
今回の記事では MySQL レプリケーショントポロジーの管理ツール Orchestrator の HA 構成について紹介します。
Orchestrator は MySQL レプリケーション環境の自動フェイルオーバーリカバリを行ってくれるのが主な役割ですが、本番環境など可用性が求められる環境では Orchestrator 自体の保護だったり、単一障害点とならない設計が必要となってきます。
要は、Orchestartor に障害が発生しても、MySQL レプリケーション管理&フェイルオーバ―リカバリが可能な状態を継続させる、ということが求められることになります。
HA 構成パターン
Orchestrator には HA 構成の選択肢が幾つか用意されています。
詳細については、以下の公式ドキュメントをご一読ください。
orchestrator/high-availability.md
そのうち、特に単一障害点を持たないようにする構成としては以下の2つのパターンのいずれかになります。
-
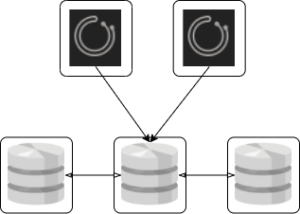
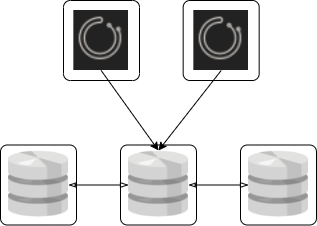
リポジトリDB を Galera Cluster/PXC, InnoDB Cluster, NDB Cluster といった同期型共有DBバックエンドにする
- Orchestrator ノードは複数台用意するが、基本的には単一ノードから操作(書込み)するように制限する
- バックエンドDB 上記 RDBMS の最低必要台数はいずれも3台
-
→ 全体で最低5台必要となる
-
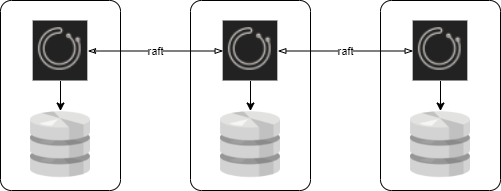
raft を用いたクラスター構成にする(orchestrator/raft)
- Orchestrator ノードは複数台(3台以上奇数台)用意し、各ノードは hashicorp/raft を用いて raft コンセンサスにより調整して動く(書込みはリーダーノードのみで行われる)
- バックエンド DB は各 Orchestrator ノードに紐づくスタンドアロン DB (MySQL または SQLite を選択可能)
- → 全体で最低3台必要となる
-
orchestrator/raftに関する公式ドキュメント:orchestrator/raft.md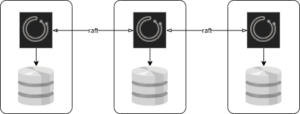
上記 1,2 それぞれの構成における対比表が公式ドキュメントで纏められていますので、こちらをご確認いただくのが最も分かり易いです。
orchestrator/raft-vs-sync-repl.md
raft クラスターの要点をまとめると以下となります。
- raft コンセンサスアルゴリズム
- クォーラムベースのリーダー選出
- raft レプリケーションログ
- スナップショットの取得・リストア
- 全メンバーが以下の処理を実行する
- レプリケーショントポロジーの検出・探査
- レプリケーショントポロジーの障害検出
- 自ノードのヘルスチェック結果登録
- リーダーノードのみが以下の処理を実行する
- リカバリ
- 任意の状態変更系コマンド実行
- HTTP リクエスト
そして上記ドキュメント内の Considerations にはどの構成を選ぶのがよいかガイダンスが示されています。
ただし、最小必要台数・スケーラビリティ・セットアップやリカバリの機能性を考慮すると raft クラスター構成を選択するのが現時点では一般的な推奨ではないかと考えます。
今回の内容は、以下の2回構成でお送りしたいと思います。
- 第1回:セットアップ方法の紹介と、基本的な障害時挙動について
- 第2回:障害ノードのリカバリ方法、クロス DC (データセンター)構成の MySQL レプリケーションフェイルオーバーリカバリとフェンシングについて
orchestrator/raft のセットアップ
検証環境
- 3ノード共通
- Rocky Linux release 8.6 (Green Obsidian)
- Orchestrator v3.2.6
| ホスト名 | IP アドレス |
|---|---|
| rha-orc-01 | 172.19.56.119 |
| rha-orc-02 | 172.19.56.120 |
| rha-orc-03 | 172.19.56.121 |
パラメータ設定
raft クラスターの構成方法は以下のドキュメントに記載されています。
orchestrator/configuration-raft.md
/etc/orchestrator.conf.json を以下のように編集します。
(rha-orc-01 の場合)
|
1 2 3 4 5 6 7 8 9 |
"RaftEnabled": true, "RaftDataDir": "/var/lib/orchestrator", "RaftBind": "172.19.56.119", "DefaultRaftPort": 10008, "RaftNodes": [ "172.19.56.119", "172.19.56.120", "172.19.56.121" ] |
RaftNodes には RaftBind に設定した自ノードを含むすべてのクラスターノードを列挙する必要があります。
全クラスターノードで orchestrator を起動すると、ノード間で raft 通信が開始されます。
