
はじめに
現代のアプリケーション開発において、データベースに格納された情報から機械学習の恩恵を受けたいというニーズは日々高まっています。
従来、データベースから機械学習モデルを活用するには、複雑なデータパイプラインの構築や、データの移動・変換処理が必要でした。
例えば、顧客のレビューテキストの感情分析を行いたい場合、従来なら以下のような手順が必要でした。
1. データベースからデータを抽出
2. 機械学習サービスにデータを送信
これを、Amazon Aurora 機械学習(Aurora ML)なら、単一のSQL文で完結し、別サービスへの橋渡しを実装する必要がなくなります。
Aurora MLを使用することで、複雑なデータパイプラインや中間処理が不要になり、SQLだけで機械学習処理が完結します。
今回は、以下で紹介する Amazon Bedrock と Aurora MySQL で Aurora ML を使用する手順を紹介したいと思います。
Aurora MLと連携可能なサービス
Aurora MLは、AWSの以下3つの機械学習・AI関連サービスとシームレスに連携できます。
Amazon Bedrock
Bedrockは、AWSが提供する生成AIのマネージドサービスです。
Claude、Llama、Titanなどの大規模言語モデル(LLM)にアクセスでき、Aurora MLを通じてデータベースから直接これらのモデルを活用し、データベース内のテキストデータに対して要約、翻訳、質問応答、コンテンツ生成などの高度な自然言語処理を直接実行できます。
※Aurora MySQL では、3.06 以降でのみ利用可能。
(この制限は、Bedrockサービス自体が比較的新しく、最新のAuroraエンジンでのみサポートされているためです。)
Amazon SageMaker
SageMakerは、AWSの包括的な機械学習プラットフォームです。
カスタム機械学習モデルの開発、トレーニング、デプロイメントを支援し、Aurora MLとの連携により、独自に作成したモデルをデータベースから直接呼び出すことができます。
SageMakerとの連携の利点は、カスタマイズ性の高さにあります。ビジネス固有の要件に合わせて作成されたモデルを、データベースレベルで活用できるため、高度にパーソナライズされたサービスの構築が可能になります。
Amazon Comprehend
Comprehendは、自然言語処理に特化したマネージドサービスです。
感情分析、エンティティ認識、キーフレーズ抽出、言語検出などの機能を提供します。
※SageMakerとComprehendはリージョンによって対応バージョンが異なりますが、比較的早期からAurora MLに対応しているため、幅広いAuroraバージョンで利用できます。詳細については、以下をご確認下さい。
事前設定手順
BedrockとAurora MySQLでAurora MLを使用する手順について記載します。
前提
- 東京リージョンで検証しています。
