
はじめに
皆さん、Amazon RDSやAmazon Auroraのスナップショットデータを、HeatWave Lakehouseで扱えることをご存知でしょうか。
下記のとおり、Amazon RDSのDB スナップショットデータを Amazon S3 バケット(以降、Amazon S3)にエクスポートするとParquet 形式で保存されます。
DB スナップショットを Amazon S3 バケットにエクスポートすると、Amazon RDS はデータを Parquet 形式に変換してエクスポートし、保存します。
引用元:Amazon RDS の Amazon S3 バケットにエクスポートする際のデータ変換
HeatWave Lakehouseでは、インポートデータとしてParquet形式をサポートしているので、理論上Amazon S3にエクスポートされたデータをそのまま直接読み込むことができます。
本ブログでは、Amazon AuroraのスナップショットのエクスポートデータをHeatWave Lakehouseで本当に読み込めるのかどうか確認します。
また、HeatWave Lakehouseの基本的な使い方については、弊社ブログのHeatWave Lakehouse を試してみたでもご紹介していますのでご参照ください。
検証の流れ
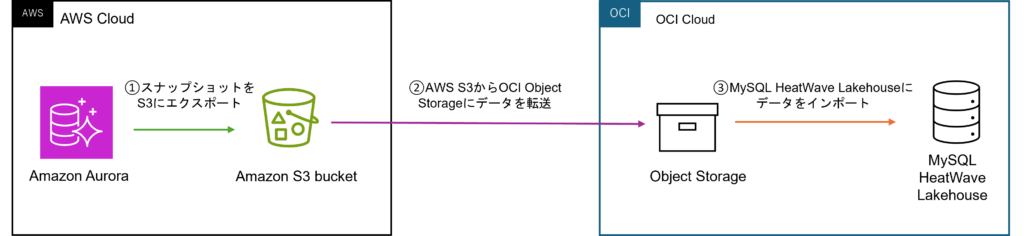
今回は以下の手順で検証を行います。
- Amazon AuroraのスナップショットをAmazon S3にエクスポートする
- Amazon S3 からOCI Object Storageにデータをコピーする
- OCI Object StorageからMySQL HeatWave Lakehousにデータをインポートする
1.Amazon AuroraのスナップショットをAmazon S3にエクスポートする
まずは、Amazon AuroraのスナップショットをAmazon S3に取得していきます。
詳細な説明はAmazon公式ドキュメントをご確認ください。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/USER_CreateSnapshotCluster.html
1-1.Amazon Auroraのスナップショットを作成する
-
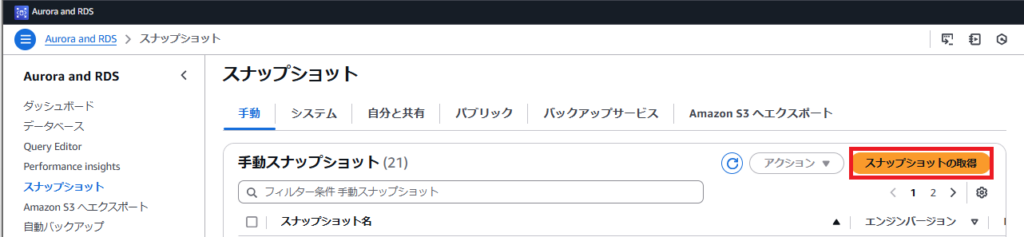
Amazonのスナップショット画面にて「スナップショットの取得」ボタンを押下します。
-
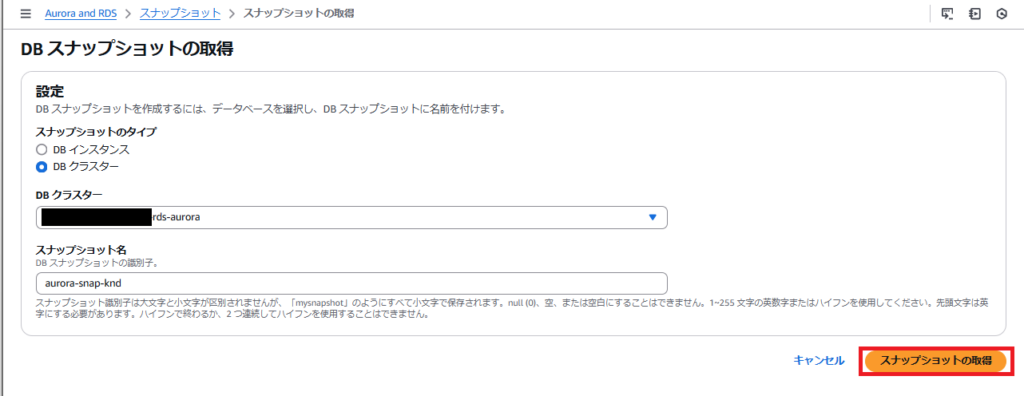
DBスナップショットの取得画面にて、以下の設定を行いAmazon Auroraのスナップショットを取得します。
- スナップショットのタイプ:DBクラスター
- DBクラスター:自身が作成したDBインスタンス(今回はAmazon Auroraのインスタンスを選択)
- スナップショット名:任意(今回はaurora-snap-knd)
-
