現代企業において、AI技術の活用は必須の競争要素となっています。
しかし「とりあえず生成AIを試す」段階を超え、業務に本格展開しようとすると、多くの企業が同じ壁にぶつかります。
それが、AIに最適化されたデータベース基盤=AIデータベースをどう設計・構築するかという問題です。
本記事では、AIデータベースの基本概念から実践的な設計・構築手法、さらにはOracle AI Database 26ai(旧23ai)を活用した具体的な企業事例までを一気通貫で解説します。
「自社のデータ基盤をAI Readyな状態にしたい」と考えているIT部門・情報システム部の方に向けて、検討の土台となる知識を整理しました。
AIデータベースとは?わかりやすく解説
AIデータベースとは、人工知能や機械学習アプリケーションでの利用を前提に設計・拡張されたデータ管理システムの総称です。従来のデータベースが主に構造化データの保存と検索を得意としてきたのに対し、AIデータベースは画像・音声・テキストなどの非構造化データから生成されたベクトル(埋め込み)を効率的に管理し、機械学習モデルの学習や推論に適した形でデータを提供します。
AIデータベースの特徴と従来型との違い
AIデータベースの中核的な特徴のひとつが、ベクトルデータの高速な類似検索機能です。AIアプリケーションでは、テキストや画像を数値ベクトルに変換して処理することが一般的であり、これらのベクトル間の類似度計算が頻繁に必要となります。
従来型データベースは、主に完全一致検索やSQLによる条件検索を前提に設計されてきました。一方で、AIデータベースではベクトル検索により、「意味的類似性」に基づいた検索(セマンティックサーチ)が可能になります。
例えば、「犬」という単語に対して「ペット」や「動物」といった関連する概念を自動的に検索結果に含めることができるのです。
AIに必要なデータベースの要件
AI向けデータベースに求められる要件として、まず、大量データの高速処理能力が不可欠です。
さらに、リアルタイム性も重要な要素となります。推論システムでは、ユーザーの問い合わせに対して瞬時に応答するため、ミリ秒単位での高速検索が求められます。また、多様なデータ形式への対応も欠かせません。異なる形式のデータを統一的に管理できる柔軟性が必要です。
主なAIデータベースの種類
AIデータベースは複数の種類に分類されます。代表的なものがベクトルデータベースで、これは機械学習モデルが生成するベクトルデータの保存と高速検索に特化しています。
時系列データベースは、株価データなど時間軸に沿ったデータの分析に適しています。グラフデータベースは、ソーシャルネットワーク分析など、エンティティ間の関係性を重視するAIアプリケーションに活用されます。
AIデータベース設計の実践ポイント
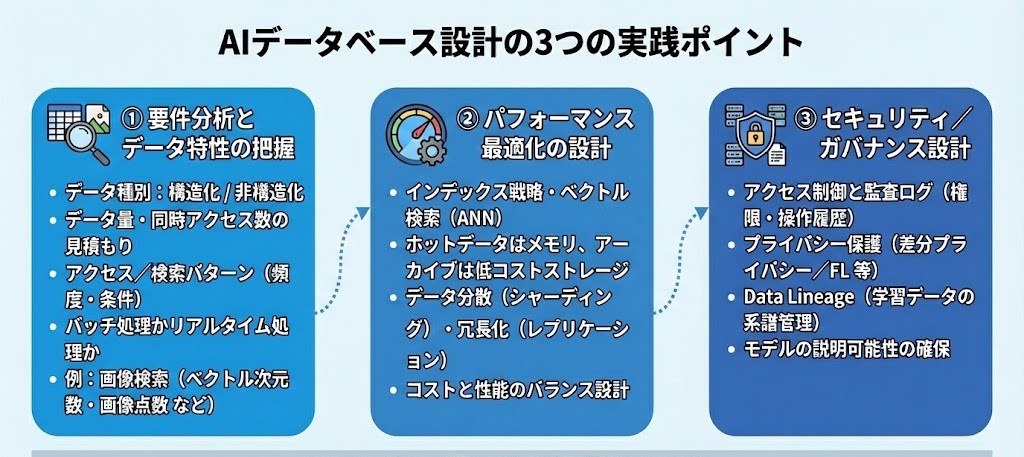
AIデータベースの設計は、AI特有の要件を理解し、データの特性に応じた最適な設計を行うことが成功の鍵となります。以下では、実践的な設計ポイントを段階的に解説します。
要件分析とデータ特性の把握
AIデータベース設計の第一歩は、データの特性と利用パターンの徹底的な分析です。扱うデータが構造化データなのか非構造化データなのか、データ量、アクセス頻度や検索パターンを詳細に把握する必要があります。
例えば、画像検索システムを構築する場合、画像データをベクトル化した際の次元数、検索対象となる画像の総数、同時アクセス数などを事前に見積もります。また、バッチ処理が中心なのかリアルタイム処理が必要なのかによって、データベースの選択肢も大きく変わります。これらの要件を明確にすることで、適切なアーキテクチャ選択が可能になります。
パフォーマンス最適化の設計原則
AIデータベースにおけるパフォーマンス最適化では、インデックス戦略の最適化が最も重要な要素の一つです。ベクトル検索では、近似最近傍探索アルゴリズムを活用して、高次元ベクトル空間での効率的な検索を実現します。
メモリとストレージの使い分けも重要な設計原則となります。頻繁にアクセスされるホットデータはメモリ上に保持し、アーカイブデータは低コストなストレージに配置するティアード戦略を採用することで、コストパフォーマンスを最適化できます。また、データの分散配置やレプリケーション戦略も、重要な検討事項です。