- 既にAurora MySQL(version 3.08.2)インスタンスが構築済みで、ライターインスタンス1台のみの構成で確認しています。
Bedrockの基盤モデルへのアクセスをリクエスト
前提として、Aurora MLから使用するしないに関わらず、Bedrockを使用する為には、基盤モデルへのアクセスリクエストが完了している必要があります。
こちらについての詳細は、以下のリファレンスをご参照下さい。
上記を実行するユーザについて必要なIAM権限については、以下のリファレンスをご確認下さい。
Bedrockにアクセスする為のIAMポリシーとロールを作成
Aurora MySQLがBedrockにアクセスする為のIAMポリシーを作成します。
ポリシーの作成画面で、「サービス」に「Bedrock」を選択し、「アクション許可」-「読み取り」で「InvokeModel」を選択します。
「リソース」は「すべて」を選択して、「次へ」ボタンを押下します。
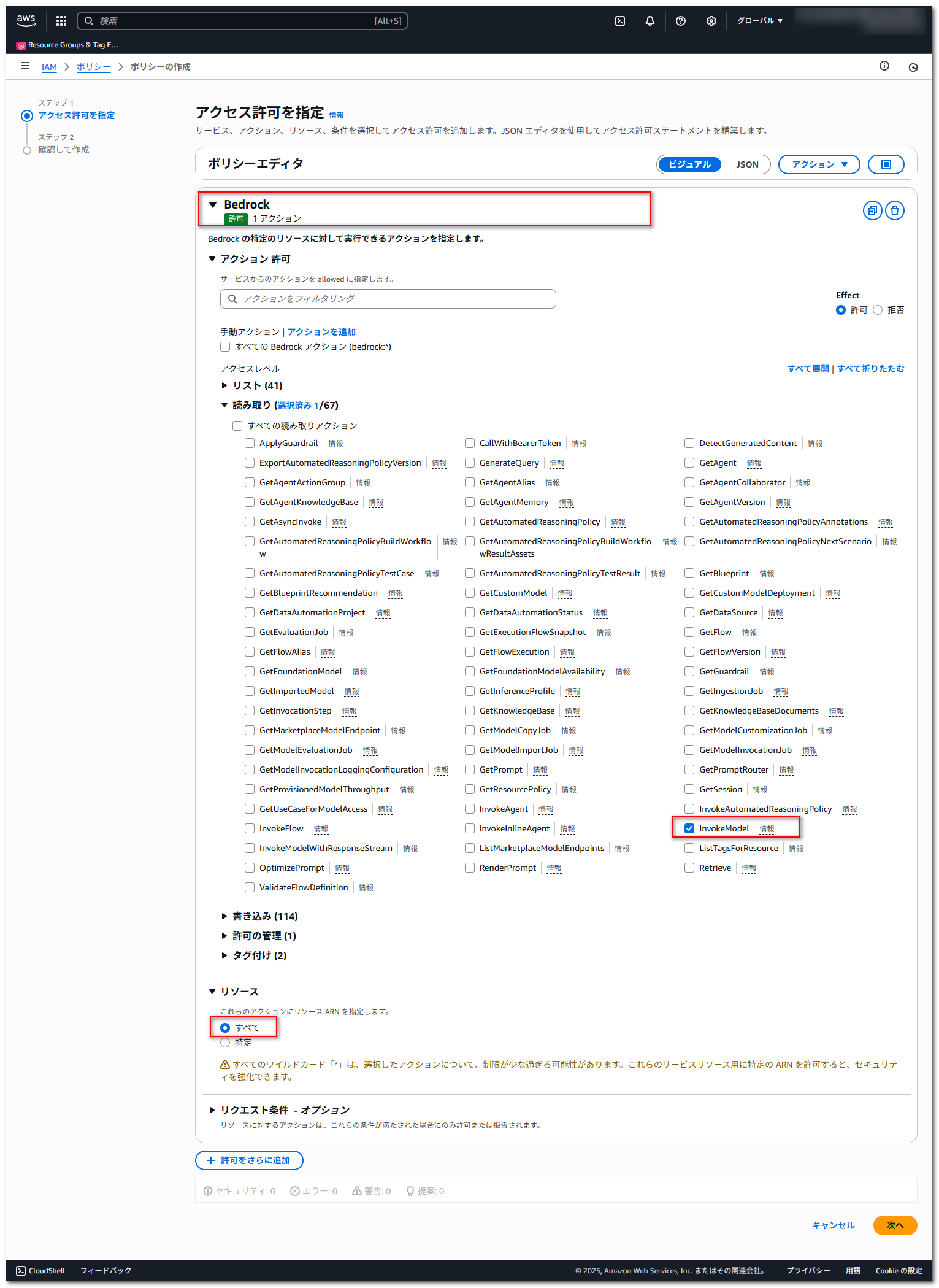
ポリシー名に適当な名前を入力し、「ポリシーの作成」を押下します。
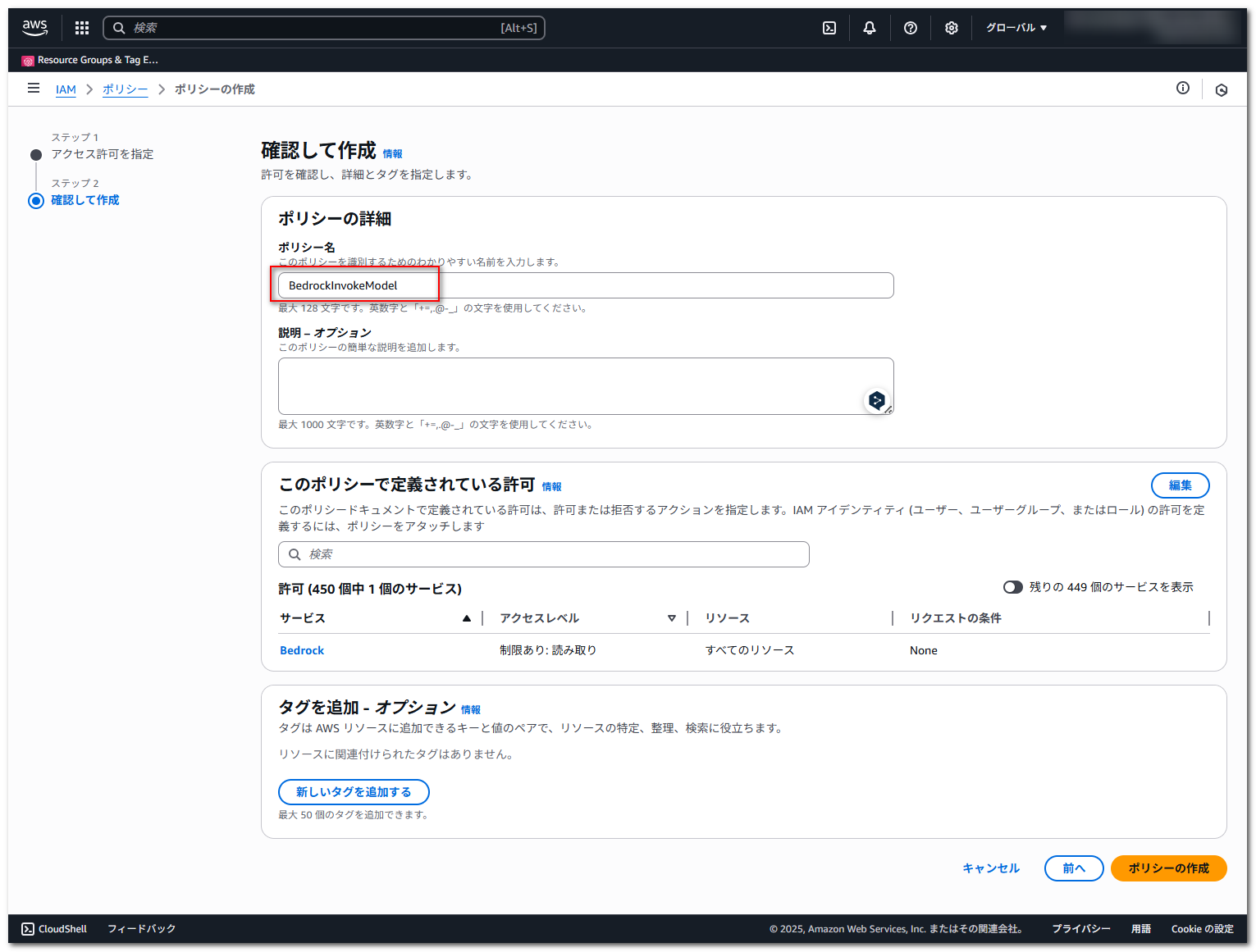
今回は以下のリファレンス同様にポリシー名を BedrockInvokeModel としています。
続いて、ロールを作成します。
「信頼されたエンティティタイプ」は「AWS のサービス」を選択し、「サービスまたはユースケース」で「RDS」を選択します。
表示された「ユースケース」で「RDS – Add Role to Database」を選択して、「次へ」を押下します。
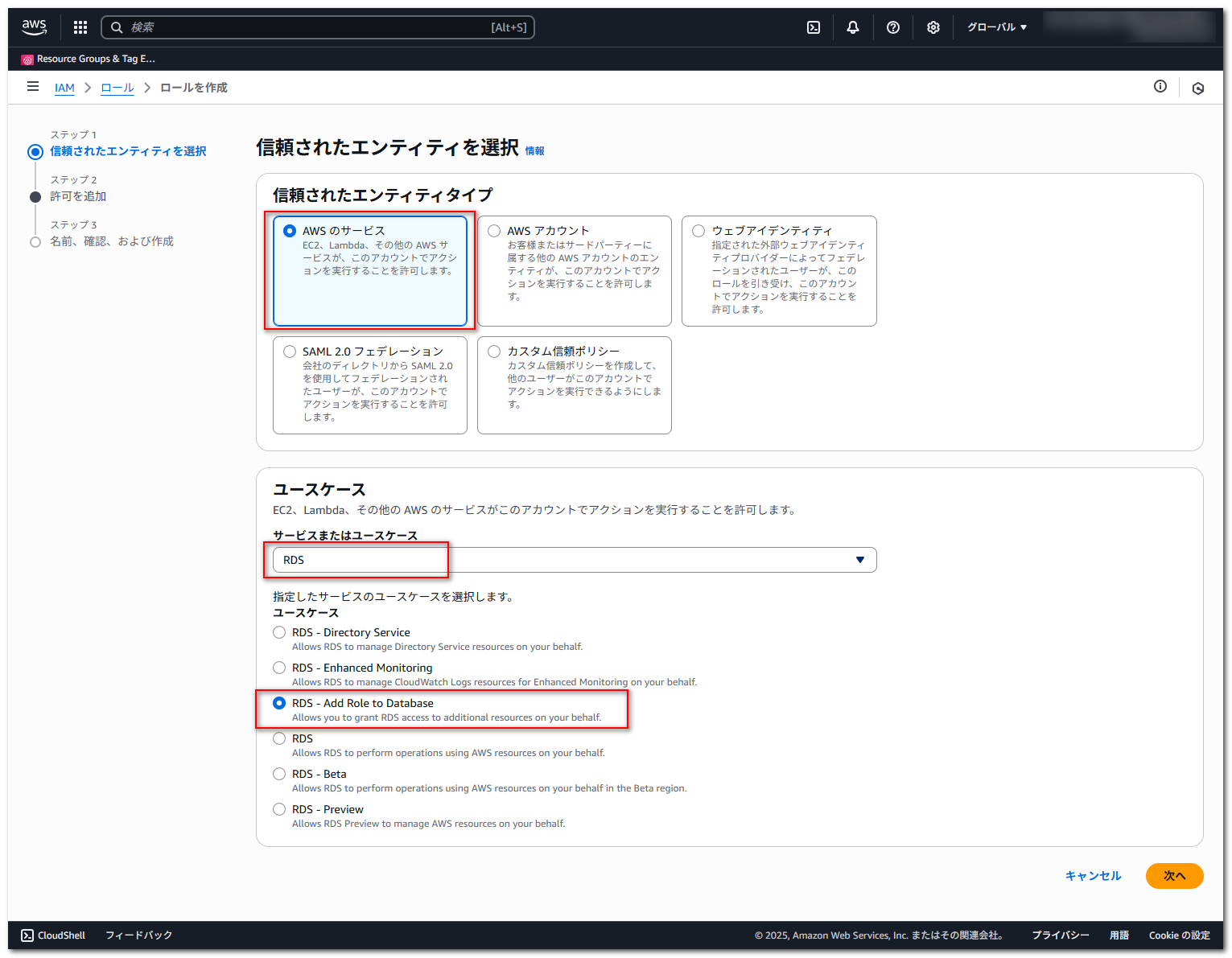
「許可ポリシー」で先程作成した BedrockInvokeModel を選択して、「次へ」を押下します。
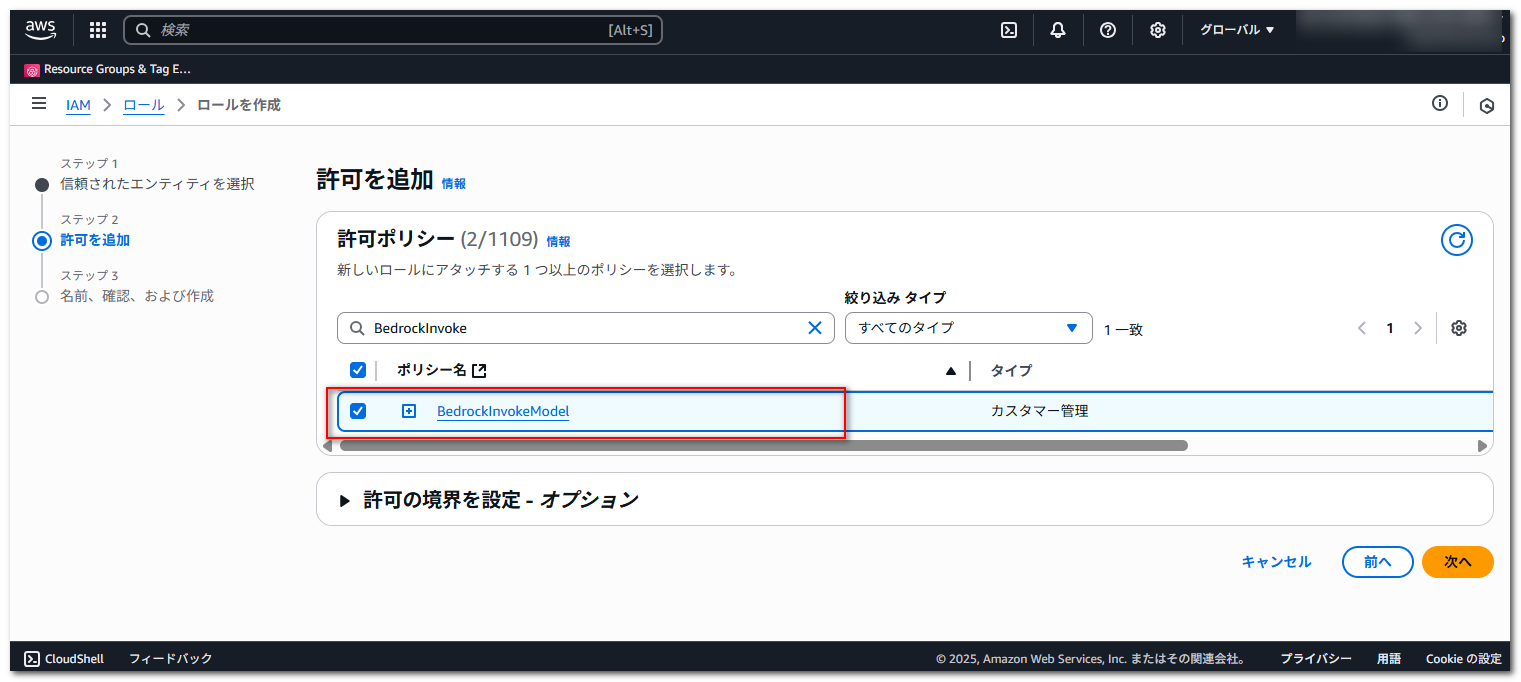
「ロール名」に適当な名前を入力して、「ロールを作成」を押下します。
ロール名は ams-bedrock-invoke-model-role としています。
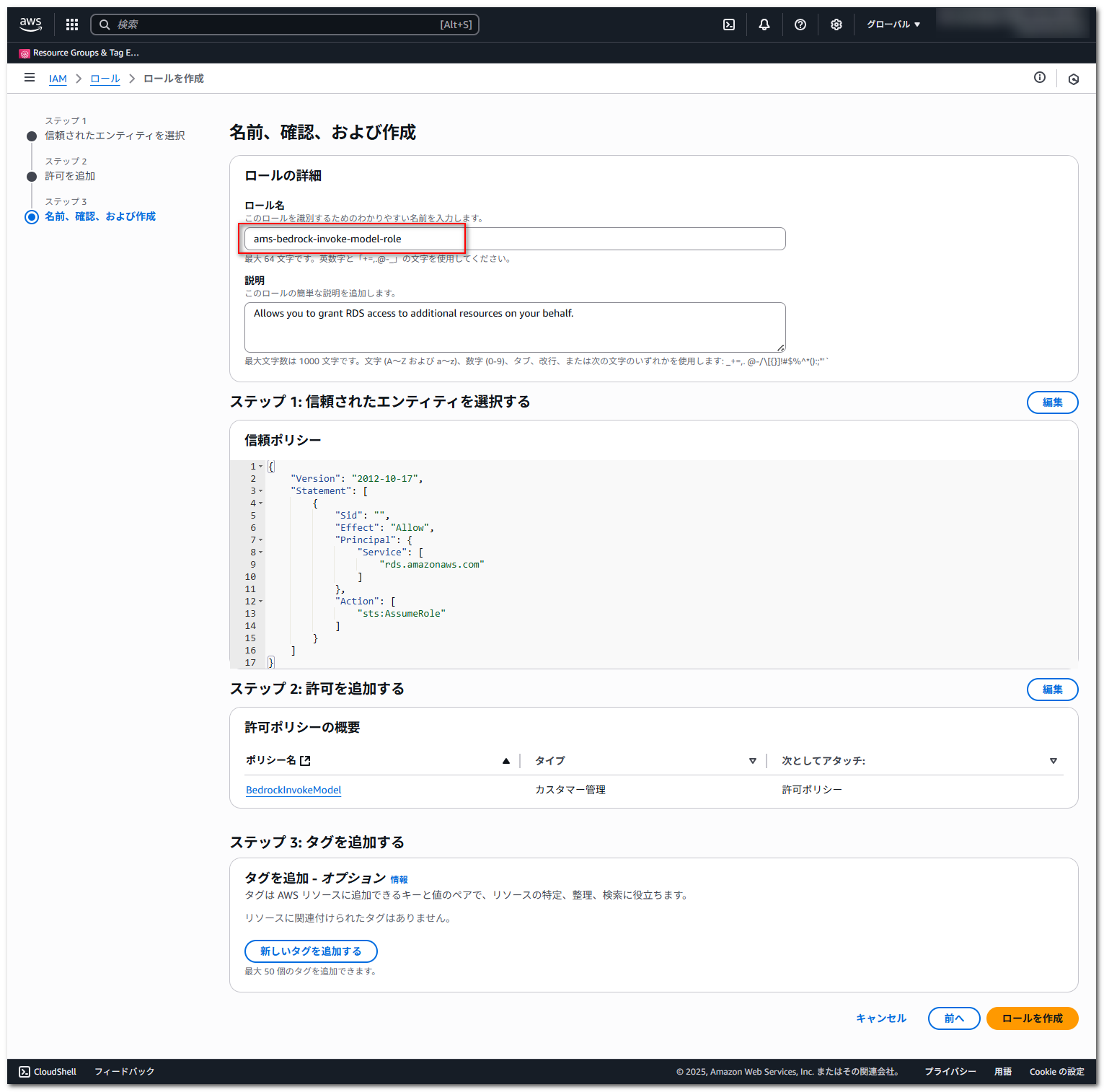
※作成後は、後で必要になるので、作成したロールの「ARN」をメモしておきます。
Aurora MySQLに作成したIAMロールを関連付け
Auroraインスタンスの詳細画面で、「接続とセキュリティ」タブから「IAM ロールの管理」で、「このクラスターに追加する IAM ロールを選択」を選択した状態で、先程作成した ams-bedrock-invoke-model-role を選択して「ロールの追加」を押下します。
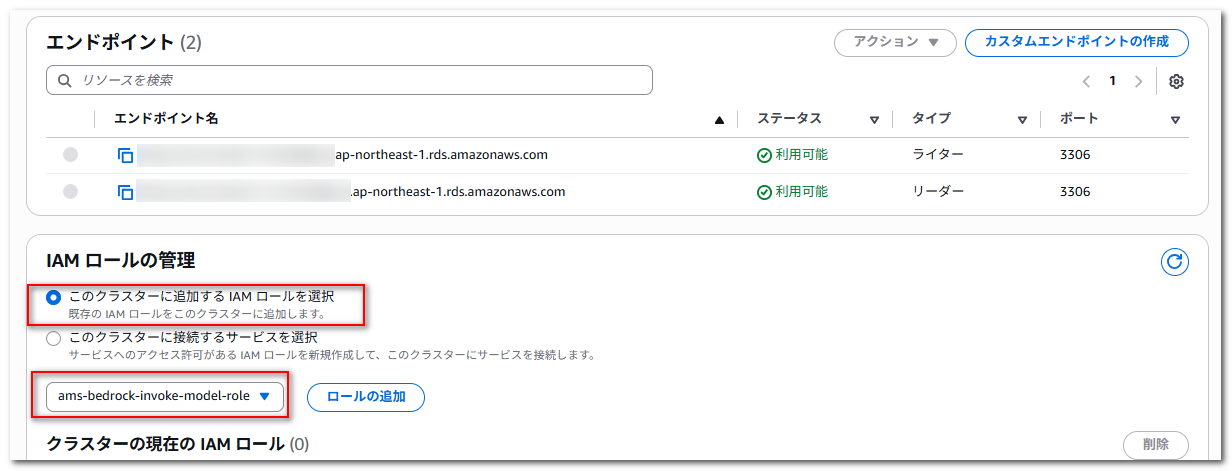
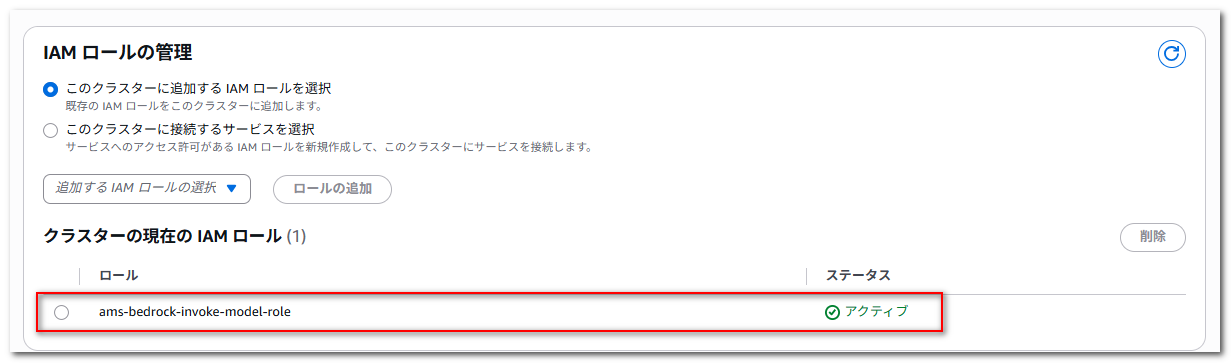
追加後、「ステータス」が「アクティブ」になっていることを確認します。
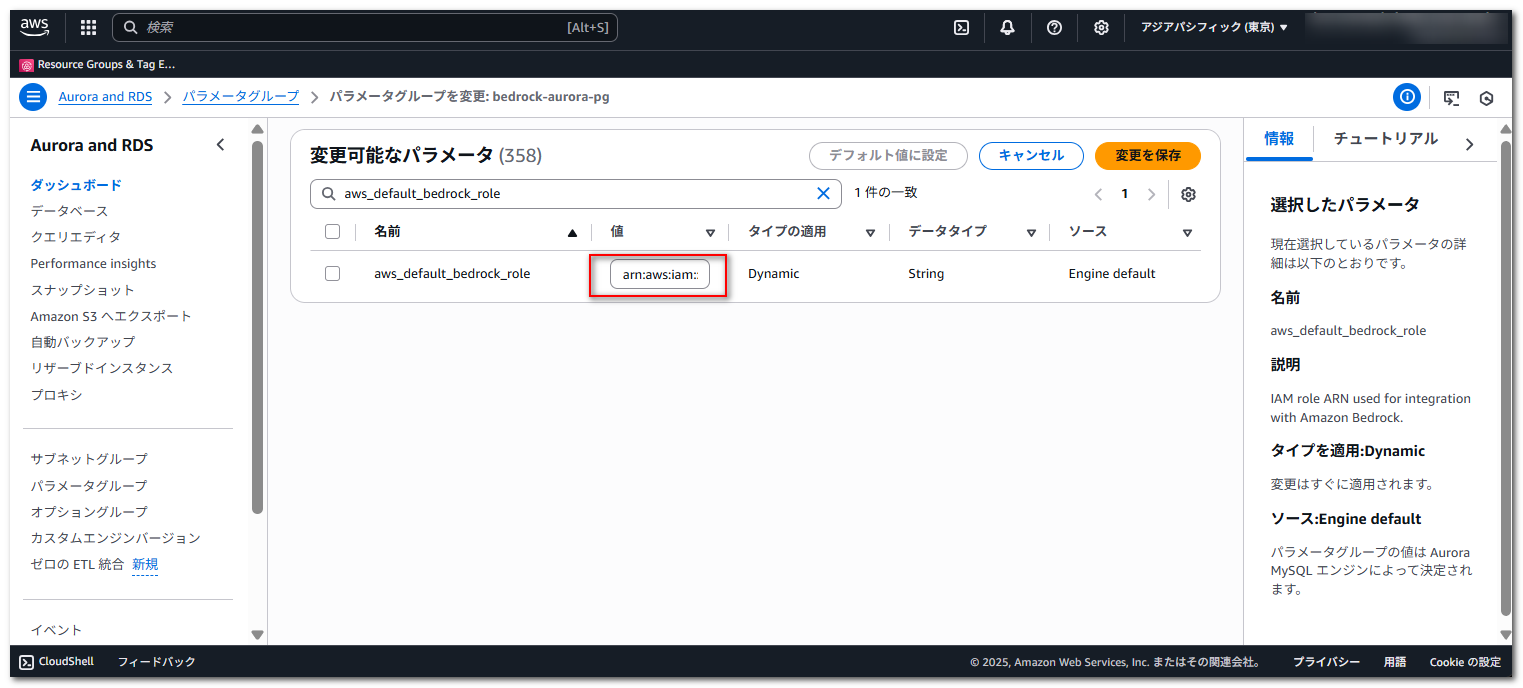
DB クラスターパラメータを設定
