はじめに
今回の記事は、
Oracle Cloud Infrastructure(以下,OCI)のETLサービスでもあるData Integrationのビジュアルフローエディタを利用して、ある2つの対象データ・ソースの絞り込みから、
指定のカラム順でデータ・ソースを統合して、1つのCSVファイルとして、出力できるか検証してみます。
Data Integrationとは
Data Integrationは、
多様なデータ・ソースに対応しており、データを簡単に抽出し、変換してロードができるETLサービスです。
直感的なビジュアルフローエディタが利用でき、簡単にデータ・フローの設計もできます。
多様なデータ・ソースへの接続をサポートしており、データベース、データウェアハウス、アプリケーション、クラウドサービスなどへのデータ連携を容易に行うことも可能です。
また、Data Integrationは高いパフォーマンスを提供し、データを迅速に処理できるため、ビジネスの要件に合わせた迅速なデータ統合ができます。
なお、サポートされているデータ・ソースは、こちらのデータ・アセットをご参照してください。
さらに、開発者の生産性向上のためにソリューション・テンプレートが導入されていて、
事前定義されたエンティティとフィールド・マッピングを提供されており、異なるスキーマのソースと宛先のデータ・フローを容易に設計ができます。
引用:OCI Data Integrationの最新リリースを使用したバージョニングおよびライフサイクル管理
本記事の前提条件
- すでにData Integrationの構築をしている状態
- データ・ソースには、CSVファイルを使用
- ソースとターゲットの各CSVの格納場所は、オブジェクトストレージを使用
Data Integrationの構築については、OCI Data Integrationチュートリアルからご確認ください。