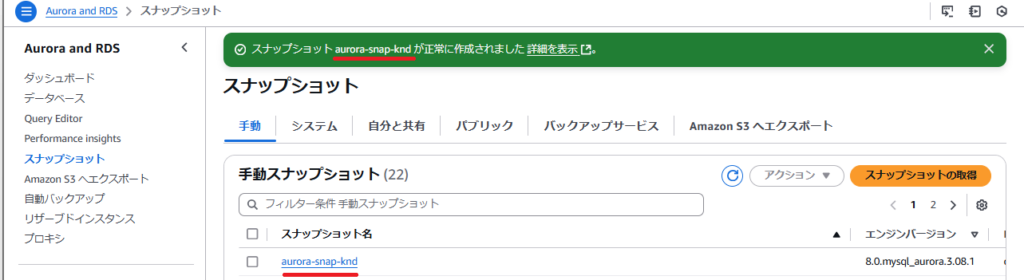
しばらくすると、スナップショットが作成されます。
1-2. スナップショットをAmazon S3にエクスポートする
今回は AWS CLI を使用して Amazon Auroraのスナップショットを Amazon S3 にエクスポートします。
start-export-task コマンドを指定することで簡単にエクスポートできてしまいます。
オプションの詳細については公式ドキュメントをご確認ください。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_ExportSnapshot.html#USER_ExportSnapshot.Exporting
|
1 2 3 4 5 6 7 |
start-export-task --export-task-identifier:エクスポートタスク名(任意) --source-arn:スナップショットのARN --s3-bucket-name:S3のバケット名 --iam-role-arn:エクスポートタスクが実行できるIAMロール --kms-key-id:AWS S3バケットの暗号化設定で指定したAWS KMSキーのID --export-only:エクスポートするスキーマ |
以下の例では、スナップショットエクスポートタスクは knd-snapshot-export と名前が付けられ、スナップショットを ss-knd-test-bucket という名前の Amazon S3に、worldスキーマのみをエクスポートします。
|
1 2 3 4 5 6 7 |
aws rds start-export-task \ --export-task-identifier knd-snapshot-export \ --source-arn arn:arn:aws:rds:xx-xxxxxxxxx-x:xxxxxxxxxxxx:cluster-snapshot:aurora-snap-knd \ --s3-bucket-name ss-knd-test-bucket \ --iam-role-arn arn:aws:iam::xxxxxxxxxxxx:role/xx-xxx-xx-xxxxxx-xxxx \ --kms-key-id xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx \ --export-only "world" |
また、今回は実証しませんが、--export-onlyオプションを省略することで全てのスキーマをエクスポートすることができます。
エクスポートタスクを実行し、しばらくするとAmazon S3バケット内にスナップショットがエクスポートされます。
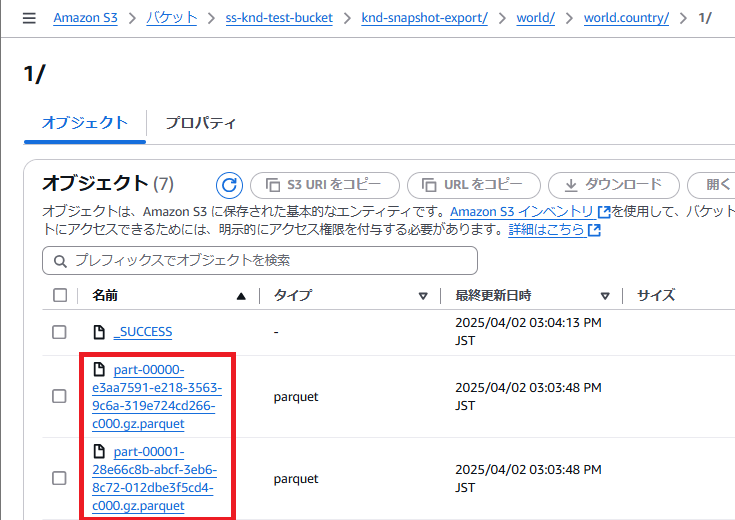
Amazon S3に保存されたエクスポートデータの形式を確認すると、しっかりとParquet形式で保存されています。
これで、AWS側の準備は完了です!
