
はじめに
MySQLを使用しているユーザの多くは「レプリケーション」機能を使用されているのではないかと思います。同機能を利用すると様々なレプリケーション構成(トポロジー)を組むことができます。
主なトポロジーとしては以下のようなものが挙げられます。勿論、別々のトポロジーを組み合わせるケースもあります。
- 通常のソース-レプリカ構成(1台のソース+複数台のレプリカ)
- マルチソースレプリケーション構成(複数台のソース+1台のレプリカ)
- グループレプリケーション構成(複数台のソース)
- 多段レプリケーション構成(ソース+子レプリカ+孫レプリカ)
そうした中で少しマイナーなトポロジーとして「デュアルソース(デュアルマスタ)構成」があります。これは2台のMySQLがお互いに「ソース」且つ「レプリカ」として同期し合う構成です。
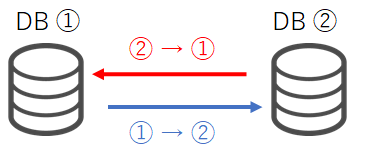
※ 通常の非同期レプリケーションを使った構成の他、「Galera Clusterを使ったデュアルソース構成」もあります
今回はこの珍しい構成をテーマとして取り上げたいと思います。
デュアルソース構成のメリット・デメリット
デュアルソース構成を組んだ場合のメリットとしては以下のような点が挙げられます。
【メリット】
- 通常のソース・レプリカ構成であればソースは1台のみで、なおかつレプリカは通常read_onlyが有効なため、ソースがダウンすると更新可能なMySQLが無くなります。しかし、デュアルソースの場合は更新可能なソースが2台あるため片方がダウンしても継続が可能です。
- 利用するのは通常の非同期レプリケーション機能であるため、特別な知識が必要ない
- 更新クエリを2台のソースに分散させることも可能
一方、以下のようなデメリットも存在します。
【デメリット】
- 更新クエリの内容によっては、両方のソースで更新が重複してしまいレプリケーションが壊れてしまう(不整合が発生する)
→ とくにauto_incrementの挙動に注意が必要(auto_increment_increment と auto_increment_offset を利用) - アクティブ-スタンバイ(詳細は後述)の構成にすれば上記の更新重複は回避できるが、メリットがいくつか失われる
結論としては、デュアルソース構成は少し使うのにはコツが要ります。そのため、正直一般的な構成とは言えず、実際に本番導入されているケースも少ないかと思います。
NDB Clusterを使用したデュアルソース構成
一般的には通常のMySQL Serverを使ってデュアルソース構成を組みますが、MySQL NDB Clusterを使って構築することも可能です。
もし2ノード構成のMySQL NDB Clusterを使ってみたい場合、dbdeployerを使って簡単に検証することができます。なお、今回は dbdeployer ver 1.52.0 を使用しています。
※ .tar.gzパッケージは公式ページからダウンロードしてください
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
$ dbdeployer --version dbdeployer version 1.52.0 ### SQLノード2台構成でデプロイ ### NDBノード(=データノード)2台構成は指定できませんでした $ dbdeployer deploy --topology=ndb replication ndb_8.0.22 --nodes 2 Installing and starting node 1 Installing and starting node 2 $HOME/sandboxes/ndb_msb_ndb_8_0_22/initialize_nodes MySQL Cluster Management Server mysql-8.0.22 ndb-8.0.22 2020-12-09 11:04:08 [ndbd] INFO -- Angel connected to 'localhost:22200' 2020-12-09 11:04:08 [ndbd] INFO -- Angel allocated nodeid: 2 2020-12-09 11:04:08 [ndbd] INFO -- Angel connected to 'localhost:22200' 2020-12-09 11:04:08 [ndbd] INFO -- Angel allocated nodeid: 3 executing 'start' on node 1 ................................... sandbox server started executing 'start' on node 2 ....................................... sandbox server started NDB cluster directory installed in $HOME/sandboxes/ndb_msb_ndb_8_0_22 run 'dbdeployer usage multiple' for basic instructions' $ cd sandboxes/ndb_msb_ndb_8_0_22/ $ ./ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm> show Connected to Management Server at: localhost:22200 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @127.0.0.1 (mysql-8.0.22 ndb-8.0.22, Nodegroup: 0, *) id=3 @127.0.0.1 (mysql-8.0.22 ndb-8.0.22, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @127.0.0.1 (mysql-8.0.22 ndb-8.0.22) [mysqld(API)] 3 node(s) id=4 @127.0.0.1 (mysql-8.0.22 ndb-8.0.22) id=5 @127.0.0.1 (mysql-8.0.22 ndb-8.0.22) id=6 (not connected, accepting connect from localhost) |
MySQL NDB Clusterを使った場合、更新クエリの分散処理もサポートされているため動作に不具合が出る可能性は低くなります。MySQL NDB ClusterはMySQL Serverとは異なる特徴を持つ製品であり、2ノードで構成することは一般的ではありませんが、試してみても良いかもしれません。
デュアルソース構成と自動フェイルオーバ
もし、デュアルソース環境を利用する場合に便利な機能があります。それは、以前別の記事でも取り上げた「接続フェイルオーバ」機能です。
ここでは、以下のような構成を想定しています。
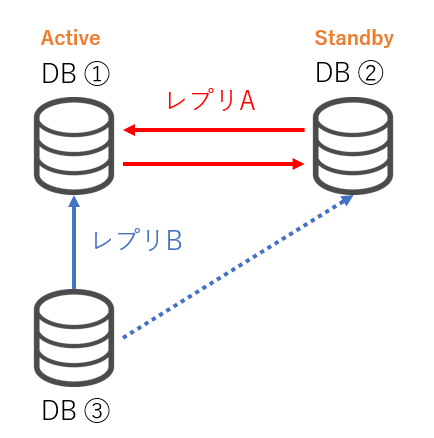
- ソースが2台存在し、互いにソース・レプリカとなるレプリケーションを組んでいる(レプリA)
- 通常時はDB①(Active)に対してのみ更新クエリを実行し、DB①がダウンしている場合にDB②(Standby)を使用する
- DB①をソースとしてDB③がレプリカとして存在し(レプリB)、参照クエリはDB③に対して実行する
この構成の場合、DB①がダウンもしくはレプリBのNWが切断された場合、通常であればDB③はエラーのまま放置され、データの整合性も保たれなくなります。
しかし、フェイルオーバ機能を使えばDB①がダウンしてもDB③はソースを自動的にDB②に切り替えてくれるため、整合性は保たれることが期待されます。
再び、dbdeployerを使って、上記の挙動を確認してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
