/Write Splittingが有効になります。
機能を使うにはその他、以下のパラメータを有効化する必要があります。
|
1 2 3 |
connection_sharing = 1 protocol = classic destinations=metadata-cache://[cluster_name]/?role=PRIMARY_AND_SECONDARY |
とは言えマニュアルで設定する事はほぼありません。
mysqlrouterのbootstrap(初期設定)時にRead/Write Splitting 用設定が自動的に追加されます。
https://dev.mysql.com/doc/relnotes/mysql-router/8.2/en/news-8-2-0.html
読み取り/書き込み分割はデフォルトで有効になっています。新しいセクション が [router:read_write_split]ブートストラップ設定に自動的に追加されます。この設定を無効にするには、 を使用してブートストラップする必要があります –disable-rw-split。
デフォルトでは 6450 ポートが使用されます。
|
1 2 3 4 5 6 7 8 9 10 11 |
[routing:mycluster_rw_split] bind_address=0.0.0.0 bind_port=6450 socket=/tmp/mysqlsplit.sock destinations=metadata-cache://mycluster/?role=PRIMARY_AND_SECONDARY routing_strategy=round-robin protocol=classic connection_sharing=1 client_ssl_mode=PREFERRED server_ssl_mode=PREFERRED access_mode=auto |
注意点として、destinations=metadata-cache が必須のため、 対象は InnoDB Cluster、または InnoDB ReplicaSet である必要があります。
Read/Write Splittingの動作確認
まずは簡単に動作を確認してみます。
検証環境には 3台構成(blog1(プライマリ), blog2/blog3(レプリカ))の InnoDB ReplicaSet を使用し、1台のmysqlrouter(blog4)を使用します。
SQLが更新系なのか参照系なのかは、実行したSQL構文によって判断されます。
SELECTから始まるクエリであればレプリカにルーティングされ、BEGINから始まるクエリであればプライマリにルーティングされ、その後のトランザクション内の処理はSELECTでもプライマリにルーティングされるはずです。
詳しくは以下を参照ください。
https://dev.mysql.com/doc/mysql-router/8.2/en/router-read-write-splitting-statements.html
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
[root@blog4 ~]# mysql_config_editor set --login-path=rwsplit -utmpadmin -p -h127.0.0.1 -P6450 Enter password: ******** [root@blog4 ~]# mysql --login-path=rwsplit -e "select @@hostname" +------------+ | @@hostname | +------------+ | blog2 | +------------+ [root@blog4 ~]# mysql --login-path=rwsplit -e "select @@hostname" +------------+ | @@hostname | +------------+ | blog3 | +------------+ [root@blog4 ~]# mysql --login-path=rwsplit -e "begin;select @@hostname" +------------+ | @@hostname | +------------+ | blog1 | +------------+ [root@blog4 ~]# mysql --login-path=rwsplit -e "begin;select @@hostname" +------------+ | @@hostname | +------------+ | blog1 | +------------+ # なおautocommit=1で暗黙的にトランザクションが開始された場合もプライマリにルーティングされる [root@blog4 ~]# mysql --login-path=rwsplit --init-command="set autocommit=0" -e "select @@hostname" +------------+ | @@hostname | +------------+ | blog1 | +------------+ |
想定通りの動きとなりました。
一つの接続の中で、明示的にプライマリノードへ処理をルーティングしたり、レプリカノードに処理をルーティングする指定も可能です。
これは、 ROUTER SET という新しく実装されたコマンドによって行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
mysql> select @@hostname; +------------+ | @@hostname | +------------+ | blog2 | +------------+ 1 row in set (0.01 sec) mysql> begin; select @@hostname; commit; Query OK, 0 rows affected (0.01 sec) +------------+ | @@hostname | +------------+ | blog1 | +------------+ 1 row in set (0.00 sec) Query OK, 0 rows affected (0.00 sec) mysql> ROUTER SET access_mode = 'read_write'; -- プライマリへルーティング Query OK, 0 rows affected (0.00 sec) mysql> select @@hostname; -- SELECTもプライマリにルーティングされる +------------+ | @@hostname | +------------+ | blog1 | +------------+ 1 row in set (0.00 sec) mysql> ROUTER SET access_mode = 'read_only'; -- レプリカへルーティング Query OK, 0 rows affected (0.00 sec) mysql> begin; select @@hostname; commit; -- BEGINもレプリカにルーティングされる Query OK, 0 rows affected (0.01 sec) +------------+ | @@hostname | +------------+ | blog2 | +------------+ 1 row in set (0.00 sec) Query OK, 0 rows affected (0.00 sec) |
基本的には Read/Write Splitting によってルーティング先は判断されますが、構文で判断している以上、複雑なSQLが意図しない候補にルーティングされるというようなエッジケースは発生し得ます。
そのような場合でもユーザ側で簡単にルーティング先を切り替えられるようになっているようです。
なお、一つの接続あたりには 1つのプライマリと1つのレプリカが割り当てられますので、SET ROUTER で read_only に切り替えても接続内ではロードバランスされない点にご注意ください。
https://dev.mysql.com/doc/mysql-router/8.2/en/router-read-write-splitting.html
Each client session can communicate with one read_write and one read_only destination.