2.Amazon S3のスナップショットデータをOCI Ocject Storageに移行する
続いて、Amazon S3からOCI Object Storageにデータ転送します。
データ転送については、Rcloneというクラウドバックエンド間でファイルやディレクトリを同期するコマンドラインユーティリティを使用します。
参考:https://rclone.org/
今回はOCIのコンピュートインスタンス上にRcloneをインストールし、Amazon S3からOCI Object Storageにデータを転送します。
2-1.Rcloneのインストール
OCIのコンピュートインスタンス上で以下のコマンドを実行し、インストールします。
|
1 |
curl https://rclone.org/install.sh | sudo bash |
2-2.Rcloneの設定(転送元と転送先の設定)
RcloneにAWSとOCIの接続設定を行うのですが、接続設定に必要な情報を事前に確認しておきたいと思います。
2-2-1.OCI(転送先)の情報取得
転送先であるOCIの接続設定に必要な以下の情報を取得していきます。
|
1 2 3 4 5 6 |
① 顧客秘密キー - アクセスキー - 秘密キー ② リージョン識別子 ③ オブジェクトストレージネームスペース ④ APIエンドポイント(自分で作成するため後述) |
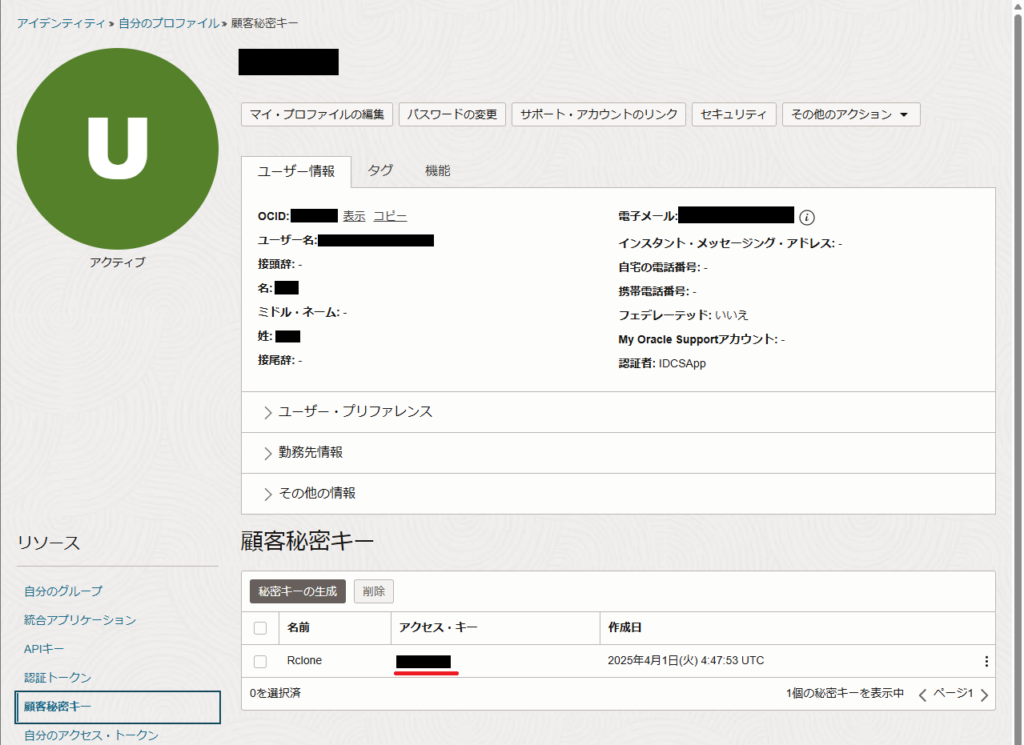
①顧客秘密キー(アクセスキーと秘密キー)
ユーザプロファイル画面から使用する顧客秘密キーのアクセスキーを確認します。また、対応する秘密キーは顧客秘密キー生成時に控えてある値を確認してください。
(顧客秘密キーの秘密キーは、生成時以降に再表示されません。秘密キーを忘れた場合や顧客秘密キーがない場合は新規に生成してください。)
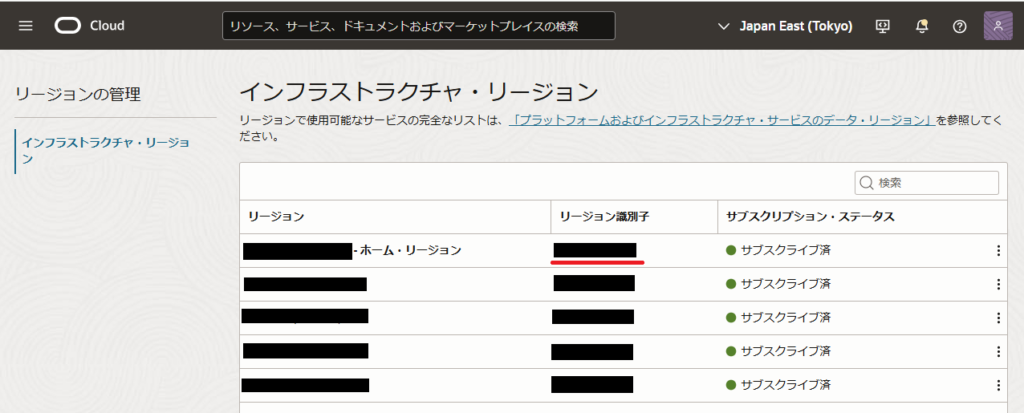
②リージョン識別子
リージョン管理のインフラストラクチャ・リージョン画面より、リージョン識別子を確認します。
(例:Tokyoリージョンならならap-tokyo-1)
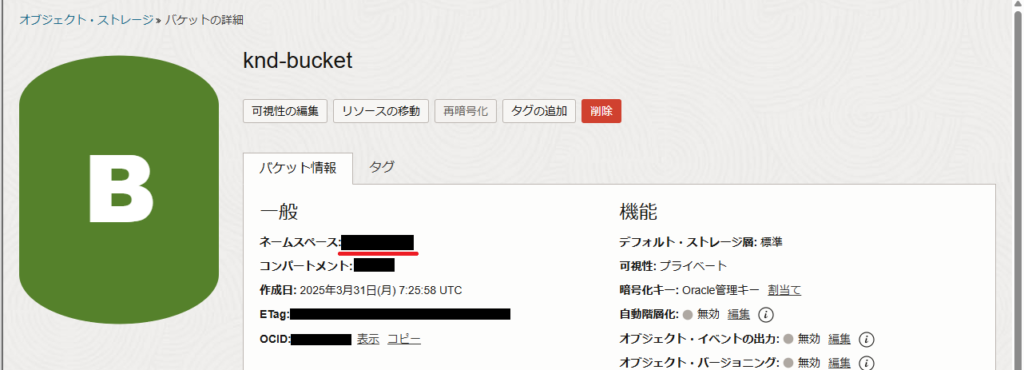
③オブジェクトストレージネームスペース
オブジェクトストレージのバケット詳細画面にて、AWS S3からデータを受け取るバケットのネームスペースを確認します。
④APIエンドポイントについて
先ほど取得した「②リージョン識別子」と「③オブジェクトストレージネームスペース」の値に置き換えて、以下のAPIエンドポイントの文字列を作成します。
|
1 |
https://<オブジェクトストレージネームスペース>.compat.objectstorage.<リージョン識別子>.oraclecloud.com |
OCIの接続情報の確認は以上です。
2-2-2.AWS(転送元)の情報取得
次に転送元であるAWSの接続設定に必要な情報を取得していきます。
|
1 2 3 |
①アクセスキー - アクセスキー - シークレットアクセスキー |
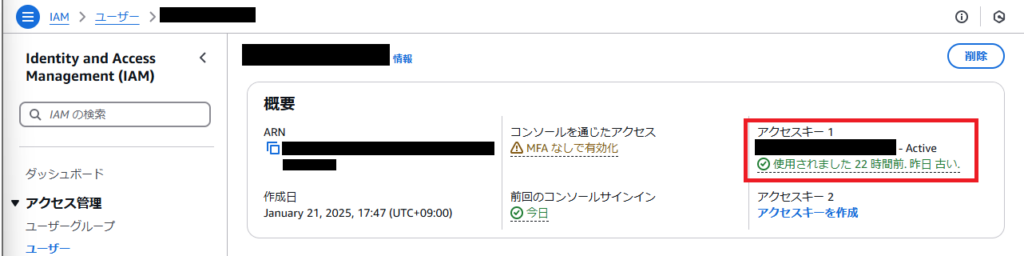
①アクセスキー(アクセスキーとシークレットアクセスキー)
IAMユーザ情報画面の概要欄にアクセスキーがあるので、使用するアクセスキー情報を確認します。また、対応するシークレットアクセスキーはアクセスキー生成時に控えてある値を確認してください。
(シークレットアクセスキーは、生成時以降に再表示されません。シークレットアクセスキーを忘れた場合やアクセスキーがない場合は新規に生成してください。)
AWSの接続情報の確認はこれだけでOKです。
2-3.RcloneのOCI(転送先)接続設定
先ほどの手順2-2-1.で取得したOCI接続情報を使って、rclone configコマンドで接続設定します。
- rclone configコマンドを実行します。新規に接続情報を作成するか聞かれるので 「n」 を入力します。
12345[opc@oracle-seminar-inst ~]$ rclone configNo remotes found, make a new one?n) New remote:(中略)n/s/q> n - 接続名を入力します。OCI側の接続設定を行うので、ここでは分かりやすく 「oci」 とします。
12Enter name for new remote.name> oci -
ストレージ・プロバイダーとプロバイダーを選択します。ここでは、ストレージ・プロバイダーは S3準拠なので 「4(S3準拠のストレージ・プロバイダー) 」、プロバイダーは 「34(他のS3互換プロバイダー)」を選択します。