本記事では、OCI Data Integrationチュートリアルの【5.プロジェクトとデータ・フローの作成】の設計に関わるリソースのコンテナで必要な「プロジェクト」の作成までを、ご参照して頂ければと思います。
CSVファイルの確認
本記事で使用するデータ・ソースは、以下の2つのCSVファイルを作成し用意しています。
-
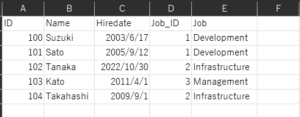
EMPLOYEE_TABLE.csvファイル(従業員テーブル)
-
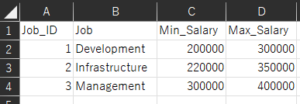
JOB_TABLE.csvファイル(JOBテーブル)
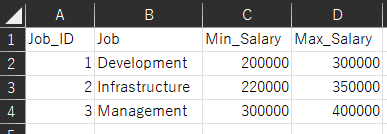
2つのCSVファイルを、Data Integrationのサービスを使用して、対象データの絞り込みと任意のカラム順で、
1つのCSVファイルへと結合して出力できるか検証してみます。
データ・ソースのCSVファイルをフォルダにアップロード
データ・ソースを、格納するために用意したオブジェクトストレージのバケットのフォルダに、
- 「EMPLOYEE_TABLE.csv」ファイル
- 「JOB_TABLE.csv」ファイル
の2つのCSVファイルをアップロードします。
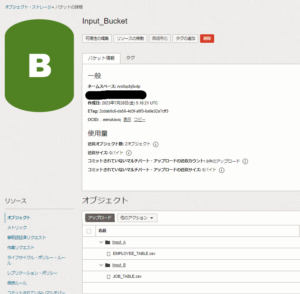
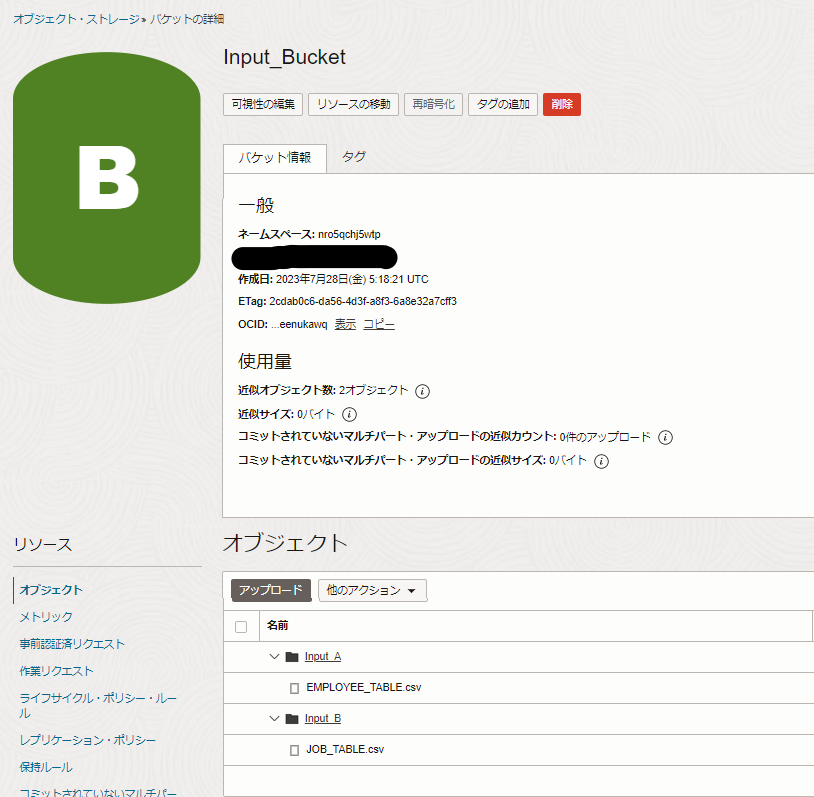
今回は、2つのCSVファイルを「Input_Bucket」という命名で、バケットを作成しました。
「Input_Bucket」バケットは、データ・ソースを格納するためのバケットです。
「Input_Bucket」バケットの中に、
- 「EMPLOYEE_TABLE.csv」ファイルは、「Input_A」フォルダへアップロード
- 「JOB_TABLE.csv」ファイルは、「Input_B」フォルダへアップロード