orchestrator ログファイルには、DEBUG レベルでログ出力させていると raft 関連のロギングが多量に出力されます。
こちらは rha-orc-02 (172.19.56.120) のログ抜粋ですが、raft リーダーに選出されています。
|
1 2 3 4 5 6 |
2023-04-05 15:37:06 DEBUG orchestrator/raft: applying command 1685019: leader-uri ... 2023-04-05 15:37:10 DEBUG raft leader is 172.19.56.120:10008 (this host); state: Leader ... 2023-04-05 15:37:15 DEBUG raft leader is 172.19.56.120:10008 (this host); state: Leader 2023-04-05 15:37:15 DEBUG orchestrator/raft: applying command 1685020: request-health-report |
rha-orc-03 (172.19.56.121) のログには、リーダーが 172.19.56.120 で、自分はフォロワー(state: Follower)であることが出力確認できます。
|
1 2 3 4 5 6 7 |
2023-04-05 15:37:06 DEBUG orchestrator/raft: applying command 1685019: leader-uri 2023/04/05 15:37:06 [DEBUG] raft-net: 172.19.56.121:10008 accepted connection from: 172.19.56.120:56522 ... 2023-04-05 15:37:10 DEBUG raft leader is 172.19.56.120:10008; state: Follower ... 2023-04-05 15:37:15 DEBUG raft leader is 172.19.56.120:10008; state: Follower 2023-04-05 15:37:15 DEBUG orchestrator/raft: applying command 1685020: request-health-report |
orchestrator-client 用の追加設定
orchestrator バイナリは単体で CLI コマンドを実行することができるのですが、 raft クラスター構成の場合、以下のエラーで実行できません。
|
1 2 |
# /usr/local/orchestrator/orchestrator -c topology --alias rha-db 2023-04-05 15:59:17 FATAL Orchestrator configured to run raft ("RaftEnabled": true). All access must go through the web API of the active raft node. You may use the orchestrator-client script which has a similar interface to the command line invocation. You may override this with --ignore-raft-setup |
エラーメッセージに記載されている通り、--ignore-raft-setup オプションを付与すれば実行は可能です。(--quietオプションは 2>/dev/null と同義です)
|
1 |
# /usr/local/orchestrator/orchestrator -c topology -alias rha-db --ignore-raft-setup --quiet |
このエラーの対応方法は以下のページに記載されています。
orchestrator/deployment-raft.md – What to deploy: client
(本家 Github リポジトリには raft に関する公式ドキュメントが散在している状態なのでなかなか見つけ辛いですが…)
raft クラスター構成の場合、リーダーノードで管理操作(特に変更系)を行うことが必要ですが、 orchestrator バイナリの CLI コマンドはローカルの DB に直接アクセスしに行くので、自ノードが リーダーノードなのか判断できないため敢えて実行エラーとしているのです。
対応方法としては、orchestrator-client を実行する OS ユーザの .bash_profile、もしくは OS ログインユーザ全体に適用させるなら /etc/profile.d/orchestrator-client.sh を作成して以下の環境変数を設定します。(※名前解決できる前提)
|
1 |
ORCHESTRATOR_API="http://rha-orc-01:3000/api http://rha-orc-02:3000/api http://rha-orc-03:3000/api" |
この設定方法の場合、orchestrator-client が raft リーダーを自動判別してくれます。