Aurora MySQLのクラスターパラメータグループの「aws_default_bedrock_role」に、先程ロールを作成した際にメモした「ARN」を設定し、インスタンスを再起動します。
再起動後、Aurora MySQLに接続し、設定したパラメータを確認します。
|
1 |
SHOW GLOBAL VARIABLES LIKE 'aws_default_bedrock_role'; |
上記SQLを実行し、以下のように出力されることを確認します。
|
1 2 3 4 5 |
+--------------------------+--------------------------------------------------------------+ | Variable_name | Value | +--------------------------+--------------------------------------------------------------+ | aws_default_bedrock_role | arn:aws:iam::{省略}:role/ams-bedrock-invoke-model-role | +--------------------------+--------------------------------------------------------------+ |
検証①
それでは、実際に使用してみましょう。
まずは、ユーザにBedrockにアクセスする為に、 AWS_BEDROCK_ACCESS 権限を付与します。
|
1 |
GRANT AWS_BEDROCK_ACCESS TO {ログインユーザ}; |
次に、BedrockにアクセスするFUNCTIONを定義します。
以下では、Claude Sonnet 4 を定義しています。
(事前にBedrockでClaude Sonnet 4へのアクセスをリクエストを完了している必要があります。)
|
1 2 3 4 5 6 |
CREATE FUNCTION invoke_claude_sonnet4 (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'apac.anthropic.claude-sonnet-4-20250514-v1:0' CONTENT_TYPE 'application/json' ACCEPT 'application/json'; |
- 定義するFUNCTIONの詳細と、指定するMODEL IDについては、以下のリファレンスをご確認下さい
その後、作成したFUNCTIONに EXECUTE 権限を付与します。
|
1 |
GRANT EXECUTE ON FUNCTION blog.invoke_claude_sonnet4 TO {ログインユーザ}; |