セキュリティとガバナンス設計
AIデータベースでは、厳格なデータガバナンス体制の構築が求められます。機械学習モデルの学習に使用される個人情報や機密情報が含まれるデータに対し適切なアクセス制御と監査ログの整備が不可欠です。
また、差分プライバシーやフェデレーテッドラーニングといったプライバシー保護技術の導入も検討すべきです。さらに、AIモデルの説明可能性を担保するため、学習データの系譜(Data Lineage)を追跡できる仕組みの構築も重要な設計要素となります。
AIデータベース構築の手順技術と要素
AIデータベースの構築は、多段階のプロセスが必要です。各段階での適切な技術選択と実装が全体の成功を左右します。ここでは実践的な構築手順を解説します。
構築段階の段階的アプローチ
AIデータベース構築は、段階的なアプローチによる反復開発が効果的です。まず概念実証(PoC)フェーズでは、技術検証を行い、選択したデータベース技術が要件を満たすかを確認します。この段階では迅速な検証を重視し、複数の技術選択肢を並行して評価することが重要です。
次のプロトタイプ開発フェーズでは、実際のデータ形式とボリュームに近い環境で詳細な性能評価を実施します。重要指標を測定し、本格運用に向けた最適化ポイントを特定します。最終的な本格導入フェーズでは、運用監視体制の構築と段階的なデータ移行を実施して、安定した本番環境を構築します。
データ統合とETLプロセスの最適化
AIデータベース構築において、ETL(Extract, Transform, Load)プロセスの設計は特に重要です。AI向けのETLでは、特徴量エンジニアリングやデータ品質チェック、ベクトル化処理などの複雑な変換処理が必要になります。
ワークフローオーケストレーションツールを活用して、複雑なデータ処理パイプラインを管理します。また、データ品質の監視とアラート機能を組み込み、異常なデータが混入した際の自動対処機能も実装することが推奨されます。
API連携とマイクロサービス化
現代のクラウドネイティブなAIシステムでは、モジュラー設計を採用するケースが一般的です。これにより、システムの柔軟性と保守性を大幅に向上させることができます。
RESTful APIやGraphQLを使用したAPI設計により、異なるチーム間での開発効率を高めます。また、Docker コンテナ化とKubernetesによるオーケストレーションにより、スケーラビリティと可用性を確保します。API ゲートウェイを通じた認証・認可機能やレート制限機能の実装により、セキュリティと性能の両立を図ることも重要な技術要素です。
ベクトル検索とエンベディング技術
ベクトル検索技術は、テキスト、画像、音声などの非構造化データを数値ベクトルに変換し、高次元空間での類似性検索を可能にすることで、幅広いAIサービスの基盤となっています。
ベクトル化(Embedding)の仕組みと重要性
エンベディング技術は、非構造化データを機械が処理可能な数値ベクトルに変換する核心技術です。例えば、「犬」という単語をベクトル空間において「ペット」や「動物」という概念に近い位置に配置することで、意味的な類似性を数値的に表現できます。これにより、従来のキーワードマッチングでは実現できない、文脈や意味を考慮した検索が可能になります。
現在主流となっているトランスフォーマーモデル(BERTやGPTシリーズ)は、文脈情報を考慮した高品質なエンベディングを生成できます。事前学習モデルを活用することで、効率的にエンベディングシステムを構築できます。ドメイン特有のデータに対しては、ファインチューニングにより、より精度の高いエンベディングを獲得することも可能です。
類似度検索と戦略的インデックス設計
高次元ベクトル空間での効率的な類似度検索には、適切なインデックス構造の選択と最適化が不可欠です。類似度検索を行うにあたり、データの特性と要件に応じて最適な手法を選択する必要があります。