をしています。
ターゲットになるバケットの確認
CSVファイルの出力先であるターゲットは、
オブジェクトストレージ内に、バケットは「Output_Bucket」を作成しています。
1.データ・フローの作成
ソースの設定
それでは、Data Integrationの「データ・フロー」というデータの流れや操作を定義するリソースを作成してみます。
Data Integrationのホーム画面から、「プロジェクト」 > 「プロジェクトの作成」をクリックします。
プロジェクトを作成した後、「データ・フロー」 > 「データ・フローの作成」の順番で、クリックをすれば、データ・フロー・エディタというビジュアルエディタが起動します。
今回の「データ・フロー」のプロパティには、「DI_A」という命名で、「データ・フロー」を作成しています。
データ・フロー・エディタの左にある「ソース演算子」から「ソース演算子」をキャンバスにドラッグアンドドロップします。
2つのCSVファイルがデータ・ソースになるため、「ソース演算子」は2つ用意します。
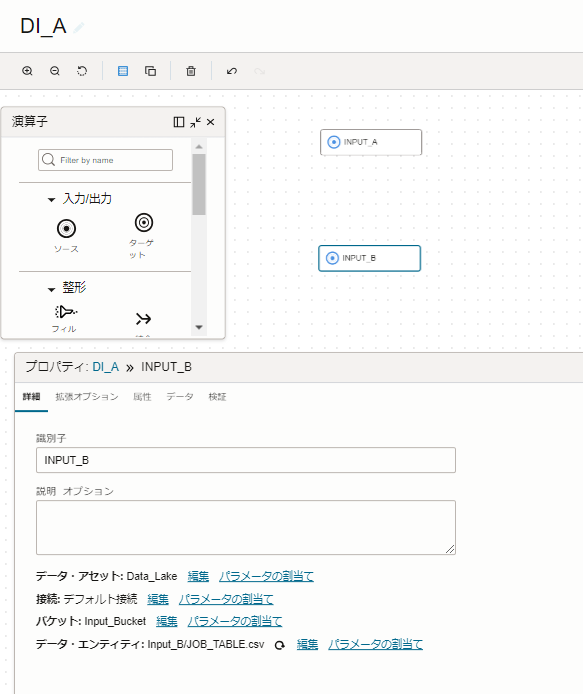
「ソース演算子」を選択後、キャンバスの下に、プロパティが表示されます。
プロパティの項目には、アップロードした2つのCSVファイルや、オブジェクトストレージの情報などを設定します。
今回は、2つの「ソース演算子」に、以下の値を入力しています。
|
1 2 3 4 5 |
- 識別子 :INPUT_A - データ・アセット : Data_Lake(データ・アセットの作成時に設定した命名) - 接続 : デフォルト接続 - スキーマ : Input_Bucket - データ・エンティティ : Input_A/EMPLOYEE_TABLE.csv |
|
1 2 3 4 5 |