(筆者はプロバイダー情報の選択を誤り、この後のOCI接続確認でエラーになりました。気をつけてください。)1234567891011121314151617Option Storage.Type of storage to configure.Choose a number from below, or type in your own value.:(中略)4 / Amazon S3 Compliant Storage Providers including AWS, Alibaba, ArvanCloud, Ceph, ChinaMobile, Cloudflare, DigitalOcean, Dreamhost, GCS, HuaweiOBS, IBMCOS, IDrive, IONOS, LyveCloud, Leviia, Liara, Linode, Magalu, Minio, Netease, Outscale, Petabox, RackCorp, Rclone, Scaleway, SeaweedFS, Selectel, StackPath, Storj, Synology, TencentCOS, Wasabi, Qiniu and others\ (s3):(中略)Storage> 4Option provider.Choose your S3 provider.Choose a number from below, or type in your own value.Press Enter to leave empty.:(中略)34 / Any other S3 compatible provider\ (Other)provider> 34 - 次のステップで認証情報を入力するので 「1」 を選択します。
1234567Option env_auth.Get AWS credentials from runtime (environment variables or EC2/ECS meta data if no env vars).:(中略)1 / Enter AWS credentials in the next step.\ (false):(中略)env_auth> 1
-
OCIの顧客秘密キー情報(アクセスキーと秘密キー)を入力します。(手順2-2-1.で調べた値を入力)
1234567891011Option access_key_id.AWS Access Key ID.Leave blank for anonymous access or runtime credentials.Enter a value. Press Enter to leave empty.access_key_id> <アクセスキーを入力>Option secret_access_key.AWS Secret Access Key (password).Leave blank for anonymous access or runtime credentials.Enter a value. Press Enter to leave empty.secret_access_key> <秘密キーを入力> - リージョン識別子を入力します。(手順2-2-1.で調べた値を入力)
1234567Option region.Region to connect to.Leave blank if you are using an S3 clone and you don't have a region.Choose a number from below, or type in your own value.Press Enter to leave empty.:(中略)region> <リージョン識別子を入力>
- APIエンドポイントを入力します。(手順2-2-1.で調べた値を入力)
12345Option endpoint.Endpoint for S3 API.Required when using an S3 clone.Enter a value. Press Enter to leave empty.endpoint> <APIエンドポイントを入力>
-
リージョン制約情報は入力せず、そのままEnterキーを押下し、ACL情報はデフォルトのままでよいので「1」を入力します。
12345678910Option location_constraint.:(中略)location_constraint> <入力せずEnterキーを押す>Option acl.:(中略)1 | No one else has access rights (default).\ (private):(中略)acl> 1 -
より詳細な設定を行うか聞かれますが、「n」を選択し設定を完了します。設定情報が表示されるので問題ないか確認します。
1234567891011121314Edit advanced config?y) Yesn) No (default)y/n> nConfiguration complete.Options:- type: s3- provider: Other- access_key_id: アクセスキー- secret_access_key: シークレットアクセスキー- region: リージョン識別子- endpoint: APIエンドポイント- acl: private
OCIへの接続確認
設定が成功していれば、以下のコマンドを実行することでOCI Object Storageにアクセスし、すべてのバケットを一覧表示します。
|
1 |
rclone lsd <remote-name>: |