上記マニュアルにも記載ある通り、もし raft リーダーにプロキシするエンドポイントを設定済みなら、以下のように設定してもかまいません。
|
1 |
ORCHESTRATOR_API="http://your.orchestrator.service.proxy:80/api" |
※以下のドキュメントページに HAProxy でセットアップする例が記載されていますのでご参考までに。
orchestrator/raft.md – Proxy: leader
RaftDataDir
RaftDataDir パラメータに指定したディレクトリには、raft のイベントログとスナップショットが格納されます。
|
1 2 3 4 |
# ls -l /var/lib/orchestrator total 3988 -rw-r--r--. 1 root root 4075520 Apr 5 17:03 raft_store.db drwxr-xr-x. 12 root root 4096 Apr 5 16:51 snapshots |
スナップショットは、Orchestrator がノードダウン後、クラスタに再参加したときに、他のアクティブなノードから最新のスナップショットを取得してダウン中に発生していたイベントを漏れなく取得することができます。
Web 管理コンソール上の表示
raft クラスターの状態は、Web 管理コンソールにログイン後、 Home > Status と辿ると確認することができます。
リーダーノード のステータス画面にのみ、raft メンバーが表示されます。
(以下の例は rha-orc-02 がリーダーノードの場合)
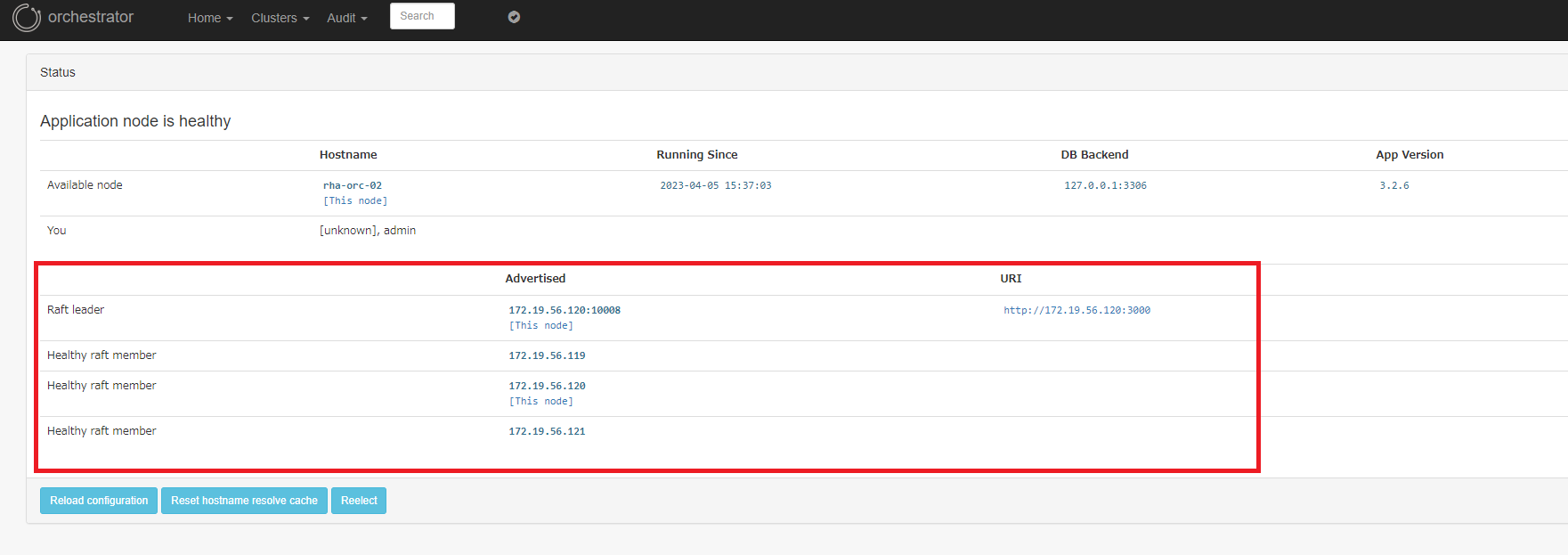
フォロワーノードでは他メンバーは表示されない仕様のようです。
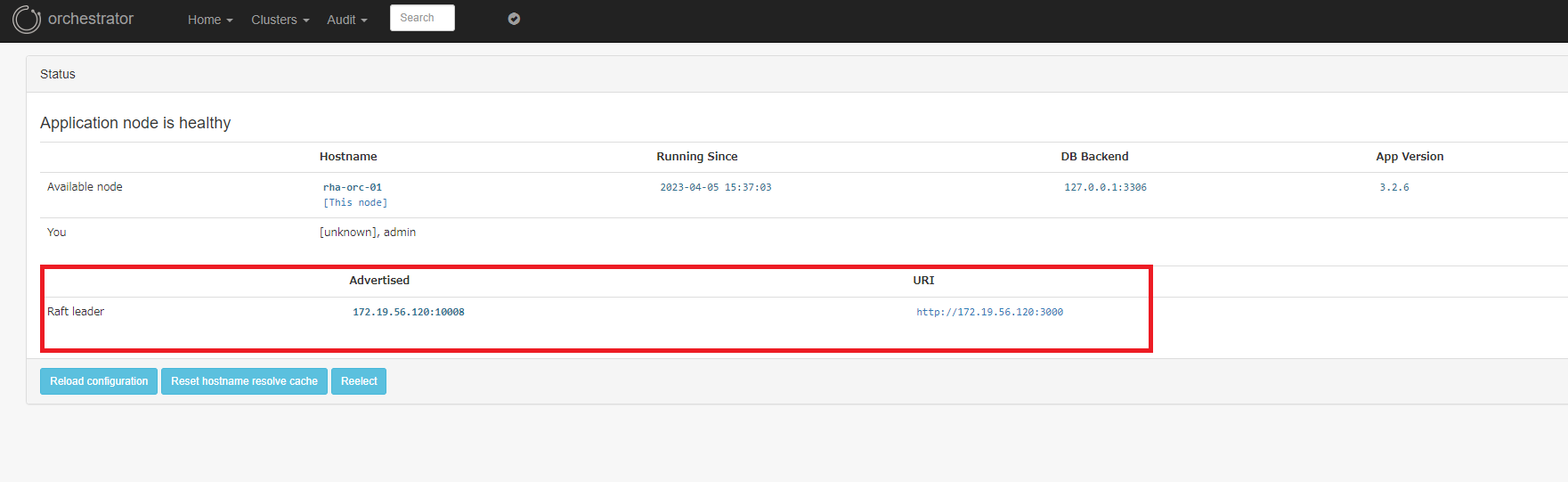
リーダーノードの確認と手動選出の CLI コマンド
以下の CLI コマンドで現在のリーダーノードを確認できます。
|
1 2 |
# orchestrator-client -c raft-leader 172.19.56.120:10008 |
リーダーノードに設定するには raft-elect-leader コマンドを実行します。
以下は、自ノードをリーダーノードに設定するコマンド例です。
|
1 2 |
[root@rha-orc-03 ~]# orchestrator-client -c raft-elect-leader -H <code>uname -n rha-orc-03 |
平常時にリーダーノードがダウンした場合
まずは基本動作の確認です。
|
1 2 3 |
[root@rha-orc-03 ~]# orchestrator-client -c raft-leader 172.19.56.121:10008 [root@rha-orc-03 ~]# systemctl stop orchestrator.service |
rha-orc-03 のログから Orchestrator プロセスが停止したのを確認します。
|
1 |
2023-04-06 12:19:40 INFO Received SIGTERM. Shutting down orchestrator |
rha-orc-01 のログでは、rha-orc-03 とのハートビートがタイムアウト後、リーダー選出が開始され、このノードがリーダーとなった様子が確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
2023/04/06 12:19:41 [WARN] raft: Heartbeat timeout from "172.19.56.121:10008" reached, starting election 2023/04/06 12:19:41 [INFO] raft: Node at 172.19.56.119:10008 [Candidate] entering Candidate state 2023/04/06 12:19:41 [ERR] raft: Failed to make RequestVote RPC to 172.19.56.121:10008: dial tcp 172.19.56.121:10008: connect: connection refused 2023/04/06 12:19:41 [DEBUG] raft: Votes needed: 2 2023/04/06 12:19:41 [DEBUG] raft: Vote granted from 172.19.56.119:10008. Tally: 1 2023/04/06 12:19:42 [INFO] raft: Duplicate RequestVote for same term: 401 2023/04/06 12:19:43 [WARN] raft: Election timeout reached, restarting election 2023/04/06 12:19:43 [INFO] raft: Node at 172.19.56.119:10008 [Candidate] entering Candidate state 2023/04/06 12:19:43 [ERR] raft: Failed to make RequestVote RPC to 172.19.56.121:10008: dial tcp 172.19.56.121:10008: connect: connection refused 2023/04/06 12:19:43 [DEBUG] raft: Votes needed: 2 2023/04/06 12:19:43 [DEBUG] raft: Vote granted from 172.19.56.119:10008. Tally: 1 2023/04/06 12:19:43 [DEBUG] raft: Vote granted from 172.19.56.120:10008. Tally: 2 2023/04/06 12:19:43 [INFO] raft: Election won. Tally: 2 2023/04/06 12:19:43 [INFO] raft: Node at 172.19.56.119:10008 [Leader] entering Leader state |
rha-orc-02 のログでは、このノードはフォロワー(変わらず)という結果が確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
2023-04-06 12:19:40 DEBUG raft leader is 172.19.56.121:10008; state: Follower 2023/04/06 12:19:41 [DEBUG] raft-net: 172.19.56.120:10008 accepted connection from: 172.19.56.119:59832 2023/04/06 12:19:41 [WARN] raft: Rejecting vote request from 172.19.56.119:10008 since we have a leader: 172.19.56.121:10008 2023/04/06 12:19:42 [WARN] raft: Heartbeat timeout from "172.19.56.121:10008" reached, starting election 2023/04/06 12:19:42 [INFO] raft: Node at 172.19.56.120:10008 [Candidate] entering Candidate state 2023/04/06 12:19:42 [ERR] raft: Failed to make RequestVote RPC to 172.19.56.121:10008: EOF 2023/04/06 12:19:42 [DEBUG] raft: Votes needed: 2 2023/04/06 12:19:42 [DEBUG] raft: Vote granted from 172.19.56.120:10008. Tally: 1 2023/04/06 12:19:43 [INFO] raft: Node at 172.19.56.120:10008 [Follower] entering Follower state (Leader: "") 2023/04/06 12:19:43 [DEBUG] raft: Node 172.19.56.120:10008 updated peer set (2): [172.19.56.119:10008 172.19.56.121:10008 172.19.56.120:10008] 2023-04-06 12:19:43 DEBUG orchestrator/raft: applying command 1694066: leader-uri 2023/04/06 12:19:43 [DEBUG] raft-net: 172.19.56.120:10008 accepted connection from: 172.19.56.119:59840 2023-04-06 12:19:45 DEBUG raft leader is 172.19.56.119:10008; state: Follower |
CLI コマンドでも、新しいリーダーノードである rha-orc-01 が確認できました。
|
1 2 |
[root@rha-orc-01 ~]# orchestrator-client -c raft-leader 172.19.56.119:10008 |
rha-orc-03 の Orchestrator サービスを再び起動します。
ローカルノードに取得していたスナップショットをリストアした後、アクティブな他ノードからログを取得し適用、クラスターに再参加する動きとなります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