- 識別子 :INPUT_B - データ・アセット : Data_Lake(データ・アセットの作成時に設定した命名) - 接続 : デフォルト接続 - スキーマ : Input_Bucket - データ・エンティティ : Input_B/JOB_TABLE.csv |
ソースの絞り込み
検証の1つでもあるデータ・ソースの絞り込みの設定をしていきます。
データ・フロー・エディタの左にある演算子から、「フィルタ演算子」をキャンバスに、ドラッグアンドドロップします。
「フィルタ演算子」のプロパティで、絞り込み条件の作成をしていきます。
今回の絞り込みの条件は、以下の通りです。
|
1 |
FILTER_1.INPUT_A.HIREDATE>='2011/4/1' |
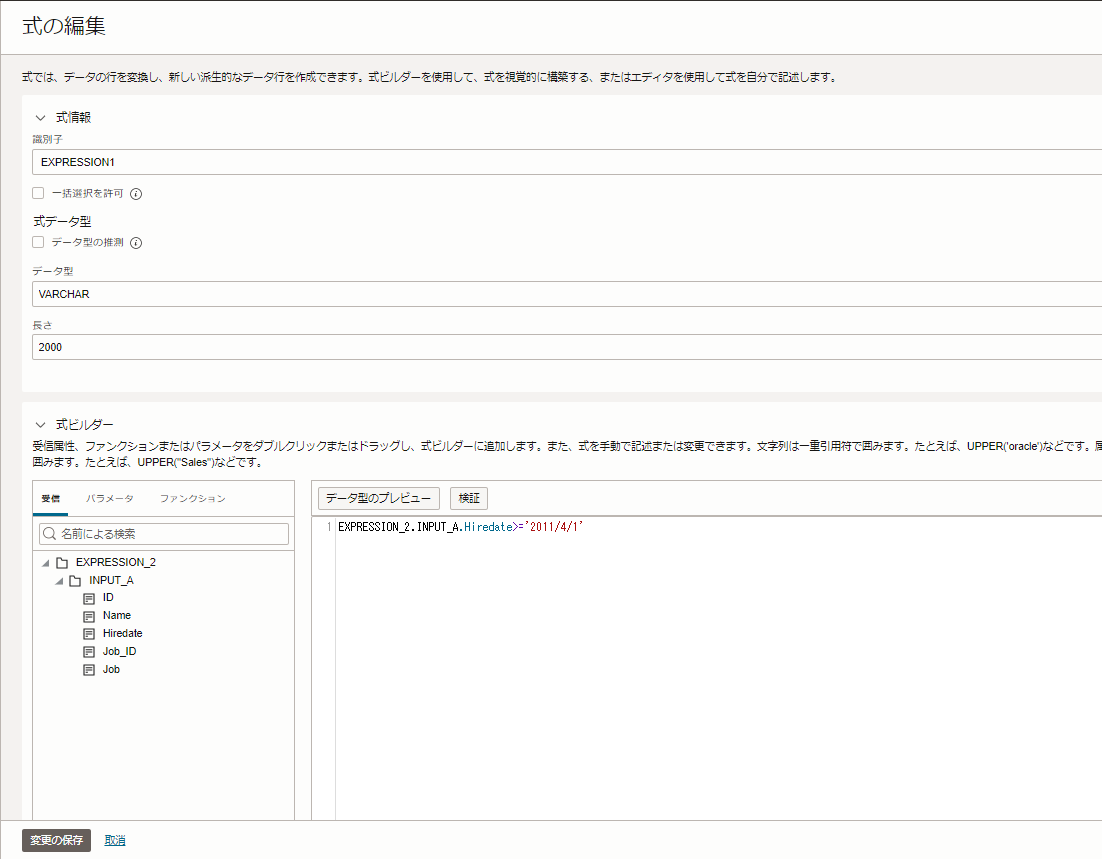
「INPUT_A」フォルダに格納している「EMPLOYEE_TABLE.csv」ファイルにある"Hiredate"のカラムに対して、"2011/4/1以降"の絞り込み条件を設定しました。
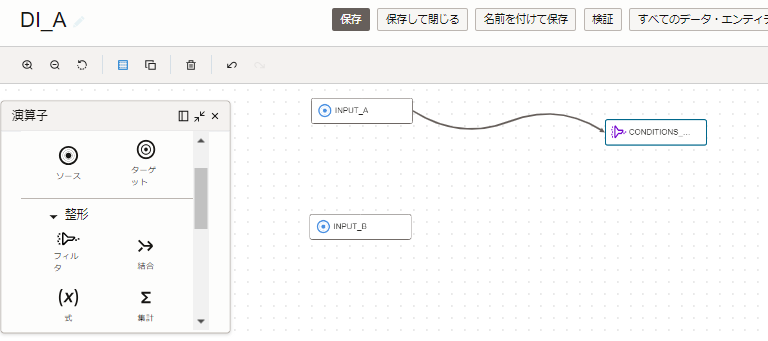
ソースの結合
絞り込みをした「EMPLOYEE_TABLE.csv」ファイルと、「JOB_TABLE.csv」ファイルを結合してみます。
データ・フロー・エディタの左にある演算子から、「結合演算子」をキャンバスに、ドラッグアンドドロップします。
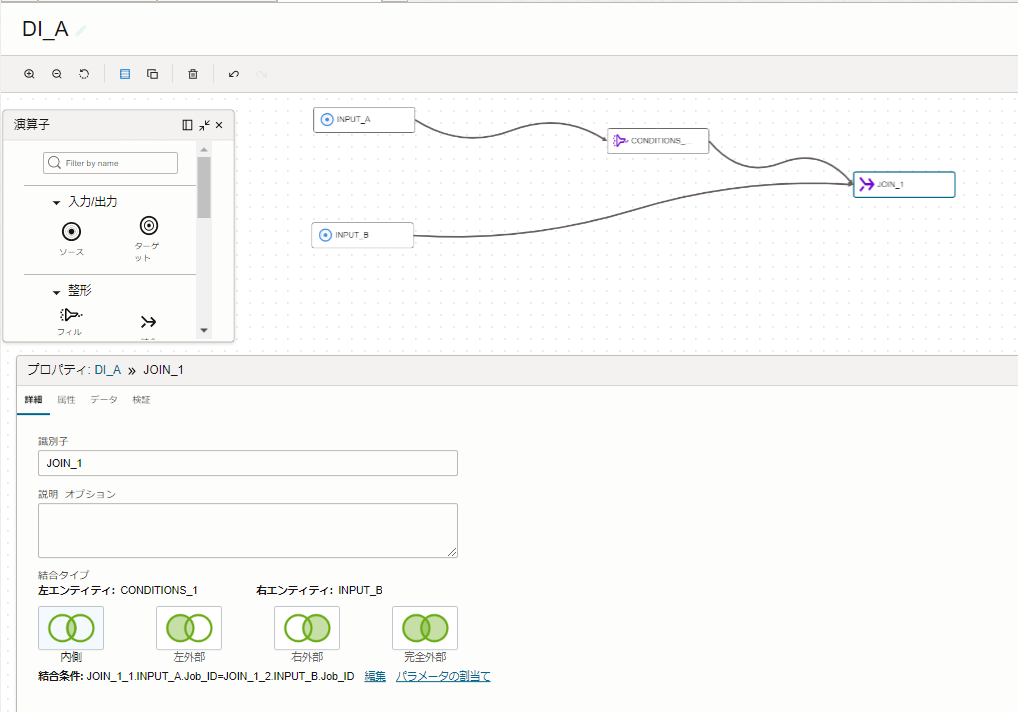
今回の結合としては、内部結合で2つのCSVファイルを結合していきます。
結合条件は、以下の通りです。
|
1 |
JOIN_1_1.INPUT_A.Job_ID=JOIN_1_2.INPUT_B.Job_ID |
「INPUT_A」フォルダに格納している「EMPLOYEE_TABLE.csv」ファイルにある"Job_ID"の値と、
「INPUT_B」フォルダに格納している「JOB_TABLE.csv」ファイルにある"Job_ID"の値が一致している場合を結合条件としています。