ここでは< remote-name >には、先ほどの手順2-3-2.で入力した「oci」を入力し、無事にOCI Object Storage内にアクセスしバケットを取得することができました。
|
1 2 |
[opc@oracle ~]$ rclone lsd oci: -1 2025-03-31 07:25:58 -1 knd-bucket |
以上でOCIの接続設定が完了です。
2-4.RcloneのAWS の接続設定
引き続き、rclone configコマンドでAWS接続情報を設定します。入力手順がOCIの時と少し異なるので注意が必要です。
(2-2-2.で取得したAWS情報を使用します)
-
AWS接続情報を作成するので「n」を選択します。
12345678910[opc@oracle-seminar-inst ~]$ rclone configCurrent remotes:Name Type==== ====oic s3n) New remote:(中略)n/s/q> n -
接続名は「aws」と入力、ストレージ・プロバイダーは 「4(S3)」、プロバイダーは「1(AWS)」を選択します。
12345678910111213141516171819Enter name for new remote.name> awsOption Storage.Type of storage to configure.:(中略)4 / Amazon S3 Compliant Storage Providers including AWS, Alibaba, ArvanCloud, Ceph, ChinaMobile, Cloudflare, DigitalOcean, Dreamhost, GCS, HuaweiOBS, IBMCOS, IDrive, IONOS, LyveCloud, Leviia, Liara, Linode, Magalu, Minio, Netease, Outscale, Petabox, RackCorp, Rclone, Scaleway, SeaweedFS, Selectel, StackPath, Storj, Synology, TencentCOS, Wasabi, Qiniu and others\ (s3):(中略)Storage> 4Option provider.Choose your S3 provider.Choose a number from below, or type in your own value.Press Enter to leave empty.1 / Amazon Web Services (AWS) S3\ (AWS):(中略)provider> 1 - 次のステップでAWSの認証情報を入力するので「1」を選択します。
1234567Option env_auth.Get AWS credentials from runtime (environment variables or EC2/ECS meta data if no env vars).:(中略)1 / Enter AWS credentials in the next step.\ (false):(中略)env_auth> 1
-
アクセスキー情報(アクセスキーとシークレットアクセスキー)を入力します。(手順2-2-2.で調べた値を入力)
1234567891011Option access_key_id.AWS Access Key ID.Leave blank for anonymous access or runtime credentials.Enter a value. Press Enter to leave empty.access_key_id> <アクセスキーを入力>Option secret_access_key.AWS Secret Access Key (password).Leave blank for anonymous access or runtime credentials.Enter a value. Press Enter to leave empty.secret_access_key> <シークレットアクセスキーを入力> - リージョンを選択します。(例:Asia Pacific (Tokyo)なら13を選択)
1234567891011Option region.Region to connect to.Choose a number from below, or type in your own value.Press Enter to leave empty./ The default endpoint - a good choice if you are unsure.:(中略)13 | Needs location constraint ap-southeast-2.\ (ap-southeast-2)/ Asia Pacific (Tokyo) Region.:(中略)region> <該当するリージョン番号を入力>
-
エンドポイント、リージョン制約、ACLについては特に設定不要なので、何も入力せずそのままEnterキーを入力します。