以上で準備は完了したので、以下のように実行してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT invoke_claude_sonnet4( JSON_OBJECT( 'anthropic_version', 'bedrock-2023-05-31', 'max_tokens', 1000, 'messages', JSON_ARRAY( JSON_OBJECT( 'role', 'user', 'content', '日本の首都は?' ) ) ) ) AS claude_response\G |
正常にチャットの回答が返されています。
|
1 2 3 |
*************************** 1. row *************************** claude_response: {"id":"msg_bdrk_01J72nobm6Er97vfN5sLjEAS","type":"message","role":"assistant","model":"claude-sonnet-4-20250514","content":[{"type":"text","text":"日本の首都は東京です。"}],"stop_reason":"end_turn","stop_sequence":null,"usage":{"input_tokens":15,"cache_creation_input_tokens":0,"cache_read_input_tokens":0,"output_tokens":14}} 1 row in set (0.96 sec) |
検証②
単純にチャットをするだけでは実用性がないので、今度は仮想ECサイトを例に、購入履歴を元にしたレコメンデーション情報を作成してみます。
商品情報としては、以下のような情報があります。
|
1 |
SELECT * FROM products; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
+----+------------------------------------+--------------------------------+-----------------------+-----------+--------------------------------------------------------------------------------------+ | id | name | category | subcategory | price | description | +----+------------------------------------+--------------------------------+-----------------------+-----------+--------------------------------------------------------------------------------------+ | 1 | iPhone 15 Pro | 家電 | スマートフォン | 159800.00 | 最新のA17 Proチップ搭載。