データの確認
絞り込みされた状態で、2つのCSVファイルのデータが結合されているか確認してみます。
「結合演算子」にある【データ】タブを選択します。
【データ】タブでは、データのプレビューが確認できます。
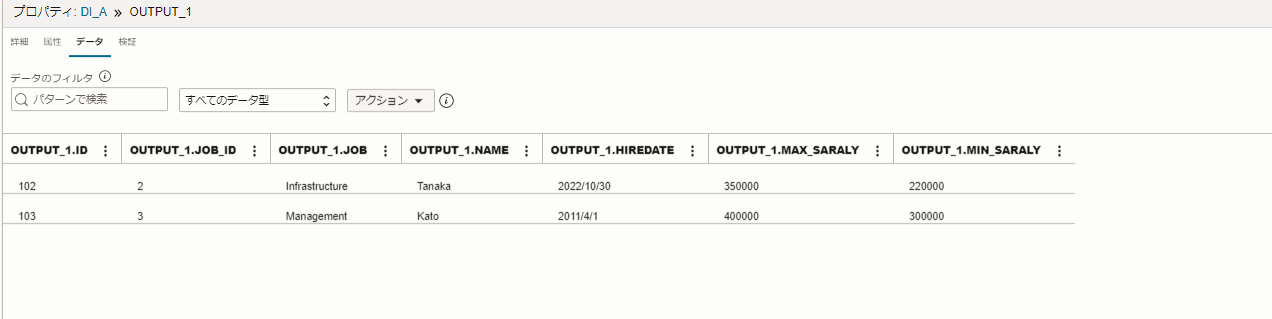
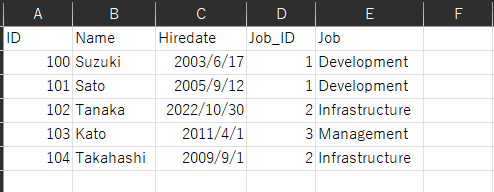
条件でもある"2011/4/1以降"として絞り込みされ、CSVファイルのデータが結合されているのを確認できました。
任意のカラム順で指定
最後の検証として、データ・ソースのカラムを任意の順番で指定して、CSVファイルへ出力をします。
元のデータ・ソースでもある2つのCSVファイルのカラム順と命名規則は、以下の通りで指定しています。
- 「EMPLOYEE_TABLE.csv」ファイルのカラム順と命名規則
12| ID | Name | Hiredate | Job_ID || ------|------| ---------| ------------| - 「JOB_TABLE.csv」ファイルのカラム順と命名規則
12| Job_ID | Job | Min_Salary | Max_Salary || -------- |------| -----------| ---------------|2つのCSVファイルのカラムの命名規則は、先頭の頭文字だけを大文字にしています。
今回の記事では、以下のカラム順と命名規則でCSVファイルへ出力を想定しています。
- 「Output.csv」ファイルのカラム順と命名規則
12| ID | JOB_ID | JOB |NAME |HIREDATE |MAX_SARALY |MIN_SARALY || ------|--------| --------------| ------------|---------- |-----------------|---------------|出力されたCSVファイルのカラムの命名規則は、全て大文字に変換しています。