実際の運用では、検索精度と速度のトレードオフを考慮し、再現率(Recall)と適合率(Precision)の要件に基づいてインデックスパラメータを調整します。また、定期的なインデックスの再構築とメンテナンスも、継続的な性能維持において重要な運用タスクとなります。
企業のAIデータベース活用事例
以下では、業界別の代表的な成功事例を紹介し、その成功要因を分析します。
事例1:【AIエージェント開発プラットフォーム】株式会社AI Shift|Oracle Autonomous Databaseで企業のAI活用を加速
サイバーエージェントの100%子会社である株式会社AI Shiftは、企業専用AIエージェント構築プラットフォーム「AI Worker」の基盤として、Oracle Cloud Infrastructure(OCI)上の Oracle Autonomous Database を採用しました。
AI Workerは、問い合わせ対応や業務支援など、企業ごとにカスタマイズしたAIエージェントを構築・運用できるプラットフォームです。生成AIの浸透により、業務プロセスの自動化ニーズは高まっていますが、実際には「既存システムとどうつなぐか」「企業固有のデータをどう安全に使うか」という壁がありました。AI Shiftは、日本オラクルと連携し、これらの課題をデータベースレイヤーから解決しようとしています。
AI Workerでは、Oracle Autonomous Databaseに搭載された Select AI を用いることで、SQLの知識がなくても自然言語でデータ検索や集計を行えるようになっています。ビジネスユーザーは、「先月のチャット問い合わせ件数の推移を教えて」といった日本語の質問を通じて、Autonomous Database上のデータにアクセスし、AIが生成した結果をそのままレポートや意思決定に活用できます。
また、Autonomous Databaseの強みである高度なセキュリティと自律運用機能により、企業の機密データを安全に扱いながら、チューニングやパフォーマンス最適化はデータベース側で自動化されます。AI Shift側は、インフラ運用に大きなリソースを割くことなく、「どのようなAIエージェントを設計するか」という本質的な価値提供に集中することができます。
今後は、Oracle Database 23aiのAI Vector Search と組み合わせ、テキストやログだけでなく、より多様な企業データを横断的に扱える高精度なAIエージェントを目指していく構想も示されています。AI Workerは、まさに「AI×データベース」を前提に設計された、次世代のAIエージェントプラットフォームと言えるでしょう。
出典: サイバーエージェント子会社のAI Shift、Oracle Autonomous Databaseを採用し、企業向けAIエージェント構築プラットフォームを提供開始
事例2:【生成AIエージェントによる業務データ活用】株式会社日立製作所|Oracle Database 23aiで複雑な業務問い合わせに対応
株式会社日立製作所は、日本オラクルと協創し、Oracle Database 23ai と Oracle Cloud Infrastructure(OCI)を組み合わせた生成AIエージェントを開発しました。狙いは、企業内に散在するあらゆる業務データを横断的に活用し、複雑な業務問い合わせにも自然言語で対応できるようにすることです。
企業の現場には、在庫や売上のような表形式のデータだけでなく、マニュアル、仕様書、社内Wikiなど、テキストベースの資料も大量に存在します。従来のRAG(検索拡張生成)は、主にテキストを対象にしていましたが、「最新の在庫数」「店舗別の実績」といった構造化データは、別途SQLで検索する必要がありました。そこで日立は、「ベクトル検索」と「SQL検索」の両方を使いこなすハイブリッド型の生成AIエージェントを構想します。
プロジェクトでは、Oracle Database 23aiの AI Vector Search を使って非構造化データを類似検索しつつ、Select AI を通じて自然言語からSQLを自動生成し、リレーショナルデータベースの表データも同じエージェントから扱えるようにしました。たとえば、「東京都内の店舗で、特定商品の在庫が50個以上ある店舗はどこ?」といった質問に対して、エージェントは質問の意図を理解し、在庫テーブルへの適切なSQLを生成して結果を取得します。同時に、関連するマニュアルや過去の対応記録があれば、それらもベクトル検索で引き当て、回答に織り込むことができます。