1234567891011Option endpoint.:(中略)endpoint> <何も入力せずEnterキーを入力>Option location_constraint.:(中略)location_constraint> <何も入力せずEnterキーを入力>Option acl.:(中略)acl> <何も入力せずEnterキーを入力> - S3にオブジェクトを保存する際の暗号化アルゴリズムについて聞かれます。今回、S3にオブジェクトを保存する場合はKMS暗号化を使用しているので「aws:kms」と入力します。
12345678Option server_side_encryption.The server-side encryption algorithm used when storing this object in S3.Choose a number from below, or type in your own value.Press Enter to leave empty.:(中略)3 / aws:kms\ (aws:kms)server_side_encryption> aws:kms
Rcloneはデータ転送時にはMD5SUMテストを実施します。上記のオプションを選択しないと、OCIへデータコピーする際にチェックサム・エラーとなるので注意してください。
Rcloneのドキュメントに記載がありますので、ご確認ください。
https://rclone.org/s3/#key-management-system-kms -
KMSキーやストレージクラスについては特に設定は不要なので、何も入力せずにそのままEnterキーを入力します。
1234567Option sse_kms_key_id.:(中略)sse_kms_key_id> <何も入力せずEnterキーを入力>Option storage_class.:(中略)storage_class> <何も入力せずEnterキーを入力> - より詳細な設定を行うか聞かれますが、「n」を選択し設定を完了します。設定情報が表示されるので問題ないか確認します。
123456789101112Edit advanced config?y) Yesn) No (default)y/n> nConfiguration complete.Options:- type: s3- provider: AWS- access_key_id: <アクセスキー>- secret_access_key: <シークレットアクセスキー>- region: <リージョン識別子>- server_side_encryption: aws:kms
AWSへの接続確認
以下のコマンドを使って、Amazon S3の指定したバケットにアクセスしオブジェクトを一覧表示します。
取得に失敗する場合、rclone configコマンドの設定情報が間違っているので再度設定しなおしてください。
|
1 |
rclone ls <remote-name>:<aws-S3-bucket-name> |
ここでは< remote-name >には先ほど入力した「aws」を入力し、< aws-S3-bucket-name >には転送元となるバケット名を入力し、無事にAmazon S3内にアクセスすることができました。
|
1 2 3 4 5 |
[opc@oracle-seminar-inst ~]$ rclone ls aws:ss-knd-test-bucket 6937 knd-snapshot-export/world/world.city/1/part-00000-63000bec-485b-361e-8371-d0fbf1f36361-c000.gz.parquet 4532 knd-snapshot-export/world/world.city/1/part-00001-5bef9394-2329-33be-aa3d-4bda61082ba6-c000.gz.parquet 6239 knd-snapshot-export/world/world.city/1/part-00002-bfc0559d-75fb-3645-b8d4-236341389de0-c000.gz.parquet :(中略) |
以上でAWSの接続設定が完了です。
2-5.データをコピーの実施
以下のコマンドで、Amazon S3バケットのデータをOCI Object Storageへコピーします。
|
1 |
rclone --verbose --no-check-dest copy <aws-remote-name>:<aws-backet-name> <oci-remote-name>:<object-strage-name> |
今回はAWS S3のss-knd-test-bucketというバケットから、OCI Object Storageのknd-bucketというバケットにデータをコピーしました。
|
1 2 3 4 5 6 7 8 9 10 |