データ・フロー・エディタの左にある演算子から、「式演算子」をキャンバスに、ドラッグアンドドロップします。
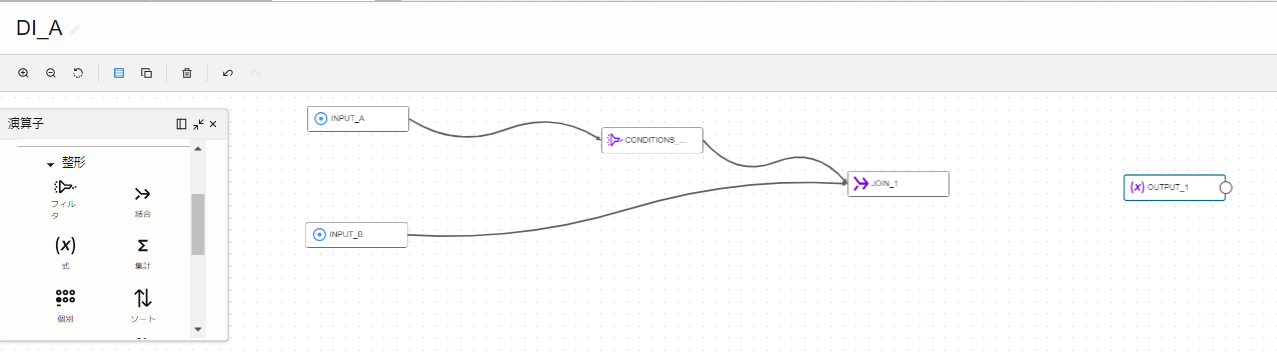
「式演算子」にある【式の追加】をクリックします。
「式ビルダー」の箇所に、2つのCSVファイルのデータ・ソースがあります。
任意のカラム順に、カラムをクリックします。
カラムをクリック後、「式演算子」のプロパティの"識別子"に、カラム名を入力します。
"識別子"は、CSV出力時に物理項目名となるので、任意のカラム名を入力してください。
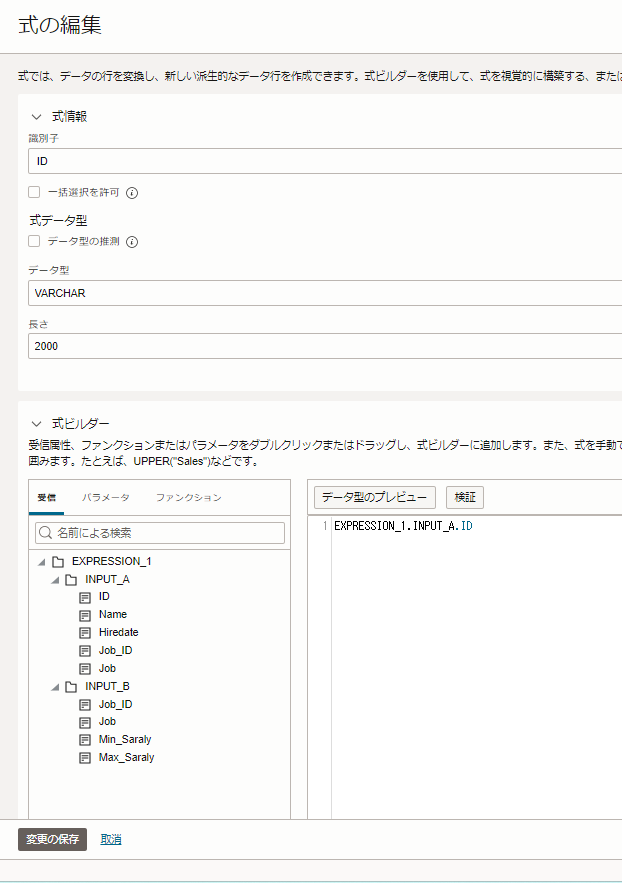
上記の作業を、任意のカラム順に変更するまで繰り返します。
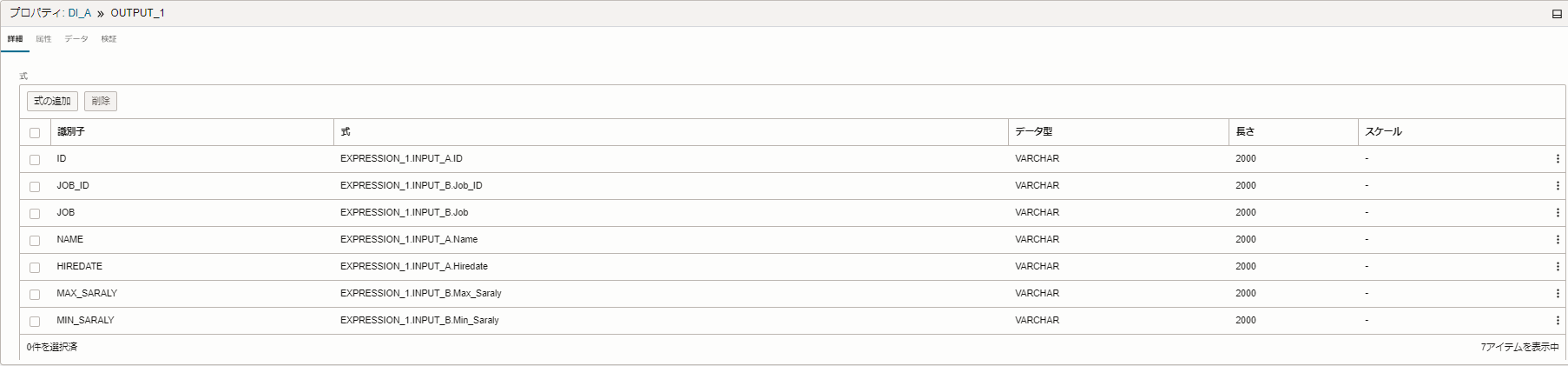
この時点で結合されたデータには、"物理項目名"と"論理項目名"が混同したデータになっているので、
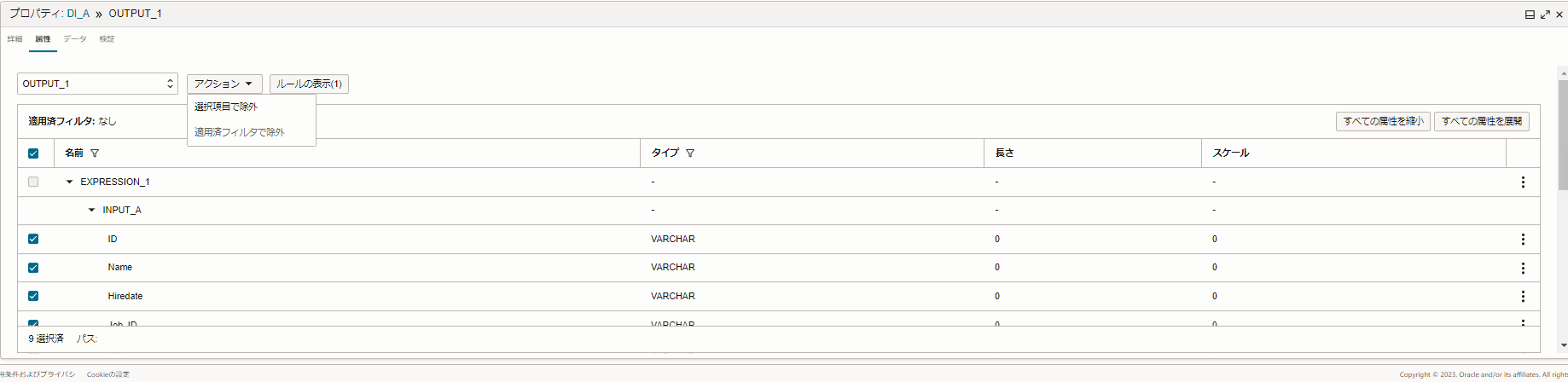
「式演算子」にある【属性】タブで、"物理項目名"を除外します。
【属性】タブから除外対象の"物理項目名"のカラムのチェックボックスにチェックをつけて、
「アクション」 > 「選択項目で除外」の順番で、クリックします。
ターゲットの作成
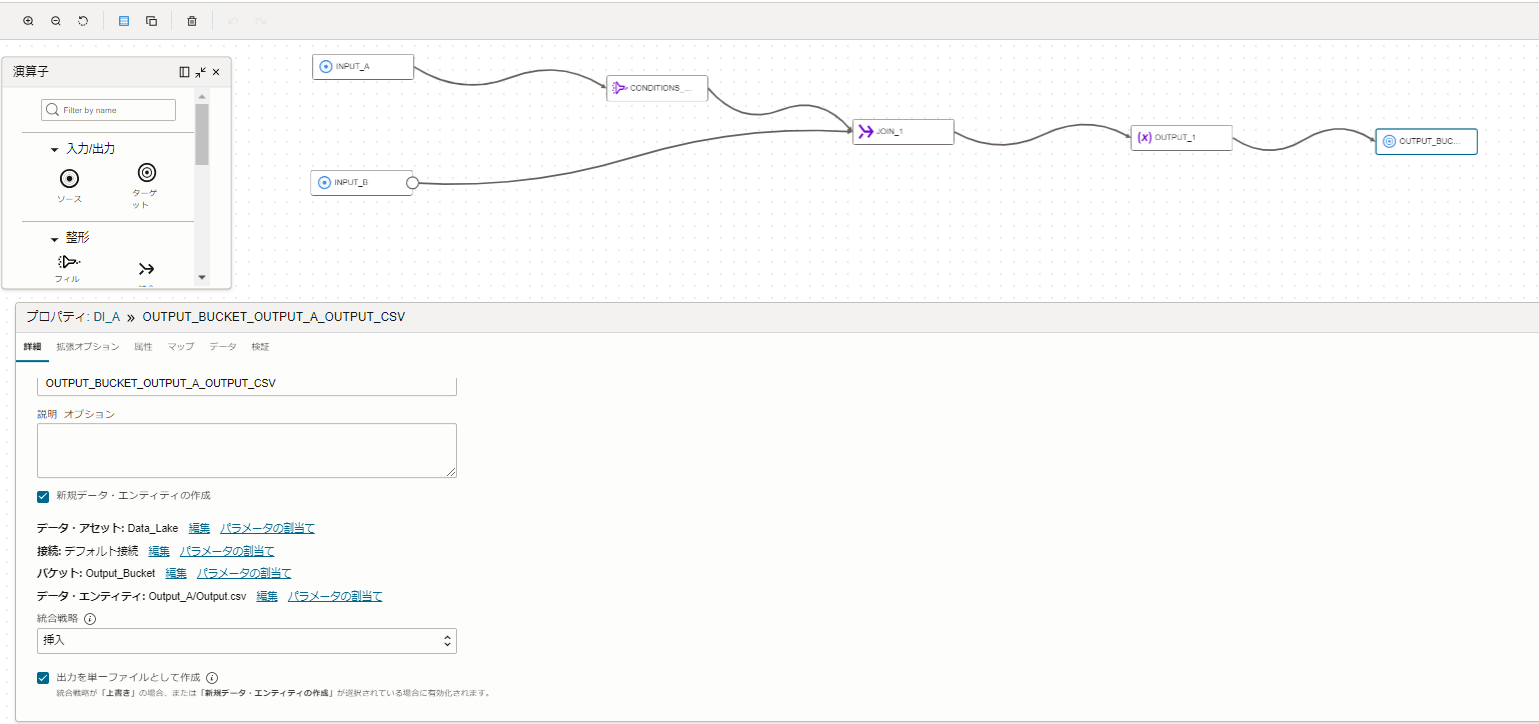
任意のカラム順で「式演算子」を追加した後は、結合したCSVファイルの出力したデータを格納するターゲットを作成します。
データ・フロー・エディタの左にある演算子から、「ターゲット演算子」をキャンバスに、ドラッグアンドドロップします。
「ターゲット演算子」に、以下の値を入力しています。
|
1 2 3 4 5 6 7 |