$ dbdeployer deploy --topology=fan-in replication 8.0.22 ※ "fan-in"トポロジーでデプロイすると上記の構成と同じソース2台、レプリカ1台の構成が作られます(マルチソースレプリケーション) ### DB③にログイン $ cd sandboxes/fan_in_msb_8_0_22/ $ ./s3 ### 既存のレプリケーション情報をリセット node3 [localhost:22825] {msandbox} ((none)) > STOP REPLICA; node3 [localhost:22825] {msandbox} ((none)) > RESET REPLICA ALL; node3 [localhost:22825] {msandbox} ((none)) > RESET MASTER; ### ソースリストにDB①を登録 node3 [localhost:22825] {msandbox} ((none)) > SELECT asynchronous_connection_failover_add_source('', '127.0.0.1', 22823, '', 100); +------------------------------------------------------------------------------+ | asynchronous_connection_failover_add_source('', '127.0.0.1', 22823, '', 100) | +------------------------------------------------------------------------------+ | The UDF asynchronous_connection_failover_add_source() executed successfully. | +------------------------------------------------------------------------------+ ### ソースリストにDB②を登録 node3 [localhost:22825] {msandbox} ((none)) > SELECT asynchronous_connection_failover_add_source('', '127.0.0.1', 22824, '', 50); +------------------------------------------------------------------------------+ | asynchronous_connection_failover_add_source('', '127.0.0.1', 22824, '', 50) | +------------------------------------------------------------------------------+ | The UDF asynchronous_connection_failover_add_source() executed successfully. | +------------------------------------------------------------------------------+ ### 登録した情報を確認 node3 [localhost:22825] {msandbox} ((none)) > SELECT * FROM performance_schema.replication_asynchronous_connection_failover; +--------------+-----------+-------+-------------------+--------+ | CHANNEL_NAME | HOST | PORT | NETWORK_NAMESPACE | WEIGHT | +--------------+-----------+-------+-------------------+--------+ | | 127.0.0.1 | 22823 | | 100 | | | 127.0.0.1 | 22824 | | 50 | +--------------+-----------+-------+-------------------+--------+ ### Node1→Node3の非同期レプリケーション開始 ### MASTER_AUTO_POSITION=1,SOURCE_CONNECTION_AUTO_FAILOVER=1を忘れずに指定 node3 [localhost:22825] {msandbox} ((none)) > CHANGE MASTER TO MASTER_HOST="127.0.0.1", MASTER_PORT=22823, MASTER_USER="msandbox", MASTER_PASSWORD="msandbox", MASTER_AUTO_POSITION=1, MASTER_RETRY_COUNT=3, MASTER_CONNECT_RETRY=10, SOURCE_CONNECTION_AUTO_FAILOVER=1; Query OK, 0 rows affected, 2 warnings (0.07 sec) node3 [localhost:22825] {msandbox} ((none)) > START REPLICA; Query OK, 0 rows affected (0.01 sec) |
※ MASTER_RETRY_COUNTは「ソースへの切断を検知した後に接続をリトライする回数」で、MASTER_CONNECT_RETRYはリトライする間隔です。デフォルトではこのリトライ回数が60日間と非常に長いため、設定を変更することを推奨します
上記でフェイルオーバーの設定は完了です。それでは早速Node1を停止して、フェイルオーバーを実施してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
### Node1がソースであることを確認 $ ./s3 -e "SHOW REPLICA STATUS\G" *************************** 1. row *************************** Replica_IO_State: Waiting for master to send event Source_Host: 127.0.0.1 Source_User: msandbox Source_Port: 22823 ### ← Node1 になっている ...(省略)... Replica_IO_Running: Yes Replica_SQL_Running: Yes ### Node1を停止する $ ./node1/stop stop /home/vagrant/sandboxes/fan_in_msb_8_0_22/node1 ### 30秒後(10秒間隔で3回リトライ)にソースが切り替わっていることを確認 $ ./s3 -e "SHOW REPLICA STATUS\G" *************************** 1. row *************************** Replica_IO_State: Waiting for master to send event Source_Host: 127.0.0.1 Source_User: msandbox Source_Port: 22824 ### ← Node2 になっている ...(省略)... Replica_IO_Running: Yes Replica_SQL_Running: Yes |
おわりに
実際の本番環境でデュアルソース構成を採用するケースは少ないかもしれませんが、このような構成が存在するという知識を覚えておくだけでも運用の選択肢は増えるかと思います。
MySQLを導入したい環境のサーバ台数や要件に合わせて、最善の構成を選択できるよう気を付けましょう。