プロ仕様のカメラシステム | | 2 | MacBook Air M3 | 家電 | ノートPC | 164800.00 | 薄型軽量で長時間バッテリー。M3チップで高性能 | | 3 | AirPods Pro | 家電 | オーディオ | 39800.00 | アクティブノイズキャンセリング機能付きワイヤレスイヤホン | | 4 | Sony WH-1000XM5 | 家電 | オーディオ | 49500.00 | 業界最高クラスのノイズキャンセリング | | 5 | Nintendo Switch | 家電 | ゲーム機 | 32978.00 | 家でも外でも楽しめるゲーム機 | | 6 | iPad Air | 家電 | タブレット | 92800.00 | 軽量で高性能なタブレット | | 7 | Kindle Oasis | 家電 | 電子書籍 | 40980.00 | 防水機能付き電子書籍リーダー | | 8 | ユニクロ ヒートテック | ファッション | インナー | 1290.00 | 保温性に優れた機能性インナー | | 9 | Nike エアマックス | ファッション | スニーカー | 14300.00 | 快適なクッション性のランニングシューズ | | 10 | カシミア セーター | ファッション | トップス | 19800.00 | 上質なカシミア100%のセーター | | 11 | レザー ビジネスバッグ | ファッション | バッグ | 25000.00 | 本革を使用したビジネス向けバッグ | | 12 | 腕時計 Classic | ファッション | アクセサリー | 35000.00 | シンプルで上品なデザインの腕時計 | | 13 | Python機械学習入門 | 本・学習 | プログラミング | 3960.00 | Python初心者向けの機械学習入門書 | | 14 | 英語学習アプリ年間版 | 本・学習 | 語学 | 12000.00 | 本格的な英語学習アプリの年間利用券 | | 15 | ビジネス書ベストセラー | 本・学習 | ビジネス | 1760.00 | 今年話題のビジネス戦略本 | | 16 | 料理レシピ本 | 本・学習 | 料理 | 1980.00 | 初心者でも作れる簡単レシピ集 | | 17 | ダイソン掃除機 | ホーム・キッチン | 掃除用品 | 89800.00 | サイクロン式コードレス掃除機 | | 18 | バルミューダ トースター | ホーム・キッチン | キッチン家電 | 27500.00 | 完璧な焼き上がりを実現するトースター | | 19 | ル・クルーゼ 鍋 | ホーム・キッチン | 調理器具 | 35200.00 | フランス製の高品質ホーロー鍋 | | 20 | 無印良品 収納ボックス | ホーム・キッチン | 収納 | 2990.00 | シンプルで使いやすい収納ボックス | | 21 | ヨガマット | スポーツ・アウトドア | フィットネス | 5980.00 | 