この仕組みを、全国に工場や店舗を持つ家電企業の在庫管理データを使って検証したところ、Oracle DatabaseとOCI上で構成したRAG型生成AIエージェントは、複雑な問いを含めた全体で82%の回答精度を達成しました。さらに、業務データベースと非構造データを組み合わせることで、従来のRAGでは対応が難しかった高度な問い合わせにも応えられることが確認されています。
特徴的なのは、この協創プロジェクトが、若手のデータサイエンティストとエンジニアを中心に、およそ3か月という短期間で形になっている点です。既存のOracle Databaseの資産やスキルを前提に、23aiの新機能を組み合わせていくスタイルは、多くの企業が参考にできる“現実解”になっています。
出典: 日立、日本オラクルと生成AIを活用した協創プロジェクトを実施
事例3:【サポート業務の効率化】NEC|Oracle AI Vector Searchで問い合わせ対応時間を20%以上短縮へ
日本電気株式会社(NEC)は、自社が販売するOracle製品のサポート業務を担う「NECオラクル・レスポンス・センター(NEORC)」において、Oracle Database 23aiのAI Vector Search を活用したRAGシステムを導入しました。目的は、年間約12,000件にのぼる問い合わせへの対応を、より高速かつ効率的に行うことです。
NEORCには、過去の問い合わせと回答、技術ナレッジ、ドキュメントなど、長年の対応で蓄積された膨大な情報が存在します。多くの問い合わせは過去の案件と内容が似通っていますが、その類似事例を人手で探し出すには時間がかかり、オペレーターの負担になっていました。そこでNECは、Oracle Database 23aiに追加されたベクトル検索機能を用い、こうした“ナレッジの山”をAIで素早く引き出せる仕組みづくりに踏み出します。
実証実験では、まず過去の問い合わせデータやナレッジをベクトル化してOracle Databaseに格納し、新規問い合わせの内容と意味的に近い事例を AI Vector Search で検索できるようにしました。そのうえで、見つかった類似事例をもとに生成AIが回答案のたたき台を自動生成し、オペレーターはそれを確認・修正してお客様に回答する、というフローを構築しています。
このRAGシステムの検証結果から、NECは問い合わせ対応時間を20%以上短縮できる見込みがあると判断し、2025年9月からNEORCのサポート業務システムで本番稼働させる計画です。
ポイントは、NECが新たな専用ベクトルデータベースを導入するのではなく、既存のOracle Database基盤にAI Vector Searchを追加する形でRAGシステムを構築していることです。これにより、長年にわたって蓄積してきたデータベース運用ノウハウやセキュリティ設定、ガバナンスの枠組みを活かしながら、生成AIを業務に組み込んでいる点が際立っています。
出典: サポート業務の効率化に向けてオラクルのAI Vector Searchを採用
運用管理と監視システム
AIデータベースシステムの安定稼働には、従来のシステム監視に加えて、AI特有の指標や動作パターンを考慮した包括的な運用管理体制が不可欠です。機械学習モデルの性能劣化や予期しないデータドリフトなど、AI固有の問題に対する監視と対処体制の構築が重要となります。
パフォーマンス監視の重要指標
AIデータベースにおけるパフォーマンス監視では、従来のインフラ/データベース指標に加えて、AI特有のメトリクスを継続的に測定する必要があります。CPU使用率やクエリレイテンシ、エラーレートなどの基本的なデータベース指標は常時監視しつつ、ベクトル検索については近似検索の品質を測る再現率(Recall)や精度、応答時間などを指標として把握します。