2023-04-06 12:28:46 INFO starting orchestrator, version: 3.2.6, git commit: c846d43668239cad384dc31b9255a3ade3a35001 ... 2023-04-06 12:28:46 DEBUG Setting up raft 2023-04-06 12:28:46 DEBUG raft: advertise=172.19.56.121:10008 2023-04-06 12:28:46 DEBUG raft: transport=&{connPool:map[] connPoolLock:{state:0 sema:0} consumeCh:0xc000075800 heartbeatFn:<nil> heartbeatFnLock:{state:0 sema:0} logger:0xc0002ac140 maxPool:3 shutdown:false shutdownCh:0xc000075860 shutdownLock:{state:0 sema:0} stream:0xc00000f668 timeout:10000000000 TimeoutScale:262144} 2023-04-06 12:28:46 DEBUG raft: peers=[172.19.56.119:10008 172.19.56.120:10008 172.19.56.121:10008] 2023-04-06 12:28:46 DEBUG raft: logStore=&{dataDir:/var/lib/orchestrator backend:<nil>} 2023-04-06 12:28:46 INFO raft: store initialized at /var/lib/orchestrator/raft_store.db 2023-04-06 12:28:46 INFO Starting HTTP listener on :3000 2023-04-06 12:28:46 DEBUG Queue.startMonitoring(DEFAULT) 2023-04-06 12:28:46 DEBUG raft snapshot restore: discarded 0 keys 2023-04-06 12:28:46 DEBUG raft snapshot restore: discovered 0 keys 2023-04-06 12:28:46 ERROR Error 1292: Incorrect datetime value: '' for column 'expire_timestamp' at row 1 2023-04-06 12:28:46 ERROR Error 1292: Incorrect datetime value: '' for column 'end_recovery' at row 1 2023/04/06 12:28:47 [DEBUG] raft-net: 172.19.56.121:10008 accepted connection from: 172.19.56.119:48706 2023-04-06 12:28:48 DEBUG raft snapshot restore applied 2023/04/06 12:28:48 [INFO] raft: Restored from snapshot 400-1693882-1680749669134 2023-04-06 12:28:48 INFO new raft created 2023-04-06 12:28:48 INFO continuous discovery: starting 2023/04/06 12:28:48 [INFO] raft: Node at 172.19.56.121:10008 [Follower] entering Follower state (Leader: "") 2023-04-06 12:28:48 DEBUG orchestrator/raft: applying command 1693883: request-health-report [martini] Started GET /api/raft-follower-health-report/ca39e218/172.19.56.121/172.19.56.121 for 172.19.56.121:36668 2023-04-06 12:28:48 ERROR Raft health report: unknown token ca39e218 [martini] Completed 500 Internal Server Error in 2.246295ms 2023-04-06 12:28:48 ERROR HttpGetLeader: got 500 status on http://172.19.56.121:3000/api/raft-follower-health-report/ca39e218/172.19.56.121/172.19.56.121 |
レプリケーションソースフェイルオーバー中にリーダーノードがダウンした場合
つぎに、管理している MySQL レプリケーショントポロジーのソースDBがダウンしフェイルオーバーリカバリを実行中のケースを確認します。
通常時のレプリケーショントポロジーが以下の状態です。
|
1 2 3 4 5 6 |
2023-04-06 19:47:26 rha-db-01:3306 [0s,ok,8.0.23,rw,ROW,>>,GTID,semi:master] + rha-db-02:3306 [0s,ok,8.0.23,ro,ROW,>>,GTID,semi:replica] + rha-db-03:3306 [0s,ok,8.0.23,ro,ROW,>>,GTID] + rha-db-04:3306 [0s,ok,8.0.23,ro,ROW,>>,GTID] + rha-db-05:3306 [0s,ok,8.0.23,ro,ROW,>>,GTID] |
ソース mysqld を停止しました。
|
1 2 |
[root@rha-db-01 ~]# date '+%F %T';systemctl stop mysqld 2023-04-06 19:47:30 |