滑り止め付きの高品質ヨガマット | | 22 | ランニングシューズ | スポーツ・アウトドア | ランニング | 16500.00 | クッション性抜群のランニング専用シューズ | | 23 | キャンプテント | スポーツ・アウトドア | キャンプ | 45000.00 | 4人用防水テント | +----+------------------------------------+--------------------------------+-----------------------+-----------+--------------------------------------------------------------------------------------+ |
ユーザIDが 1 の「田中太郎さん」は、以下3つの商品を購入済みです。
- テーブル情報
- users:ユーザ情報
- purchases:購入履歴
- products:商品情報
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT u.name as user_name, u.age_group, u.gender, p.name, p.category, p.subcategory, p.price FROM users u INNER JOIN purchases pu ON u.id = pu.user_id INNER JOIN products p ON pu.product_id = p.id WHERE u.id = 1; |
|
1 2 3 4 5 6 7 |
+--------------+-----------+--------+--------------------------+--------------+-----------------------+-----------+ | user_name | age_group | gender | name | category | subcategory | price | +--------------+-----------+--------+--------------------------+--------------+-----------------------+-----------+ | 田中太郎 | 30代 | 男性 | iPhone 15 Pro | 家電 | スマートフォン | 159800.00 | | 田中太郎 | 30代 | 男性 | AirPods Pro | 家電 | オーディオ | 39800.00 | | 田中太郎 | 30代 | 男性 | Python機械学習入門 | 本・学習 | プログラミング | 3960.00 | +--------------+-----------+--------+--------------------------+--------------+-----------------------+-----------+ |