# バケットの中身をルートからルートへコピー $rclone --verbose --no-check-dest copy aws:ss-knd-test-bucket oci:knd-bucket 2025/04/02 06:45:00 INFO : knd-snapshot-export/world/world.city/1/part-00000-63000bec-485b-361e-8371-d0fbf1f36361-c000.gz.parquet: Copied (new) : :(中略) : 2025/04/02 06:45:00 INFO : Transferred: 140.030 KiB / 140.030 KiB, 100%, 0 B/s, ETA - Transferred: 30 / 30, 100% Elapsed time: 0.7s |
以上でAmazon S3からOCI Object Storageへのデータ転送が完了しました。
3.OCI Object Storageから HeatWave Lakehouseにデータをインポートする
最後に、OCI Object Storageに転送したAWS AuroraのスナップショットのエクスポートデータをHeatWave Lakehouseにインポートしてみます。
3-1.OCI Object Storageのバケット内データへのアクセス許可を取得する
まず、HeatWave Lakehouseからデータをインポートする前に、OCI CLIコマンドでバケット内のデータに対してPAR(事前認証済みリクエスト)を取得します。
OCI CLIコマンドによるPARの取得については、Pre-Authenticated Request Examplesとしてドキュメントに公開されていますのでご確認ください。
https://dev.mysql.com/doc/heatwave/en/mys-hw-lakehouse-par-examples.html
以下のコマンドではknd-bucketというオブジェクトストレージのバケット内のデータにアクセスするPAR(事前認証済みリクエスト)を取得します。
|
1 2 3 4 |
oci os preauth-request create --namespace <オブジェクトストレージネームスペース> --bucket-name knd-bucket \ --name par_read_country --access-type AnyObjectRead \ --bucket-listing-action ListObjects \ --time-expires="2025-04-03T00:00:00+00:00" |
コマンドが成功するとPARが取得できます。full-pathの値をデータインポート時に使用するので、控えておきましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "data": { "access-type": "AnyObjectRead", "access-uri": "/p/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xx-xxxxxxxxxxxxxxxxxxxxxxxx/n/xxxxxxxxxxxx/b/knd-bucket/o/", "bucket-listing-action": "ListObjects", "full-path": "https://objectstorage.xx-xxxxx-x.oraclecloud.com/p/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx/n/xxx-xxxxxx/b/oci-bucket/o/", "id": "xxxxxxxxx+xxxxxxxxxxxx+xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx+xxxxxx", "name": "par_read_country", "object-name": null, "time-created": "2025-04-02T08:14:07.330000+00:00", "time-expires": "2025-04-03T00:00:00+00:00" } } |
3-2.OCI Object Storage内のデータをHeatWave Lakehouseにインポートする
HeatWave Lakehouseでは、外部テーブルを使用してObject Storage内のデータをインポートすることができます。
コマンドの詳細はドキュメントをご確認ください。
https://dev.mysql.com/doc/heatwave/en/mys-hw-lakehouse-table-syntax.html
以下のコマンドでは、先ほどのknd-bucketバケットに対するPARを使用し、worldスキーマのcountryテーブルとcountrylanguageテーブルをインポートします。
ここで大切なことは、インポートするファイル形式がParquet形式であることです。Amazon S3のエクスポートデータと同じであるため、そのままファイルをインポートすることができてしまいます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