rha-orc-01 のリカバリフック実行ログに PreFailoverProcesses で仕込んでおいたスクリプトの実行が確認できます。
実際のリカバリ処理(新ソースへのフェイルオーバ処理)が動く直前のステップです。
(このスクリプトには今回の検証のため sleep を入れています)
|
1 2 3 |
2023-04-06 19:47:36.236 Detected UnreachableMaster on rha-db-01:3306. Affected replicas: 4 2023-04-06 19:47:40.234 Will recover from DeadMaster on rha-db-01:3306 2023-04-06 19:47:40.257 [INFO] pre-failover.sh Start. |
このタイミングで リーダーノードの orchestrator プロセスを強制停止します。
|
1 |
[root@rha-orc-01 ~]# pkill -9 orchestrator |
rha-orc-03 のリカバリフック実行ログを確認すると、DeadMaster のリカバリステップから処理が継続されています。
rha-orc-03 がリーダーノードとなったためです。
|
1 2 3 4 5 6 7 8 9 |
2023-04-06 19:47:48.648 Will recover from DeadMaster on rha-db-01:3306 2023-04-06 19:47:48.668 [INFO] pre-failover.sh Start. (sleep を入れたため少し待機...) 2023-04-06 19:48:19.250 Recovered from DeadMaster on rha-db-01:3306. Failed: rha-db-01:3306; Promoted: rha-db-02:3306 2023-04-06 19:48:19.283 (for all types) Recovered from DeadMaster on rha-db-01:3306. Failed: rha-db-01:3306; Successor: rha-db-02:3306 2023-04-06 19:48:19.303 [INFO] post-failover.sh Start. 2023-04-06 19:48:19.307 [INFO] post-failover.sh End. |
独自のスクリプトをフックさせて実行させている途中で Orchestrator のフェイルオーバが起こった場合は、流石にスクリプト内の処理を継続したりリカバリしたりはできないので、それはユーザー側の責任範疇です。
障害時を想定したアトミックまたはフェイルセーフなコーディングを心掛けたいところです。
rha-orc-03 の Orchestrator ログで raft によるリカバリ処理のフェイルオーバ状況が確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
2023/04/06 19:47:45 [WARN] raft: Heartbeat timeout from "172.19.56.119:10008" reached, starting election 2023/04/06 19:47:45 [INFO] raft: Node at 172.19.56.121:10008 [Candidate] entering Candidate state 2023/04/06 19:47:45 [ERR] raft: Failed to make RequestVote RPC to 172.19.56.119:10008: EOF 2023/04/06 19:47:45 [DEBUG] raft: Votes needed: 2 2023/04/06 19:47:45 [DEBUG] raft: Vote granted from 172.19.56.121:10008. Tally: 1 2023/04/06 19:47:46 [DEBUG] raft-net: 172.19.56.121:10008 accepted connection from: 172.19.56.120:47922 2023/04/06 19:47:46 [INFO] raft: Duplicate RequestVote for same term: 478 2023/04/06 19:47:47 [WARN] raft: Election timeout reached, restarting election 2023/04/06 19:47:47 [INFO] raft: Node at 172.19.56.121:10008 [Candidate] entering Candidate state 2023/04/06 19:47:47 [ERR] raft: Failed to make RequestVote RPC to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:47 [DEBUG] raft: Votes needed: 2 2023/04/06 19:47:47 [DEBUG] raft: Vote granted from 