少し長くなりますが、以下のSQLを実行して、「田中太郎さん」の購入履歴を元にお勧めの商品を3つ提案してもらいましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
WITH user_unpurchased AS ( SELECT p.id, p.name, p.category, p.price, p.description FROM products p WHERE p.id NOT IN ( SELECT DISTINCT product_id FROM purchases WHERE user_id = 1 ) ), user_profile AS ( SELECT u.name, u.age_group, u.gender, GROUP_CONCAT(DISTINCT CONCAT(p.name, '(', p.category, ')') SEPARATOR ', ') as purchase_history FROM users u JOIN purchases pu ON u.id = pu.user_id JOIN products p ON pu.product_id = p.id WHERE u.id = 1 GROUP BY u.id, u.name, u.age_group, u.gender ) SELECT up.name as user_name, up.age_group, up.gender, up.purchase_history, JSON_UNQUOTE(JSON_EXTRACT( invoke_claude_sonnet4( JSON_OBJECT( 'anthropic_version', 'bedrock-2023-05-31', 'max_tokens', 1200, 'temperature', 0.2, 'messages', JSON_ARRAY( JSON_OBJECT( 'role', 'user', 'content', CONCAT( '【ECサイト商品推薦タスク】', 'ユーザー: ', up.name, ' (', up.age_group, ', ', up.gender, ')', '、購入履歴: ', up.purchase_history, '。以下の未購入商品リストから、このユーザーに最適な商品を3つ選んで推薦理由を説明してください:', (SELECT GROUP_CONCAT(CONCAT('「', name, '」(', category, ', ¥', FORMAT(price, 0), ')') SEPARATOR ', ') FROM user_unpurchased), '。※必ずリスト内の商品名を正確に使用してください。' ) ) ) ) ), '$.content[0].text' )) as recommendations FROM user_profile up\G |
実行結果は以下のようになりました。