識別子 : OUTPUT_BUCKET_OUTPUT_A_OUTPUT_CSV 新規データ・エンティティの作成:チェック(新しいデータ・エンティティを作成するため) データ・アセット : Data_Lake(今回は、データ・ソースと同一のオブジェクトストレージを使用) 接続 : デフォルト接続 データ・エンティティ : Output_A/Output.csv(Output_Aフォルダに、「Output.csv」ファイルを出力) 統合戦略:挿入 出力を単一ファイルとして作成:チェック(今回は、タスクを実行する度に、「Output.csv」ファイルが上書きされるようにする) |
2.タスクの作成と公開
タスクの作成
データ・フローの作成が完了した後、「タスク」というデータに対する一連のアクションを指定するリソースを作成します。
「タスク」には種類がありますが、データ・フローを呼び出す場合は、"統合タスク"を使用しますので、
今回は、"統合タスク"を選択します。
「統合タスク」の作成については、プロジェクト画面から「タスク」 > 「タスクの作成」 > 「統合タスク」をクリックします。
「統合タスク」の作成で、以下の項目に値と設定をしました。
|
1 2 |
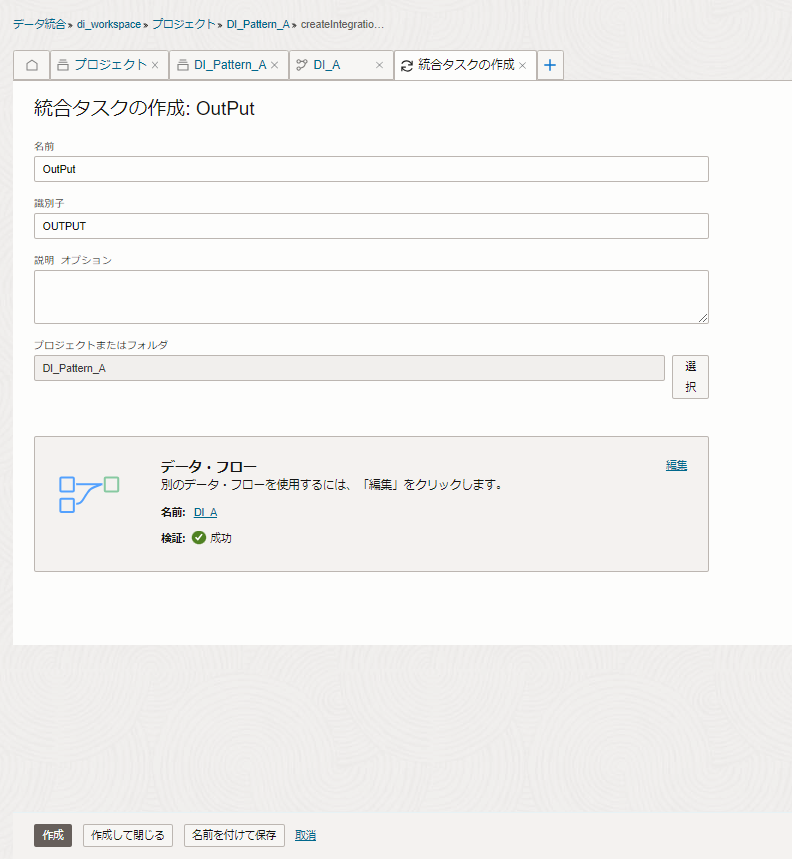
名前:Output データ・フロー:DI_A(選択リンクをクリックし、作成したデータ・フローを選択します) |
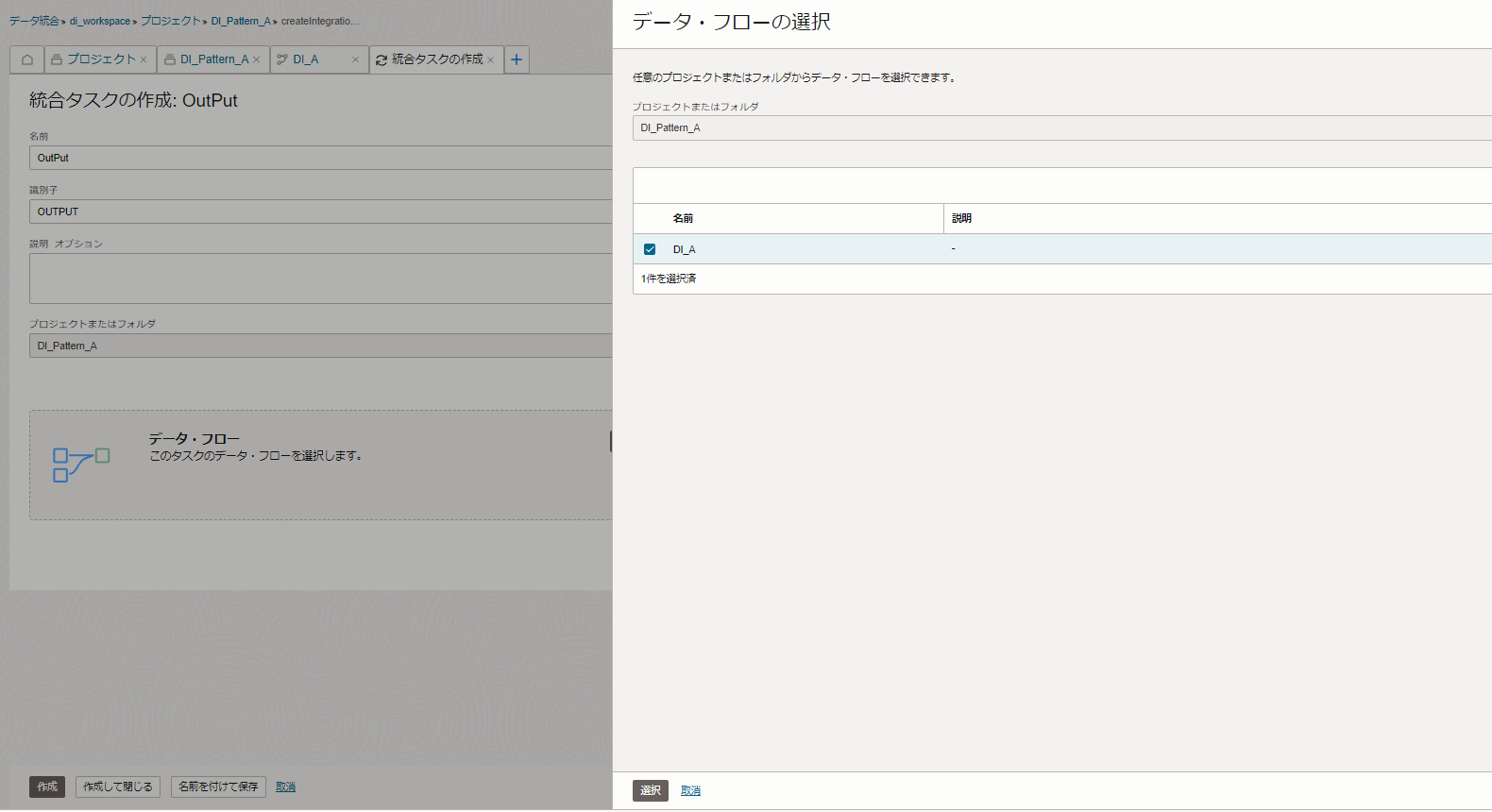
データ・フローを選択をすると自動的に検証が行われます。
検証の成功を確認し、「作成」をクリックします。
タスクの公開
タスクの作成後、Data Integrationのホーム画面にアプリケーションというタスクを実行するコンテナがあります。
タスクはアプリケーションに公開し、アプリケーションから実行します。
Data Integrationのホームタブを選択し、クイック・アクションから「アプリケーションの作成」をクリックします。