172.19.56.121:10008. Tally: 1 2023/04/06 19:47:47 [DEBUG] raft: Vote granted from 172.19.56.120:10008. Tally: 2 2023/04/06 19:47:47 [INFO] raft: Election won. Tally: 2 2023/04/06 19:47:47 [INFO] raft: Node at 172.19.56.121:10008 [Leader] entering Leader state 2023/04/06 19:47:47 [ERR] raft: Failed to AppendEntries to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:47 [INFO] raft: pipelining replication to peer 172.19.56.120:10008 2023/04/06 19:47:47 [DEBUG] raft: Node 172.19.56.121:10008 updated peer set (2): [172.19.56.121:10008 172.19.56.119:10008 172.19.56.120:10008] 2023-04-06 19:47:47 DEBUG orchestrator/raft: applying command 1697985: leader-uri 2023/04/06 19:47:47 [ERR] raft: Failed to AppendEntries to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:47 [ERR] raft: Failed to AppendEntries to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:47 [ERR] raft: Failed to AppendEntries to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:47 [ERR] raft: Failed to heartbeat to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:47 [ERR] raft: Failed to AppendEntries to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:47 [ERR] raft: Failed to heartbeat to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:47 [ERR] raft: Failed to AppendEntries to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:48 [WARN] raft: Failed to contact 172.19.56.119:10008 in 501.56379ms 2023/04/06 19:47:48 [ERR] raft: Failed to heartbeat to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:48 [ERR] raft: Failed to AppendEntries to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:48 [ERR] raft: Failed to heartbeat to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023/04/06 19:47:48 [WARN] raft: Failed to contact 172.19.56.119:10008 in 952.922553ms 2023/04/06 19:47:48 [ERR] raft: Failed to heartbeat to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023-04-06 19:47:48 ERROR Will not resolve empty hostname 2023-04-06 19:47:48 INFO executeCheckAndRecoverFunction: proceeding with DeadMaster detection on rha-db-01:3306; isActionable?: true; skipProcesses: false 2023/04/06 19:47:48 [ERR] raft: Failed to AppendEntries to 172.19.56.119:10008: dial tcp 172.19.56.119:10008: connect: connection refused 2023-04-06 19:47:48 INFO checkAndExecuteFailureDetectionProcesses: could not register DeadMaster detection on rha-db-01:3306 2023-04-06 19:47:48 INFO