購入履歴からの推薦商品として、妥当な結果ではないでしょうか。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
*************************** 1. row *************************** user_name: 田中太郎 age_group: 30代 gender: 男性 purchase_history: AirPods Pro(家電), iPhone 15 Pro(家電), Python機械学習入門(本・学習) recommendations: 田中太郎さんの購入履歴を分析すると、Apple製品への強い親和性と機械学習への学習意欲が見て取れます。以下の3商品を推薦いたします: ## 推薦商品 ### 1. MacBook Air M3(¥164,800) **推薦理由:** - iPhone 15 ProとAirPods Proを既に所有しており、Apple エコシステムの完成度を高められる - Python機械学習の学習において、より本格的な開発環境が構築可能 - 30代男性のプロフェッショナルなワークスタイルにマッチする高性能デバイス ### 2. iPad Air(¥92,800) **推薦理由:** - 既存のApple製品との連携により、シームレスな作業環境を実現 - 機械学習の学習時に、資料閲覧や手書きメモ、プレゼンテーション作成に活用可能 - iPhone 15 Proとの組み合わせで、モバイルワークの効率が大幅に向上 ### 3. 英語学習アプリ年間版(¥12,000) **推薦理由:** - Python機械学習を学習中であることから、継続的なスキルアップ志向が強い - 技術分野では英語力が重要であり、機械学習の最新情報は英語圏から発信されることが多い - 既存のAppleデバイスで学習でき、通勤時間等を有効活用可能 これらの商品は田中さんの技術志向とApple製品への親和性を考慮し、学習効率とワークスタイルの向上を実現する組み合わせとなっています。 |
ただ、実行時間に30秒程要したのと、対象ユーザの購入商品と販売している商品情報を全てLLMに渡す必要があり、
トークンも大量に消費してしまうことが想定されるので、このようなケースでは、RAGを組む方が適切な実装方法かなと思います。
※ちなみに、現時点では、Aurora MySQLのAuto MLではベクトルストアが使用できない為、RAGを組むようなことはできませんが、 Heatwave on AWS の GenAI ならベクトルストアを使用したRAGも実現できます。
まとめ
Aurora MySQLとBedrockを連携させたAurora MLの使用方法について、事前に必要な設定から簡単な使用例までを解説してみました。
今回は、簡単な使用例で確認しましたが、データベースに格納された情報を最大限に活用したい現代のアプリケーション開発において、Aurora MLを活用できる用途は多岐に渡り、複雑なデータ移動や変換処理なしに、SQL文一つで高度なAI機能を利用できる点は、開発者にとって大きなメリットといえるでしょう。