アプリケーションの作成後、「プロジェクト」 > 「タスク」をクリックして、作成した「タスク」をアプリケーションに公開します。
今回は、「Output」というタスクをアプリケーションに公開するので、作成済みのタスク「Output」右端の3つの点が、縦に並ぶメニューボタンからアプリケーションに公開を選択します。
タスクの実行
公開されたタスクはアプリケーションの詳細のタスクの下に表示され、右端のメニューボタンから実行を選択することができます。
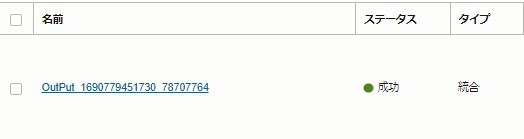
公開した「Output」のタスクを実行しました。

実行すると自動的にアプリケーションの詳細の実行に遷移します。
「リフレッシュ」をクリックすることで進捗ステータスを確認することができます。
「リフレッシュ」をクリックし、ステータスが成功になれば、タスクの実行が完了です。
ターゲットであるバケットを確認
実行された「タスク」によって、CSVファイルの出力先である「Output_Bucket」バケットの「Output_A」フォルダに、「Output.csv」ファイルが出力されています。

「Output.csv」ファイルのデータは、絞り込みと任意のカラム順で出力されているのが確認できました。

まとめ
今回は、OCIのData Integrationを使用して、2つのCSVファイルをデータ絞り込みとカラム順序変更して出力できたことは、非常にシンプルで効率的でした。
このサービスを使うことで、複雑なデータ処理を簡単に実行でき、柔軟性を持ちながらも直感的な操作で、データのETLが実現することが可能です。
データの絞り込みやカラムを任意の順番に変更したい場面では、本記事がお役に立てれると思います。
今回は、データの絞り込みとカラム順変更でしたが、次回は、Data Integrationのユーザ定義のファンクションやパラメータを紹介したいと思います。