Read/Write Splittingにおける参照系処理の待機
SET ROUTER コマンドで設定できるオプションとして、 access_mode の他に、wait_for_my_writes、wait_for_my_writes_timeout が追加されています。
ドキュメントの和訳は以下の通りですが、少しわかリ辛いかもしれません。
wait_for_my_writes
タイプ 整数
デフォルト値 1
最小値 0
最大値 1
読み取り専用クエリは、最後に書き込まれたトランザクションを待ちます。セクション3.5「読み取り/書き込みの分割」 を参照してください。
wait_for_my_writes_timeout
タイプ 整数
デフォルト値 1
最小値 0
最大値 4294967295
読み取り専用の宛先が書き込まれたトランザクションを適用するまで待機する最大時間 (秒)。その後、読み取り専用の宛先にフォールバックします。
Read/Write Splittingが有効なセッションでは、(トランザクションを明示的に開始していない限り)更新はプライマリに、参照はレプリカにルーティングされます。
一方、非同期レプリケーション環境ではプライマリに実行した更新がレプリカに到達するまでにタイムラグがありますので、自分で更新したと思っていたデータが後ほどの参照で更新されていないような事がおきるケースがあります。
そのようなケースの防止策がこれらのオプションになります。
wait_for_my_writes は、更新処理に続く参照処理を実行する時に、先に実行された更新処理がレプリカに反映されるまではプライマリノードへ参照処理を行う という動作を有効にします。
wait_for_my_writes_timeout は、プライマリへルーティングするかどうかを待機する時間のタイムアウト(秒)になります。
試してみましょう。
|
1 2 3 4 5 6 7 8 |
[root@blog4 ~]# mysql --login-path=rwsplit mysql> select @@hostname; +------------+ | @@hostname | +------------+ | blog3 | # blog3が参照系 +------------+ |
検証のため参照系で遅延レプリケーションを有効にします
|
1 2 3 4 5 6 7 8 |
mysql blog3> STOP SLAVE; Query OK, 0 rows affected, 1 warning (0.05 sec) mysql blog3> CHANGE REPLICATION SOURCE TO SOURCE_DELAY=10; -- 10秒の遅延 Query OK, 0 rows affected (0.02 sec) mysql blog3> START SLAVE; Query OK, 0 rows affected, 1 warning (0.05 sec) |
更新・参照クエリを連続実行してみると、insertしたデータが遅延レプリによりまだ到達しないので、Empty setになります。
|
1 2 3 4 |
mysql> insert into test.t (v) values (@@hostname);select * from test.t; Query OK, 1 row affected (0.01 sec) Empty set (0.00 sec) |
wait_for_my_writes を設定してみると、先の更新がレプリカに反映するまでプライマリにルーティングされる様子が確認できます
wait_for_my_writes_timeout のデフォルトは1ですが、プライマリにルーティングされるまでに2秒の待機が発生しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
mysql> ROUTER SET wait_for_my_writes = 1; Query OK, 0 row affected (0.00 sec) mysql> insert into test.t (v) values (@@hostname); Query OK, 1 row affected (0.01 sec) mysql> select @@hostname; +------------+ | @@hostname | +------------+ | blog1 | +------------+ 1 row in set (2.00 sec) mysql> select @@hostname; +------------+ | @@hostname | +------------+ | blog1 | +------------+ 1 row in set (2.01 sec) mysql> select @@hostname; +------------+ | @@hostname | +------------+ | blog1 | +------------+ 1 row in set (2.01 sec) mysql> select @@hostname; +------------+ | @@hostname | +------------+ | blog3 | +------------+ 1 row in set (0.90 sec) |
まとめ
MySQL Routerに Read/Write Splitting 機能がやってきたことで、よりアプリケーションから透過的にデータベースクラスタをスケールアウトする事が可能になりました。
今後もMySQL Routerの新機能に注目していきたいと思います!