あわせて、モデルの推論性能、データドリフトの有無、特徴量分布の変化、予測精度の推移といった AI 特有の指標を追跡することで、システムの技術的健全性だけでなく、ビジネス価値の継続的な提供を支えられます。
また、A/Bテスト機能を組み込み、モデル変更がビジネスメトリクスに与える影響を定量的に評価できる体制を整えておくと、改善サイクルを回しやすくなります。
自動化されたアラート体制
AIシステムでは、異常の早期発見と、可能な範囲での自動対処機能が重要です。モデル性能の劣化やデータドリフトは徐々に進行することが多いため、適切な閾値を設定した早期警告システムを用意しておく必要があります。
Prometheus+Grafana スタックや、各クラウドプロバイダーの監視サービスを活用して、インフラからモデルまでをカバーする包括的な監視環境を構築します。アラート体制としては、重要度に応じた段階的なエスカレーションを設計し、緊急度の高い問題は即座に担当チームへ通知し、軽微な問題は定期レポートに集約する、といった運用が有効です。
さらに、一部のケースでは、モデルの再学習やベクトルインデックスの再構築などを自動実行する自動復旧機能を組み込むことで、運用負荷の軽減が期待できます。Slack などのコラボレーションツールと連携させれば、インシデント対応のスピードとチーム内の情報共有も向上します。
バックアップとディザスタリカバリ戦略
AIデータベースシステムでは、学習済みモデルと大容量データの保護が、従来以上に重要なテーマとなります。大規模モデルの再学習には多大な計算資源と時間が必要なため、学習済みモデルを適切にバックアップし、管理システムと連携して各バージョンのモデルと学習データセットを対応づけて保存しておくことが望まれます。
データベースの復旧戦略としては、Point-in-Time Recovery 機能を活用し、特定時点のデータを迅速に復旧できる体制を整えることが基本となります。クラウド環境では、複数リージョンに跨った冗長構成を採用することで、災害リスクを抑えられます。
あわせて、定期的な復旧テストを実施し、実際の障害発生時にも計画どおりに復旧できるかを確認しておくことが重要です。その際、ベクトルインデックスの再構築にかかる時間やコストも織り込んだうえで、段階的な復旧手順を事前に設計しておくと、より現実的なディザスタリカバリ計画になります。
スマートスタイルのAIデータベース基盤構築支援
AIを本番業務で活用するには、モデルだけでなく「AIが使えるデータ基盤」が必要です。スマートスタイルは、Oracle Database と Oracle Cloud Infrastructure(OCI)を組み合わせた AI Ready Platform on OCI 導入支援サービス を通じて、次のようなテーマを一括で支援します。
- 既存 Oracle Database を活かした AI/RAG 対応データ基盤の設計・構築
- SaaS・社内DB・ファイルなど社内データの統合とベクトル検索の仕組みづくり
- 監視・バックアップ・セキュリティを含めた運用設計とチューニング支援
自社のAIデータベース基盤をどこから検討すべきかお悩みの方は、以下よりサービス詳細・資料ダウンロード・お問い合わせをご覧ください。
AI Ready Platform構築支援サービスの詳細はこちら
まとめ
AIデータベースの設計・構築は、企業のデジタル変革において中核的な役割を果たす重要な技術領域です。本記事では、基本概念から実践的な構築手法、企業事例まで包括的に解説しました。
- AIデータベースは従来型とは根本的に異なる設計思想とアプローチが必要
- ベクトル検索とエンベディング技術がAIシステムの核心的基盤となる
- NoSQLとクラウドサービスの活用により柔軟性とスケーラビリティを実現
- 実企業の成功事例から学ぶ具体的な導入効果と実装ポイント
- 継続的な運用管理と監視体制がシステムの長期的成功を支える
- 専門家による支援サービス活用が確実な導入と運用最適化を可能にする
AIデータベース基盤の構築を検討されている企業様は、まず要件の明確化と技術選択肢の評価から始め、段階的なアプローチによる確実な導入を進めることをおすすめします。