MySQL > CREATE DATABASE IF NOT EXISTS world; MySQL > SET @db_list = '["world"]'; MySQL > SET @ext_tables = '[{ "db_name": "world", "tables": [ { "table_name": "country", "dialect": { "format": "parquet"}, "file": [ {"par": "https://objectstorage.xx-xxxxx-x.oraclecloud.com/p/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx/n/xxx-xxxxxx/b/oci-bucket/o/", "prefix": "ss-knd-test-bucket/world/world.country/" } ] }, { "table_name": "countrylanguage", "dialect": { "format": "parquet"}, "file": [ {"par": "https://objectstorage.xx-xxxxx-x.oraclecloud.com/p/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx/n/xxx-xxxxxx/b/oci-bucket/o/", "prefix": "ss-knd-test-bucket/world/world.countrylanguage/" } ] } ] }]'; MySQL > SET @options = JSON_OBJECT('external_tables', CAST(@ext_tables AS JSON)); MySQL > CALL sys.heatwave_load(@db_list, @options); |
インポートが成功するとLOAD SUMMARYが出力され、HeatWave Lakehouse上でアクセスできるようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
MySQL SQL > CALL sys.heatwave_load(@db_list, @options); +------------------------------------------+ | INITIALIZING HEATWAVE AUTO PARALLEL LOAD | +------------------------------------------+ | Version: 3.10 | | | | Load Mode: normal | | Load Policy: disable_unsupported_columns | | Output Mode: normal | | | +------------------------------------------+ 6 rows in set (0.0281 sec) : : +-------------------------------------------------------------------------------+ | LOAD SUMMARY | +-------------------------------------------------------------------------------+ | | | SCHEMA TABLES TABLES COLUMNS LOAD | | NAME LOADED FAILED LOADED DURATION | | ------ ------ ------ ------- -------- | | <code>world</code> 2 0 19 18.46 s | | | +-------------------------------------------------------------------------------+ 6 rows in set (0.0074 sec) MySQL SQL > select count(*) from world.country; +----------+ | count(*) | +----------+ | 239 | +----------+ 1 row in set (0.0064 sec) MySQL SQL > select count(*) from world.countrylanguage; +----------+ | count(*) | +----------+ | 984 | +----------+ 1 row in set (0.0039 sec) |
まとめ
今回、Amazon S3のエクスポートデータをそのままHeatWave Lakehouseへインポートできることを確認できました。
AWS上のAmazon RDSやAmazon AuroraなどのDBインスタンスのスナップショットを使うことで、わざわざDBツールなどでバックアップを取らなくてもよい点だったり、AWS上に存在するDBの特定の静止点でのデータ分析をHeatWave Lakehouseでできちゃうという点が魅力的ですね!
皆さんもぜひ、HeatWave Lakehouseをお試しください!