executeCheckAndRecoverFunction: proceeding with DeadMaster recovery on rha-db-01:3306; isRecoverable?: true; skipProcesses: false 2023-04-06 19:47:48 DEBUG orchestrator/raft: applying command 1697986: write-recovery 2023-04-06 19:47:48 INFO topology_recovery: will handle DeadMaster event on rha-db-01:3306 2023-04-06 19:47:48 DEBUG orchestrator/raft: applying command 1697987: write-recovery-step 2023-04-06 19:47:48 INFO topology_recovery: Running 2 PreFailoverProcesses hooks 2023-04-06 19:47:48 DEBUG orchestrator/raft: applying command 1697988: write-recovery-step 2023-04-06 19:47:48 INFO topology_recovery: Running PreFailoverProcesses hook 1 of 2: echo $(date +'%Y-%m-%d %H:%M:%S.%3N') 'Will recover from DeadMaster on rha-db-01:3306' >> /var/log/orchestrator/recovery.log |
結果、レプリケーションフェイルオーバーリカバリが完遂しました。
|
1 2 3 4 5 |
2023-04-06 19:48:28 rha-db-02:3306 [0s,ok,8.0.23,rw,ROW,>>,GTID,semi:master] + rha-db-03:3306 [0s,ok,8.0.23,ro,ROW,>>,GTID,semi:replica] + rha-db-04:3306 [0s,ok,8.0.23,ro,ROW,>>,GTID] + rha-db-05:3306 [0s,ok,8.0.23,ro,ROW,>>,GTID] |
Orchestrator リポジトリDBスキーマが消失や破損した場合
リポジトリDB のスキーマ(※) が消失したり破損した場合、Orchestrator サービスはダウンします。
※スキーマ名は MySQLOrchestratorDatabase パラメータで定義。デフォルトは orchestrator
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | orchestrator | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) mysql> drop database orchestrator; Query OK, 47 rows affected (0.19 sec) |
|
1 2 3 4 5 |
2023-04-06 19:24:57 ERROR Error 1049: Unknown database 'orchestrator' 2023-04-06 19:24:57 ERROR Error 1049: Unknown database 'orchestrator' 2023-04-06 19:24:57 ERROR ContinuousRegistration: RegisterNode failed: Error 1049: Unknown database 'orchestrator' 2023-04-06 19:24:57 ERROR Health test is failing for over 5 seconds. raft yielding 2023-04-06 19:24:57 FATAL Node is unable to register health. Please check database connnectivity and/or time synchronisation. |
フェイルオーバーリカバリ中に発生した場合は、前述と同じように他のメンバーノードで処理がフェイルオーバー(継続)されます。
ダウンした Orchestrator を再び起動させれば、起動時に DB スキーマおよびテーブルは内部的に再作成されます。
その後、raft スナップショットのリストアおよびクラスタメンバーからの raft ログ適用によって、最新状態までリカバリされます。
まとめ
今回の記事では、Orchestrator raft クラスターのセットアップと障害時挙動(フェイルオーバー、リカバリの継続実行)について確認しました。
パラメータを設定するだけの非常にシンプルなセットアップで HA 構成が組めることが特徴的です。
また、目的である冗長化による Orchestrator のサービス継続性も高まることがお分かりいただけたかと思います。
続き記事として、次回は以下のドキュメントにも紹介されている DC fencing (複数データセンターに分散配置させた場合のフェイルオーバーリカバリ時のフェンシング)の挙動について確認してみたいと思います。






